MarkLogicをインストールした後は、データロードを行います。
前回の記事で簡単な動作確認用のデータロード方法を記載しましたが、じゃあ大量データはどうやって登録するのといった話があるのですぐに使えるような記事にします。
データロードの前に
このNOsqlDBはOracleDBなどのRDBMSと異なりETLを必要としません。
テーブル定義などを行うことなくデータをASISで取り込むことができます。
取り込めるドキュメントタイプはこの通りです。
- xml(Extensible Markup Language):基本ドキュメントタイプ。ファレンスとかでもxmlが前提となっている
- JSON(JavaScript Object Notation): xmlと同じく構造データ。 ウェブアプリで値を返却するときはJSONが多い
- TEXT:取り込んで検索はできるけど構造は持たない。
- RDF(Resource Description Framework):そもそもの理解についてはこちらを参考にしました
- バイナリ:画像とかofficeドキュメントなど。他のデータと同様に格納できます。参照するときは、URLでアクセスしてダウンロードします
memo1
後述しますが、CSVは取り込み時にxmlの形に変換すればデータを扱うことが容易です。なので、実際RDBMSから移行をかけるときはCSVエクスポートでmarklogicに取り込むのがいいかなと思います。(難しくない)
memo2
逆にmarklogicからデータをエクスポートするときは、クエリ―コンソールでクエリ―組むかCorbを使うかですかね。
データロード5種
その1/5 メモリロード(一番手っ取り早い)
クエリ―コンソールでxdmp:document-insert()関数を使います。まあほとんど動作確認用ですね。
その2/5 Webdav(準備が簡単で手っ取り早いが)
Webdavの機能でGUIでポイっと格納できます。
なのですが、Webdavなのでロードに時間がかかるしファイルサイズが大きいものは無理です。
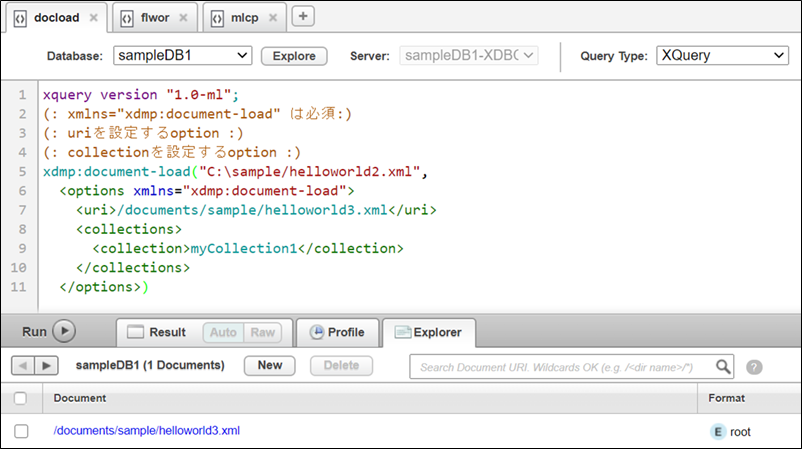
その3/5 ファイルシステムからドキュメントをロード(初心者向け)
クエリ―コンソールにて下記のようにdocument-loadでローカルファイルを投入できます。(1ドキュメントをファイル指定で取り込み)
- ソースコード
xquery version "1.0-ml";
(: xmlns="xdmp:document-load" は必須:)
(: uriを設定するoption :)
(: collectionを設定するoption :)
xdmp:document-load("C:\sample/helloworld2.xml",
<options xmlns="xdmp:document-load">
<uri>/documents/sample/helloworld3.xml</uri>
<collections>
<collection>myCollection1</collection>
</collections>
</options>)
- サンプルデータ (C:\sample/helloworld2.xml)
<?xml version="1.0" encoding="UTF-8"?>
<root>
<message>Hello2</message>
<message>World2</message>
</root>
- イメージ
その4/5 FLWOR で一括ロードする(ML歩きはじめ)
クエリ―コンソールにて下記のようにFLWOR式を利用してdocument-loadでローカルファイルを投入できます。(フォルダ指定で取り込み)
- ソースコード
(: namespaceの指定は必須 :)
(: filesystem-directoryでローカルディレクトリの指定 :)
(: uri指定で/hogehoge/配下になるように指定しています :)
declare namespace dir="http://marklogic.com/xdmp/directory";
for $d in xdmp:filesystem-directory("C:\sample\sample_many_data")//dir:entry
return xdmp:document-load($d//dir:pathname,
<options xmlns="xdmp:document-load">
<uri>/hogehoge/{fn:string($d//dir:filename)}</uri>
<collections>
<collection>sample</collection>
</collections>
<format>xml</format>
</options>)
-
サンプルデータ
その3/5 ファイルシステムからドキュメントをロードを参考にフォルダやデータを修正してください -
イメージ

その5/5 ①mlcp(MarkLogic Content Pump )②mlcpでCSV取り込み(一般ユーザ向け)
①mlcpでフォルダを指定して、複数データを投入
-
コマンド
C:\sample\mlcp-10.0.4\bin\mlcp.bat -options_file "C:\sample\sample_mlcp\mlcp-import-options.txt" -
options_fileの設定
import
-mode
local
-host
localhost
-port
8046
-username
admin
-password
admin
-input_file_path
C:\sample\sample_mlcp\files
-output_uri_replace
"/C:/sample,'hogehoge'"
-
サンプルデータ
その3/5 ファイルシステムからドキュメントをロードを参考にフォルダやデータを修正してください -
イメージ


②mlcpでフォルダを指定して、CSVデータを投入
- コマンド
C:\sample\mlcp-10.0.4\bin\mlcp.bat -options_file "C:\sample\sample_mlcp\mlcp-import-options2.txt"
- options_fileの設定
import
-mode
local
-host
localhost
-port
8046
-username
admin
-password
admin
-input_file_type
delimited_text
-input_file_path
C:\sample\sample_mlcp\csvfiles
-output_uri_prefix
/test/
-output_uri_replace
"/C:/sample,'hogehoge'"
-document_type
xml
- サンプルデータ
idの部分でURIが決まるので一意になるようにする必要があります。
重複すると上書きされます
id,word1,word2,word3
001,aaa,bbb,ccc
002,aaa,bbb,ddd
- イメージ

イメージの通り取り込みされました。

結論ですが、MLCPが一番高速なので5の利用をお勧めします。
MLCPを利用する場合、忘れずにマークロジックの管理画面でXDBCサーバの設定をしてください。
<提供されている全量はこちら>
- MarkLogic Content Pump:大量のドキュメントをデータベースに読み込むコマンドラインツール
- REST API:プログラミング言語に依存せずにデータベースにドキュメントを書き込む方法
- Java AP:Javaコードで使用する、データベースにドキュメントを書き込むためのJavaクラス
- Node.js API:Node.jsコードで使用する、データベースにドキュメントを書き込むためのNode.jsクラス
- XCC:Javaや.NETアプリケーションがMarkLogicデータベースにドキュメントを書き込む方法
- XQuery関数:Query ConsoleあるいはXQueryアプリから、データベースにドキュメントを書き込む方法
- JavaScript関数:Query ConsoleあるいはJavaScriptアプリから、データベースにドキュメントを書き込む
- WebDAV:ドキュメントをドラッグ&ドロップできます
- MarkLogic Connector for Hadoop:Hadoop MapReduceの入力元あるいは出力先としてMarkLogicを利用
- CPF(Content Processing Framework):パイプラインフレームワークで、データベースへの読み込み時にドキュメントを変換※MS OfficeやPDF形式ドキュメントのXMLへの変換など
以上です。