NetAppでSales Specialistをしている小寺です。
S3アクセスポイントをサポートしたアップデートに関わるブログも終盤です。

ローンチブログではQuickSuite、Bedrockが取り上げられていましたが、今日はONTAPのデータをS3ポイントを経由して、Athenaからクエリを実行したみたいと思います。
事前準備
(1) FSx for ONTAPからS3アクセスポイントを作成しておきます。

(2) Athenaからアクセスするので、S3アクセスポイントのアクセスポリシーを指定します。
最初は権限を絞っていたのですが、Athenaからのテーブル作成時にアクセス権限エラーが出てしまい、フルを指定しています。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowAthenaFullS3Access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<AWSアカウントID>:<ユーザ名>"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:us-east-1:<AWSアカウントID>:accesspoint/my-s3-access-point",
"arn:aws:s3:us-east-1:<AWSアカウントID>:accesspoint/my-s3-access-point/object/*"
],
"Condition": {
"StringEquals": {
"aws:PrincipalArn": "arn:aws:iam::<AWSアカウントID>:role/AthenaQueryRole"
}
}
}
]
}
(3) クエリ用のサンプルデータをFSx for ONTAPに格納します。
Athenaのクエリ保存設定
(1) Athenaのクエリエディタからクエリ保存先のS3を指定します。
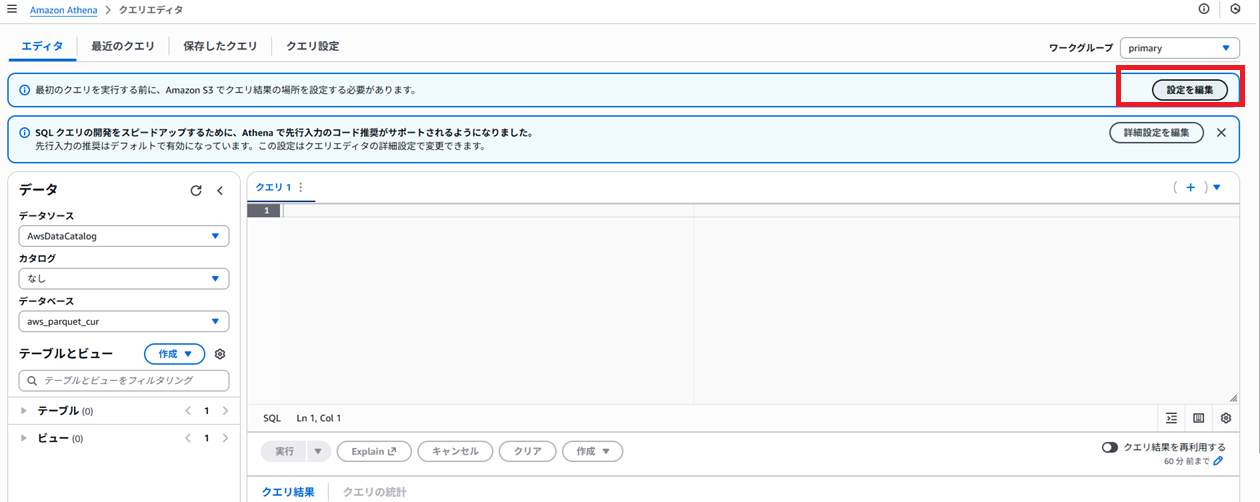
(2) S3バケットを指定します。クエリ結果の書き込みのため、チェックボックスにチェックも入れます。
(3) クエリ設定が保存されました。
Athenaのテーブル作成
(1) クエリエディタの「テーブルとビュー」で「作成」から「S3バケットデータ」を選びます。

(2) 「S3 バケットデータからテーブルを作成」画面にて、テーブル名を入力します。

データセットにS3アクセスポイントのエイリアスを入力します。

ファイル形式は「CSV」とします。

列の設定を行います。

(3) テーブル作成を行います。
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`ontap_table` (
`No` int,
`prefecture` string,
`year` int,
`population` string,
`populationmen` int,
`populationwomen` int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://my-s3-access-poi-uxxdxoggrxtp891ngejc5zht78h64use1b-ext-s3alias/'
TBLPROPERTIES ('classification' = 'csv');
クエリを実行してみます
今回は、年代別、男女別の人口のデータです。
SELECT year, population
from ontap_table
where year IN (1970, 1980);
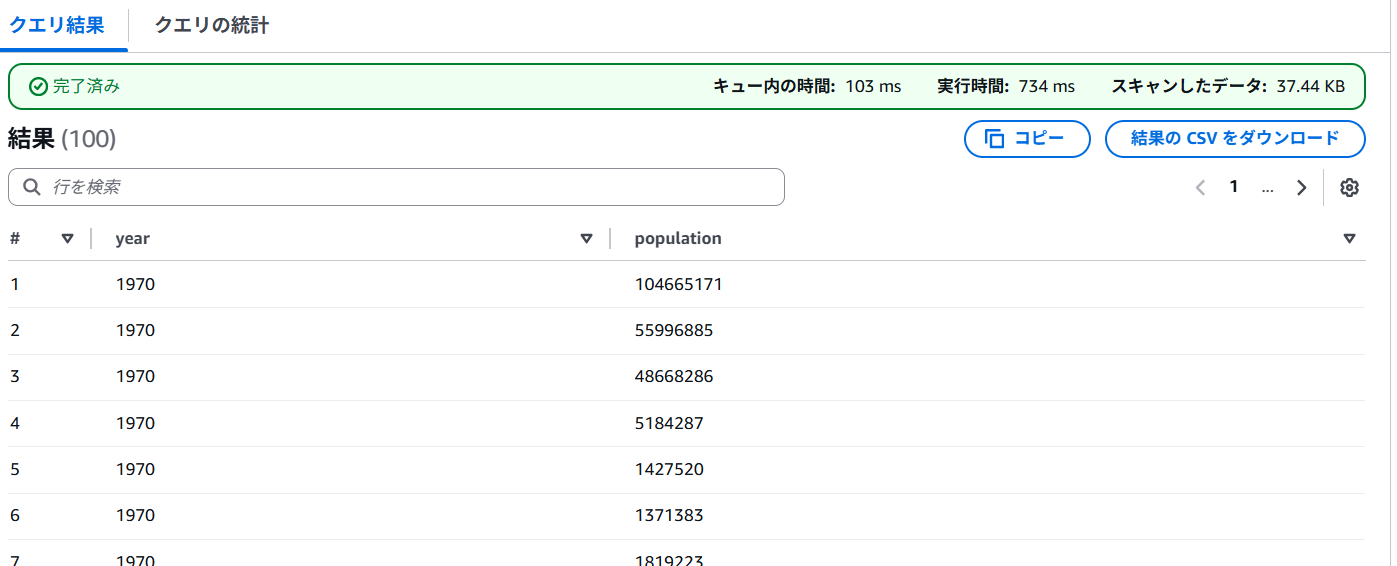
ONTAPに保存したデータに対してもS3アクセスポイントを経由して、クエリを実行できるようになりました。
データをS3に移動することなく、Athenaからデータへアクセスすることができます。
ぜひ試してみてください!