はじめに
大量データをクラウドに格納してデータ分析に利用してみようと思い、
速い・安いと言われるGoogleCloudPlatform(GCP)のBigQueryを触ってみた…
かったのですが、以下の記事にもあるように予想外に課金されてしまった事例を小耳に挟んでいたため二の足を踏んでいました。
BigQueryのコストに対する恐怖心を払拭すべく公式ドキュメントを料金面にフォーカスして読み解き、
不用意に大量課金されないよう気をつける点をまとめたのが本記事となります。
今後も改定される可能性もありますので、利用の際にはご自身でも確認していただければと思います。
また、情報が誤っていた場合はご指摘いただければ幸いです。
課金される操作
BigQueryで課金される内容は
・ストレージ代金
・データ操作代金
です。単純ですね。
ただし、データ操作は回数だけではなく、扱うデータ量・操作方法に応じて課金額が異なります。
利用時に気をつける事
必要以上の課金を抑える為に以下に気をつければ良いと感じました。
各項目について順に説明を行います。
1.データの読込方法を検討する
2.不要なデータを扱うクエリを実行しない
3.理解した上でHigh-Computeクエリを実行する
4.分割テーブルやデコレータを利用して対象を絞る
5.費用管理を行い課金上限を設定しておく
6.不安な場合はdry runを実行し、データ処理量を確認する
BigQueryとはなにか
そもそもBigQueryについてざっくり説明すると、ペタバイト以上のデータであっても高速でSQLクエリを実行することが出来るデータウェアハウスです。Googleの潤沢なインフラを用いて大量のデータを格納し、素早く取り出すことができます。用途としてはデータ分析に特化していると言えます。
データは様々な言語のクライアントライブラリを用いて利用することができます。
GCPの一つであるCloud Datalabなどと連携して扱うこともあります。
料金一覧
はじめに標準料金におけるストレージとデータ操作における料金一覧です。
大容量(月$10,000以上など)使用する利用者向けに定額料金もあるそうですが、
以降本記事では標準料金について言及します。
| 操作 | コスト | メモ |
|---|---|---|
| ストレージ | GB あたり $0.02/月 | MB あたり、秒あたりで案分。100 MB を半月格納した場合、支払い額は $0.001 |
| 長期保存 | GB あたり $0.01/月 | テーブル毎、パーティション毎に編集有無を計測。90日以上データが編集(追加・削除)されていない場合。 |
| ストリーミング インサート | GB あたり $0.05 | データを1行づつ読み込む場合にかかる費用。最小サイズ1KBで各行を計算。 |
| クエリ | TB あたり $5 | 毎月 1 TB まで無料。SQL コマンドとユーザー定義関数の実行が対象。エラー返却やキャッシュから返却されたクエリは対象外。 |
| データの読み込み | 無料 | Google Cloud Storage からCSV、JSON(改行区切り)、Avro ファイル、Google Cloud Datastore バックアップを読み込む場合。 |
| データのコピー | 無料 | BigQuery内のテーブルのコピー操作 |
| データのエクスポート | 無料 | BigQuery内のデータのエクスポート操作 |
| メタデータ オペレーション | 無料 | list、get、patch、update、delete の呼び出し。 |
データを用いて分析を行う際に課金が発生するコンセプトのように感じました。このことはupdateなどメタデータオペレーションの割当ポリシーとして2秒に1回しか実行することができないことに現れていると思います。
BigQueryの用途としてトランザクション管理やマスタ管理などではなく、データ分析のためのデータ格納という考え方であるからでしょう。
【参考】
https://cloud.google.com/bigquery/pricing?hl=ja
次項から気をつける点をドキュメントと照らし合わせながら一つづつ説明してきます。
データの読み込み方法を検討する
データ読み込みは3パターンありますが、パターンに応じて課金のされ方が異なります。
①Google Cloud Storage(GCS)から読み込む
②データストリームで読み込む
③データを直接投入

①についてはBigQueryとしての料金は無料です。
が、クラウドストレージサービスであるGCSについてストレージ料金とGCS→BigQueryのデータ転送料金が別途かかります。
(但しデータ転送料金については Cloud Storage バケット と Google Cloud Platform サービスが同じロケーションまたはサブロケーションにある場合、無料になると記載があります)
速度について制限が無いのであればGCSにはgzipでアップロードしておけばBigQuery読み込みの際には解凍するようにトランスコーディングすることで容量節約することができるでしょう。
②はストリーミングインサートを用いるためGBあたり$0.05が発生するため恒常的に利用する場合は少し注意が必要です。
1行づつインサートしていくのでリアルタイムで分析をする場合は良い方法だと思います。
③ではBigQueryのウェブUIを用いてJSON形式などのデータを読み込みます。BigQueryとしての料金は無料です。
ただし、読み込み速度が遅いとの情報もあります。
(どなたかのサイトで拝見したのですが、失念してしました…)
【参考】
https://cloud.google.com/storage/pricing?hl=ja
【ポイント】
データ転送料金が無料になる(GCSとBigQueryが同じロケーションにある)ならばGCSへ格納した後、BigQueryへ読み込んだほうが良いかと思います。
ただし、サービスで利用しつつデータを追加していきたい場合などリアルタイム性が必要であれば課金してでもストリーミングインサートを用いる必要があると思います。
クエリ実行時のデータ処理容量
料金一覧を見てわかるように、ストレージは比較的安い値段に設定されています。(1TBだとしても$20/1ヶ月)想定外に大量課金されるのはクエリ実行によるものではないでしょうか。
クエリ実行の料金は MB 単位のデータ処理容量(端数は四捨五入)で決まります。
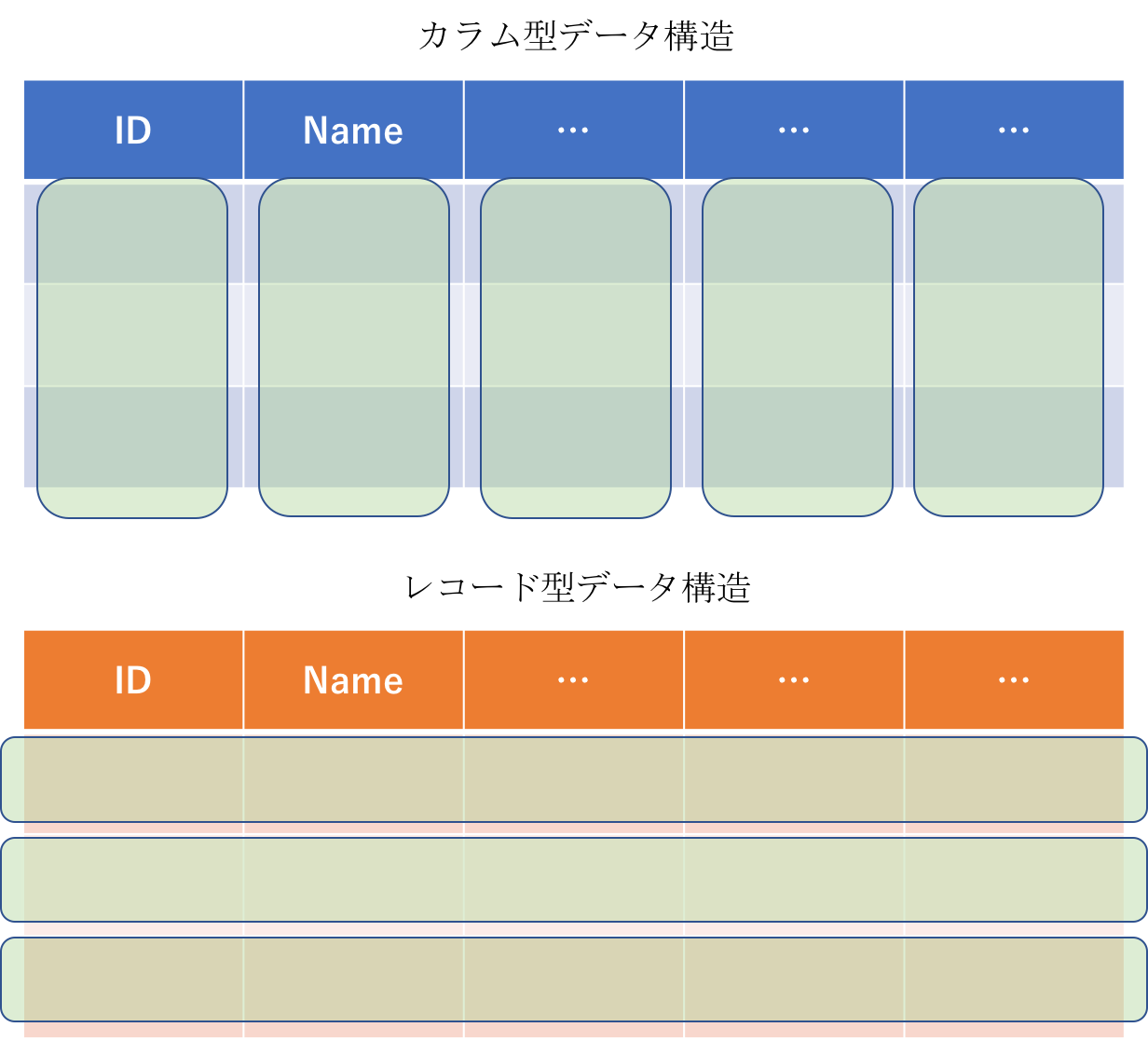
BigQuery はカラム型データ構造を使用しているため、選択した列にある処理される全データが課金対象であり、データの種類によってデータサイズが設定されています。
また、実行中のクエリジョブをキャンセルするとそのクエリが完了した場合に発生する料金が全額課金される可能性があると記載されています。
・データ型に応じたサイズ一覧
| データ型 | サイズ |
|---|---|
| STRING | 2 バイト + UTF-8 エンコードされた文字列のサイズ |
| INTEGER | 8 バイト |
| FLOAT | 8 バイト |
| BOOLEAN | 1 バイト |
| TIMESTAMP | 8 バイト |
| RECORD | 0 バイト + 含まれているフィールドのサイズ |
| どのデータ型でも、null 値は 0 バイトとして計算される。 |
カラム型データ構造
レコード(行)単位でデータを格納しているのではなく、カラム(列)単位でデータを格納している構造です。データ分析を行なう際は個々のレコード情報よりテーブル全体のカラム情報を用いる事が多いためこのようになっているようです。
分析において必要な列だけデータ処理対象とすることができるため課金額を節約することができます。
【参考】
https://cloud.google.com/bigquery/pricing?hl=ja#on_demand_pricing
クエリ毎課金対象例
以下はドキュメントそのままですが、クエリを少し工夫すれば課金対象を減らせるアドバイスがありました。
・Where句でLIMIT
SELECT句で指定しているカラムの全データ分課金されてしまいます。(LIMITで絞ったデータだけでない)
オラクルのrownumと一緒で対象データ取得後に件数を絞っているのかな。
・Select句でCOUNT(*)
単純に特定テーブルに含まれるデータ数を数える場合、全行が対象であるが読み込まれるバイトが無いので無料とのこと。
・Select句にCOUNT(corpus)
一方こちらはcoupusの全データ分が課金対象。
corpusがNullであるものはカウントしない仕様であり、
判定のためにバイト読み込みが発生しているのだろうか。
以下のようなwhere句でカラムを判定している場合も同様に課金対象です。
SELECT
COUNT(*)
FROM
publicdata:samples.shakespeare
WHERE
corpus = 'hamlet';
・Select句に*
これが一番やばいと思います。
全てのカラムを取得するため、スキーマ設定によってはかなりのデータ量になると思われます。更に複数テーブルをJOINしていたら…
【参考】
https://cloud.google.com/bigquery/pricing?hl=ja#samplecosts
余談としてキャッシュされたクエリの場合課金されないとありますが、
キャッシュ保持が24時間(確約ではない)、データが変更されたらキャッシュが無効、
NOWなどを用いると無効など制限があるのであまり当てにしないほうがよいと感じました。
【ポイント】
不要な列を指定しない。(select句においても、where句においても。)
なんでも*で抽出しない。
理解した上でHigh-Computeクエリを実行する
BigQueryでは大量のコンピューティングリソースを消費するクエリをHigh-Computeクエリと定められています。
ドキュメントではJOIN または CROSS JOINなどユーザー定義関数を用いた場合と紹介されていますが、厳密にどのようなクエリであるかは言及されていません。
High-Computeクエリを実行する場合、処理を完了できなければbillingTierLimitExceeded エラーとクエリの費用の概算が返されるそうです。(エラー時は課金対象外)
High-Computeクエリを実行する場合、クエリリクエストの中でmaximumBillingTierを正の値で設定すると可能になりますが、クエリデータ使用量の単位料金を増加するため注意が必要です。
増加する料金単位は最大で maximumBillingTier設定値×現在の料金プラン となります。
(標準プランで「maximumBillingTier:2」として実行すると、最大でTBあたり$10となる)
【参考】
https://cloud.google.com/bigquery/pricing#high-compute
【ポイント】
JOINなど用いる場合はHigh-Computeクエリとなる可能性があるのでクエリを改良出来ないか検討する。
それでも実行したい場合はmaximumBillingTierをなるべく小さく設定した上で実行する。(クエリの費用概算を確認してから設定したほうがよいかも)
分割テーブルやデコレータを利用して対象を絞る
これまでは抽出条件などに注目してきましたが、対象とするテーブルを絞ることでもデータ処理量を削減することができます。
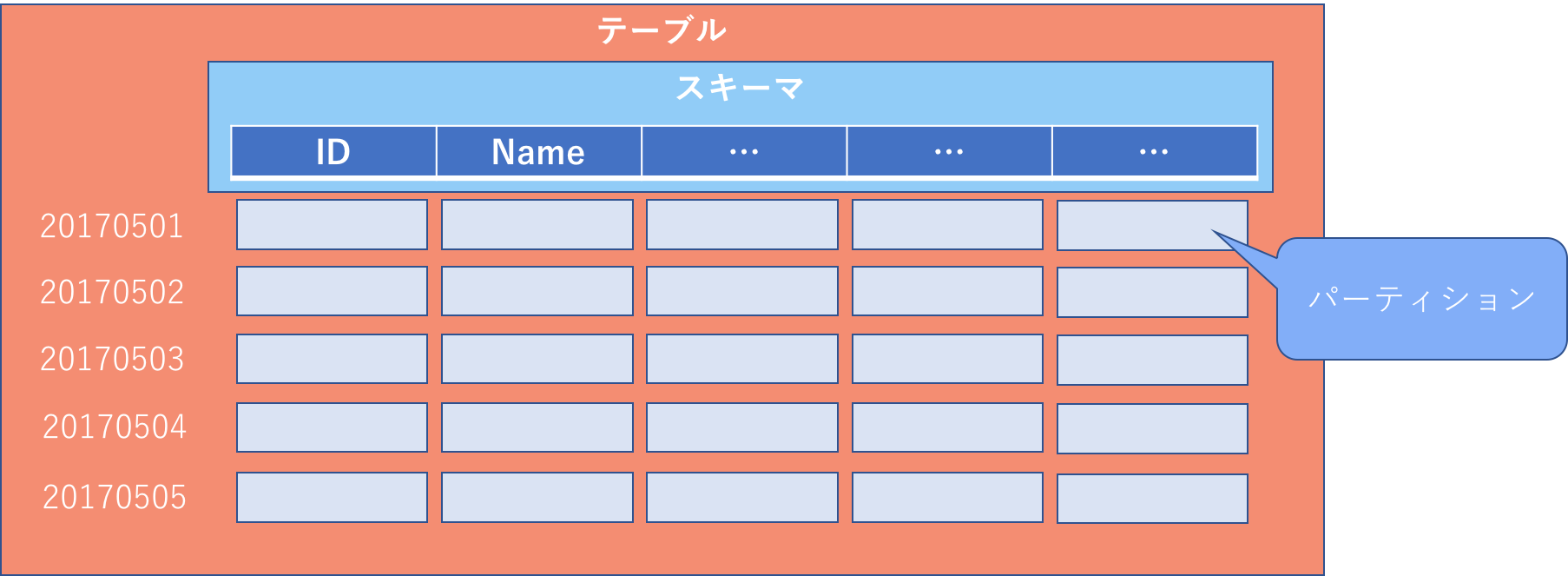
分割テーブル
分割テーブル設定を行えばテーブルを日付によって分割して扱うことが可能です。
クエリでパーティションを指定することによって扱うデータ量を削減できる(=課金額を抑える)可能性がありますので、いつも決まった期間の分析を行う際はテーブル分割しておくとよいでしょう。
【参考】
https://cloud.google.com/bigquery/docs/creating-partitioned-tables?hl=ja
デコレータ(レガシーSQLのみ)
実行日から過去7日以内であればテーブルデコレータを利用することができます。
デコレータを使用した場合テーブルの全データではなく、指定された日付範囲のデータのみを対象とすることができます。
ただし、レガシーSQLのみ利用可能であり、現時点では標準SQLではサポートされていません。
【参考】
https://cloud.google.com/bigquery/table-decorators?hl=ja
※レガシーSQLと標準SQL
BigQueryでは独自の記法であったレガシーSQL(https://cloud.google.com/bigquery/query-reference )を用いていましたが、
2016年にSQL 2011に準拠した標準SQL(https://cloud.google.com/bigquery/sql-reference/ )がリリースされました。
実行時にオプションを追加したり、クエリ接頭辞を設定することによって標準とレガシーの使い分けが可能です。
今後は標準SQLに移行していくと思われますが、無理して直ちにレガシーSQLからの移行を勧めてはいないようです。
新規利用する方は特に制約がなければ標準SQLで記述したほうが良いかと思います。
挿入などのDML文やwhere句でのサブクエリなど様々な機能が追加されているメリットがあります。
デコレータを利用できない点は、分割テーブルで代用すればよいのではないでしょうか。
【参考】
https://cloud.google.com/bigquery/docs/reference/standard-sql/migrating-from-legacy-sql
【ポイント】
テーブル分割やデコレータを利用することによって扱うデータ量を削減した状態でクエリ実行できないか検討する
費用管理を行い課金上限を設定しておく
クエリの実行に工夫を行なう以外にも課金上限を設定しておくことでセーフティを掛けておくことができます。
BigQueryではプロジェクトやユーザー単位でクエリ処理バイト数を1日10TB単位で割当管理出来ます。
デフォルトでは無効であり、設定・解除は申請後2〜3日で適用が反映される模様。
ただし、思いがけず大量処理してしまった場合には割当回復や解除に時間がかかってしまう点には注意しておいたほうが良さそうです。
【参考】
https://cloud.google.com/bigquery/cost-controls?hl=ja
【ポイント】
BigQueryクエリ費用の管理を予め設定しておくことで、最悪の事態を防いでおく
不安な場合はdry runを実行し、データ処理量を確認する
費用管理を行っていても1日最低10TB(=$50)を超えなければストップしません。
実行してみるまでデータ処理量が分からないのは怖いので、dry runというオプションが用意されています。
dry runを指定しておくことで、実際には検索せずに走査バイト数を計測することが出来るので、実行料金を把握して実行することが可能になります。これで安心ですね。
例としてbqコマンドのヘルプでは以下のオプションを付与してdry runを実行できると記載があります。
--[no]dry_run: Whether the query should be validated without executing.
おわりに
上記6点に注意しながら用いれば大抵のことでは大量課金されないと思いますので
今後はBigQueryをバシバシ叩こうと思います!
参考
BigQueryの課金、節約しませんか
[SQLおじさん(自称)がBigQueryのStandard SQLを使ってみた]
(https://www.slideshare.net/kumanoryo/sqlbigquerystandard-sql?next_slideshow=2)
→日本語における標準SQLについての説明が少ないのでとても参考になりました。