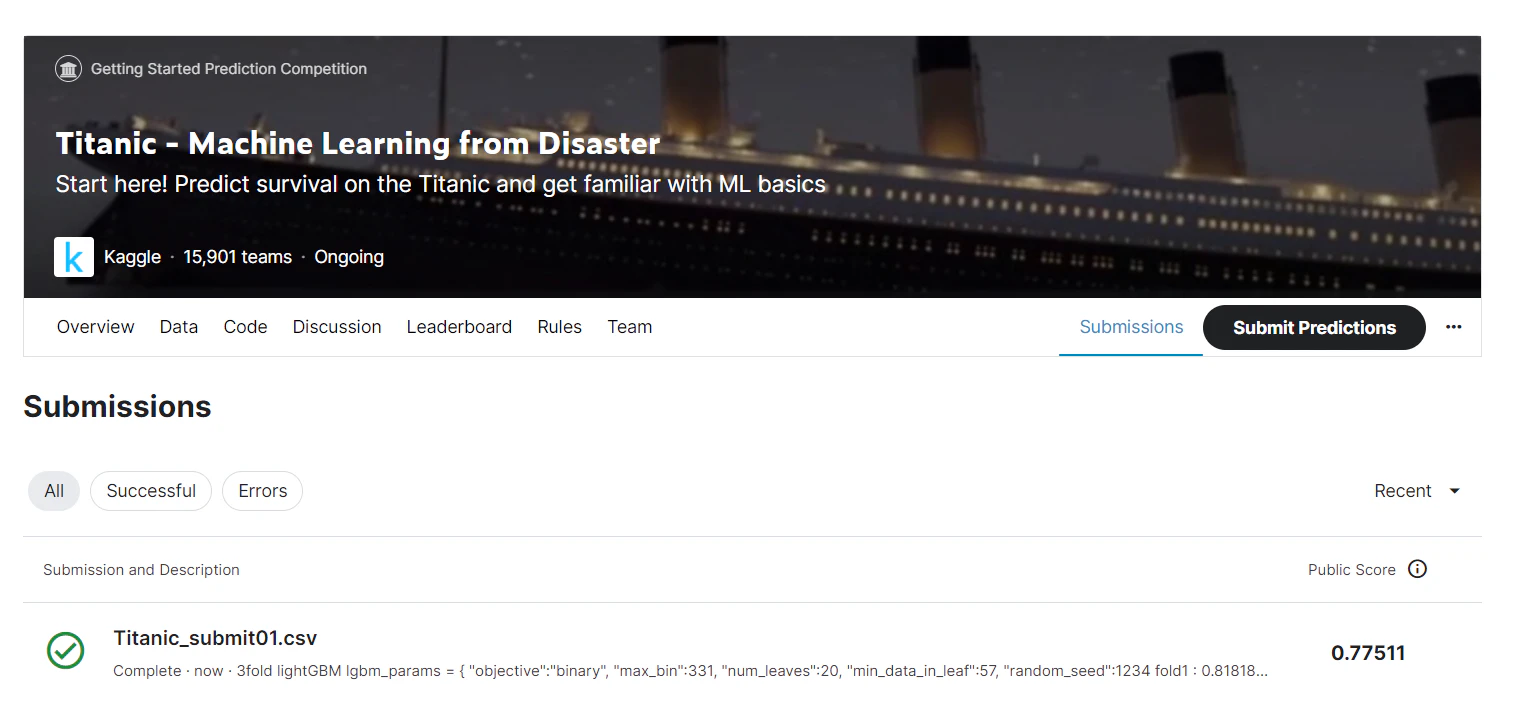
これは何の記事?
Titanic分析の学習ログです
環境
Google Colab
分析の流れ
- データの概要把握
- データの可視化
- 前処理・特徴量の生成
- モデリング
- Submit
データの概要把握
# 使用するライブラリをインポート
import pandas as pd
import numpy as np
# データの読み込み
train_df = pd.read_csv("/content/drive/MyDrive/Kaggle/Titanic/train.csv")
test_df = pd.read_csv("/content/drive/MyDrive/Kaggle/Titanic/test.csv")
submission = pd.read_csv("/content/drive/MyDrive/Kaggle/Titanic/gender_submission.csv")
# データ内容を確認
train_df.info()

・AgeとCabinは欠損値が多いため注意
・Parch:乗船している親や子供の数
# 先頭の5行を確認
train_df.head()

・Surviveは0,1フラグで記載
# 男女比
train_df["Sex"].value_counts()

データを可視化
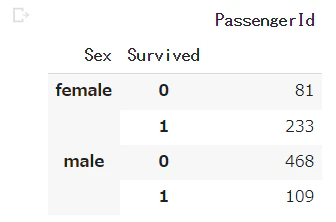
女性の方が生存率が高い
# 男女別の生存比
train_df[["Sex","Survived","PassengerId"]].groupby(["Sex","Survived"]).count()
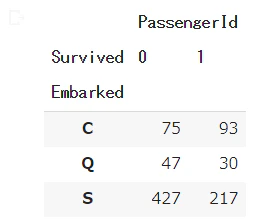
C(Cherbourg港)から乗船した人は生存率が高い
# 港別の生存比
train_df[["Embarked","Survived","PassengerId"]].groupby(["Embarked","Survived"]).count().unstack()
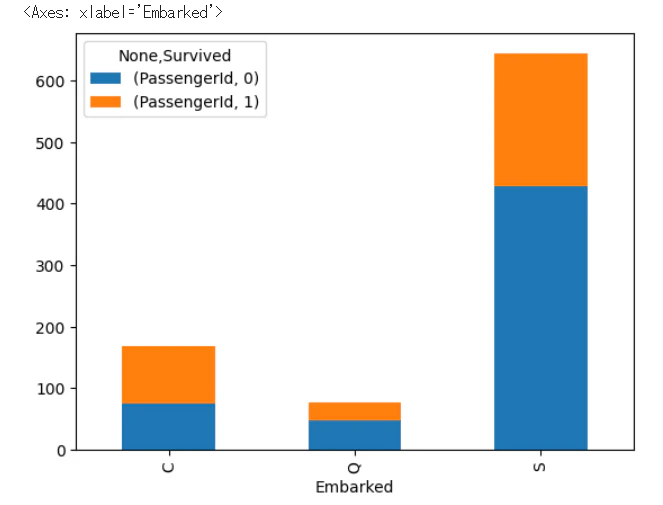
港別の生存率をグラフ化
# 港別生存比の式を代入
embarked_df = train_df[["Embarked","Survived","PassengerId"]].groupby(["Embarked","Survived"]).count().unstack()
# 港別生存比を棒グラフ化
# stacked=Trueは積み上げの指示
embarked_df.plot.bar(stacked=True)
男女と港はダミー変数化しておく
# 男女をカテゴリ変数からダミー変数に
# 値は2つしかないので1列でよい、最初の列を削除
train_df_dummies = pd.get_dummies(train_df, columns=["Sex"], drop_first=True)
# 港をカテゴリ変数からダミー変数に
train_df_dummies = pd.get_dummies(train_df_dummies, columns=["Embarked"])
train_df_dummies.head()

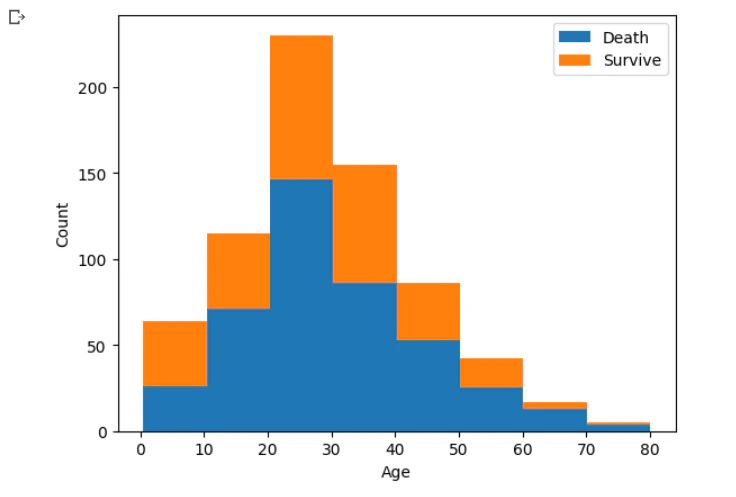
若い方が生存率が高い
# 使用するライブラリをインポート
import matplotlib.pyplot as plt
# 生存別の年齢データを取得
# 年齢が欠損しているレコードは削除
death_age = train_df[train_df["Survived"] == 0]["Age"].dropna()
survive_age = train_df[train_df["Survived"] == 1]["Age"].dropna()
# ヒストグラムを作成、ラベルを指定
plt.hist((death_age, survive_age), histtype="barstacked", bins=8, label=("Death", "Survive"))
plt.legend()
plt.xlabel("Age")
plt.ylabel("Count")
plt.show()
相関係数を確認
# 相関行列を作成
train_corr = train_df_dummies.corr()
train_corr
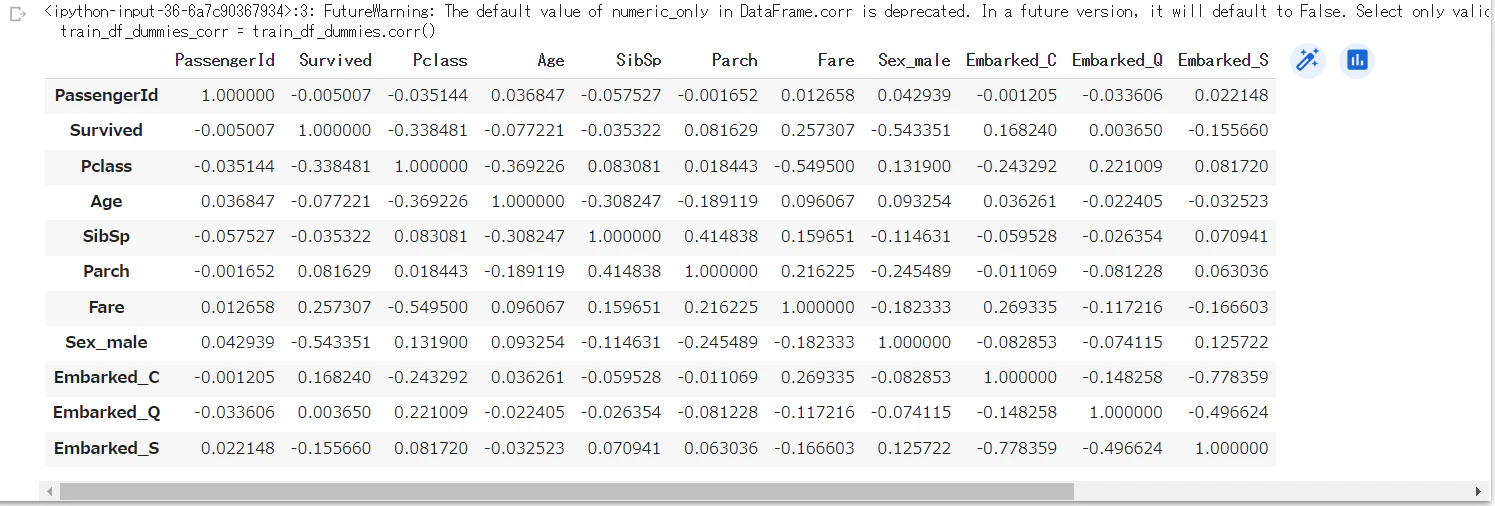
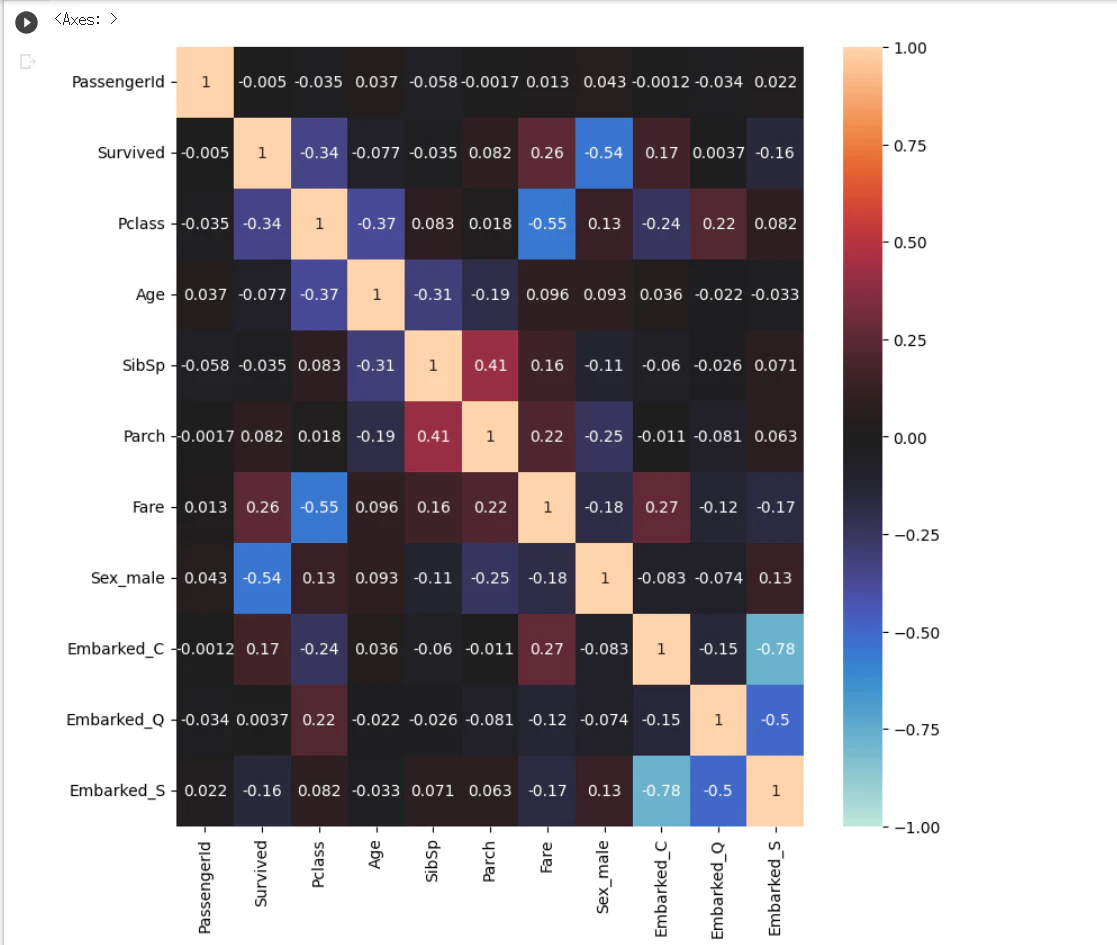
年齢はあまり関係がない?(欠損値が多いせい?)
# 使用するライブラリをインポート
import seaborn as sns
# ヒートマップを作成
plt.figure(figsize=(9,9))
sns.heatmap(train_corr, vmax=1, vmin=-1, center=0, annot=True)
前処理・特徴量の生成
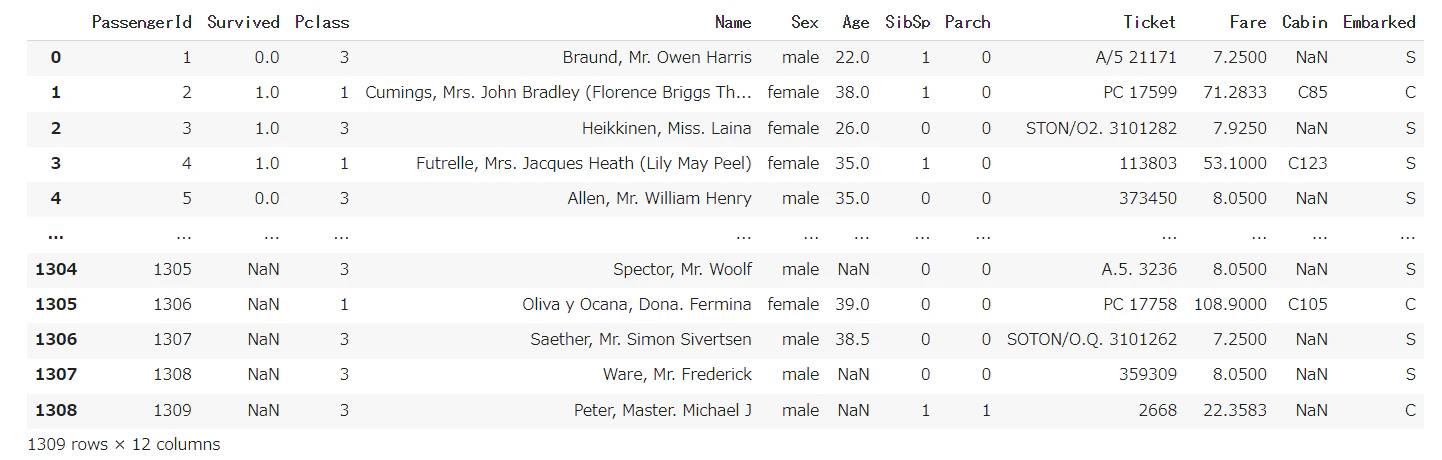
学習データとテストデータを結合
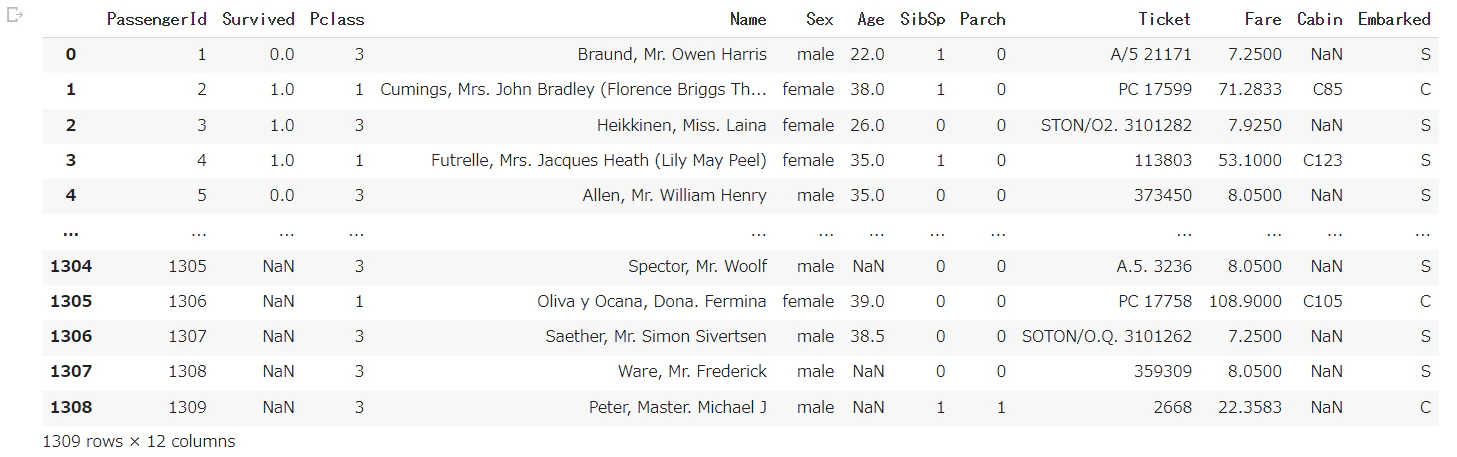
# 学習データとテストデータを結合
all_df = pd.concat([train_df, test_df], sort=False).reset_index(drop=True)
all_df
欠損値確認
all_df.isnull().sum()
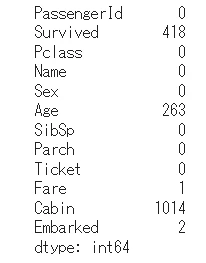
欠損値穴埋め(Fare)
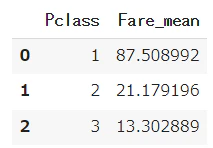
# Pclassごとに平均値算出
Fare_mean = all_df[["Pclass", "Fare"]].groupby("Pclass").mean().reset_index()
# カラム変更
Fare_mean.columns = ["Pclass", "Fare_mean"]
Fare_mean
# all_dfにFare_meanを結合
all_df = pd.merge(all_df, Fare_mean, on="Pclass", how="left")
# FareがNULLの場合、Fare_meanの値に置き換え
all_df.loc[(all_df["Fare"].isnull()), "Fare"] = all_df["Fare_mean"]
# Fare_meanの列を削除
all_df = all_df.drop("Fare_mean", axis=1)
all_df
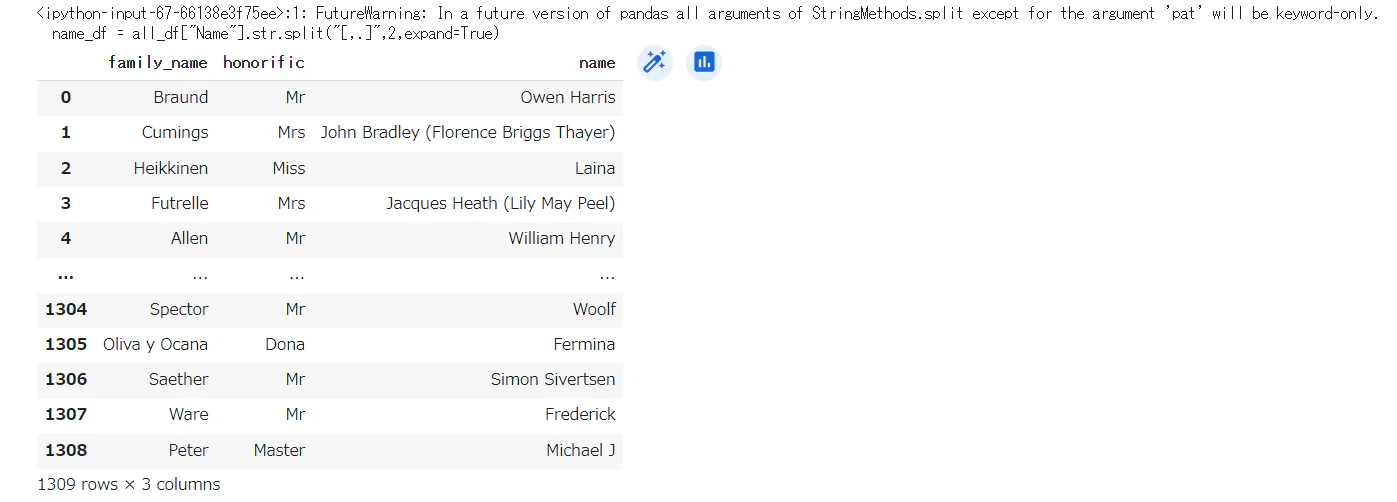
敬称を取得
# 苗字、敬称、名前で分割したdf作成
name_df = all_df["Name"].str.split("[,.]",2,expand=True)
name_df.columns = ["family_name", "honorific", "name"]
# 前後の空白を削除
name_df["family_name"] = name_df["family_name"].str.strip()
name_df["honorific"] = name_df["honorific"].str.strip()
name_df["name"] = name_df["name"].str.strip()
name_df
# 敬称別でカウント
name_df["honorific"].value_counts()
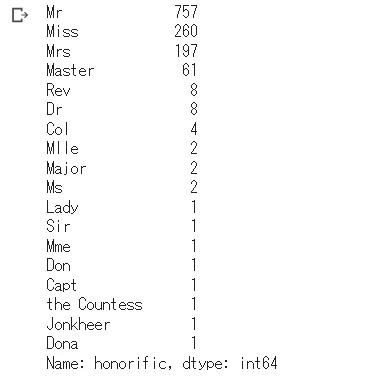
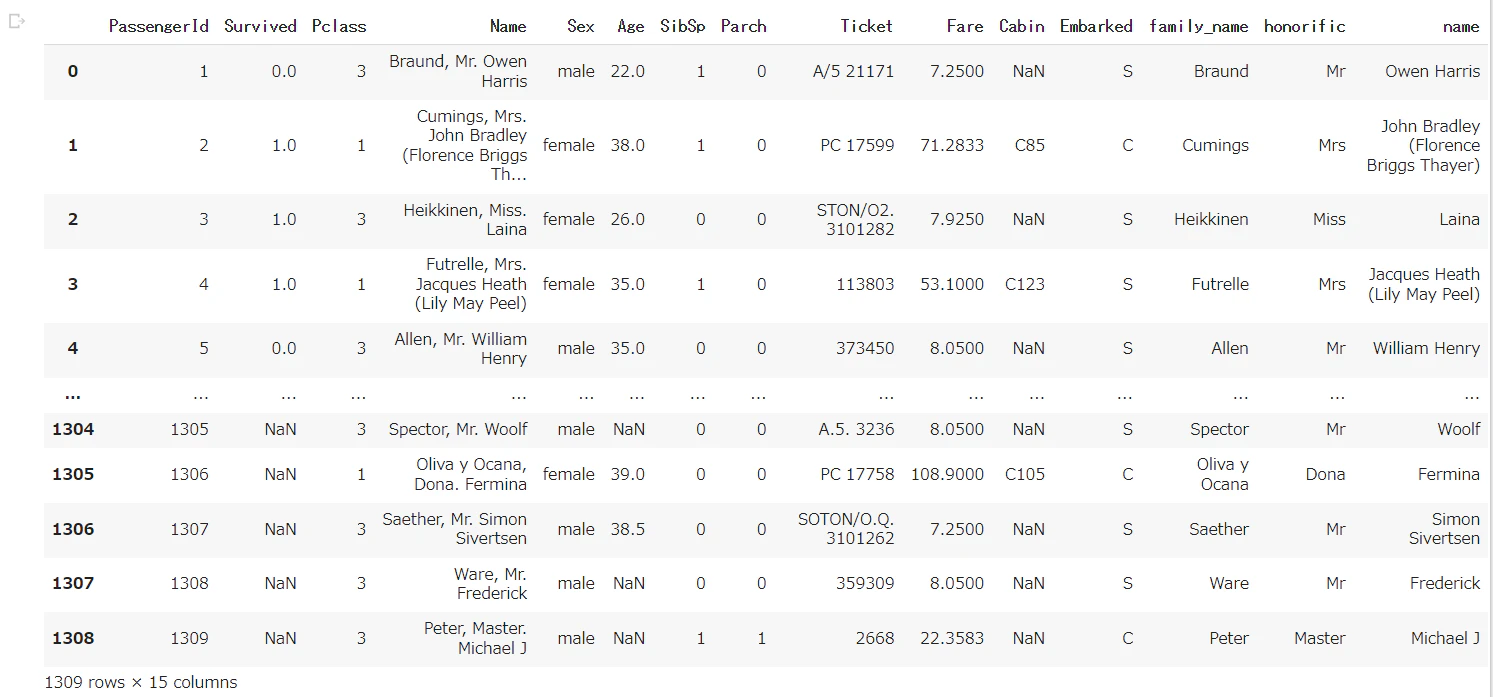
# dfを横に結合
all_df = pd.concat([all_df, name_df], axis=1)
all_df
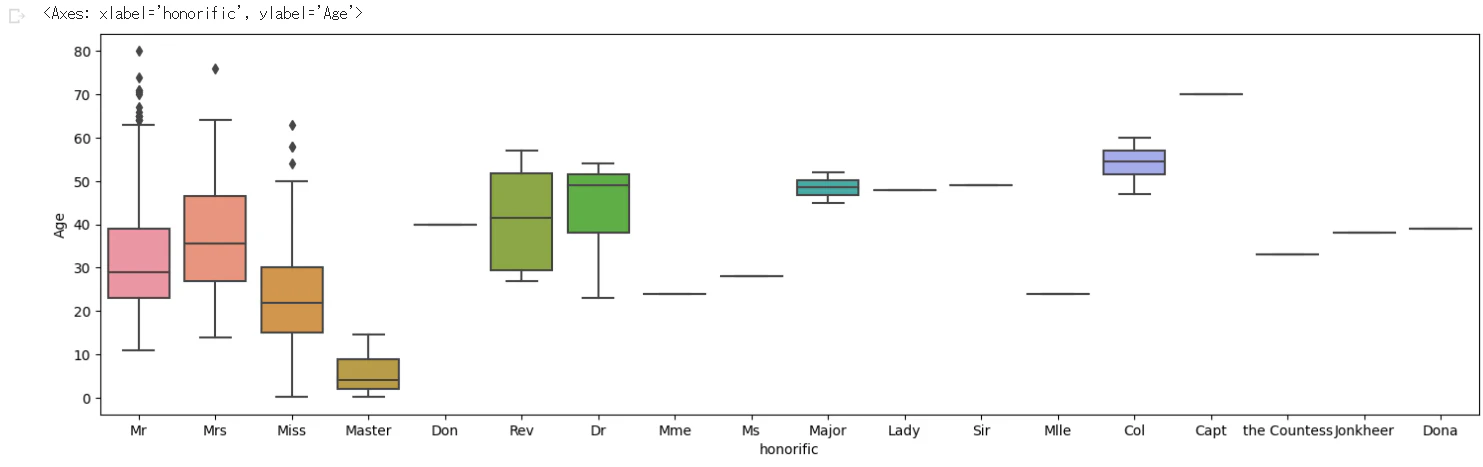
# 敬称別の分布
plt.figure(figsize=(18, 5))
sns.boxplot(x="honorific", y="Age", data=all_df)
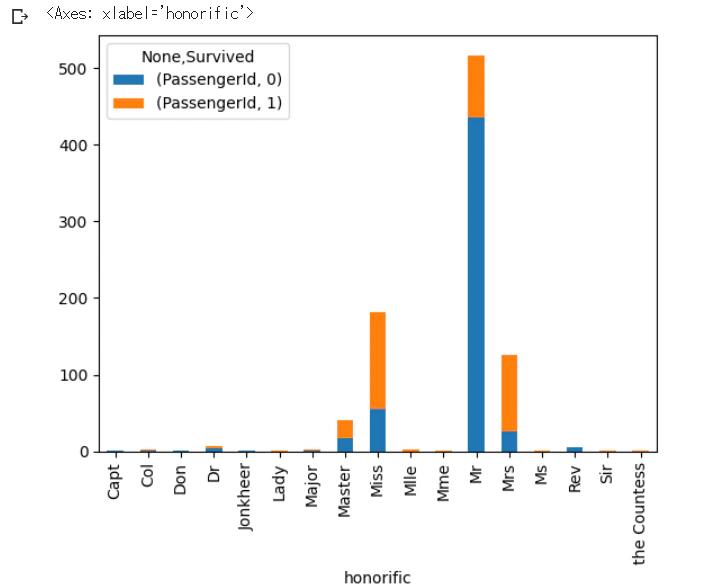
MissとMirsは生存率が高く、Mrは死亡率が高い
# 元のdfにname_dfを結合
train_df = pd.concat([train_df, name_df[0:len(train_df)].reset_index(drop=True)], axis=1)
test_df = pd.concat([train_df, name_df[len(train_df):].reset_index(drop=True)], axis=1)
# 敬称別で生存比を確認
honorific_df = train_df[["honorific", "Survived", "PassengerId"]].dropna().groupby(["honorific", "Survived"]).count().unstack()
honorific_df.plot.bar(stacked=True)
年齢の欠損は敬称ごとの平均値で補完
# 敬称ごとの平均値を出す
honorific_age_mean = all_df[["honorific", "Age"]].groupby("honorific").mean().reset_index()
honorific_age_mean.columns = ["honorific", "honorific_age"]
# 敬称ごとの平均値カラムを用意し、NULLの場合代入
all_df = pd.merge(all_df, honorific_age_mean, on="honorific", how="left")
all_df.loc[(all_df["Age"].isnull(), "Age")] = all_df["honorific_age"]
# 不要な列削除
all_df = all_df.drop(["honorific_age"], axis=1)
家族人数を追加
# 家族人数カラムを用意
all_df["family_num"] = all_df["Parch"] + all_df["SibSp"]
all_df["family_num"].value_counts()

# 一人乗船フラグを用意
all_df.loc[all_df["family_num"] == 0, "alone"] = 1
all_df["alone"].fillna(0, inplace=True)
all_df
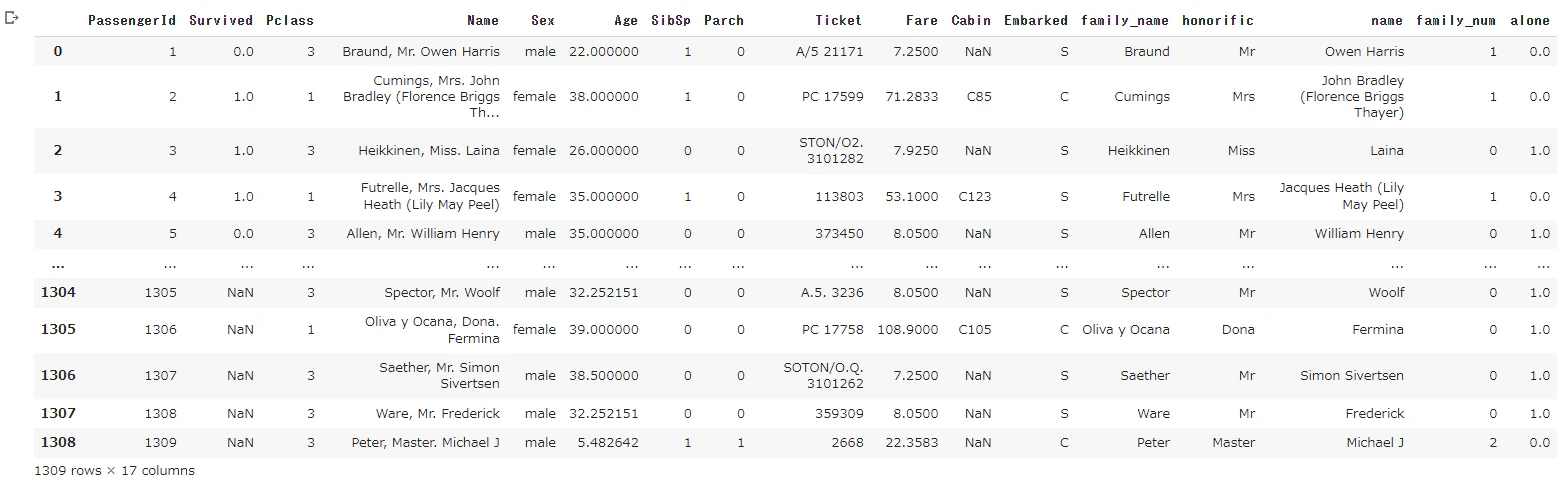
カテゴリ変数を数値に変換
# 不使用のカラム削除
all_df = all_df.drop(["PassengerId", "Name", "family_name", "name", "Ticket", "Cabin"], axis=1)
all_df.head()
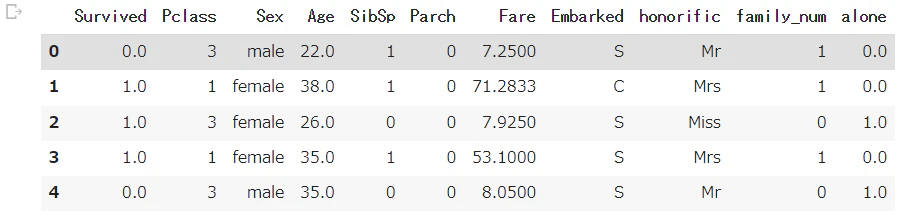
# カテゴリ変数として管理
categories = all_df.columns[all_df.dtypes == "object"]
print(categories)

# 敬称は5種類に統一
all_df.loc[~((all_df["honorific"] == "Mr") |
(all_df["honorific"] == "Miss") |
(all_df["honorific"] == "Mrs") |
(all_df["honorific"] == "Master")), "honorific"] = "other"
all_df.honorific.value_counts()

# 使用するライブラリをインポート
from sklearn.preprocessing import LabelEncoder
# 欠損値をNaNで埋める
all_df["Embarked"].fillna("missing", inplace=True)
# Sexを数値変換
le = LabelEncoder()
le = le.fit(all_df["Sex"])
all_df["Sex"] = le.transform(all_df["Sex"])
# 残りはまとめて
for cat in categories:
le = LabelEncoder()
if all_df[cat].dtypes == "object":
le = le.fit(all_df[cat])
all_df[cat] = le.transform(all_df[cat])
all_df.head()
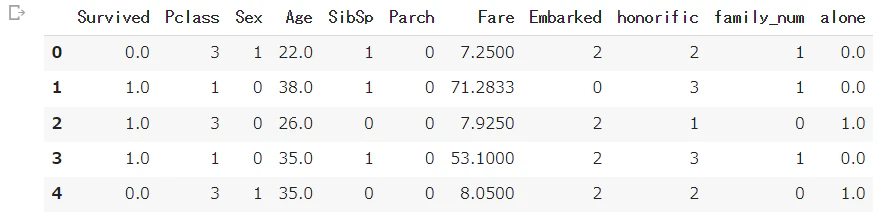
データを学習用とテスト用に戻す
train_X = all_df[~all_df["Survived"].isnull()].drop("Survived", axis=1).reset_index(drop=True)
train_Y = train_df["Survived"]
test_X = all_df[all_df["Survived"].isnull()].drop("Survived", axis=1).reset_index(drop=True)
モデリング
LightGBMでトライ
# 使用するライブラリをインポート
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
X_train, X_valid, y_train, y_valid = train_test_split(train_X, train_Y, test_size=0.2)
# データセット
categories = ["Embarked", "Pclass", "Sex", "honorific", "alone"]
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categories)
lgb_eval = lgb.Dataset(X_valid, y_valid, categorical_feature=categories, reference=lgb_train)
# パラメーター設定
lgbm_params = {
"objective":"binary",
"random_seed":1234
}
model_lgb = lgb.train(lgbm_params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval=10)
※一部のライブラリが最新バージョンに対応してない模様
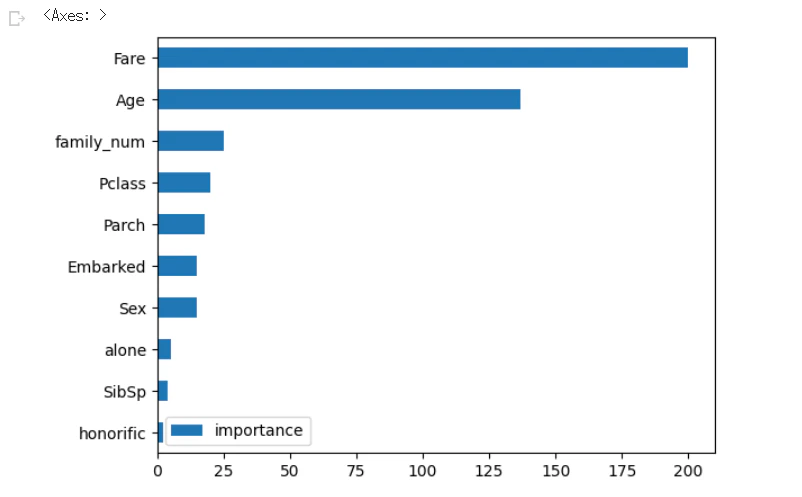
Fare, Ageが重要な変数
# 各変数の重要度
model_lgb.feature_importance()
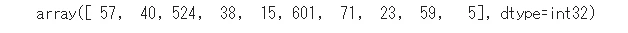
# 可視化
importance = pd.DataFrame(model_lgb.feature_importance(), index=X_train.columns, columns=["importance"]).sort_values(by="importance", ascending=True)
importance.plot.barh()
# 最も精度の高い学習モデルを適用
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
# accuracyを計算
from sklearn.metrics import accuracy_score
accuracy_score(y_valid, np.round(y_pred))
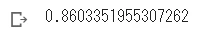
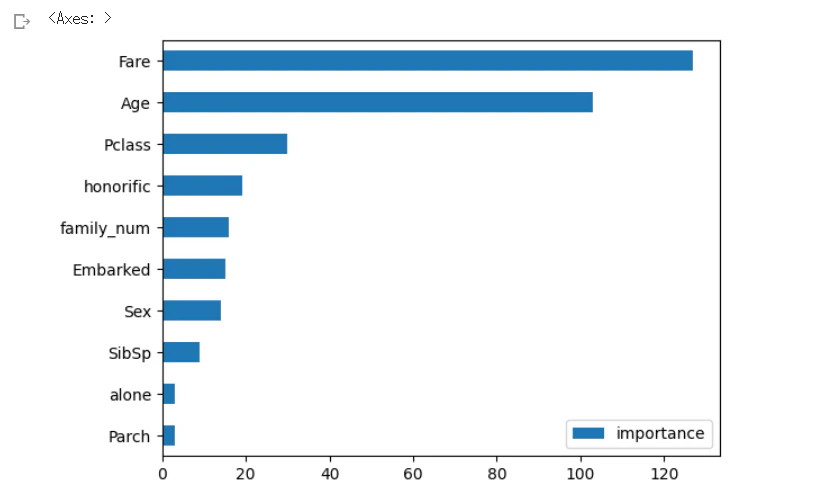
ハイパーパラメータを変更
# パラメーターを再設定
lgbm_params = {
"objective":"binary",
"max_bin":331,
"num_leaves":20,
"min_data_in_leaf":57,
"random_seed":1234
}
categories = ["Embarked", "Pclass", "Sex", "honorific", "alone"]
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categories)
lgb_eval = lgb.Dataset(X_valid, y_valid, categorical_feature=categories, reference=lgb_train)
model_lgb = lgb.train(lgbm_params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval=10)

# 可視化
importance = pd.DataFrame(model_lgb.feature_importance(), index=X_train.columns, columns=["importance"]).sort_values(by="importance", ascending=True)
importance.plot.barh()
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
# accuracyを計算
from sklearn.metrics import accuracy_score
accuracy_score(y_valid, np.round(y_pred))
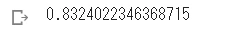
クロスバリデーション
# 3分割
folds = 3
kf = KFold(n_splits=folds)
models = []
for train_index, val_index in kf.split(train_X):
X_train = train_X.iloc[train_index]
X_valid = train_X.iloc[val_index]
y_train = train_Y.iloc[train_index]
y_valid = train_Y.iloc[val_index]
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categories)
lgb_eval = lgb.Dataset(X_valid, y_valid, categorical_feature=categories, reference=lgb_train)
model_lgb = lgb.train(lgbm_params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval=10
)
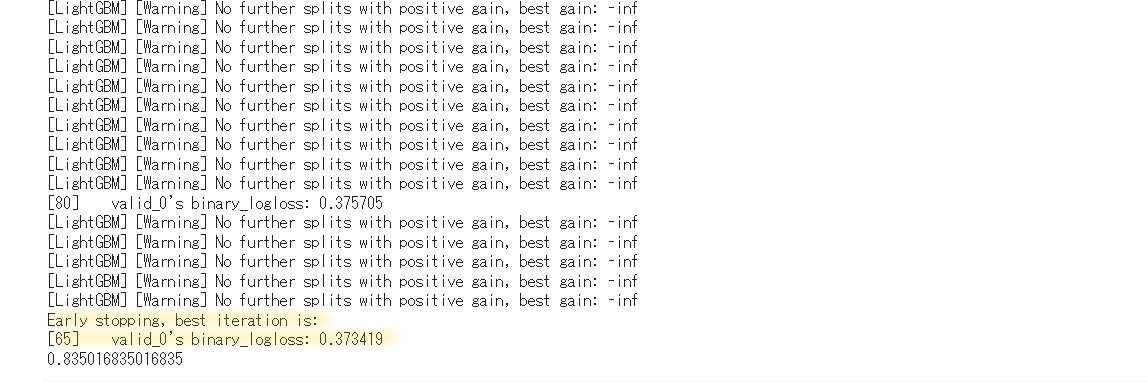
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
print(accuracy_score(y_valid, np.round(y_pred)))
models.append(model_lgb)
# テストデータの結果を予測して格納
preds = []
for model in models:
pred = model.predict(test_X)
preds.append(pred)
# 平均
preds_array = np.array(preds)
preds_mean = np.mean(preds_array, axis=0)
# 予測生存確率を0か1に変換、0.5より大きいと1
preds_int = (preds_mean > 0.5).astype(int)
submission["Survived"] = preds_int
submission
結果をcsvに書きだす
# csvに書き出し
submission.to_csv("Titanic_submit01.csv", index=False)
# 内容確認
!cat Titanic_submit01.csv

# ローカルにダウンロード
from google.colab import files
files.download("Titanic_submit01.csv")
Submit