NetAppでSales Specialistをしている小寺です。
今日は、Amazon FSx for NetApp ONTAPに保管されたデータをUpstage AIのDocument Parseでデータ抽出を行う方法についてお伝えします。
※ネットアップとUpstage AIは技術的な協業のため、戦略的MOUを締結しております。
https://prtimes.jp/main/html/rd/p/000000010.000159603.html
Document Parseの特長
Document Parseの特長は以下の通りです。
・多様なドキュメント形式に対応
PDF、JPEG/PNG/BMP/TIFF/HEICなどのスキャン画像、Office文書(DOCX/PPTX/XLSX)から処理可能。
日本語にも対応している。
・レイアウト要素の高精度検出
段落・見出し・表・画像・図・チャート・数式など、文書構造を保ったHTML/Markdown形式で出力。
Table Structure Recognition (TSR) により、罫線がない表やセル結合も正確に検出。
表や図が複数ページにまたがるケースでは、マルチページ表の統合処理も可能(nightly版)
高速かつスケーラブル
同期APIでは 1ページあたり約0.6秒(構造化精度:5%向上)で解析可能とのことで、非同期APIなら 最大1,000ページ/50MBまで対応しています。
REST API & インテグレーション対応
REST API経由で構造化HTML/Markdownを取得可能。
AWS Marketplace、SageMaker JumpStart、オンプレミスでも導入可能。 [aws.amazon.com], [upstage.ai]
LLMやRAGワークフローとの統合を前提に設計されており、企業システムへの組み込みが容易
検証する環境
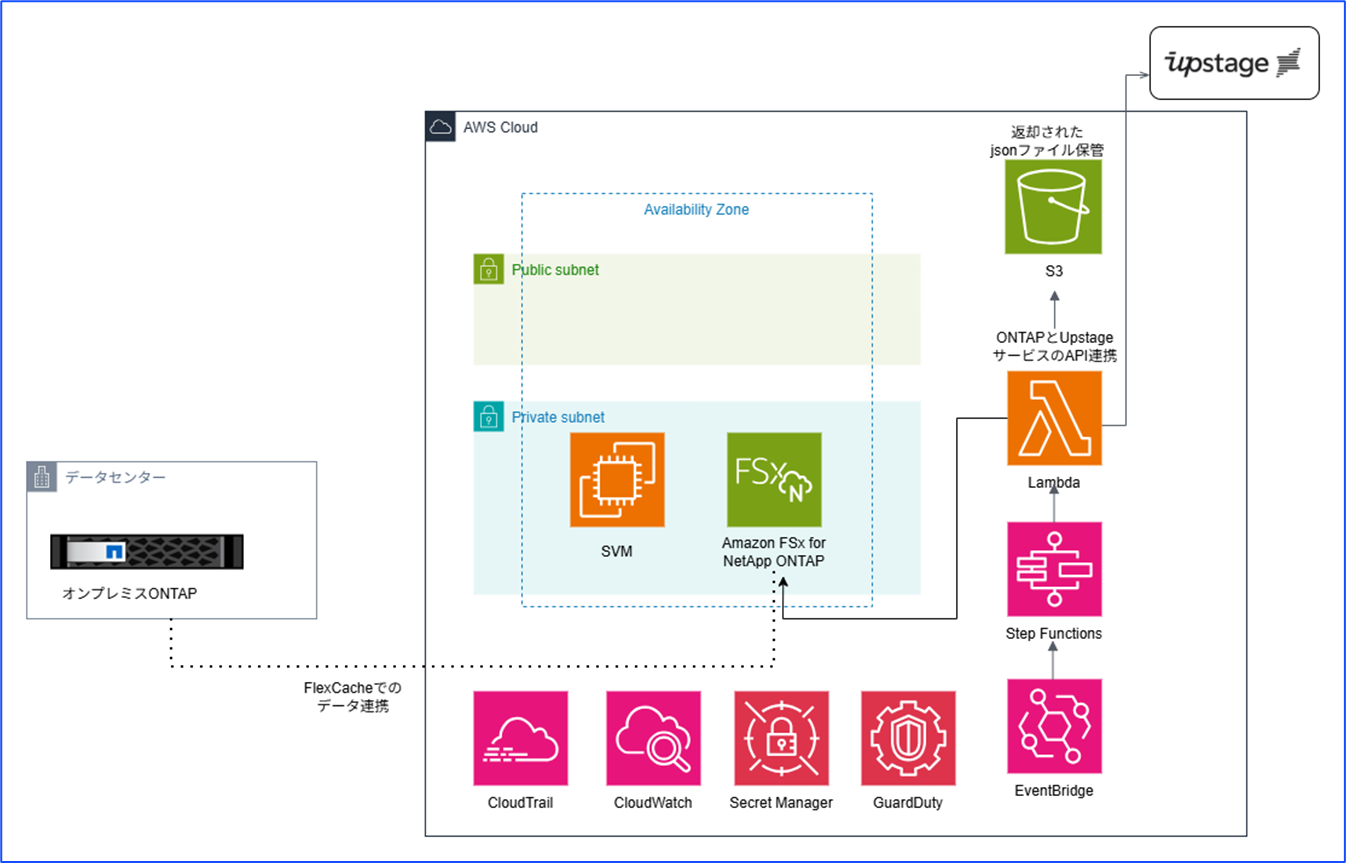
検証するファイルをAmazon FSx for NetApp ONTAPに保管し、S3アクセスポイントを作っておきます。
最初の想定アーキは以下です。S3アクセスポイントがリリースされたので、Lambdaからアクセスポイント経由でデータへアクセスします。
リリース前まではLambdaからは直接FSx for ONTAPをマウントできないため、EC2上でPythonを実行していましたが、リンプルな構成で実行できるようになっています。
同期APIで最大100ページ、非同期APIで最大1,000ページまで処理可能なので、処理を順番に行う際にStep Funcstionsを使う想定です。
APIでInformation Extractionを実行
事前準備
(1) Amazon FSx for NetApp ONTAPに検証用データを格納します。
(2) Fsx for ONTAPのS3アクセスポイントを作ります。
(3) APIキーをUpstageコンソールのダッシュボードから作成します。

サンプルPDF
サンプルファイルを利用しました。
Lambdaの設定
(1) 設定からS3アクセスポイントへ接続できるようにロールを追加します。
合わせて、S3アクセスポイントのアクセスポイントポリシーにもファイルの読み取りができるよう設定します。
(2) requestモジュールを使うので、Layerを作成する必要があります。
外部モジュールを入れたものをzipファイルにして、AWSマネジメントコンソールからアップロードします。
# -*- coding: utf-8 -*-
import os
import io
import json
import boto3
import requests
S3 = boto3.client("s3")
# 環境変数
UPSTAGE_API_URL = os.getenv("UPSTAGE_API_URL", "https://api.upstage.ai/v1/document-digitization")
UPSTAGE_API_KEY = os.getenv("UPSTAGE_API_KEY")
UPSTAGE_MODEL = os.getenv("UPSTAGE_MODEL", "document-parse") # 安定版。必要なら document-parse-nightly
def handler(event, context):
alias = event.get("alias") or os.getenv("FSXN_S3_ALIAS")
key = event.get("key")
if not (alias and key and UPSTAGE_API_KEY):
raise ValueError("alias/key/UPSTAGE_API_KEY のいずれかが未設定です。")
# 1) PDFをFSxN S3アクセスポイント(alias)から取得
pdf_bytes = get_s3_object(alias, key)
# 2) Upstage Document Parse(同期API)へ送信
resp_json = call_document_parse(pdf_bytes)
# 3) レスポンスをそのまま保存(HTMLとelements)
content = resp_json.get("content", {})
html = content.get("html", "")
elements = resp_json.get("elements", [])
base = os.path.splitext(os.path.basename(key))[0] # 例: 10.pdf -> 10
out_prefix = f"parsed/{base}/"
saved = {}
if html:
put_bytes(alias, f"{out_prefix}{base}.html", html.encode("utf-8"))
saved["html_key"] = f"{out_prefix}{base}.html"
# elements はサイズが大きくなる場合があるので必要なときだけ保存する
# ここでは保存しますが、不要ならこのブロックをコメントアウトしてください。
put_bytes(alias, f"{out_prefix}{base}.elements.json",
json.dumps(elements, ensure_ascii=False).encode("utf-8"))
saved["elements_key"] = f"{out_prefix}{base}.elements.json"
# レスポンス全体(デバッグ用)も残す場合
put_bytes(alias, f"{out_prefix}{base}.response.json",
json.dumps(resp_json, ensure_ascii=False).encode("utf-8"))
saved["response_key"] = f"{out_prefix}{base}.response.json"
return {"saved_prefix": out_prefix, **saved}
def get_s3_object(bucket_alias, key):
"""FSxN S3 Access Point の alias をバケット名として使用"""
r = S3.get_object(Bucket=bucket_alias, Key=key)
return r["Body"].read()
def call_document_parse(pdf_bytes):
"""Upstage Document Parse(同期API)呼び出し(HTMLを返す)"""
headers = {"Authorization": f"Bearer {UPSTAGE_API_KEY}"}
files = {"document": ("document.pdf", io.BytesIO(pdf_bytes), "application/pdf")}
data = {
"ocr": "force", # スキャンや日本語PDFを確実に処理したい場合は force が無難
"model": UPSTAGE_MODEL, # 安定版: document-parse / 最新機能: document-parse-nightly
"output_formats": "html" # content.html を返す
# "mode": "enhanced" # 複雑表や画像が多い場合(nightly利用時)
}
resp = requests.post(UPSTAGE_API_URL, headers=headers, files=files, data=data, timeout=60)
resp.raise_for_status()
return resp.json()
def put_bytes(bucket_alias, key, data):
S3.put_object(Bucket=bucket_alias, Key=key, Body=data)
結果
サンプルPDF P13の図です。

HTML結果です。
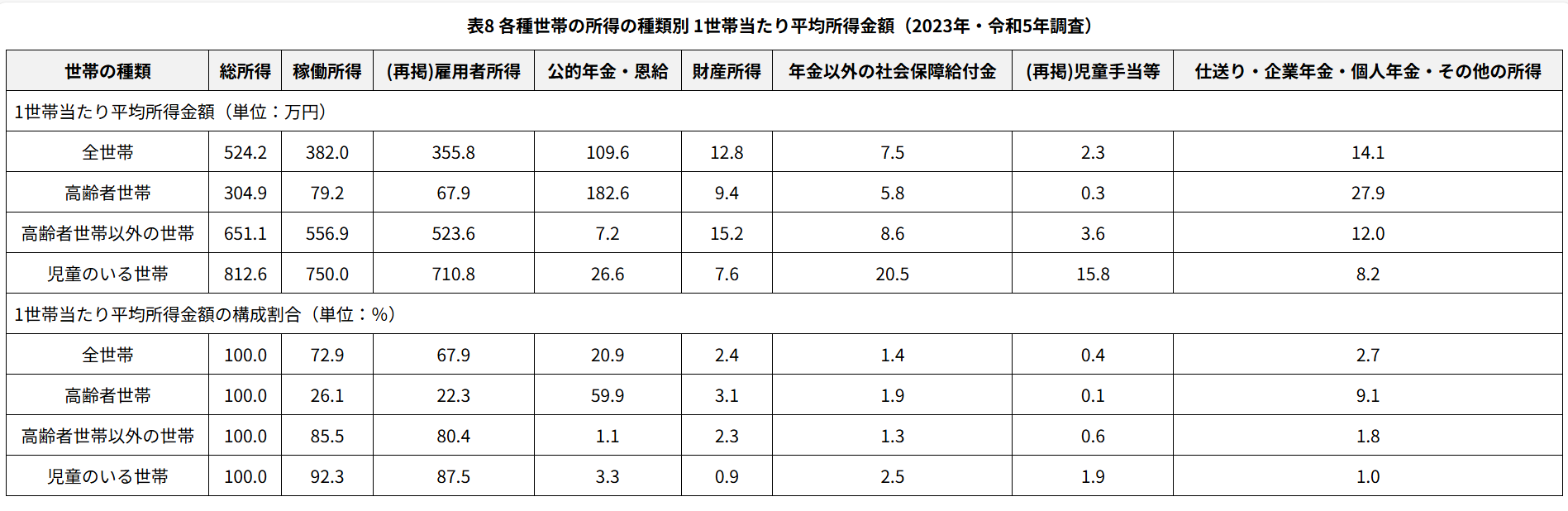
数字等正しく情報が抽出できています。
ドキュメントを処理する際に、表形式の構造が崩れずに処理が正しくできています。
もう少しサンプルを増やして、結果をアップデートしていければと思います。