はじめに
こんにちは。NTTデータ先端技術の亀井(@kamein)です。
最近はクラウド化がさらに進んでデータ活用市場がますます大きくなってきています。筆者らは市場動向に追随できるように若手中心で集まって簡単なデータ活用環境を構築し、データ活用基盤の概要を学ぼうと取り組みました。また、近年、暗黙の了解になりつつあるウォーターフォール型での各工程の動き方の振り返りも行いました。
本記事では、データ活用基盤の構築内容および各工程の動作内容についてご紹介します。
目次
- 本シリーズの読者イメージ
- シリーズの目次構成
- シナリオ構成
- シナリオ目的
- 実現したいこと
- 機能要望
- 非機能要望
- システム概要図
- 実案件での基盤構成検討ポイントについて
本シリーズの読者イメージ
以下に当てはまる方は、本記事をご一読頂いてご参考になれば幸いです。
- データ活用基盤を作りたいが何から始めたら良いかわからない人(構成検討のポイントをご紹介)
- データ活用基盤をsmallstartしたいけど基盤構成イメージが湧かない人(データ活用基盤の構成例をご紹介)
- 要件定義、基本設計、詳細設計、構築、試験の各工程ではどのようなことを行うのかイメージを掴みたい人(各工程成果物例をご紹介)
- Terraformの環境構築の進め方や実際のコードを参考にしたい人(Terraformの進め方や作成例をご紹介)
シリーズの目次構成
| タイトル | 概要 |
|---|---|
| データ活用基盤を作ってみたその1(構成シナリオ) | ※本記事。構成シナリオを記載 |
| データ活用基盤を作ってみたその2(要件定義) | 要件定義工程の考え方および実施内容をご紹介 |
| データ活用基盤を作ってみたその3(基本設計) | 基本設計工程の考え方および実施内容をご紹介 |
| データ活用基盤を作ってみたその4(詳細設計) | 詳細設計工程の考え方および実施内容をご紹介 |
| データ活用基盤を作ってみたその5(試験) | 試験工程の考え方および実施例をご紹介 |
| データ活用基盤を作ってみたその6(構築・デプロイ方法) | 構築手法およびデプロイ方法のご紹介 |
| データ活用基盤を作ってみたその7(構築・IAM) | IAM周辺の実装内容をご紹介 |
| データ活用基盤を作ってみたその8(構築・データ収集-Lambda) | Lambdaを中心にデータ収集領域の実装内容をご紹介 |
| データ活用基盤を作ってみたその9(構築・データ蓄積-S3) | S3の蓄積環境の実装内容をご紹介 |
| データ活用基盤を作ってみたその10(構築・データ加工-Glue) | Glueを中心にデータ加工領域の実装内容をご紹介 |
| データ活用基盤を作ってみたその11(構築・データ活用-Athena) | Athenaを中心にデータ活用の実装内容をご紹介 |
| データ活用基盤を作ってみたその12(Terraform使ってみた) | Terraformの選定理由や使ってみて感じたことTips集 |
シナリオ構成
今回の学習目的で構成するシナリオを以下の通りに定めました。
シナリオ目的
前提
- 中期経営計画では、新規サービス創出・既存ビジネス効率化のため、全社で利用可能なデータ活用基盤を作る方針を掲げています。
- 一方で、既存システム群はそれぞれが独自開発を進めていたため、データの一貫性が取れていない課題を抱えています。
- 始めに既存システム効率化を目指し、データ活用基盤上に一貫性のあるデータを配置し、既存システムが配置データを利用することで一貫性の課題解消を考えます。
目的
今回はPhase1として、smallstartで試験的に郵便番号データを収集・配置・加工し、一部の既存システムから郵便番号データを閲覧して活用できるデータ活用基盤を構成することとしました。
実現したいこと
日本郵便株式会社の郵便番号データをデータ活用基盤に配置および月初ジョブで最新化し、既存システム(NWが離れた単一EC2)からCliベースでselectできる環境をAWS上で構成する。
機能要望
- (データ収集)月次ジョブlambdaで日本郵便からzipファイルダウンロードしてS3に保存する
- (データ加工)AWS Glueでデータ加工を行いS3に格納し直す
※ 今回の学習目的は基盤構成の理解であり、具体的な加工処理の作りこみは目的から外れるため、処理内容は簡単な文字コード変換のみとする - (データ活用)オンライン時間帯中は既存システム(EC2)からAthenaで加工済みデータをselectできる
- (メタデータ管理)テクニカルメタデータのみをGlue data catalogで管理する
非機能要望
- (可用性)全てマネージドサービスを使用する
- (性能/拡張性)SmallStart時点で具体的な性能目標は定義しない。ただし、今後の拡大かに備えて、スケール可能なリソースを利用する
- (運用・保守性)
- 営業時間帯 10:30~18:00にオンライン作業ができること
- バックアップ構成しない。(障害発生時は再構築および上流からのデータ再投入)
- (セキュリティ)
- 今後、個人情報活用予定があるため、NW暗号化、ストレージ暗号化を実装する
- マネコン操作ではMFA認証必須とする
- 監査実装する。監査対象は全ユーザーのログイン、ログアウト。特権ユーザー変更操作内容。
以下のアクターで権限分離を実装する。
| アクター名 | 概要 |
|---|---|
| 本システムの特権ユーザー | 基盤運用の責任者 |
| 本システムの運用作業者 | 共同会社のオペレーター。簡易な運用作業の実施 |
| 本システムの監査運用者 | 監査異常を確認する |
| 本システムのデータエンジニア | 投入データ管理 |
| 既存システムのデータ活用者 | 加工データを閲覧できる |
- (移行性)無し
- (システム環境・エコロジー)AWS活用のため、対象外
システム概要図
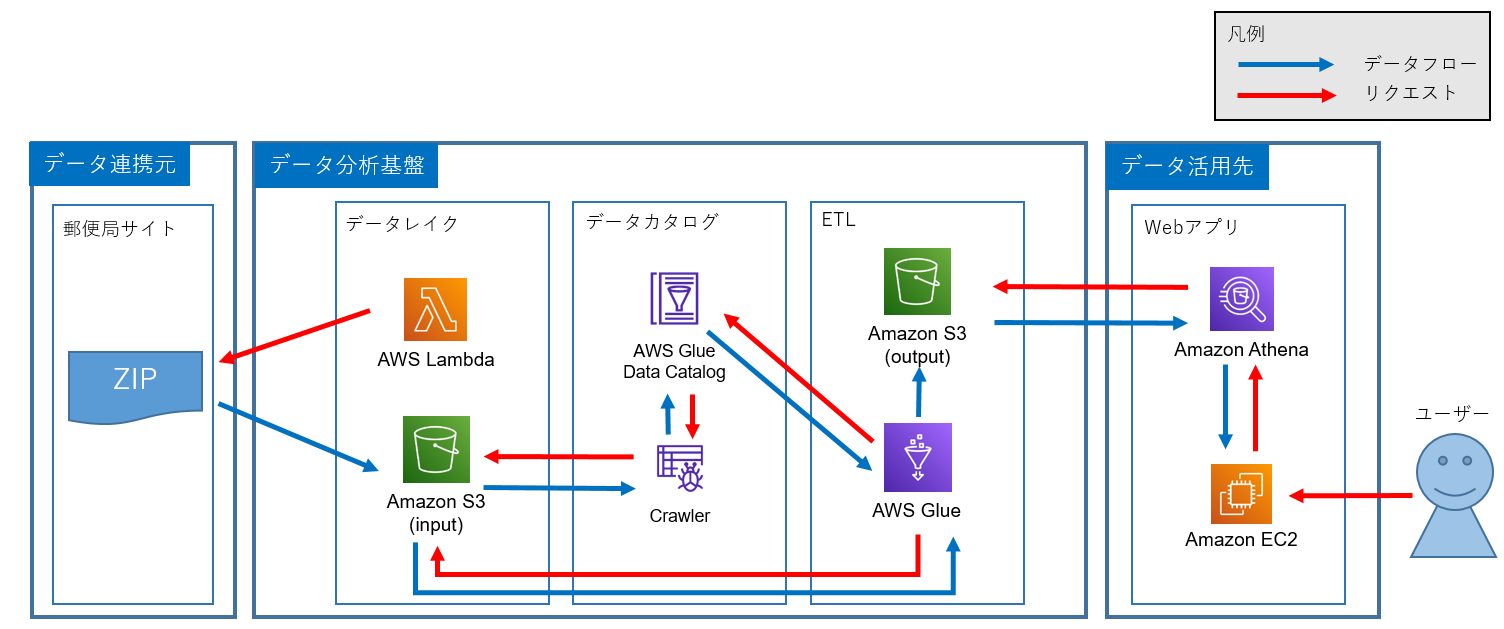
実案件での基盤構成検討ポイントについて
基盤構成を考える上で必要なインプット情報をシナリオ定義として設定しました。これからデータ活用基盤の検討を始める方は少なくとも上記で定義したような内容がある程度整理されていることが必要だと感じて頂けたら幸いです。
実際にデータ活用基盤検討を始めるために特に重要な検討ポイントは、ビジネス課題からシステム目的を定義し、データ活用のユースケースを整理することです。どのようなデータ活用したいかに合わせて必要なデータを検討することが可能となり、そして、必要なデータをどこから収集や前処理すべきかが見えてきます。
今回は学習向けのため、ピンポイントで郵便番号データを既存システム(Athena)から見えることとしましたが、これからデータ活用を始める方は、まずはビジネス課題に対するユースケース検討に時間をかけて、ある程度整理できてからデータ活用基盤検討に進むことをお勧めします。
最後に
シナリオ構成を考えましたが難しいですね。。。実案件と比べると定義内容がかなり曖昧で後々苦労しましたが学習目的ならばこれで十分だと思うことにしました。参考程度に後続記事もご一読頂けますと幸いです。
次の記事はデータ活用基盤を作ってみたその2(要件定義) です。
最後までお読みいただきありがとうございました。