これは何の記事?
ELO MERCHANT CATEGORY RECOMMENDATIONコンペの学習ログです
特徴量エンジニアリングを行います(▶前回の記事はこちら)
※途中からvscodeに環境を切り替え(▶参考記事)
環境
VSCode
記事の流れ
- 特徴量群の作成
- 統計的な特徴量群の作成
- null処理
- train_dfに結合
特徴量群の作成
①card_idの取引回数
# card_idの取引回数カラムを追加
transaction_counts = historical_df[["card_id", "purchase_date"]].groupby("card_id").count().reset_index()
transaction_counts.columns = ["card_id", "transaction_counts"]
# train_dfにtransaction_countsを結合
train_df = pd.merge(train_df, transaction_counts, on="card_id", how="left")
②card_idの平均取引額
# card_idの平均取引額カラムを追加
avg_purchase_amount = historical_df[["card_id", "purchase_amount"]].groupby("card_id").mean().reset_index()
avg_purchase_amount.columns = ["card_id", "avg_purchase_amount"]
# train_dfにavg_purchase_amountを結合
train_df = pd.merge(train_df, avg_purchase_amount, on="card_id", how="left")
③各card_idの取引merchantの多様性(取引を行ったユニークな店舗数)
# card_idの取引merchantのユニーク数
merchant_variety = historical_df[["card_id", "merchant_id"]].groupby("card_id").nunique().reset_index()
merchant_variety.columns = ["card_id", "merchant_variety"]
# train_dfにmerchant_varietyを結合
train_df = pd.merge(train_df, merchant_variety, on="card_id", how="left")
④各card_id最頻のmerchantカテゴリ(最も利用した店舗カテゴリ)
# card_idの最頻のmerchantカテゴリ
most_common_merchant = historical_df[["card_id", "merchant_category_id"]].groupby("card_id").agg(lambda x: x.value_counts().index[0]).reset_index()
most_common_merchant.columns = ["card_id", "most_common_merchant"]
# train_dfにmost_common_merchantを結合
train_df = pd.merge(train_df, most_common_merchant, on="card_id", how="left")
⑤各card_idのcityごとの取引回数
# card_idのcityごとの取引回数
most_common_city = historical_df[["card_id", "city_id"]].groupby("card_id").agg(lambda x: x.value_counts().index[0]).reset_index()
most_common_city.columns = ["card_id", "most_common_city"]
# train_dfにmost_common_cityを結合
train_df = pd.merge(train_df, most_common_city, on="card_id", how="left")
追加で特徴量群の作成
⑥card_idごとの統計量
# historical_dfをcard_idでグループ化し、指定の統計量を計算
historical_stats = historical_df.groupby("card_id").agg({
"purchase_amount": ["max", "min", "var"],
"installments": ["sum", "max", "min", "mean"]
})
historical_stats.head()
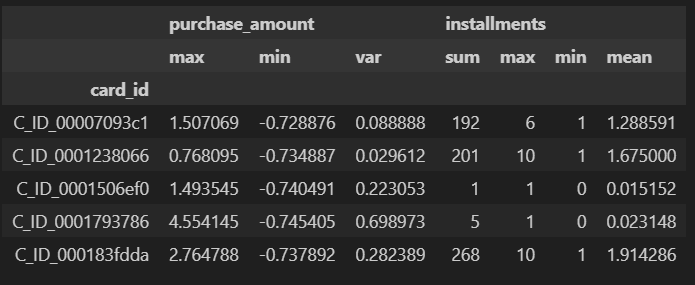
# カラム名を分かりやすく
historical_stats.columns = ["_".join(col).strip() for col in historical_stats.columns.values]
historical_stats.head()

# Indexの再設定
historical_stats.reset_index(inplace=True)
historical_stats.head()

# 欠損値確認
historical_stats.isnull().sum()
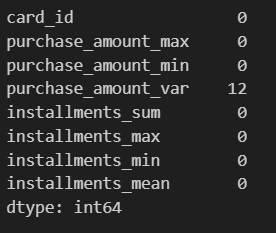
# purchase_amount_varの欠損値を0で補完
historical_stats["purchase_amount_var"].fillna(0, inplace=True)
# train_dfに特徴量を結合
train_df = pd.merge(train_df, historical_stats, on="card_id", how="left")
ここでfeatureという特徴量をまとめるための箱を作成する。特徴量の確認を行い、大丈夫そうならあとでまとめてtrain_dfに結合
# featureというdfを用意、card_idで一意に
feature = pd.DataFrame(historical_df["card_id"].unique(), columns=["card_id"])
feature.head()
⑦各card_idの利用期間
# purchase_dateを日付型に変換
historical_df["purchase_date"] = pd.to_datetime(historical_df["purchase_date"])
# 利用期間の最大と最小
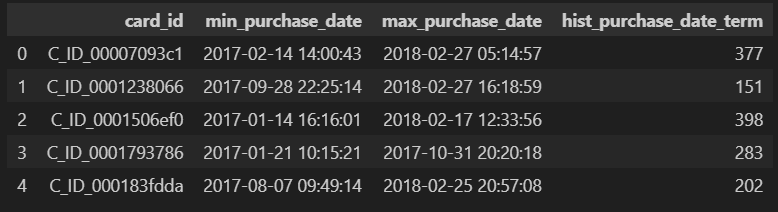
tmp = historical_df[["card_id", "purchase_date"]].groupby("card_id").agg(["min", "max"]).reset_index()
tmp.columns = ["card_id", "min_purchase_date", "max_purchase_date"]
tmp.head()
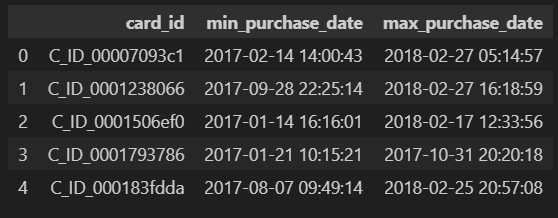
# 差分をdt.daysで日単位で出力
tmp["hist_purchase_date_term"] = (tmp["max_purchase_date"] - tmp["min_purchase_date"]).dt.days
tmp.head()
# 利用期間のみfeatureに結合
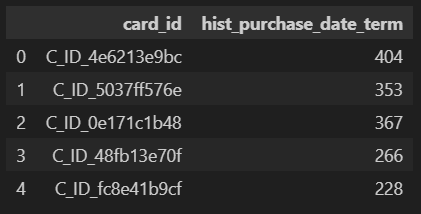
feature = pd.merge(feature, tmp[["card_id", "hist_purchase_date_term"]], on="card_id", how="left")
feature.head()
⑧各card_idの月当たりの平均利用回数
# sizeメソッドで、cadr_idの各purchase_dateの月単位で何回利用されたか集計
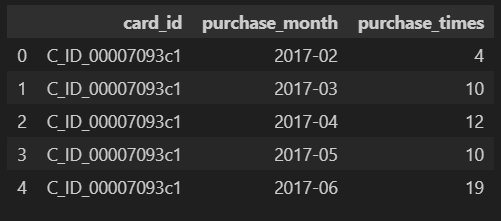
tmp = historical_df.groupby(['card_id', historical_df['purchase_date'].dt.to_period("M")]).size().reset_index()
tmp.columns = ["card_id", "purchase_month", "purchase_times"]
tmp.head()
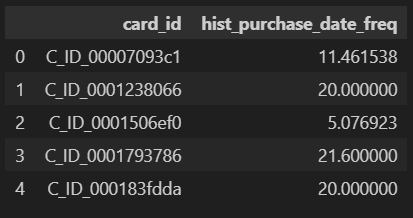
tmp = tmp[["card_id", "purchase_times"]].groupby("card_id").mean().reset_index()
tmp.columns = ["card_id", "hist_purchase_date_freq"]
tmp.head()
feature = pd.merge(feature, tmp[["card_id", "hist_purchase_date_freq"]], on="card_id", how="left")
feature.head()
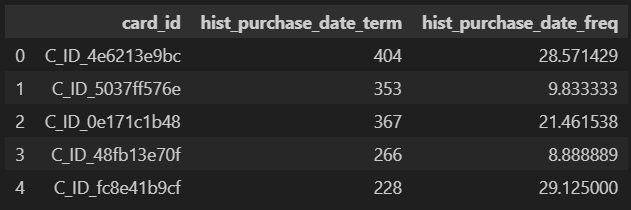
⑨各card_idごとのmonth_lagの統計量
tmp = historical_df[["card_id", "month_lag"]].groupby("card_id").agg(["mean", "min", "max", "var"]).reset_index()
tmp.head()
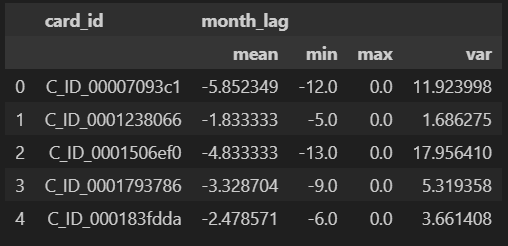
tmp.columns = ["card_id", "hist_lag_mean", "hist_lag_min", "hist_lag_max", "hist_lag_var"]
feature = pd.merge(feature, tmp, on="card_id", how="left")
feature.head()

⑩各card_idごとのauthorized_flagのカウント
# authorized_flagのカウント
tmp = historical_df.groupby(["card_id", "authorized_flag"]).size().reset_index()
tmp.head()
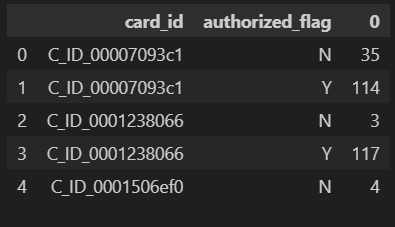
# 出力方法を変える
tmp = historical_df.groupby(["card_id", "authorized_flag"]).size().unstack().reset_index()
tmp.columns = ["card_id", "authorized_flag_N", "authorized_flag_Y"]
tmp.head()
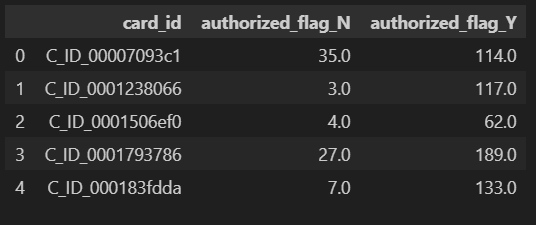
# featureに結合
feature = pd.merge(feature, tmp, on="card_id", how="left")
feature.head()
⑪各card_idごとのcategory_1のカウント
# category_1のカウント
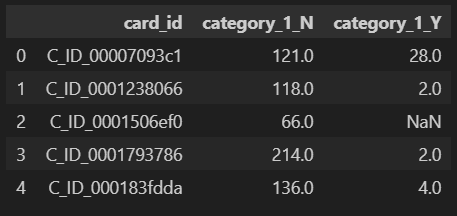
tmp = historical_df.groupby(["card_id", "category_1"]).size().unstack().reset_index()
tmp.columns = ["card_id", "category_1_N", "category_1_Y"]
tmp.head()
# 比率に変換
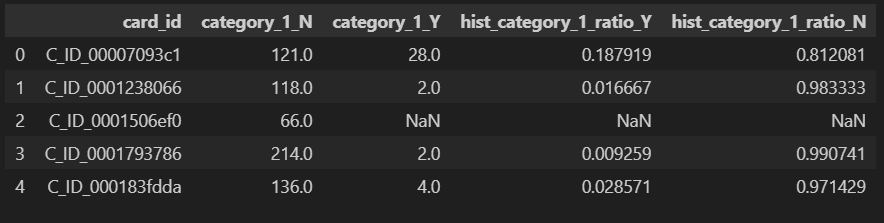
tmp["hist_category_1_ratio_Y"] = tmp["category_1_Y"] / (tmp["category_1_N"] + tmp["category_1_Y"])
tmp["hist_category_1_ratio_N"] = tmp["category_1_N"] / (tmp["category_1_N"] + tmp["category_1_Y"])
tmp.head()
⑫category_2,3の最頻値
# category_2, category_3の最頻値
for col in ["category_2", "category_3"]:
tmp = historical_df.groupby("card_id")[col].apply(lambda x: x.mode()[0] if len(x.mode()) > 0 else np.nan).reset_index()
tmp.columns = ["card_id", f"hist_{col}_freq"]
feature = pd.merge(feature, tmp, on="card_id", how="left")
feature.head()

null処理
NULLが発生していることを確認
feature.isnull().sum()
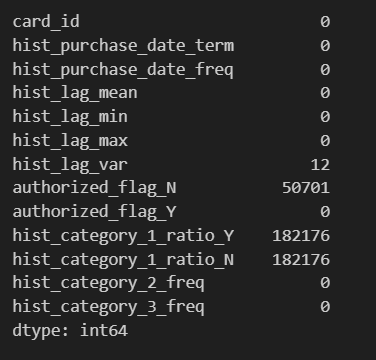
hist_lag_var にNULLが発生するのはcard_idが一つしかなく、差分が取れなかったため
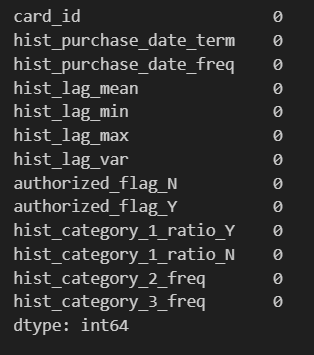
# hist_lag_varは0で埋める
feature["hist_lag_var"].fillna(0, inplace=True)
authorized_flag_N にNULLが発生するのは、card_idに対して"Y"しか存在しなかったため。他も同様。
# 他も0で埋める
feature["authorized_flag_N"].fillna(0, inplace=True)
feature["hist_category_1_ratio_Y"].fillna(0, inplace=True)
feature["hist_category_1_ratio_N"].fillna(0, inplace=True)
train_dfに結合
featureをtrain_dfに結合
train_df = pd.merge(train_df, feature, on="card_id", how="left")
train_df.head()
~part4に続く~