はじめに
最近、RAG(Retrieval-Augmented Generation)の進化系として Graph RAG (Knowledge Graph RAG) が注目されていますね。
「グラフ構造を使うと精度が上がるらしいけど、実装が難しそう...」と感じている方も多いのではないでしょうか。
今回は、DifyとローカルLLM環境を用いて、グラフDBと連携したRAGシステムを実際に構築してみたいと思います!
システムの全体像から、Docker構成、FastAPIによるバックエンド実装、そしてNeo4jのCypherクエリまで、順を追って丁寧に解説していきます。
対象読者
- Difyで一歩進んだRAG(Graph RAG)を試してみたい方
- グラフデータベース(Neo4j)とLLMをどう連携させるのか興味がある方
- ローカル環境(Docker)で手軽にRAGシステムを動かしてみたい方
この記事でわかること
- アーキテクチャ: Dify, Neo4j, FastAPI, Ollamaを組み合わせたGraph RAGの全体像
- 実装コード: PDFからデータを投入し、検索するまでの具体的なロジック
- クエリ: ベクトル検索とグラフ探索を組み合わせたCypherクエリの書き方
1. システムアーキテクチャ
まずは全体の構成を見てみましょう。
本システムは完全ローカル環境(Docker)で動作する構成を目指しました。
コンポーネント構成
それぞれの役割は以下の通りです。
| コンポーネント | 技術スタック | 役割 |
|---|---|---|
| UI / Workflow | Dify | チャット画面やRAGのワークフローを管理します。 |
| Backend API | FastAPI | 検索やデータ投入のロジックを実行する司令塔です。Difyからのリクエストをここで受け取ります。 |
| Graph DB | Neo4j | 論文データ(Paper)とチャンク(Chunk)をグラフ構造として保存します。ベクトル検索もここで行います。 |
| LLM | Ollama | 最終的な回答生成を行うローカルLLM(Llama 2など)です。 |
| Embedding | Sentence-Transformers | テキストをベクトル(数値の列)に変換するモデルです。 |
2. インフラ構築 (Docker Compose)
開発環境の再現性を確保するため、サービスをDocker Composeで定義しています。
これなら docker compose up 一発で環境が立ち上がるので便利ですよね。
docker-compose.yml
name: graph-rag-mvp
services:
neo4j:
image: neo4j:5.26.0-community
container_name: neo4j
restart: unless-stopped
ports:
- "7474:7474"
- "7687:7687"
environment:
NEO4J_AUTH: neo4j/${NEO4J_PASSWORD:-testpassword}
volumes:
- neo4j_data:/data
- neo4j_logs:/logs
- neo4j_plugins:/plugins
networks:
- rag-net
knowledge-api:
build:
context: ../knowledge-api
dockerfile: Dockerfile
container_name: knowledge-api
restart: unless-stopped
ports:
- "8000:8000"
environment:
NEO4J_URI: bolt://neo4j:7687
NEO4J_USER: ${NEO4J_USER:-neo4j}
NEO4J_PASSWORD: ${NEO4J_PASSWORD:-testpassword}
EMBED_MODEL_NAME: ${EMBED_MODEL_NAME:-sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2}
CHUNK_SIZE: ${CHUNK_SIZE:-800}
CHUNK_OVERLAP: ${CHUNK_OVERLAP:-100}
TOP_K: ${TOP_K:-5}
VECTOR_DIM: ${VECTOR_DIM:-384}
MAX_FILE_SIZE_MB: ${MAX_FILE_SIZE_MB:-50}
INDEX_NAME: ${INDEX_NAME:-chunk_embedding_index}
CANDIDATE_MULTIPLIER: ${CANDIDATE_MULTIPLIER:-5}
CANDIDATE_OFFSET: ${CANDIDATE_OFFSET:-20}
EXTERNAL_KB_API_KEY: ${EXTERNAL_KB_API_KEY:-my-dify-kb-key}
depends_on:
- neo4j
volumes:
- knowledge_data:/app/data
networks:
- rag-net
ollama:
image: ollama/ollama:latest
container_name: ollama
profiles:
- ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
networks:
- rag-net
volumes:
neo4j_data:
neo4j_logs:
neo4j_plugins:
knowledge_data:
ollama_data:
networks:
rag-net:
name: graph-rag-mvp-net
環境変数の設定項目
設定ファイルでよく使う変数は以下の通りです。
| 変数名 | 設定値例 | 説明 |
|---|---|---|
NEO4J_URI |
bolt://neo4j:7687 |
Dockerネットワーク内のサービス名を指定して接続します。 |
EMBED_MODEL_NAME |
sentence-transformers/... |
Hugging Faceのモデル名です。自動でダウンロードされるので楽ちんです。 |
VECTOR_DIM |
384 |
Embeddingモデルの次元数です。インデックス作成時に必要になります。 |
EXTERNAL_KB_API_KEY |
my-dify-kb-key |
Difyと連携するための合言葉(APIキー)です。 |
2.5 Difyの起動とネットワーク連携
Dify本体は公式のDocker Composeを利用して起動し、Graph RAG用のコンテナ群とはネットワーク経由で連携させます。
手順
-
Difyの取得と起動:
git clone https://github.com/langgenius/dify.git cd dify/docker docker compose up -d -
ネットワークの疎通確認:
-
Docker Desktop (Mac/Windows):
host.docker.internalを使うことで、Difyコンテナからホスト上のポート(Graph RAG APIの8000番)にアクセスできます。特別なネットワーク設定は不要です。 -
Linux:
host.docker.internalがデフォルトでは使えないため、docker-compose.ymlでextra_hostsを設定するか、DifyとGraph RAGのコンテナを同じDockerネットワークに参加させる必要があります。
-
Docker Desktop (Mac/Windows):
今回は最も手軽な Docker Desktop環境 を前提とし、Difyから http://host.docker.internal:8000 でAPIにアクセスする構成として解説を進めます。
3. 実装詳細:データ投入 (Ingestion)
ここからは実装の中身に入っていきます。
まずはPDFからテキストを抽出し、グラフ構造としてNeo4jに格納するプロセス(Ingestion)です。
処理フロー
-
PDF解析:
PyMuPDFを使ってテキストを抽出します。 - チャンク分割: 長い文章を一定文字数(例: 800文字)で分割します。文脈が切れないように、少しだけ前後を被らせる(オーバーラップ)のがコツです。
- ベクトル化: Sentence-Transformersでテキストをベクトルに変換します。
-
グラフ格納:
PaperノードとChunkノードを作成し、それらを線で繋ぎます。
グラフ構造モデル
今回はシンプルに、以下のような親子関係からスタートします。
-
Nodes:
(:Paper),(:Chunk) -
Relation:
(:Paper)-[:HAS_CHUNK]->(:Chunk)
イメージとしては、「論文(Paper)」という親が、複数の「断片(Chunk)」という子供を持っているような構造ですね。
4. 実装詳細:検索 (Retrieval)
次に、検索プロセスです。
Difyからのリクエストを受け、Neo4jに対してハイブリッド検索(ベクトル + グラフ)を実行します。
Cypherクエリ(検索ロジック)
ここがGraph RAGの肝となる部分です!
ベクトル検索で「意味が近いチャンク」を見つけ、そこからグラフを辿って「親の論文情報」を取得します。
// 1. ベクトルインデックス検索
CALL db.index.vector.queryNodes($index_name, $k_candidates, $query_embedding)
YIELD node, score
// 2. フィルタリング(スコア閾値など)
WHERE score >= $min_score
// 3. グラフパターンマッチ(Chunk -> Paper)
MATCH (p:Paper)-[:HAS_CHUNK]->(node)
// 4. 結果返却
RETURN p.paper_id AS paper_id,
p.title AS title,
node.text AS text,
score
ORDER BY score DESC
LIMIT $top_k
拡張性(引用関係の検索)
後からクエリを変えるだけで検索ロジックを拡張できるようにします。
例えば、将来的に「引用されている論文も一緒に探したい!」となった場合は、以下のようにクエリを書き足すだけでOKです。
// 引用論文も同時に取得する例
MATCH (p:Paper)-[:HAS_CHUNK]->(node)
OPTIONAL MATCH (p)-[:CITES]->(cited_paper:Paper)
RETURN p.title, cited_paper.title, ...
データ構造を大きく変えずにロジックを進化させられるのは、グラフDBならではの強みと言えると思います。
5. API実装 (FastAPI)
Difyの「External Knowledge API」仕様に合わせたエンドポイントを実装します。
エンドポイント仕様
-
URL:
POST /retrieval - Auth: Bearer Token
-
Response:
records配列を含むJSON
実装コード例
from fastapi import FastAPI, Header
from pydantic import BaseModel
app = FastAPI()
class RetrievalRequest(BaseModel):
knowledge_id: str
query: str
@app.post("/retrieval")
def retrieval(
request: RetrievalRequest,
authorization: str | None = Header(default=None)
):
# 1. 認証
if authorization != f"Bearer {settings.API_KEY}":
return {"error": "Unauthorized"}, 401
# 2. 検索実行 (Neo4j)
results = run_graph_rag_search(request.query)
# 3. Dify形式へ整形
records = []
for row in results:
records.append({
"content": row["text"],
"score": row["score"],
"metadata": {
"source": row["title"],
"paper_id": row["paper_id"]
}
})
return {"records": records}
Neo4j ベクトルインデックスの自動生成
アプリ起動時に「インデックスあるかな?」と確認し、なければ自動で作るロジックを入れておくと便利です。
def ensure_index(driver, dim):
query = f"""
CREATE VECTOR INDEX chunk_embedding_index IF NOT EXISTS
FOR (c:Chunk) ON (c.embedding)
OPTIONS {{ indexConfig: {{
`vector.dimensions`: {dim},
`vector.similarity_function`: 'cosine'
}}}}
"""
driver.execute_query(query)
6. Dify連携設定
最後に、Dify側の設定です。
手順
-
外部ナレッジAPIの登録:
-
[ナレッジ] > [外部ナレッジ連携 API] を開きます。
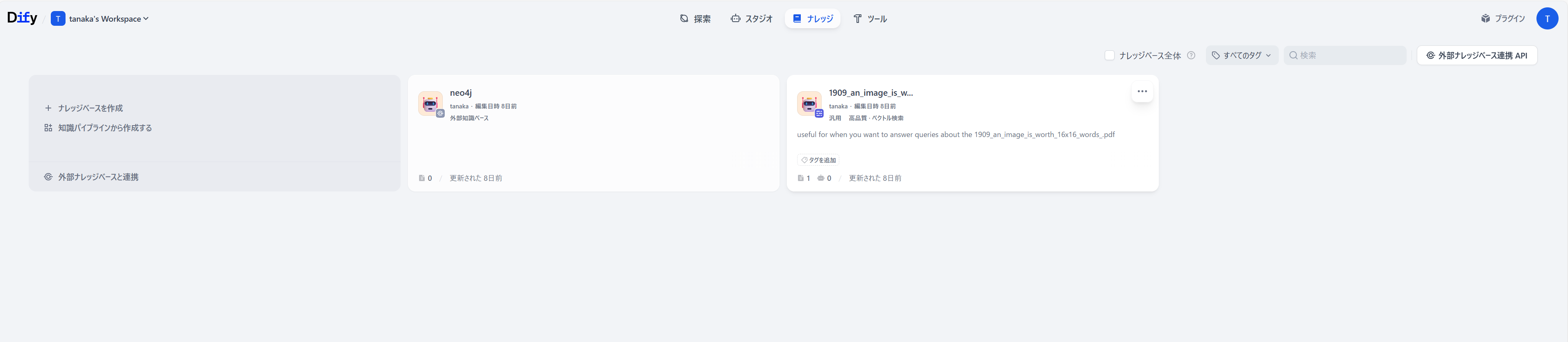

-
外部ナレッジベースAPIを追加をクリックします。
-
Name、エンドポイント、APIキーを指定します。
- Name: 任意の名前
- Endpoint:
http://knowledge-api:8000(FastAPIのエンドポイントを指定する。IPアドレスはコンテナサービス名のknowledge-apiを指定する。) - API Key:
my-dify-kb-key(composeで設定した環境変数の値を指定する。)
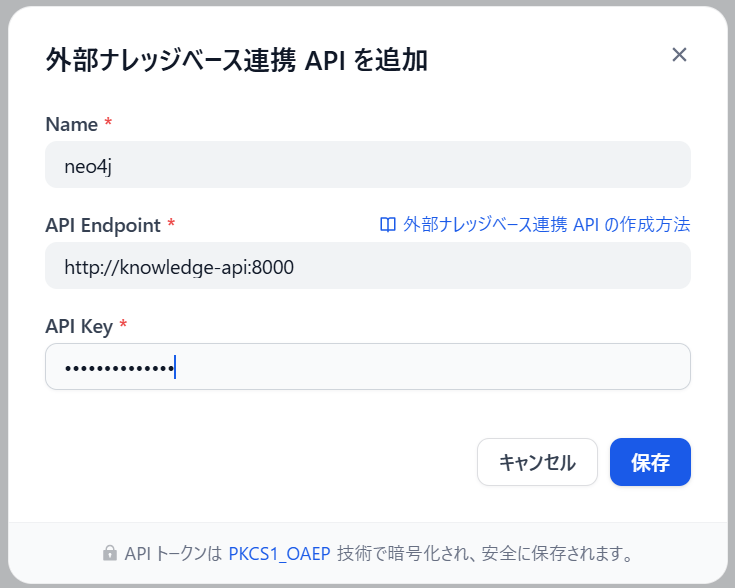
-
正常に連携ができると外部連携が追加されます。
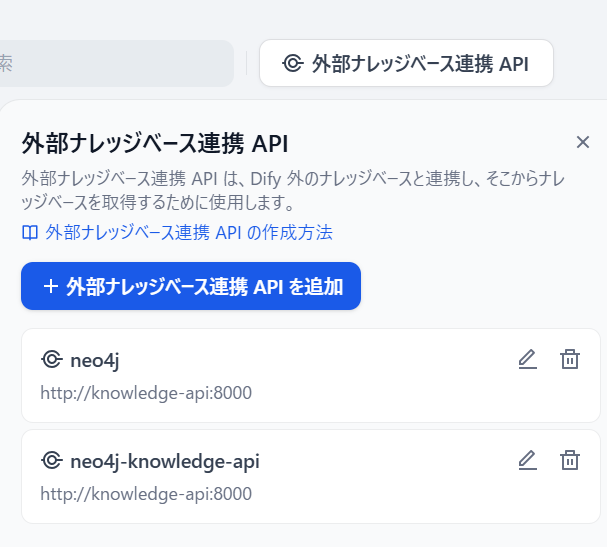
-
-
外部ナレッジ連携APIをワークフローで呼び出す:
- 知識検索のノードを追加します。
- ナレッジベースで先ほど追加した外部ナレッジベースを指定すれば完了です。
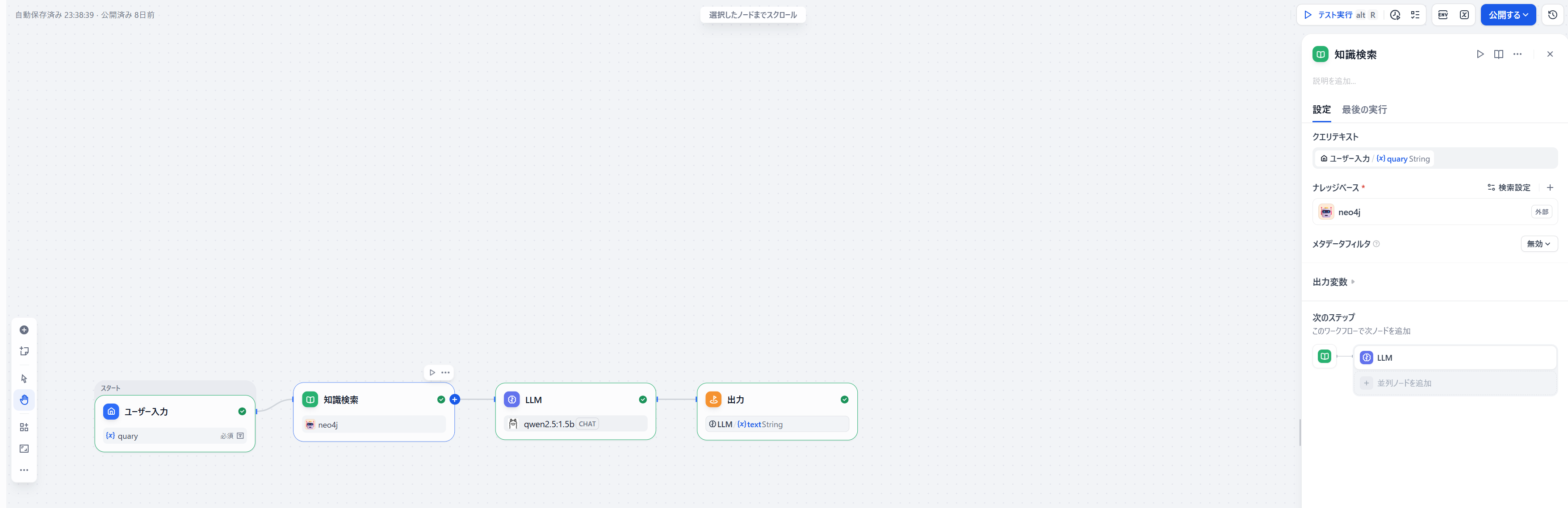
まとめ
今回は、DifyとNeo4jを組み合わせてGraph RAGを実装する方法について解説しました。
- Graph RAGのメリット: 文脈(論文間の関係性など)を保持した検索が可能になります。
- 構成: Dify (UI) + FastAPI (Logic) + Neo4j (DB) という疎結合なアーキテクチャを採用しました。
- 拡張: クエリベースで検索ロジックを柔軟に変更・拡張できるのが大きな魅力です。
少しハードルが高そうに見えるGraph RAGですが、こうして分解してみると意外とシンプルに実装できることが分かります。
ぜひ皆さんも、この機会にGraph RAGの世界に足を踏み入れてみてください!