おつかれさまです。
必要に迫られており、クソ焦って勉強した。
とりあえずWEB上でカンニングできるように、1番素人がしっくりきそうなデータ分析手順のカンニングシートをQiitaにアップ。
必要なライブラリのインストール
# pandasはデータの取扱系ライブラリ
import pandas as pd
# とくにDataFrameはよく使うので、個別importしておく
from pandas import DataFrame
# numpyは行列計算系ライブラリ
import numpy as np
# matplotlibとseabornはグラフ系ライブラリ
import matplotlib.pyplot as plt
import seaborn as sns
# Jupyter Notebookを使う想定なのでブラウザ上にグラフ表示できるように設定
%matplotlib inline
データの取り込み
CSVファイルで取り込む場合は、
実行しているipynbファイルと同じディレクトリにCSVファイルおいた状態で、
df = pd.read_csv('CSVファイル名', header = None)
# `header=None`を指定せず`pd.read_csv('CSVファイル名')`とした場合は1行目が自動的にカラム名として挿入される
Excelファイルで取り込む場合は、
実行しているipynbファイルと同じディレクトリにExcelファイルおいた状態で、
df = pd.read_excel('Excelファイル名', sheetname='シート名', header = None)
# `header=None`を指定せず`pd.read_excel('Excelファイル名', sheetname='シート名')`とした場合は1行目が自動的にカラム名として挿入される
コピペで取り込む場合は、
コピーした状態で、
df = pd.read_clipboard(header = None)
# `header=None`を指定せず`pd.read_clipboard()`とした場合は1行目が自動的にカラム名として挿入される
とりあえず、今回のサンプルデータは、
https://www.kaggle.com/c/titanic/data
のtraining.csvと仮定してすすめてきまーす。
Kaggleで有名なタイタニックでどんな人が生還したかのデータです!
データを眺める
実際のデータを見たいときは、
df.head()
# ()の中が何もなければ最初の5行、数字いれればその行数分を上から見れる
各列のデータ数や平均、標準偏差、最小値、中央値、最高値とかを見たいときは、
df.describe()
単純にデータの行列のサイズを見たいときは、
df.shape
カラム名を変える
カラム名が気に入らないときは、
df = df.rename(columns = {'変更前カラム名1': '変更後カラム名1', '変更前カラム名2': '変更後カラム名2'})
欠損データがどれくらいあるか調べる
df.info()
欠損データをなんとかする
欠損データを消す場合は、
df = df.dropna()
# 1つでもNaNが含まれる行が削除される
あるカラムに欠損データがあって、その行を消す場合は、
df = df.dropna(subset=['カラム名'])
# 指定したカラム名にNaNが含まれる行が削除される
欠損データに列ごとに平均値、中央値、最頻値を入れたいときは、
# 平均値を入れたいときは
df = df.fillna(df.mean())
# 中央値を入れたいときは
df = df.fillna(df.median())
# 最頻値を入れたいときは
df = df.fillna(df.mode().iloc[0])
欠損データに前後の値から推測してデータを入れたいときは、
# 列方向に推測したデータを入れたいときは
df = df.interpolate()
# 行方向に推測したデータを入れたいときは
df = df.interpolate(axis=1)
欠損データに同列の前後の値を入れたいときは、
# 前の値を入れたいときは
df = df.fillna(method='ffill')
# 後の値を入れたいときは
df = df.fillna(method='bfill')
欠損データに特定のデータを入れる場合は、
df = df.fillna(入れたい値)
列によって欠損データに入れたい値が異なるときは、
df = df.fillna({'カラム名1':入れたい値,'カラム名2':入れたい値,'カラム名3':入れたい値})
新しい列を追加する
たとえば、Sexカラムの「male」「female」のデータをもとに、「0」「1」データのMaleカラムを作りたいときは
df['Male'] = df['Sex'].map({'male':1,'female':0})
たとえば、Ageカラムをもとに、「adult」「child」「baby」のデータを持つAge_rangeカラムを作りたいときは
def adult_child_baby(age):
if age < 4:
return 'baby'
elif age < 19:
return 'child'
else:
return 'adult'
df['Age_range'] = df['Age'].apply(adult_child_baby)
たとえば、SexカラムとAge_rangeカラムをもとに、「0」「1」データのBoyカラムを作りたいときは
def check_boy(human):
sex, age_range = human
if sex = 'male' and age_range = 'child':
return 1
else:
return 0
df['Boy'] = df[['Sex','Age_range']].apply(check_boy,axis=1)
最終的に下記のような感じになります!
ピボット化
Excelでいうピボットテーブルみたいなもの。
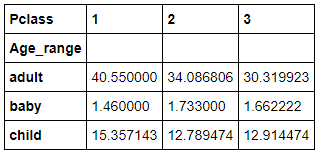
たとえば、行がAge_rangeで列がPclassで値をAgeの平均値にしたいときは、
pd.pivot_table(df, values='Age',index='Age_range', columns='Pclass', aggfunc='mean')
# valueに値、indexに行項目、columnsに列項目、aggfuncに値の計算方法を指定
で下記みたいな感じになります!
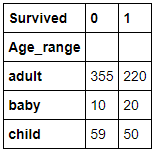
たとえば、行がAge_rangeで列がSurvivedで値をAgeのデータ数にしたいときは、
df.pivot_table(values='Age',index='Age_range',columns='Survived',aggfunc="count")
で下記みたいな感じになります!
グループ化
そのまんま、グルーピングです。
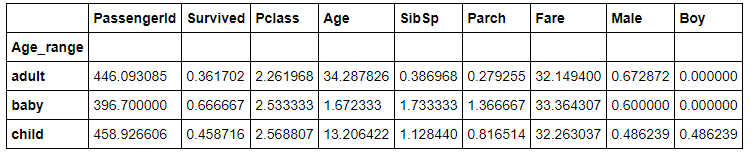
たとえば、Age_rangeごとに平均値を出したいときは、
df.groupby(['Age_range']).mean()
で下記みたいになります!
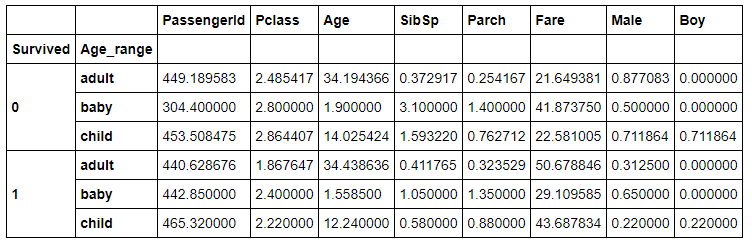
グルービングは二重にできたりもします。
例えば下記みたいな感じ。
df.groupby(['Survived','Age_range']).mean()
すると下記みたいになります。
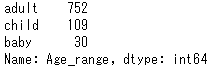
カウント
これも結構つかえます。
例えばAge_rangeのそれぞれのデータ数がほしいときは、
df['Age_range'].value_counts()
でこんな感じに表示されます!
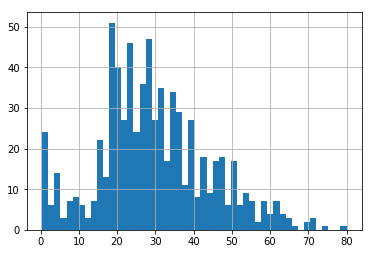
棒グラフ化
まずはヒストグラムってやつから。
df['Age'].hist(bins=50)
# binsで棒の本数を指定
つぎに棒グラフ。
# まずSurvivedごとにAgeの標準偏差をしらべておく
std = df.groupby('Survived')['Age'].std()
# SurvivedごとのAgeの平均値を棒グラフ(bar)にして標準偏差の棒をつける
df.groupby('Survived')['Age'].mean().plot(yerr=std, kind='bar', legend=False)
# kind='bar'で棒グラフになる
# legendはTrue, Falseで凡例はつけるかどうか
# yerrでエラーバーをいれれる
つぎは横棒グラフ。
df.groupby('Sex')['Age'].mean().plot(kind='barh', legend=False, figsize=(5,3))
# kind='barh'で横棒になる
# figsizeでグラフの大きさ
次は、データ数の棒グラフ化。
sns.countplot('Age_range',data=df)
# 引数にカテゴリーを指定
データ数の棒グラフ化は更に細分化できる。
sns.countplot('Age_range',data=df,hue='Survived', order=['adult','child','baby'])
# hueで細分化したいカテゴリを指定
# orderで棒グラフの順番を指定できる
Seaborn(barplot)を使うと、これらのカテゴリ分解やエラーバーが一瞬でできる!
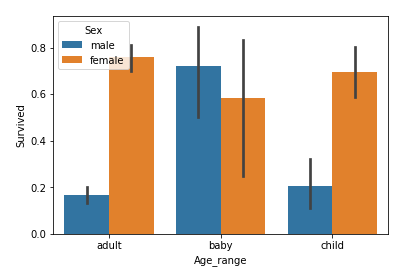
sns.barplot(x='Age_range', y='Survived', hue='Sex', data = df)
# エラーバーは信頼区間95%を表現
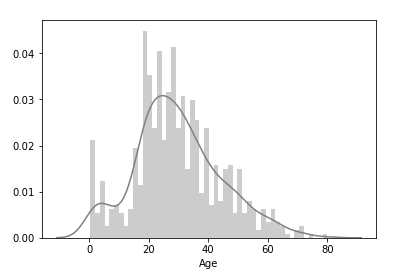
Seaborn(distplot)を使うと、ヒストグラムにそれっぽい曲線が追加される!
sns.distplot(df['Age'].dropna(), bins=50, color='gray')
# 曲線はカーネル密度推定
# distplotは欠損データがあるとエラーになるのでdropna()を忘れないこと
# colorで色が指定できたりもする
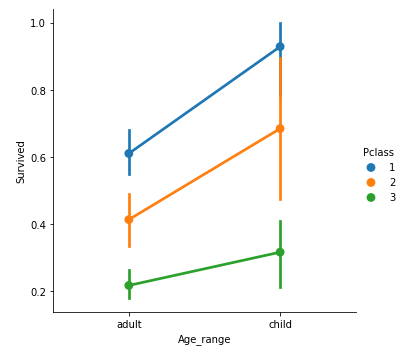
なんかそれっぽいグラフ化
何という名前かわからんが、Seaborn(factorplot)を使うと下記みたいになる。
sns.factorplot('Age_range','Survived',hue='Pclass',data=df, order=['adult','child'])
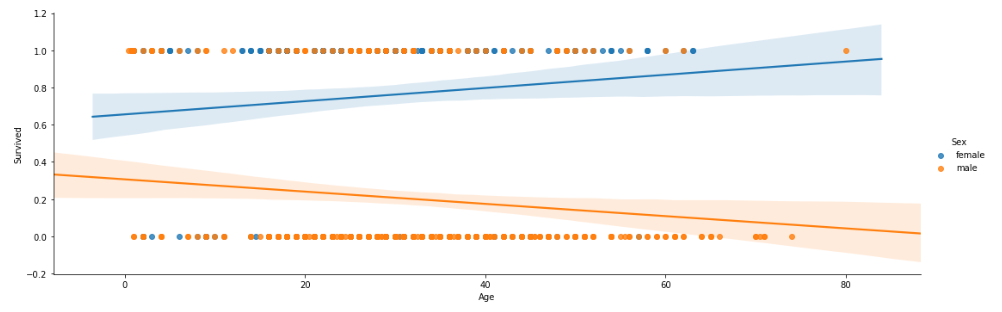
さらに何という名前かわからんが、Seaborn(lmplot)を使うと下記みたいになる。
sns.lmplot('Age','Survived', hue='Sex', data=df, hue_order=['female', 'male'], aspect=3)
# 直線は回帰直線
# 影は信頼区間95%を表現
# aspectでグラフの縦横比率を指定できる
散布クラフ化
タイタニックデータは数値データが少ないので、数値データの多い別のものを準備!
df2 = sns.load_dataset('car_crashes')
df2.head()
こんな感じです。
これは縁起悪いですが、クルマの事故データです。
pyplotのscatterメソッドをつかったら散布グラフになります!
plt.scatter(df2['speeding'], df2['alcohol'])
# 第一引数にX軸にしたいもの、第二引数にY軸にしたいものを指定
pyplotはいろんなことを指定できます。
plt.scatter(df2['speeding'], df2['alcohol'])
# X軸とY軸の最大値と最小値を指定
plt.xlim([0, 10])
plt.ylim([0, 12])
# X軸とY軸の名前を指定
plt.xlabel('speeding')
plt.ylabel('alcohol')
でも!Seaborn(scatterplot)を使うと一瞬で散布グラフができます!
sns.scatterplot(x='speeding', y='alcohol', data=df2)
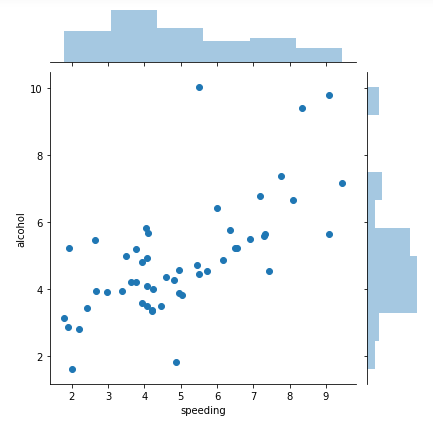
さらにSeaborn(jointplot)を使うと散布グラフとヒストグラムの合体版になります!
sns.jointplot('speeding', 'alcohol', df2)
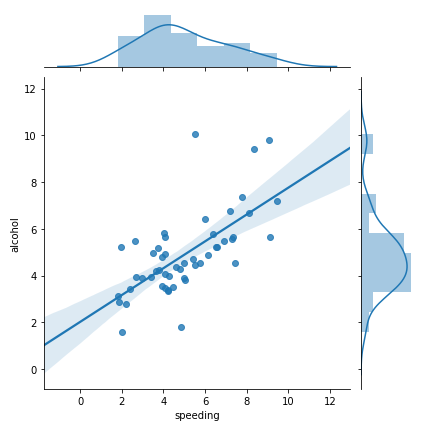
さらにさらに!なんかスゲーことになります。
sns.jointplot('speeding', 'alcohol', df2, kind="reg")
# kind="reg"を指定すると回帰直線と信頼区間95%の影がでてくる
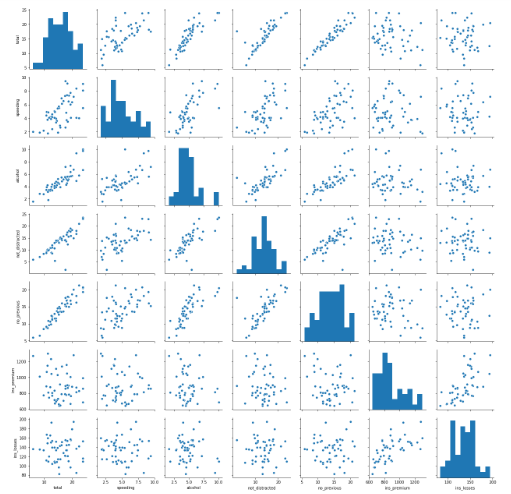
Seaborn(pairplot)を使うと、全通りの散布グラフ!!
sns.pairplot(df2)
# pairplotの引数は欠損値があるとエラーになる
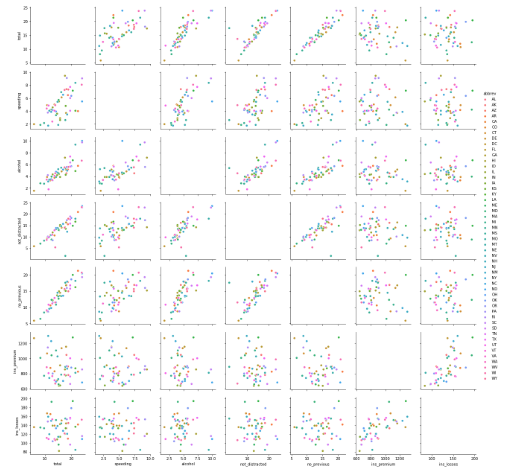
Seaborn(pairplot)でカテゴリ細分化までできる。
sns.pairplot(df2, hue='abbrev')
ヒートマップ
もはや説明不要だろう。
Seabornはかってにスゴいグラフになる。
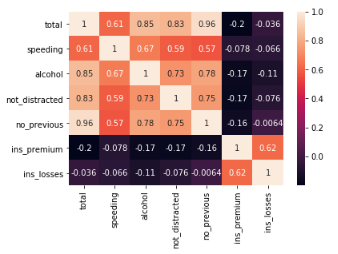
sns.heatmap(df2.corr(), annot=True)
# annot=Trueで各マスに数値が入る
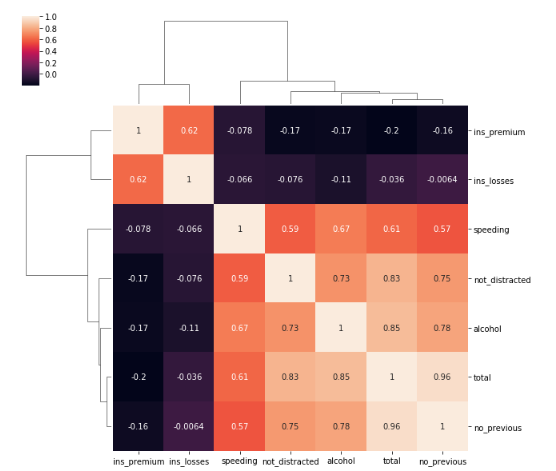
clustermapを使うと樹形図てきなものまで入る。
sns.clustermap(df2.corr(), annot=True)
折れ線グラフ
折れ線グラフは時系列データを対象にするとわかりやすいので、Googleの株価を取得してみる。
import pandas_datareader.data as pdr
import datetime
end = datetime.date.today()
start = end - datetime.timedelta(days=10)
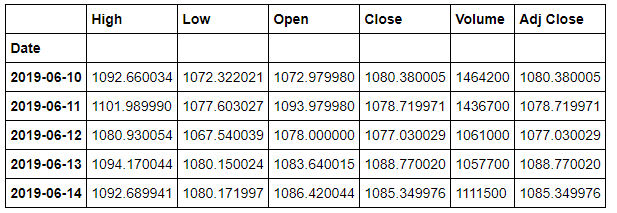
df3 = pdr.DataReader('GOOG', 'yahoo', start, end)
df3.head()
こんな感じ。
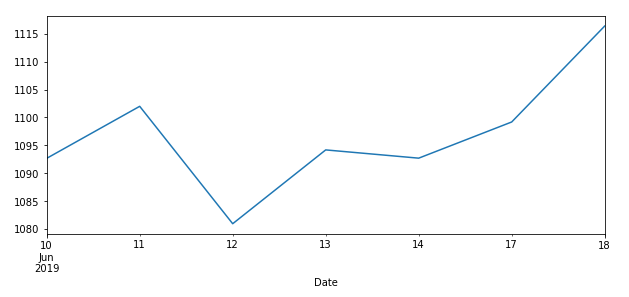
対象データに対してplotメソッドを使うと下記のような感じになる。
df3['High'].plot(legend=True, figsize=(10,4))
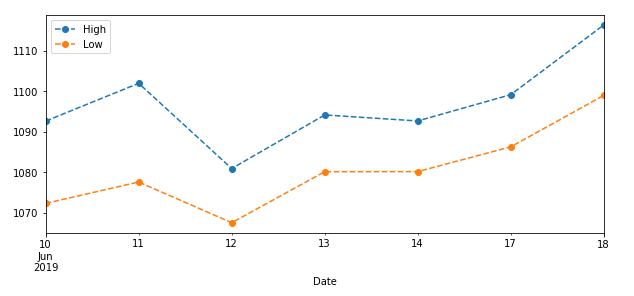
点や、点と点をむずぶ線のスタイルを変更することもできる。
df3[['High', 'Low']].plot(figsize=(10,4), legend=True, linestyle='--', marker='o')
# markerで点スタイルを指定
# linestyleで点と点を結ぶ線スタイルを指定
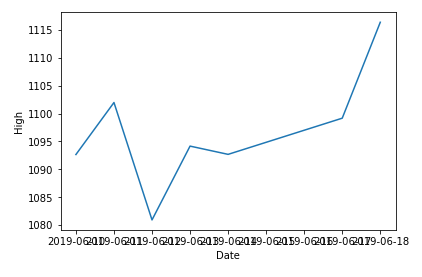
ここでやはりSeabornを使えば一瞬。
sns.lineplot(x=df3.index, y='High', data=df3)
ストーリー仕立てでイメージを深めるなら
ストーリー仕立てでイメージを深めるなら、こちらの教材が良い。有料なので、まずは無料部分を読んでニーズとマッチするか判断しましょう。
https://www.techpit.jp/courses/30/curriculums/31/sections/264/parts/906