はじめに
工場からの出荷依頼PDF等を、運用チームが都度手作業でGoogle Spreadsheetに転記しており工数がかかっているという課題がありました。
件数も多い上にフォーマットも工場ごとに微妙に違う。
これを解決するため、AWS Bedrock と Claude を使って自動取り込みする仕組みを作りました。
最初はPDFだけでしたが、途中からExcel対応の要件があり、invoke_model API から Converse API に統一したりと実運用をしながら作成・改善を行いました。
全体像
最終的にできた仕組みは以下です。
[運用担当者]
↓ 発注書PDF/Excelをアップロード
[Google Drive]
↓ 5分ごとにポーリング (EventBridge Scheduler)
[AWS Lambda] ─── [Google Sheets API]
│
│ document.format = pdf / xlsx
↓
[AWS Bedrock Converse API] (Claude Sonnet 4.6)
↓ 構造化JSON
[Google Spreadsheet] (自動入力シート)
↓ 結果通知
[Slack]
ポイントは以下の3つです。
- PDF / Excel をどちらも同じパイプラインで処理
- BedrockのClaudeに「明細を抽出してJSONで返して」と投げるだけで、様々なフォーマットに応じた複雑なパース処理が必要ない
- マスタ(住所/商品コードなど)はGoogle Spreadsheet上で管理して、Lambdaから補完
技術スタック
- インフラ管理: Terraform
- 実行環境: AWS Lambda (Python)
- AI処理: AWS Bedrock (Claude Sonnet 4.6)
- トリガ: EventBridge Scheduler
- GCP認証: Workload Identity Federation
現在は Claude Opus も利用できると思いますが、Sonnet4.6でも精度は十分で、例えばPDFに取り消し線で手書きで殴り書きされた文字なども高い精度(ほぼ100%) で読み取ってくれます(!)
PDF発注書を自動取り込みする基盤を作る
Google Sheets を Lambda から触れるようにする
最初に行ったことは、Lambda → Google Sheets API の通信経路を作ることです。
一般的にはサービスアカウントキー(JSON)を作成してLambdaの環境変数に入れるような方法もありますが、漏洩リスクのある鍵ファイル自体を必要がないという点とLambdaの実行ロールそのものを認証の主体とする運用のために Workload Identity Federation を利用しました。
Lambdaは自前でJWTを発行できないためGCPのOIDC連携は使えないものの、 Workload Identity Federation + AWS STS の署名付きリクエスト を利用することができます。
[Lambda IAMロール]
↓ STSで自分のARNを署名付きリクエスト化
[GCP STS Token Service]
↓ AWSのARNを検証してGCPのアクセストークンに交換
[Google Sheets API]
インフラ構築ではTerraformでモジュール化しておき、別Lambda追加時もすぐ使い回せるようにしました。
Bedrock利用のために Anthropic にユースケースを提出
AnthropicモデルをAWSアカウントで最初に利用する時に、ユースケースを提出する必要があります。

Bedrock Claudeに発注書PDFを投げる
ここからが本題で、PDFをBedrockに投げて構造化JSONを抽出する処理です。
最初に詰まったのは 「ClaudeでPDFを直接扱える」 ことを知らなかった点。
ドキュメントを漁り、Claude Sonnet 3.5 v2 以上ならMessages APIの document ブロックでPDFをbase64で渡せると判明し、これで進めました。
import base64
import boto3
bedrock = boto3.client('bedrock-runtime')
pdf_bytes = ... # Google Drive からダウンロードしたPDFバイト列
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 64000,
"messages": [{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": base64.b64encode(pdf_bytes).decode(),
},
},
{"type": "text", "text": "発注書から商品明細をJSONで抽出してください..."},
],
}],
}
response = bedrock.invoke_model(
modelId="anthropic.claude-sonnet-4-6",
body=json.dumps(body),
)
SCPでクロスリージョン推論のブロック
実装を進めつつ、モデル選定のためにBedrockのPlaygroundを試しているとエラーが。
AccessDeniedException
User: ... is not authorized to perform: bedrock:InvokeModelWithResponseStream
on resource: arn:aws:bedrock:ap-northeast-3::foundation-model/anthropic.claude-sonnet-4-6
with an explicit deny in a service control policy
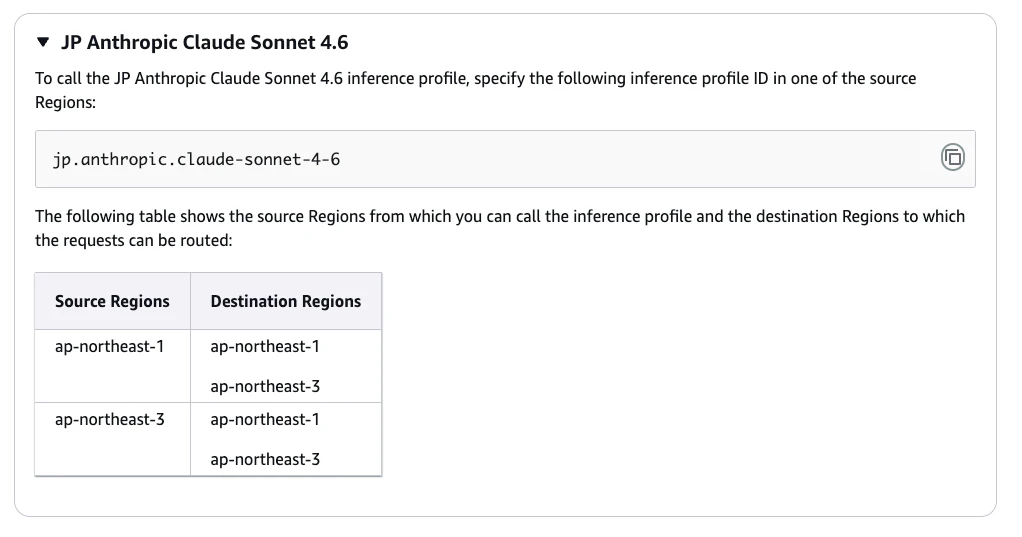
ap-northeast-3 (大阪)が拒否されていることが分かります。
原因は、Claude Sonnet 4.6 が クロスリージョン推論モデル で、東京 + 大阪の両方のリージョン許可が必要なのに、SCPで大阪を拒否していたことです。
組織のSCPで ap-northeast-1 (東京) しか許可していなかったので、大阪も許可することで解決しました。

stop_reasonフィールドの確認
ClaudeAPIには stop_reason という (リクエスト処理の失敗を示すエラーとは異なる)レスポンス生成を正常に完了した理由停止を返すフィールド が存在します。
APIが200で返ってきていてもこのフィールドが end_turn 以外なら、応答が想定通りに完結していない可能性が高い、というシグナルになります。
開発時は1〜2ページのPDFで動作確認していたのですが、いざ本番運用に乗せると巨大ページのPDFを扱う場面があり、レスポンスが途中で切れエラーになるという問題が発生しました。
この時にstop_reason を確認し デフォルト指定の max_tokens では足りずに途中で打ち切られていた事をすぐ判明することができました。
運用に乗せる
MVPができたので、ここから運用に耐える仕組みに育てていきます。
EventBridge Schedulerで5分ごとに実行 / 処理対象の通知
PDFをDriveにアップロードしたら自動で取り込まれてほしいので、EventBridge Schedulerで5分ごとに対象フォルダをスキャンする方式に。
完了/失敗したPDFはそれぞれのフォルダに移動させることで二重処理を防ぎ、かつファイルの状態を目視で管理できるようにしました。
また、処理対象PDFがあったときだけ、成功/失敗をSlackに通知。Driveの共有リンク付きで送り運用チームがクリック1つで確認できるようにしました。
マスタによる住所補完
発注書PDFには住所情報が含まれていないこともあるため、会社名で住所マスタ(Google Spreadsheet)を引いて補完** する仕組みを追加しました。
特に、全角/半角の括弧や空白の揺れを吸収 する実装を追加することで、PDF記載自体の表記揺れ・Bedorockの解析結果自体の表記揺れを吸収させています。
invoke_model から Converse API への移行
特定のいくつかの工場ではPDF以外の例えばExcel(xlsx)で格納されることがありました。
Excelの読み取りであれば openpyxl を利用するなど必ずしもAIを介す必要もありませんが、コードで吸収したほうがヒューマンエラーも入り込まず一貫した挙動を保てるという判断からBedrockを採用しました。
最初は xlsx → markdown → invoke_model
invoke_model のMessages APIは document ブロックが PDF と plain text しか受け付けないので、xlsxをmarkdownテーブルにシリアライズしてからtextとして送る方式を実装。
しかし調べてみると、Bedrockには Converse API という別系統もあり xlsx もネイティブ対応していることが分かりました。
コスト
Converseとinvoke_modelとでは課金レート(トークン単価)は同じ。
トークン消費量は変わるものの、Bedrockの課金は「モデル × token量」で、API種別によるレート差はありませんでした。
| 形式 | Input tokens | Output tokens | コスト/ファイル |
|---|---|---|---|
| ~1,500 | ~300 | ~$0.010 | |
| Excel (Converse) | ~3,000 - 5,000 | ~500 | ~$0.020 |
おわり
簡単ではありますが、AWS BedrockでAIの自動運用として行った際の気づきなどをまとめました。
最近では Claude API スキル という最新リファレンスやベストプラクティスを参照させるSkillもあるようです。
AIだからと言って任せ仕切りにせず、観測性と検証の仕組みを必ずセットで持たせる ことが、結局は 安心してAIに任せられる範囲を広げる コツだと感じました。
Claude API スキルのような新しい仕組みも上手く取り入れつつ、 モデルやAPIの進化に合わせて自分達の運用も継続的にアップデートしていきたいと思います。