はじめに
こんにちは、NTTデータ先端技術の白木です。
本記事はデータ活用基盤を作ってみた連載記事の10(構築・データ加工-Glue)です。
本シリーズの取り組みの内容についてはその1(構成シナリオ)をご覧ください。
前の記事は、その9(構築・データ蓄積-S3)からご覧ください。
今回は、作成したデータ活用基盤の加工処理について記載します。
目次
- データ加工処理設計
- データ加工処理の流れ
- 構築方法
- データ加工処理の実装
- 詰まったところ
- まとめ
データ加工処理設計
データ活用基盤を構築する際に欠かせないデータ加工処理の設計について紹介します。
本システムでは、その1の機能・非機能要望を満たせるように設計しました。
データ加工処理に関連する機能・非機能要望は以下になります。
| 項目 | 要望 | |
|---|---|---|
| 機能 | - | 月次ジョブGlueで文字コード変換を行いS3に保存する |
| 非機能 | 可用性 | 新構成のデータ活用基盤側は全てマネージドサービスを使用すること |
| 非機能 | 性能/拡張性 | SmallStart時点で具体的な性能目標は定義しない。ただし、今後の拡大かに備えて、スケール可能なリソースを利用する |
| 非機能 | 運用/保守性 | 営業時間帯 10:30~18:00にオンライン作業ができること。 |
| 項目 | 設計内容 | 理由 |
|---|---|---|
| 加工サービス | 加工については、Glueを利用。月次ジョブの実行には、EventBridgeとStepFunctionを利用。 | 機能要望で指定されていたため。月次ジョブの実行については、マネージドサービスを利用する必要があったため。 |
| 加工タイミング | 毎月1日の0:00の収集処理完了後。タイムゾーンはAsia/Tokyo | オンライン作業に影響を与えない時間帯を選んだため。 |
| 加工対象 | 収集後データ | 機能要望で指定されていたため。 |
| 加工対象の格納先 | S3バケット | 機能要望で指定されていたため。 |
データ加工処理の流れ
構成図
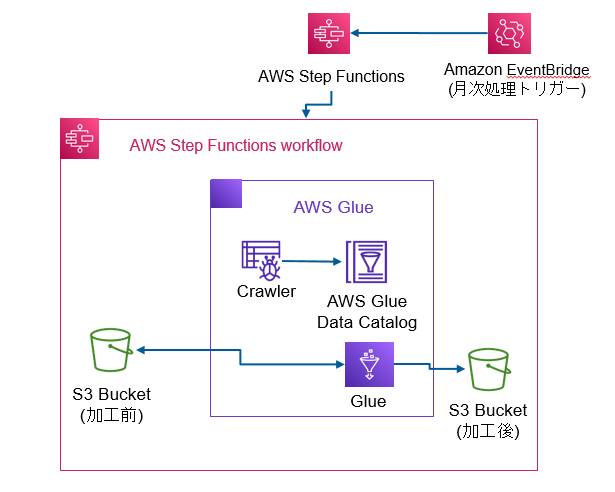
手順
- 毎月1日の0:00にEventBridge Schedulerが起動し、Step Functionのワークフローを動作させます。
- 収集Lambda(その8)処理完了後、ワークフローのGlue jobを起動し、処理を実行します。
- Glue jobは、加工前のS3バケットにアクセスし、対象のzipファイルをGlueローカルストレージにダウンロードします。zipファイルを展開し、文字コードをshift_jisからutf-8へ変換後、加工後S3バケットにCSVファイルをアップロードします。
- Glue job完了後、ワークフローのGlue Crawlerが起動し、自動的にデータカタログの作成を行います。
構築方法
今回作成しているAWSリソースはTerraformを用いたInfrastructure as Code(IaC)で作成しています。以下に作成したTerraform構成ファイル(jobs.tf)の内容について記載します。
Glueリソースの作成
加工処理を行うGlue job、カタログを作成するGlue Crawler、カタログの保存先であるGlue Databaseを以下のように作成します。
#Glue Job
resource "aws_glue_job" "biwa-prod-glue-job-zip-001" {
name = "biwa-prod-glue-job-zip-001"
role_arn = aws_iam_role.biwa-prod-iam-role-glue-execution-001.arn
max_capacity = 0.0625
glue_version = "2.0"
execution_property {
max_concurrent_runs = 5
}
command {
name = "pythonshell"
python_version = "3.9"
script_location = "{スクリプトを配置しているS3バケット}"
}
}
# Glue Catalog database
resource "aws_glue_catalog_database" "biwa-prod-glue-catalogdatabase-analytics-001" {
name = "biwa-prod-glue-catalogdatabase-analytics-001"
}
# Glue Crawler
resource "aws_glue_crawler" "biwa-prod-glue-crawler-analytics-001" {
database_name = "biwa-prod-glue-catalogdatabase-analytics-001"
name = "biwa-prod-glue-crawler-analytics-001"
role = aws_iam_role.biwa-prod-iam-role-glue-execution-001.arn
s3_target {
path = "{S3バケットのパス}"
}
}
Glue job
S3バケットから加工前データを取得し、文字コード変換を行ったのち、S3にアップロードする処理は以下になります。
コードは単純で、ファイル取得→文字コード変換→カラム情報追加→アップロードという流れになっています。
カラム情報追加処理ですが、加工前データになかったことから追加しています。
import zipfile
import codecs
import boto3
import os
import sys
import pandas
import logging
from botocore.config import Config
import botocore.exceptions as BotoExceptions
# 定数定義
OBJECT_KEY_NAME = 'ken_all.zip'
DOWNLAOD_ZIP_PATH = "/tmp/ken_all.zip"
SOURCE_BUCKET_NAME = 'biwa-prod-s3-bucket-datastorage-001'
UPLOAD_BUCKET_NAME = 'biwa-prod-s3-bucket-datastorage-002'
SHIFT_JIS_CSV_PATH = '/tmp/KEN_ALL.CSV'
UTF_8_CSV_PATH = '/tmp/KEN_ALL_utf8.CSV'
UPLOAD_CSV_PATH = 'ken_all.csv'
COLUMN_LIST = [
"jis_code", "old_postal_code", "postal_code", "prefecture_kana",
"city_kana", "town_kana", "prefecture_kanji", "city_kanji",
"town_kanji", "multiple_towns_flag", "has_subdivision_flag", "has_district_flag",
"multiple_areas_flag", "update_status", "change_reason"
]
# loggingの設定
logger = logging.getLogger()
[logger.removeHandler(h) for h in logger.handlers]
log_format = '[%(levelname)s]\t%(filename)s:\t%(funcName)s:%(lineno)d\t%(message)s'
stdout_handler = logging.StreamHandler(stream=sys.stdout)
stdout_handler.setFormatter(logging.Formatter(log_format))
logger.addHandler(stdout_handler)
logger.setLevel(logging.INFO)
def download_zip_file(s3):
"""s3からローカルにファイルのダウンロード
s3からzipファイルをglueのローカルにダウンロードし、
zipファイルの展開を実施する関数。
Args:
s3 (boto3.resources.factory.s3.ServiceResource): boto3 s3 interface
Raises:
e: all exceptions
"""
# s3よりファイル取得
source_bucket = s3.Bucket(SOURCE_BUCKET_NAME)
try:
source_bucket.download_file(OBJECT_KEY_NAME, DOWNLAOD_ZIP_PATH)
logger.info('file download success!')
except BotoExceptions.ClientError as e:
if e.response['Error']['Code'] == "404":
logger.error("The object does not exist.")
logger.error(e.response['Error'])
else:
raise e
# zipファイル展開
zp = zipfile.ZipFile(DOWNLAOD_ZIP_PATH, "r")
zipfile.ZipFile.extractall(zp, '/tmp')
logger.info('file extraction completed!')
return
def extract_zip_file():
"""文字コード変換
glueローカルにダウンロードしたCSVをshift_jisからutf-8へ文字コード変換を実施する関数
"""
# 文字コード変換
fin = codecs.open(SHIFT_JIS_CSV_PATH, "r", "shift_jis")
fout_utf = codecs.open(UTF_8_CSV_PATH, "w", "utf-8")
for row in fin:
fout_utf.write(row)
fin.close()
fout_utf.close()
logger.info('character code conversion completed!')
return
def insert_column_info_to_csv():
"""CSVにカラム情報をインサート
CSVにカラム情報をインサートを実施する関数
Raises:
e: all exceptions
"""
# カラム情報を1行目にインサート
df = pandas.read_csv(UTF_8_CSV_PATH, names=COLUMN_LIST, encoding='utf-8')
df.to_csv(UTF_8_CSV_PATH, index=False)
logger.info('column information insert completed!')
return
def upload_csv_file(s3):
"""CSVをS3へアップロード
CSVをS3へアップロードを実施する関数
Args:
s3 (boto3.resources.factory.s3.ServiceResource): boto3 s3 interface
Raises:
e: all exceptions
"""
upload_bucket = s3.Bucket(UPLOAD_BUCKET_NAME)
try:
upload_bucket.upload_file(UTF_8_CSV_PATH, UPLOAD_CSV_PATH)
logger.info('file upload success!')
except BotoExceptions.ClientError as e:
logger.error(e.response['Error'])
raise e
return
def main():
"""Glueメイン処理
以下の処理を実施する。
・S3からファイルのダウンロード
・文字コード変換
・ファイルをS3へアップロード
・Glueローカルのファイル削除
"""
config = Config(
connect_timeout=5,
retries={
'max_attempts': 3,
'mode': 'standard'
}
)
s3 = boto3.resource('s3', config=config)
# ファイルダウンロード
download_zip_file(s3)
# 文字コード変換
extract_zip_file()
# カラム情報インサート
insert_column_info_to_csv()
# ファイルアップロード
upload_csv_file(s3)
# ファイル削除
os.remove(SHIFT_JIS_CSV_PATH)
os.remove(UTF_8_CSV_PATH)
os.remove(DOWNLAOD_ZIP_PATH)
logger.info('file delete success!')
return
if __name__ == "__main__":
main()
所感
本PJでは、Athenaからデータを参照する要件だったため、Glue Databaseにメタデータを作成するためにGlue Crawlerを利用した。
そのため、Glue Databaseにデータを格納するためにGlue Crawlerを利用したのですが、カンマ区切りのデータをコードを書いたり、設定をせずともCrawlerがいい感じにメタデータを格納してくれたのはとても便利だなと思いました。
ただ、実際どのような処理が行われているのかなど理解できずに終わってしまったので、次回触る際は詳細を理解できるようにしたいと思いました。
最後に
今回はデータ加工処理の設計や、TerraformのIacを用いてGlueリソースを作成する方法について紹介しました。
次章は、その11(構築・データ活用-Athena)についてです。
ここまでお読みいただきありがとうございました。