はじめに
これまでAzureを基盤とした生成AIの知識や技術に触れてきましたが、このたび初めて、AWSを基盤とする生成AIに取り組むことになりました。
まずは手始めに、AWSのFoundational(基礎)レベルの資格学習を通じてサービス名を少しずつ覚えつつ、先日は AWS Summit Japan 2025 に参加し、具体的な活用事例も拝見しました。
現在は無料利用枠でAWSアカウントを作成し、Amazon Bedrockを試しながら学習を継続しています。実際に手を動かして学ぶことで、AWSの使い方やAIサービスの構築方法を肌感覚で理解することを目標とし、そのアウトプットとして記事を作成していきたいと考えています。
構築・実行手順
このような操作イメージでBedrockにアクセスします
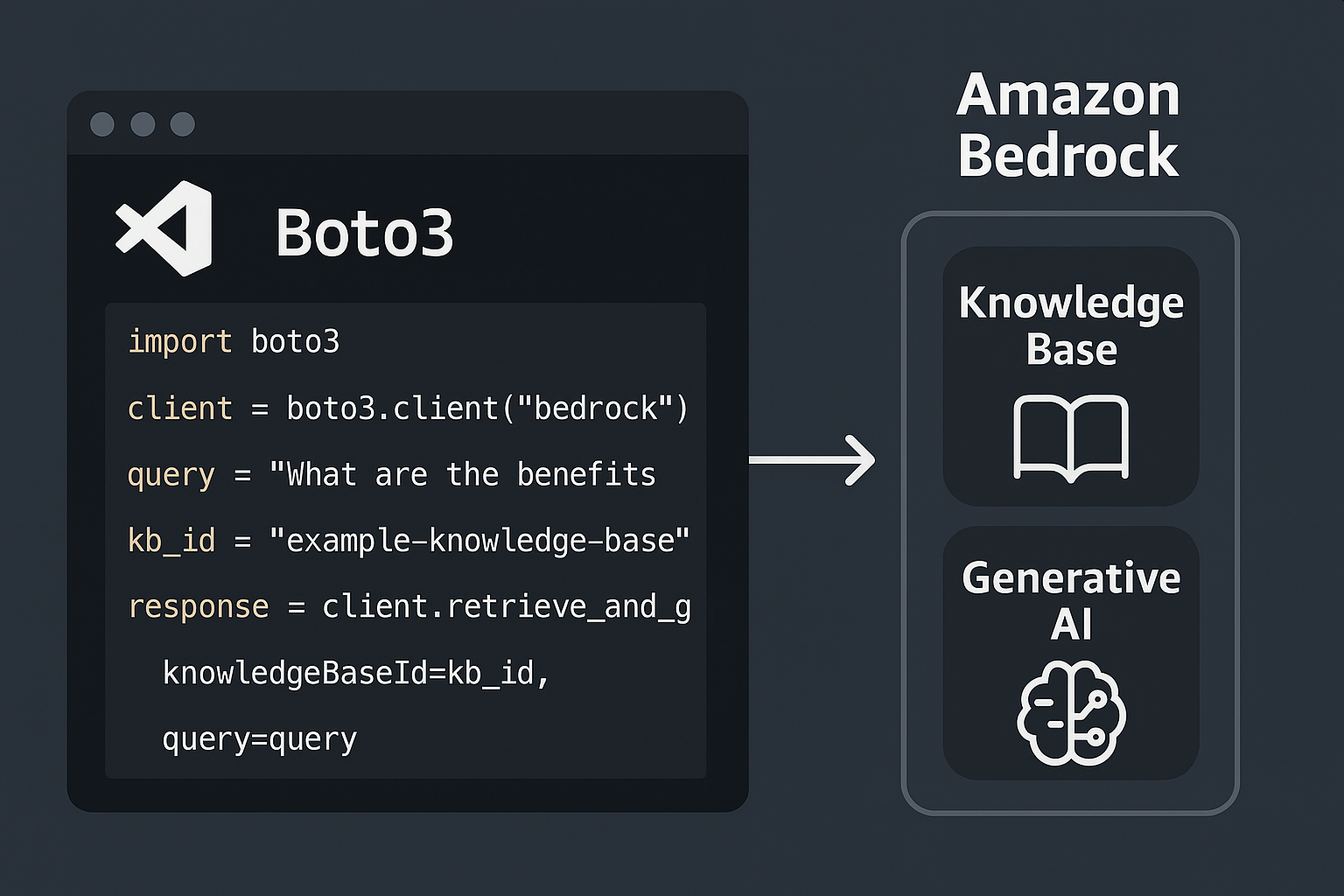
1.利用環境の準備: AWS アカウント作成
2025.7.15に、AWSの無料利用枠が刷新されました。新規ユーザーは、最大6か月間・最大200ドルのクレジットの範囲内で、追加費用なくAWSのサービスを試せます(Microsoft Azureの方式に近いですが、Azureは1か月のみ)。
●公式アナウンス
●実際に登録イメージはこちらの記事でご紹介されています。
2.利用環境の準備: ルートユーザのMFA設定
●AWSアカウントの作成が完了すると、AWS マネジメントコンソールにユーザー名(またはメールアドレス)とパスワードでログインできるようになります。ただし、このまま利用を続けるとアカウント乗っ取りのリスクが高いため、まず多要素認証(MFA)を有効化します。特にルートユーザーには必ずMFAを設定してください。
●コンソール右上のアカウント名(またはアカウントID)から「セキュリティ認証情報」を開くと、自分の認証情報画面が表示されます。中央付近の「多要素認証(MFA)」セクションから「MFA デバイスの割り当て」を実行します。選択肢は「パスキー/セキュリティキー」または「認証アプリケーション(例:Google Authenticator)」が簡単です。画面に表示されるQRコードを読み取れば登録完了です。

●少し画面レイアウトが古いかもしれませんが、こちらの記事でご紹介されています
https://qiita.com/ti_and6id/items/08f96d965aed0d85ae23
3.利用環境の準備: 一般ユーザアカウントの作成
●一般ユーザアカウントを作成します。
ルートユーザを使わずこの後の操作4,5を実行する為です。![]()
許可ポリシーはAdministratorAccessにします(適切な設定をして下さい)。
4.LLM利用開始の準備
●ざっくりやる事は以下の3点になります。
やること1: 生成AIモデルの有効化。Bedrockの左メニューから利用許可申請
![]() Anthropicなどリージョン単位に許可が必要です。
Anthropicなどリージョン単位に許可が必要です。
やること2: ナレッジベース作成する≒いわゆるRAGです、AuroraDBでOK。
![]() MSだといわゆるAzure AI Searchです。
MSだといわゆるAzure AI Searchです。
やること3: Bedrockのポリシーの作成≒通常のAWSサービス同様にIAM認証。![]()
![]() MSのサービス プリンシパルだと理解。
MSのサービス プリンシパルだと理解。
![]() Bedrockが2025.7にAPIキーを導入したが今回は未利用。
Bedrockが2025.7にAPIキーを導入したが今回は未利用。![]()
公式アナウンス:Amazon Bedrock が開発の効率化のために API キーを導入
APIキーの利用方法:BedrockのAPIキーについての諸々
【参考】1、2についてはこちらのハンズオン記事が大変参照になります
![]() CludShellベースで簡単にできるので、一通りやってみることを推奨します。
CludShellベースで簡単にできるので、一通りやってみることを推奨します。
【参考】3については3.3.2.2. ポリシーの作成をご参照ください。
【参考】ナレッジベースについて、LLMがラグを利用しているかどうかについては、
新しめの情報を組み込んであげると体感しやすいです。今回は楽曲情報をyoutube
から取得して、ラグを作成しています。
5.ローカルPC側の設定
●WindowsOS上で実行に必要なものをリストアップしました。インストールしてください。
| アプリケーション | 取得元 | 参考サイト | 備考 |
|---|---|---|---|
| Visual Studio Code | https://code.visualstudio.com/ | https://qiita.com/ucan-lab/items/e85931bf8276da43cc97 | GithubCopilotの利用を推奨 |
| Python | https://www.python.org/downloads/ | https://tenshoku.mynavi.jp/engineer/guide/articles/Z6HiFREAACcAuPTP | python --version >>Python 3.13.5 |
| Boto3 | $ pip install boto3 | https://qiita.com/kimihiro_n/items/f3ce86472152b2676004 | boto3 1.39.16 |
| dotenv | $ pip install python-dotenv | https://qiita.com/hedgehoCrow/items/2fd56ebea463e7fc0f5b | python-dotenv 1.1.1 |
警告
今回は省力化の為、グローバル環境にPIPでインストールしていますが、環境を分けたい場合はvenvで仮想環境を作成してください。Poetry等もおすすめです。
https://qiita.com/shun198/items/97483a227f288ad58112
6.実際にソースを書いて、実行してみる
では、実際にVSCodeにてナレッジベース&Bedrockを使用してみましょう。
フォルダ構成ですが、以下のようにしてください。.envが同じ階層にあればOK。
●XXproject
└sample1.py
└sample2.py
└.env
6-1.ナレッジベースを取得する
sample1.pyを作成し、実行してみます。
import boto3
from dotenv import load_dotenv
# AWSの認証情報を環境変数から読み込む
load_dotenv()
client = boto3.client('bedrock-agent-runtime')
response = client.retrieve(
# ナレッジベースのIDを指定
knowledgeBaseId='XXXXXXXXX',
retrievalQuery={
'text': '再会の特徴を教えてください'
}
)
print(response)
print('###############################')
for i, result in enumerate(response['retrievalResults']):
print(f"\n--- チャンク {i+1} ---")
print(result['content']['text'])
$ python sample1.pyを実行すると下記のような結果が返却されます。
ナレッジベースを参照し、スコアの高い5件のチャンクが取得できました。

6-2.ナレッジベースを使用した回答と使用しない回答の比較
sample2.pyを作成し、実行してみます。
ナレッジベースを利用した回答はこちらを参考に作成しています。
AWSの生成AIで社内文書検索! Bedrockのナレッジベースで簡単にRAGアプリを作ってみよう
ナレッジベースを利用しない回答はこちらを参考に作成しています。
【AWS】GitHub CodespacesとAWS SDKでClaude 3.5 Sonnetを実行してみる
メッセージコードの例
import boto3
import os
import json
import time
from dotenv import load_dotenv
from botocore.config import Config
# .envファイルを同じディレクトリに配置し、以下の内容を含めてください
#AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXX
#AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXX
# AWSの認証情報を環境変数から読み込む
load_dotenv()
# ナレッジベースを使った回答を取得するためのクライアントを作成
print('('#############')ナレッジベースを使った回答('#############')')
# Bedrock Agent Runtimeクライアントを作成
client = boto3.client('bedrock-agent-runtime')
# ナレッジベースから情報を取得して回答を生成
# ここでは、特定のナレッジベースIDとモデルARNを指定しています
response = client.retrieve_and_generate(
input={'text': '再会の特徴を教えてください'},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
# ナレッジベースのIDを指定
'knowledgeBaseId': 'XXXXXXXXXXXXXXXXXX',
# 使用するモデルのARNを指定
# ここでは、AnthropicのClaude 3.5 Sonnetモデルを使用しています
'modelArn': 'arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0'
}
}
)
# レスポンスから生成されたテキストを取得して表示
print(response['output']['text'])
# ナレッジベースを使わない回答を取得するためのクライアントを作成
print('#############ナレッジベースを使わない回答('#############')
retries_config = Config(
retries={
# 最大リトライ回数を指定
# 'max_attempts'は最大リトライ回数を指定します
# ここでは10回のリトライを設定しています
'max_attempts': 10,
# リトライモードを指定
# 'standard'はデフォルトのリトライモード
# 'adaptive'は適応型リトライモード ※こちらはうまくいきませんでした
'mode': 'standard'
}
)
# Bedrock Runtimeクライアントを作成
client = boto3.client("bedrock-runtime",config=retries_config)
# リクエストボディをJSON形式で作成
# ここでは、AnthropicのClaude 3.5 Sonnetモデルを使用してユーザーの質問に答える設定をしています
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"system": "あなたの仕事はユーザーの質問に答えることです。",
"messages": [
{
"role": "user",
"content": "再会の特徴を教えてください"
}
]
})
# 使用するモデルのIDを指定
# ここでは、AnthropicのClaude 3.5 Sonnetモデルを使用しています
model_id = "anthropic.claude-3-5-sonnet-20240620-v1:0"
# モデルを呼び出して回答を取得
# invoke_modelメソッドを使用して、指定したモデルにリクエストを送信します
response = client.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
# レスポンスのボディを読み取り、JSON形式に変換
# レスポンスから生成されたテキストを取得して表示
if response.get("body"):
res_body = json.loads(response["body"].read())
if res_body.get("content"):
answer = res_body["content"][0].get("text")
print(answer)
else:
print("レスポンスにcontentがありません")
else:
print("レスポンスのボディがありません!")
$ python sample2.pyを実行すると下記のような結果が返却されます。
ナレッジベースを使った回答では質問者の意図に沿った回答が作成できていますね。

以上です。ご精読頂きありがとうございました。
本記事内のリンク先について執筆の参考にさせていただきました。有難うございました。