はじめに
AIや機械学習に興味を持ち始めた頃、線形代数の知識やpython独特の記法やライブラリを使った解説ではいまいち腹落ちしなかった記憶があります。
本記事では線形代数の知識が無い方、python初心者向けになるべく平易に3層ニューラルネットワークの実現方法を解説したつもりです。
私も機械学習は勉強中&pythonはprogateのみで実務経験なしなので、至らない点がございましたらお気軽に編集リクエスト頂けますと幸いです。
3層ニューラルネットワークのアイデア
脳の中にはニューロンと呼ばれる細胞が無数にあり、ニューロンどうしはお互いにシナプスによってつながり合って巨大なネットワークを作っています。
外界からの刺激を受けて、ニューロンは電気刺激を他のニューロンに伝えます。受け取ったニューロンは、その刺激がある閾値を超えると発火してさらに次のニューロンに刺激を伝えます。この連続で、ニューラルネットワークは複雑な情報処理を行っています。

ニューロンは、電気刺激の入力を受け取る樹状突起、出力を他のニューロンに伝えるシナプス、刺激を伝送する軸索から構成されます。ニューロンに伝わる電気刺激の合計が閾値を超えた場合は後続のニューロンに電気刺激を伝達します。出力する刺激の強さは入力値にかかわらずほぼ一定となります。このことを全か無かの法則と呼びます。

米国の心理学者Frank Rosenblattがこの仕組みを数理モデル化して、単純パーセプトロンと呼ばれるシンプルなニューラルネットワークを考案しました。
単純パーセプトロンは、一つのニューロンを数式で模したもので、下記の数式で表されます。
$$ y = \sum_{ i=1 }^{ n } x_i w_i $$
f(y) = \left\{
\begin{array}{ll}
1 & (y \gt \theta) \\
0 & (y \leq \theta)
\end{array}
\right.
各入力$x_i$の値に、それぞれの樹状突起の太さに見立てた$w_i$を掛けた値が閾値$\theta$を超えると1が出力され、超えないと0が出力されます。
その後、単純パーセプトロンを組み合わせた形の3層構造を持つニューラルネットワークが考案されました。

単純パーセプトロンは簡単な問題しか解けないことが判明していますが、3層構造を持つニューラルネットワークは任意の連続関数を近似できることが証明されています。
普遍近似定理 (Cybenko (1989)など)
ニューラルネットワークは、⼗分な数のパラメタがあれば、連続関数を任意の精度で近似できる。
普遍性定理について詳しく知りたい方は下記の記事で詳しく解説されているので読んでみてください。
まずは2層のニューラルネットから
3層ニューラルネットワークから隠れ層(2層目)を取り除いた形のモデルです。3層ニューラルネットワークよりシンプルで理解がしやすいため、まずは2層のニューラルネットモデルを理解していきます。
下記の図のような構成のモデルです。

数式の理解
1. 入力値と重みの積の合計uを求める
u = \sum_{i=0}^{n} x_iw_i \quad \cdots \quad 全てのiに対して入力x_iと重みw_iをかけたものを足す
通常、Xは入力データの次元数より一つ多い次元数で用意しておき、余った一つには1を設定します。これにより、ニューラルネットのバイアス(入力データに依存しないパラメータ)を作成することが出来ます。
u = x_0w_0 + x_1w_1 + x_2w_2 \quad \cdots \quad 上記の図に合わせて書くとこんな感じ
2. uを活性化関数f(u)に入れる
yp = f(u) \quad \cdots \quad 得られたypは入力がx_0...x_nだった時の予測される出力
活性化関数と呼ばれる非線形な関数を使うことで、モデルの表現力を上げることが出来ます。
3. 教師データytとypの二乗誤差Lを計算する
L = \frac{1}{2} (yp - yt)^2 \quad \cdots \quad ypとytの差を二乗して2で割った値を二乗誤差Lとする
モデルによる予測値ypと真の値ytが近ければLは小さくなる。2乗しているため、Lの最小値は0になる。
一般的なニューラルネットワークモデルでは、この二乗誤差を小さくしていくことでだんだんとypをytに近づけていく。
4. 二乗誤差Lを各ニューロンの重みwで微分する
\displaylines{
\frac{\partial L}{\partial w_i} =
\frac{\partial L}{\partial yp} \cdot \frac{\partial yp}{\partial w_i} \\
= \frac{\partial L}{\partial yp} \cdot \frac{\partial yp}{\partial w_i} \\
= (yp - yt) \cdot x_i \cdot f^{\prime}(u)
}
二乗誤差Lを極小化したいので、Lに勾配降下法を適用します。
Lはn個の$w_i$をパラメータとする関数なので、Lをi番目の$w_i$のみをパラメータとする関数と考え、その他のwを定数と考えるとLを$w_i$で微分できます。この考え方を、偏微分といいます。
5. wを更新する
w_i = w_i - \alpha * \frac{\partial L}{\partial w_i}
前述の勾配降下法に従って$w_i$を更新します。$\alpha$は学習率と呼ばれる値で、一回の学習で修正される量を決定しています。$\alpha$は大きすぎると正確な結果を得るのが難しくなり、小さすぎると学習完了までにかかる時間が増えていきます。
手順1~5を繰り返し、二乗誤差が一定の値以下になるか、あらかじめ決めておいたステップ数繰り返した後手順を終了します。
2層のニューラルネットワークの実装
行列積やライブラリを使うともっとシンプルに実装できますが、理解を妨げないためになるべく数式そのままに実装しています。
import numpy as np
from matplotlib import pyplot
# 活性化関数(シグモイド関数)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 活性化関数の微分
def sigmoid_derivative(x):
return (1 - sigmoid(x))*sigmoid(x)
# 学習ステップ数
STEP = 1000
# 学習率
alpha = 0.5
# 入力データ
data = [
[0, 0],
[1, 0],
[0, 1],
[1, 1],
]
# 教師データ(ANDゲート)
yt = [0, 0, 0, 1]
# 入力データ末尾にダミー変数を追加
x = np.insert(data, 2, 1, axis=1)
# ニューロンの重みをランダムに初期化
w1 = np.random.rand(3)
# 各ステップごとの二乗誤差を格納する配列
L = np.zeros(STEP)
# 学習
for step in range(STEP):
# 各入力データに対してループ
for k in range(4):
u = 0.0
# 入力値と重みの積の合計uを求める
for i in range(3):
u += x[k][i]*w1[i]
# uを活性化関数f(u)に入れる
yp = sigmoid(u)
# 各ステップごとの二乗誤差を格納
L[step] += ((yp - yt[k])**2)/2
# 二乗誤差Lを各ニューロンの重みwで微分し、wを更新する
for i in range(3):
w1[i] -= alpha * (yp - yt[k]) * sigmoid_derivative(u) * x[k][i]
# 学習結果の確認
for k in range(4):
u = 0.0
for i in range(3):
u += x[k][i]*w1[i]
yp = sigmoid(u)
print(f'入力: {data[k]}, 予測値: {yp:.2f}, 真の値: {yt[k]}')
# STEPごとの誤差の出力
pyplot.plot(L)
pyplot.show()
実行結果
入力: [0, 0], 予測値: 0.00, 真の値: 0
入力: [1, 0], 予測値: 0.08, 真の値: 0
入力: [0, 1], 予測値: 0.08, 真の値: 0
入力: [1, 1], 予測値: 0.90, 真の値: 1
入力データに合わせた予測値が出力できています。
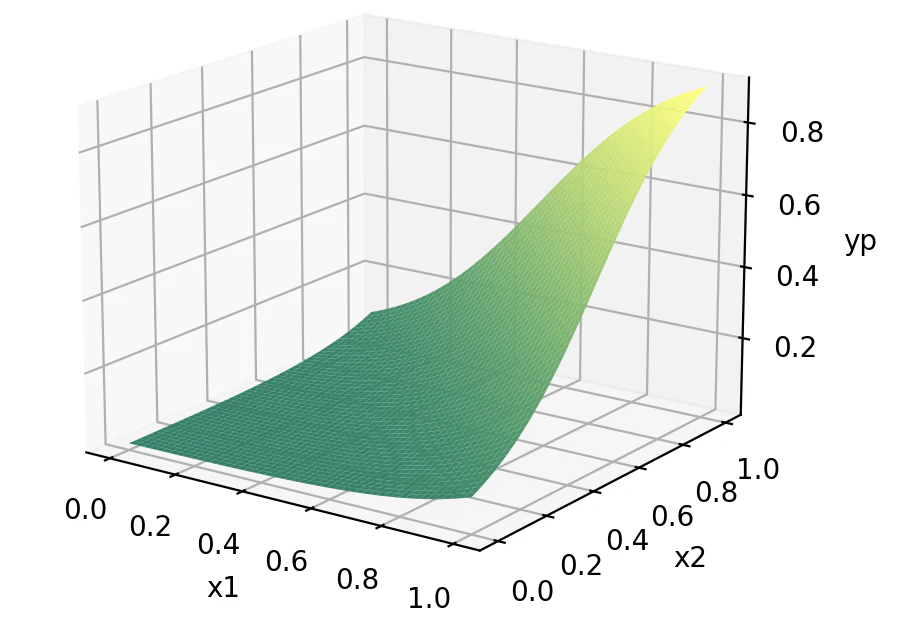
x1, x2を0から1まで変化させた時のypを3Dグラフにしてみると下の図のようになります。
3Dグラフを描画するコード(折りたたまれています)
from matplotlib import pyplot as plt
def predict(x1, x2):
print(x1)
u = x1*w1[0] + x2*w1[0] + w1[2]
return sigmoid(u)
# Figureと3DAxeS
fig = plt.figure()
ax = fig.add_subplot(111, projection="3d")
# (x,y)データを作成
x = np.linspace(0, 1, 50)
y = np.linspace(0, 1, 50)
# 格子点を作成
X, Y = np.meshgrid(x, y)
# 各x1,x2に対応するypの計算
Z = predict(X, Y)
# 曲面を描画
ax.plot_surface(X, Y, Z, cmap = "summer")
# 軸ラベルを設定
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_zlabel('yp')
plt.title('3D Plot of Neural Network Output')
plt.show()
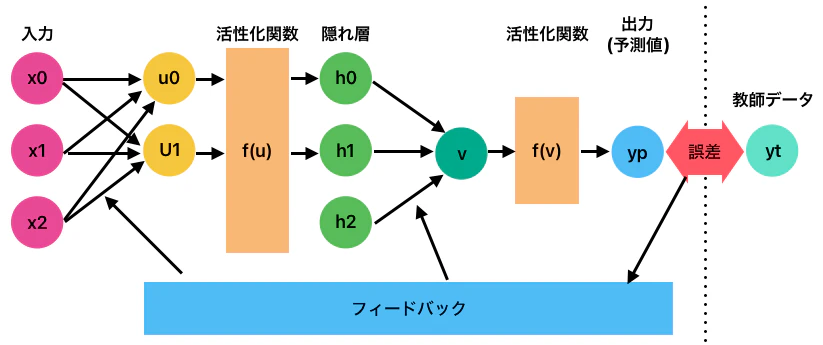
3層ニューラルネットワーク
2層のニューラルネットワークの入力層と出力層の間に、隠れ層と呼ばれる層を一層追加したモデルです。
数式の理解
1. 入力値と重みの積の合計を求める
u_j = \sum_{i=0}^{n} x_iw^{first}_{ij}
隠れ層のノードの内、j番目のノードの値は上記の式で決まります。$w^{first}_{ij}$は一層目と二層目の間の重みのうち、i番目の入力$x_i$とj番目の隠れ層$u_j$の間にあるものです。全ての隠れ層の値を上記の式で求めたら手順2に移ります。
2. uを活性化関数f(u)に入れる
h_j = f(u_j)
3. hを入力にして二層目と三層目の間にある重みとの積の和を求める
v = \sum_{j=0}^{m} h_jw^{second}_{j}
$w^{second}_{j}$は二層目と三層目の間の重みです。
4. vを活性化関数f(v)に入れる
yp = f(v)
5. 教師データytとypの二乗誤差Lを計算する
L = \frac{1}{2} (yp - yt)^2
6. 二乗誤差Lを各ニューロンの二層目と三層目の間の重みで微分する
\displaylines{
\frac{\partial L}{\partial w^{second}_j} =
\frac{\partial L}{\partial yp} \cdot \frac{\partial yp}{\partial w^{second}_j} \\
= (yp - yt) \cdot x_i \cdot f^{\prime}(u)
}
7. 二乗誤差Lを各ニューロンの一層目と二層目の間の重みで微分する
\displaylines{
\frac{\partial L}{\partial w^{first}_{ij}} =
\frac{\partial L}{\partial yp} \cdot \frac{\partial yp}{\partial w^{first}_{ij}} \\
= \frac{\partial L}{\partial yp} \cdot \frac{\partial yp}{\partial h_j} \cdot \frac{\partial h_j}{\partial w^{first}_{ij}}\\
= (yp - yt) \cdot f^{\prime}(v) \cdot w^{second}_j \cdot x_i \cdot f^{\prime}(u_j)
}
8. 全てのwを更新する
w^{second}_j = w^{second}_j - \alpha * \frac{\partial L}{\partial w^{second}_j}
w^{first}_{ij} = w^{first}_{ij} - \alpha * \frac{\partial L}{\partial w^{first}_{ij}}
3層のニューラルネットワークの実装
import numpy as np
from matplotlib import pyplot as plt
STEP = 2000
alpha = 0.5
# 隠れ層の数
hidden_layers = 3
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return (1 - sigmoid(x))*sigmoid(x)
data = [
[0, 0],
[1, 0],
[0, 1],
[1, 1],
]
yt = [0, 1, 1, 0]
x = np.insert(data, 2, 1, axis=1)
u = np.zeros(hidden_layers-1)
h = np.ones(hidden_layers)
# ニューロンの重みをランダムに初期化
w1 = np.random.rand(3, hidden_layers-1)
w2 = np.random.rand(hidden_layers)
L = np.zeros(STEP)
for step in range(STEP):
for k in range(4):
# 入力層→隠れ層
for j in range(hidden_layers - 1):
u[j] = 0.0
for i in range(3):
u[j] += x[k][i]*w1[i][j]
h[j] = sigmoid(u[j])
# 隠れ層→出力層
v = 0.0
for j in range(hidden_layers):
v += h[j]*w2[j]
y = sigmoid(v)
L[step] += (y - yt[k])**2
# 重みの更新
delta_output = (y - yt[k]) * sigmoid_derivative(v)
for j in range(hidden_layers):
w2[j] -= alpha * delta_output * h[j]
for j in range(hidden_layers-1):
delta_hidden = delta_output * w2[j] * sigmoid_derivative(u[j])
for i in range(3):
w1[i][j] -= alpha * delta_hidden * x[k][i]
# 学習結果の確認
for k in range(4):
for j in range(hidden_layers - 1):
u[j] = 0.0
for i in range(3):
u[j] += x[k][i]*w1[i][j]
h[j] = sigmoid(u[j])
v = 0.0
for j in range(hidden_layers):
v += h[j]*w2[j]
yp = sigmoid(v)
print(f'入力: {data[k]}, 予測値: {yp:.2f}, 真の値: {yt[k]}')
# STEPごとの誤差の出力
plt.plot(L)
plt.show()
実行結果
入力データに合わせた予測値が出力できています。
入力: [0, 0], 予測値: 0.08, 真の値: 0
入力: [1, 0], 予測値: 0.92, 真の値: 1
入力: [0, 1], 予測値: 0.92, 真の値: 1
入力: [1, 1], 予測値: 0.07, 真の値: 0
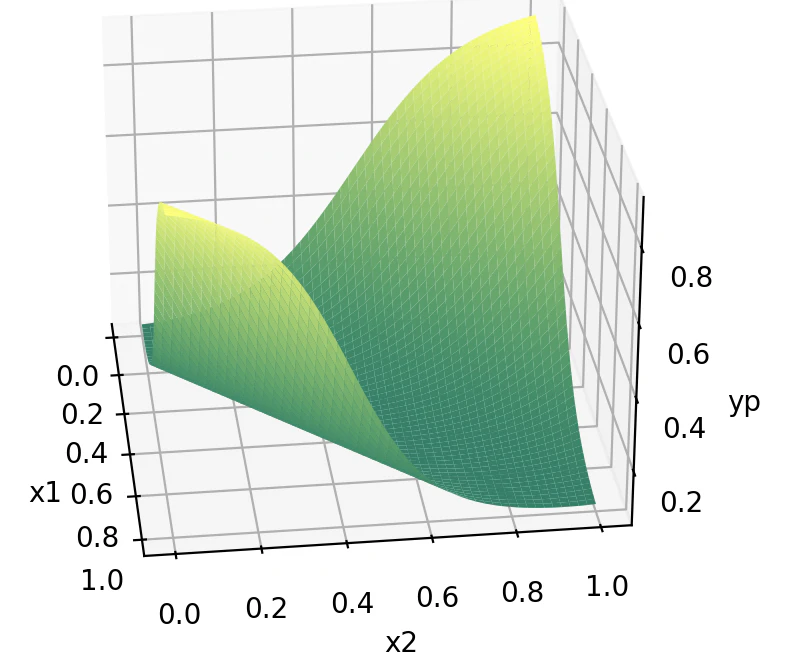
x1, x2を0から1まで変化させた時のypを3Dグラフにしてみると下の図のようになります。
参考文献
赤石 雅典 著 『最短コースで分かる ディープラーニングの数学』 日経BP (2019/4/15)