これは何の記事?
Google colabで巨大なデータを扱おうとすると、RAM容量オーバーでクラッシュする事態が発生
VScodeに切り替えることに
流れを簡単に記載するので誰かの参考になれば
環境
VScode
記事の流れ
- 環境構築の流れ
- ローカルcsvファイルを読み込む
- 補足(Google colab)
環境構築までの流れ
1. VSCodeをインストール
https://code.visualstudio.com/download

2. ターミナル ⇒ 新しいターミナルを開く

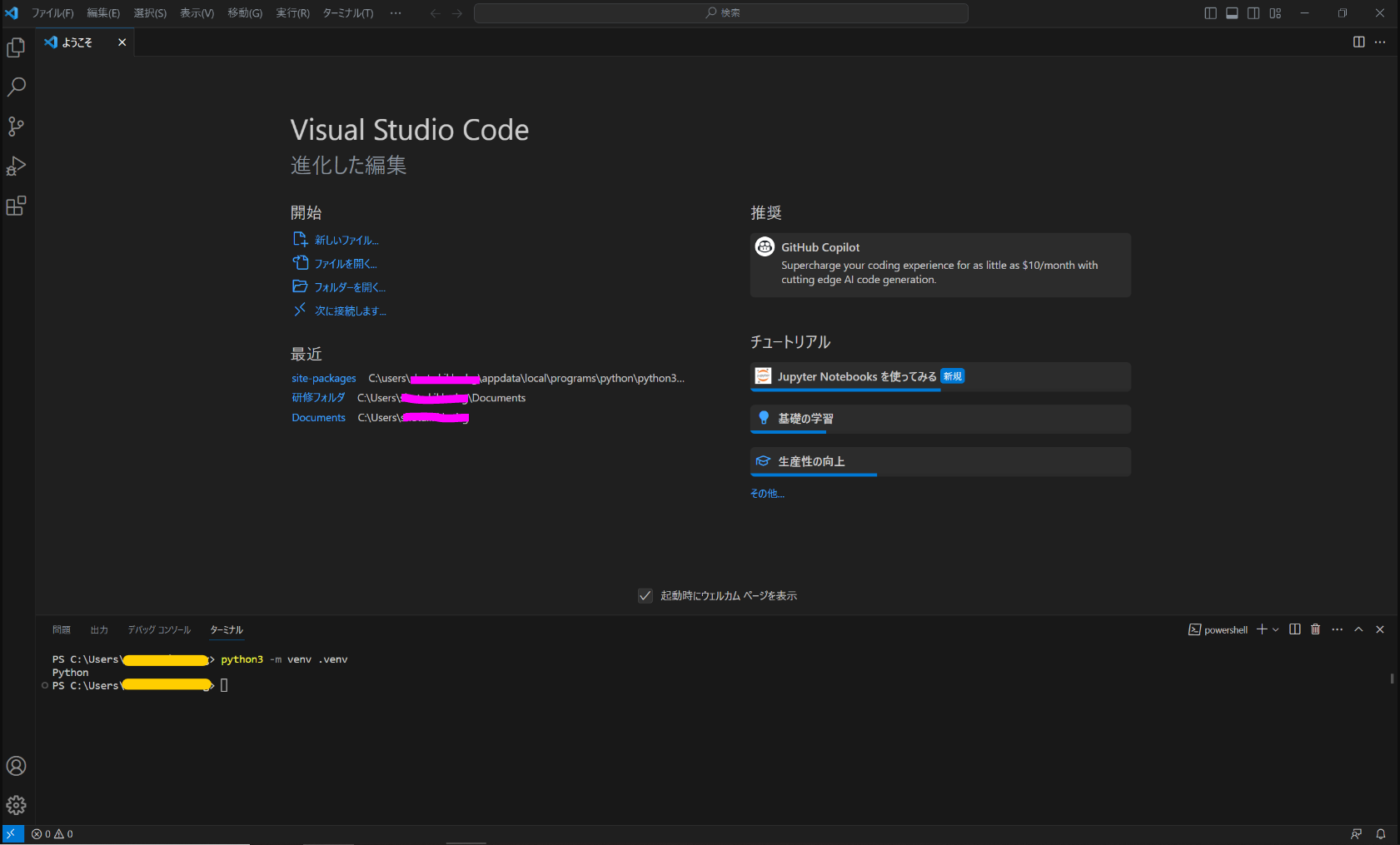
3. 仮想環境
ターミナルに「python3 -m venv .venv」と入れて実行
4. Jupiterパッケージをインストール
ターミナルに「pip install jupyter」と入れて実行
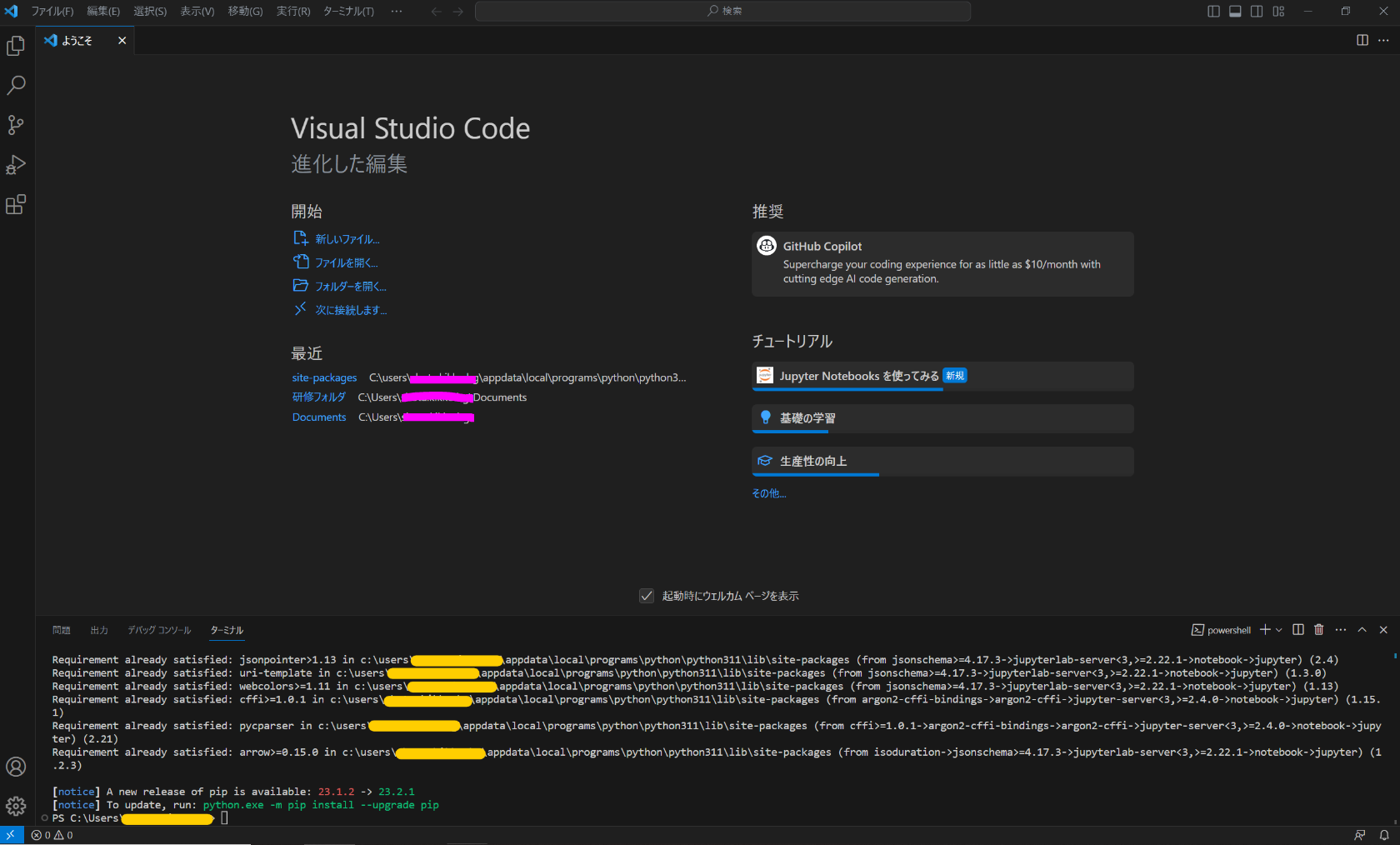
※もしpipコマンドをインストールできていない場合、以下からインストール
https://pypi.org/project/ipykernel/
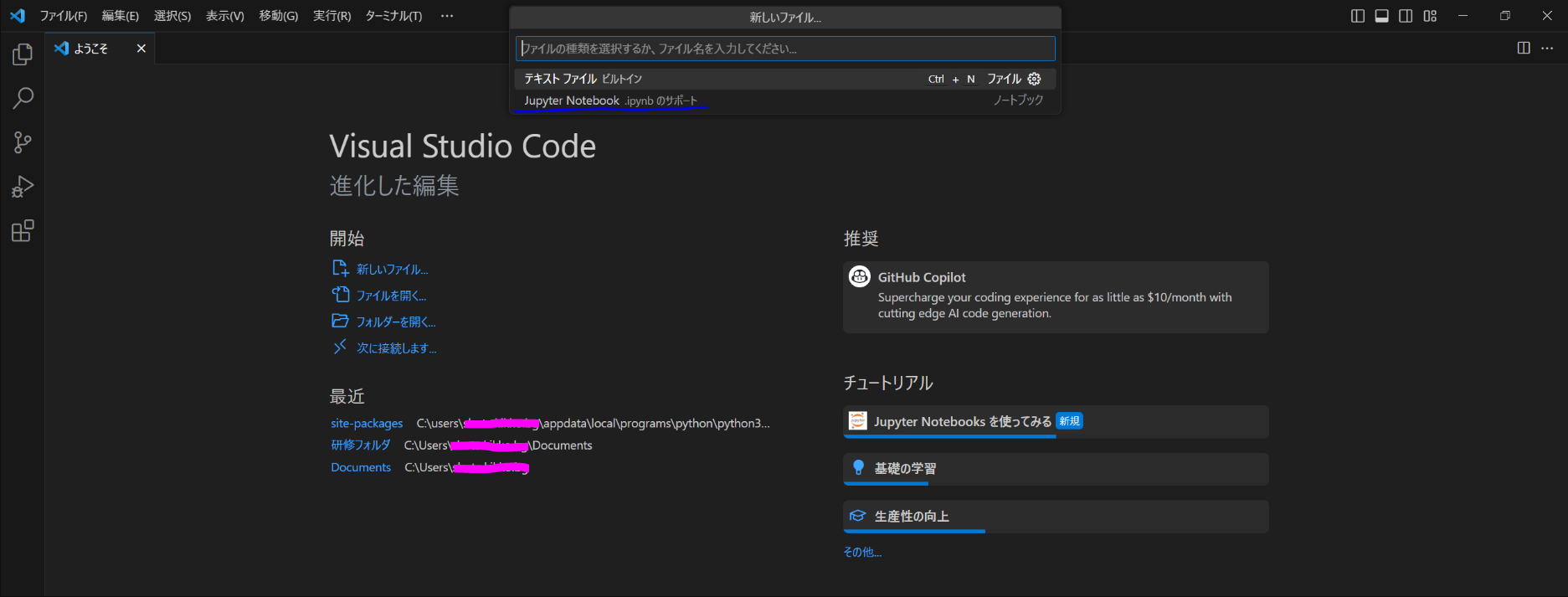
5. 新しいファイルを開く
ファイル ⇒ 新しいファイルからJupiter Notebookを開く
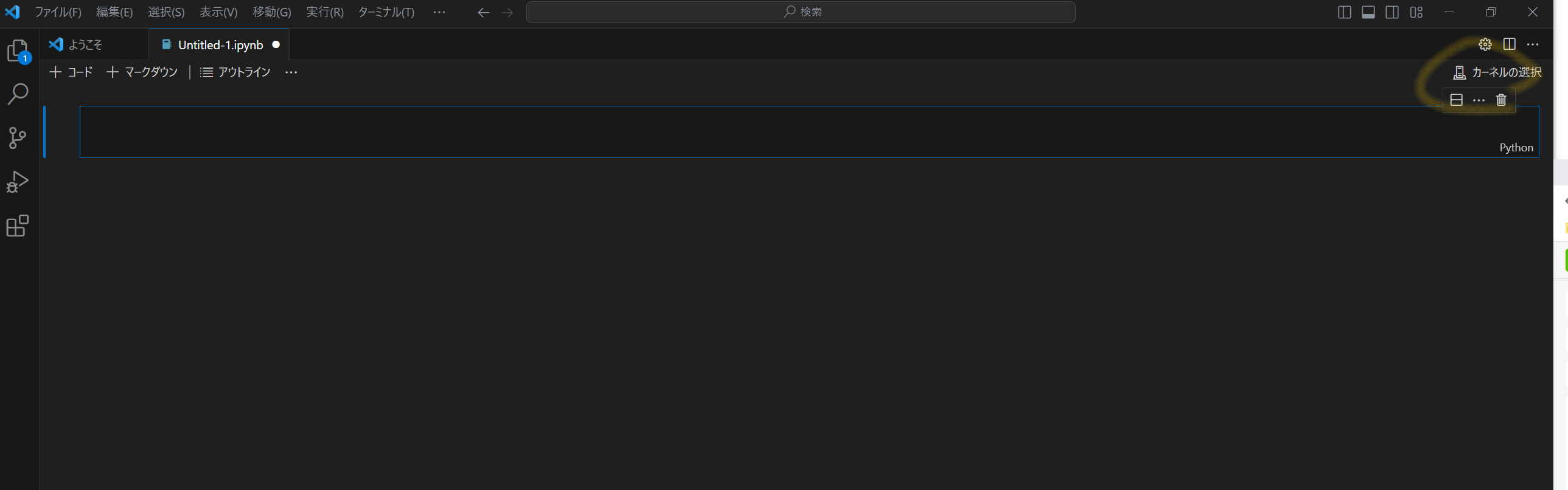
6. カーネルの選択
Pythonを選択、これで環境構築完了
ローカルファイルを読み込むまでの流れ
1. 必要なモジュールを読み込む
「pip install pandas」で実行
他にも、numpy や matplotlib など必要なものをすべて入れる

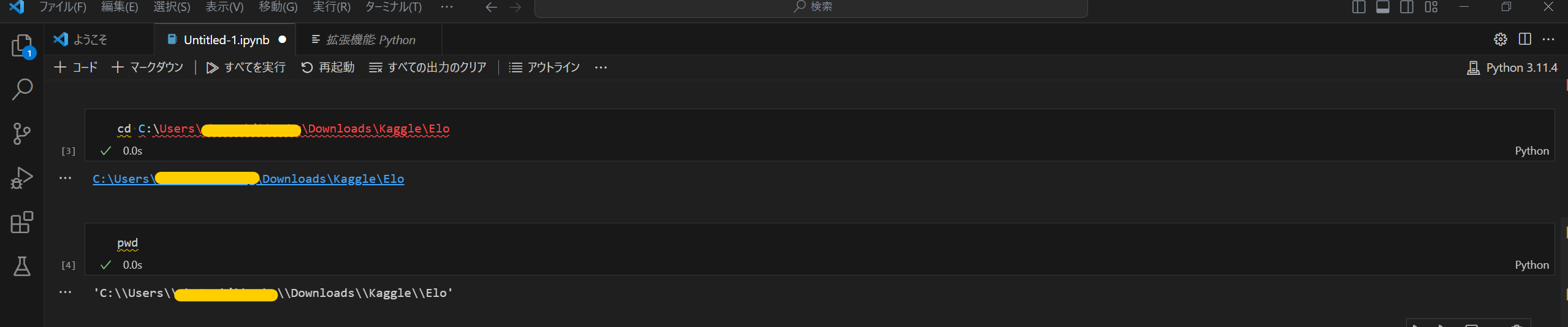
2. cdメソッドで読み込みファイルの位置を指定
「cd C: (ディレクトリ ※ファイルの位置)」を入れ実行

要はフォルダのこの部分をコピペ
※試しにpwdメソッドを実行すると、現在位置が先ほど指定したディレクトリになっている
3. 訓練データを読み込む
read_csv("ファイル名")で読み込める

補足
もし容量的にGoogle colabで間に合うなら、無理してVSCodeでしなくてもよいかも。例:Titanic分析
その際、環境構築(csv読み込ませまで)は以下参照
https://qiita.com/kame_house_0828/items/aa68ea187cf5c02b6b36