Google BigQueryにデータをimport/exportするときに、私はApache Avro形式のファイルを使っています。
Avro形式は、データだけでなくテーブルのスキーマ情報も持つので、テーブル作成のデータソースとしてjsonやcsvより便利です。
また、バイナリファイルなのでjsonやcsvよりも高速に処理できるそうです。
BigQueryへのimport用にAvroファイルを作成するとき、私はfastavroを使用して以下のようなPythonコードを書いています。
下記コードでは変数名SCHEMA内のfields配列に各列の情報を入れているのですが、本記事では BigQueryのそれぞれの型に対応するPythonコードの書き方を、わかる範囲でまとめてみました。
(記述に誤りがありましたらご指摘くださいませ)
import traceback
import fastavro
from pathlib import Path
SCHEMA = {
"type": "record",
"name": "Root",
"fields": [
{
"name": "id",
"type": "long",
},
{
"name": "rating",
"type": "long",
},
{
"name": "title",
"type": "string",
},
{
"name": "comment",
"type": "string",
}
]
}
DATA = [
{
"id": 1,
"rating": 5,
"title": "最高です",
"comment": "感動しました"
},
{
"id": 2,
"rating": 4,
"title": "良いです",
"comment": "気に入りました"
}
]
def main():
out_dir = Path.cwd()
out_path = out_dir / "foo.avro"
with open(out_path, "wb") as fo:
writer = fastavro.write.Writer(fo, SCHEMA)
for rec in DATA:
writer.write(rec)
writer.flush()
if __name__ == "__main__":
try:
main()
except Exception:
print(traceback.format_exc())
それでは型マッピングの一覧です。
BIGNUMERIC型とGEOGRAPHY型は、試した結果よくわからない結果になったので、割愛しました。
なお、全体を通じて "name" に設定する値は任意です。
プリミティブ型
モード=REQUIRED
タイプ=STRING
-
BigQuery

-
Python
{
"name": "col_string",
"type": "string"
},
タイプ=BYTES
-
BigQuery

-
Python
{
"name": "col_bytes",
"type": "bytes"
},
タイプ=INTEGER
-
BigQuery

-
Python
{
"name": "col_integer",
"type": "long"
},
タイプ=FLOAT
-
BigQuery

-
Python
{
"name": "col_float",
"type": "double"
},
タイプ=NUMERIC
-
BigQuery

-
Python
{
"name": "col_numeric",
"type": {
"type": "bytes",
"logicalType": "decimal",
"precision": 38,
"scale": 9
}
},
タイプ=BOOLEAN
-
BigQuery

-
Python
{
"name": "col_boolean",
"type": "boolean"
},
タイプ=TIMESTAMP
-
BigQuery

-
Python
{
"name": "col_timestamp",
"type": {
"type": "long",
"logicalType": "timestamp-millis"
}
}
{
"name": "col_timestamp",
"type": {
"type": "long",
"logicalType": "timestamp-micros"
}
},
タイプ=DATE
-
BigQuery

-
Python
{
"name": "col_date",
"type": {
"type": "int",
"logicalType": "date"
}
},
ただし、DATE型をBigQueryからavroファイルに出力するとstring型になる。
タイプ=TIME
-
BigQuery

-
Python
{
"name": "col_time",
"type": {
"type": "long",
"logicalType": "time-micros"
}
},
ただし、TIME型をBigQueryからavroファイルに出力するとstring型になる。
タイプ=DATETIME
-
BigQuery

-
Python
{
"name": "col_datetime",
"type": {
"type": "long",
"logicalType": "local-timestamp-millis"
}
},
{
"name": "col_datetime",
"type": {
"type": "long",
"logicalType": "local-timestamp-micros"
}
},
ただし、DATETIME型をBigQueryからavroファイルに出力するとstring型になる。
タイプ=JSON
-
BigQuery

-
Python
{
"name": "col_json",
"type": {
"type": "string",
"sqlType": "JSON"
}
},
モード=REQUIRED以外
モード=NULLABLE
-
BigQuery

-
Python
{
"name": "col_string_nullable",
"type": [
"null",
"string"
],
"default": null
},
モード=REPEATED
-
BigQuery

-
Python
{
"name": "col_string_repeated",
"type": {
"type": "array",
"items": "string"
}
},
レコード型
タイプ=RECORD、モード=REQUIRED
-
BigQuery

-
Python
{
"name": "col_record",
"type": {
"type": "record",
"namespace": "root",
"name": "Col_Record",
"fields": [
{
"name": "col_record_1",
"type": "string"
},
{
"name": "col_record_2",
"type": "string"
}
]
}
},
タイプ=RECORD、モード=NULLABLE
-
BigQuery

-
Python
{
"name": "col_record_nullable",
"type": [
"null",
{
"type": "record",
"namespace": "root",
"name": "Col_Record_Nullable",
"fields": [
{
"name": "col_record_1",
"type": "string"
},
{
"name": "col_record_2",
"type": "string"
}
]
}
],
"default": null
}
タイプ=RECORD、モード=REPEATED
-
BigQuery

-
Python
{
"name": "col_record_repeated",
"type": {
"type": "array",
"items": {
"type": "record",
"namespace": "root",
"name": "Col_Record_Repeated",
"fields": [
{
"name": "col_record_1",
"type": "string"
},
{
"name": "col_record_2",
"type": "string"
}
]
}
}
},
以上の型マッピングの情報を用いて、実際にPythonコードを書いてみます。
Avroファイルを作って BigQuery に import してみる
以下のPythonコードを実行して Avroファイルを作ります。
import traceback
import fastavro
from pathlib import Path
import time
import datetime
from decimal import *
SCHEMA = {
"type": "record",
"name": "Root",
"fields": [
{
"name": "col_string",
"type": "string"
},
{
"name": "col_bytes",
"type": "bytes"
},
{
"name": "col_integer",
"type": "long"
},
{
"name": "col_float",
"type": "double"
},
{
"name": "col_numeric",
"type": {
"type": "bytes",
"logicalType": "decimal",
"precision": 38,
"scale": 9
}
},
{
"name": "col_boolean",
"type": "boolean"
},
{
"name": "col_timestamp_millis",
"type": {
"type": "long",
"logicalType": "timestamp-millis"
}
},
{
"name": "col_timestamp_micros",
"type": {
"type": "long",
"logicalType": "timestamp-micros"
}
},
{
"name": "col_date",
"type": {
"type": "int",
"logicalType": "date"
}
},
{
"name": "col_time",
"type": {
"type": "long",
"logicalType": "time-micros"
}
},
{
"name": "col_datetime_millis",
"type": {
"type": "long",
"logicalType": "local-timestamp-millis"
}
},
{
"name": "col_datetime_micros",
"type": {
"type": "long",
"logicalType": "local-timestamp-micros"
}
},
{
"name": "col_json",
"type": {
"type": "string",
"sqlType": "JSON"
}
},
{
"name": "col_string_nullable",
"type": [
"null",
"string"
],
"default": None
},
{
"name": "col_string_repeated",
"type": {
"type": "array",
"items": "string"
}
},
{
"name": "col_record",
"type": {
"type": "record",
"namespace": "root",
"name": "Col_Record",
"fields": [
{
"name": "col_record_1",
"type": "string"
},
{
"name": "col_record_2",
"type": "string"
}
]
}
},
{
"name": "col_record_nullable",
"type": [
"null",
{
"type": "record",
"namespace": "root",
"name": "Col_Record_Nullable",
"fields": [
{
"name": "col_record_1",
"type": "string"
},
{
"name": "col_record_2",
"type": "string"
}
]
}
],
"default": None
},
{
"name": "col_record_repeated",
"type": {
"type": "array",
"items": {
"type": "record",
"namespace": "root",
"name": "Col_Record_Repeated",
"fields": [
{
"name": "col_record_1",
"type": "string"
},
{
"name": "col_record_2",
"type": "string"
}
]
}
}
}
]
}
def main():
out_dir = Path.cwd()
out_path = out_dir / "foo.avro"
with open(out_path, "wb") as fo:
writer = fastavro.write.Writer(fo, SCHEMA)
writer.write({
"col_string" : "string",
"col_bytes" : b"abc",
"col_integer" : -1234567890,
"col_float" : 3.14,
"col_numeric" : Decimal("123.456"),
"col_boolean" : True,
"col_timestamp_millis" : datetime.datetime(2022, 1, 2, 3, 4, 5, 6),
"col_timestamp_micros" : datetime.datetime(2022, 1, 2, 3, 4, 5, 6),
"col_date" : datetime.date(2022, 1, 2),
"col_time" : time.time() * 1_000_000,
"col_datetime_millis" : datetime.datetime(2022, 1, 2, 3, 4, 5, 6),
"col_datetime_micros" : datetime.datetime(2022, 1, 2, 3, 4, 5, 6),
"col_json" : '{"key": 1, "value": "あ"}',
"col_string_nullable" : None,
"col_string_repeated" : ["a", "b", "c"],
"col_record" : {"col_record_1":"A", "col_record_2":"B"},
"col_record_nullable" : None,
"col_record_repeated" : [{"col_record_1":"A", "col_record_2":"B"},{"col_record_1":"C", "col_record_2":"D"}]
})
writer.flush()
if __name__ == "__main__":
try:
main()
except Exception:
print(traceback.format_exc())
実行すると foo.avro が生成されました。
以下のコマンドを使って BigQuery にロードします。
bq load \
--replace \
--source_format=AVRO \
--use_avro_logical_types \
--project_id=example_project \
example_dataset.foo \
./foo.avro
以下のように、意図したスキーマで fooテーブルが作成されました。
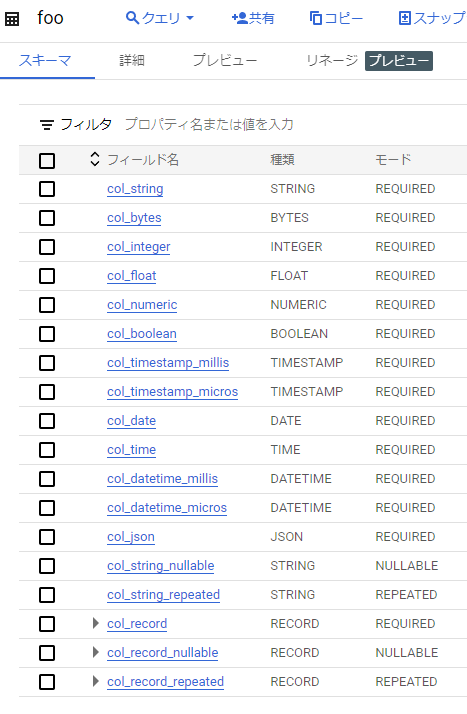
fooテーブルのデータを見てみます。


Pythonコードで設定したデータがロードされているようです。