pythonでデータを可視化するのにmatplotlibを使う人は多いと思いますが、seabornというmatplotlibのラッパーが素晴らしく便利です。
インストール
まずはseabornをインストールします。pipもしくはcondaでインストールできます。
pip install seaborn
conda install seaborn
前準備
seabornはnumpy, matplotlib, pandasに依存しているので、同時にimportします。
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
サンプルデータとして、titanic,tips,irisのデータセットを使います。
titanic = sns.load_dataset("titanic")
tips = sns.load_dataset("tips")
iris = sns.load_dataset("iris")
変数分布を知る
とりあえずある変数の分布はどうなっているのだろう?と可視化することはよくあります。seabornだと、matplotlib以上の情報を簡単に与えてくれるため、得られるインサイトの費用対効果がとても大きいです。早速見てみましょう。
1変数の場合(distplot)
まず、データを用意します。標準正規分布に従う乱数を100件用意しておきます。
x = np.random.normal(size=100)
distplot()関数を使うと、ヒストグラムとKDEが同時に表示されます。これだけでも結構便利です。ヒストグラムだけ表示したり、より細かい分布をみたり等の調節もできます。
sns.distplot(x)

2変数の場合(jointplot)
次に、変数をxとyの2つに増やしてみます。pandasのDataFrameを用います。
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"])
df.head()
こんなデータです。
x y
0 1.512856 2.527512
1 0.311464 2.143966
2 0.774056 1.870894
3 -0.995346 -0.371048
4 0.756758 2.866903
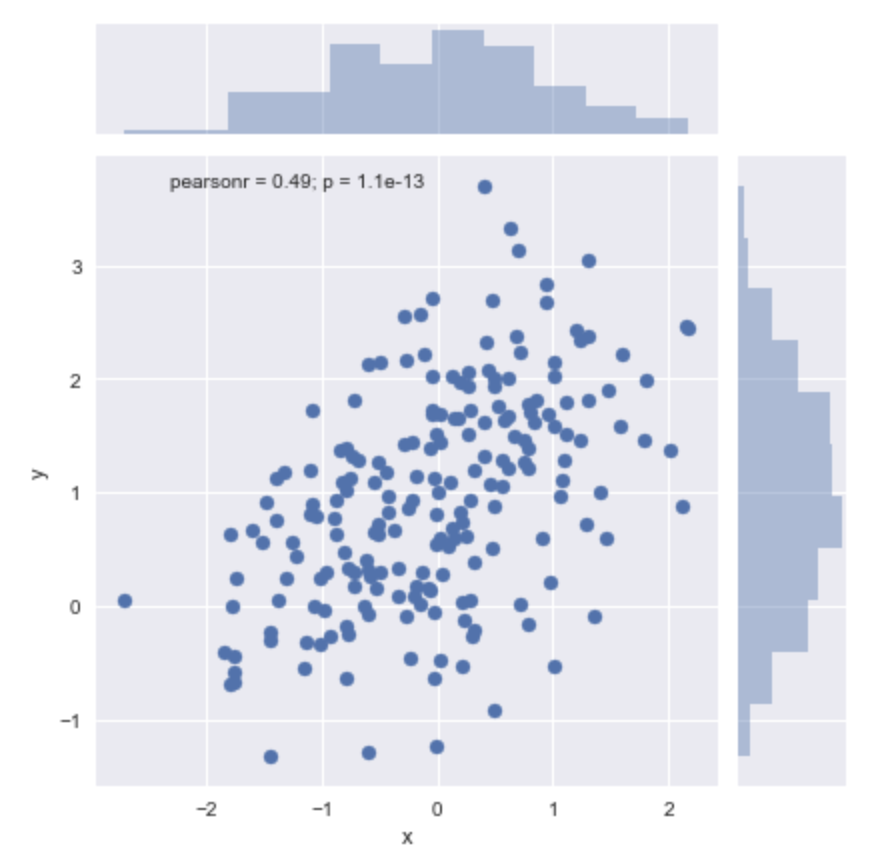
2変数の分布を可視化するのには、jointplot()関数を用います。x軸・y軸・dataを指定してあげればOKです。2変数の散布図・各変数のヒストグラムが同時に見られます。素晴らしすぎる。
sns.jointplot(x="x", y="y", data=df)
カテゴリ情報を知る
データを眺めるとき、「カテゴリごとに変数の分布がどうなっているか」などカテゴリごとに変数の特徴を押さえたいケースがよくあります。seabornはカテゴリに対する可視化にもうってつけです。
カテゴリごとのデータの分布を見る
曜日ごとにチップとして支払われている額に傾向があるのか、男性・女性では、喫煙かどうかは影響するの? はい、stripplot()関数を使えば一発で可視化できます。
sns.stripplot(x="day", y="total_bill", data=tips)

swarmplot()関数にすると、データの分布が重ならないように調節してくれます。
sns.swarmplot(x="day", y="total_bill", data=tips)

hueという引数に新たな変数を設定することで、新たな変数を加えることができます。性別という情報も加えて可視化してみます。どこまでやってくれるんだseabornは。
sns.swarmplot(x="day", y="total_bill", hue="sex", data=tips)

カテゴリごとのデータの分散を見る
箱ひげ図を用いてデータを可視化することで、上の散布図で見るよりも正確にデータを捉えることができます。boxplot()関数を用います。
sns.boxplot(x="day", y="total_bill", data=tips)

統計的にデータを推定する
barplot()関数を用いて、棒グラフを書くことができます。以下ではtitanicのデータセットを使います。性別・客室の階級と生存有無にどのような関係があるかを一発で可視化しています。
sns.barplot(x="sex", y="survived", hue="class", data=titanic)

poitplot()関数を用いることで、上のデータをシンプルに置き換えることができます。
sns.pointplot(x="sex", y="survived", hue="class", data=titanic)

線形回帰モデルを知る
線形回帰直線を描く
seabornを使えば、分布図の上に線形回帰直線を引くのも一瞬でできます。regplot()関数を用います。
sns.regplot(x="total_bill", y="tip", data=tips)

同じことは、lmplot()関数でもできます。両者の違いは、regplot()は、データをpandas.Seriesやpandas.DataFrameなどどのような形で渡しても良い一方で、lmplot()は、必ずxとyを指定しなければならない点です。
sns.lmplot(x="total_bill", y="tip", data=tips)

上と同じように、hueを与えれば変数を増やして可視化することができます。
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips)

巨大なデータセットから効率よくインサイトを得る
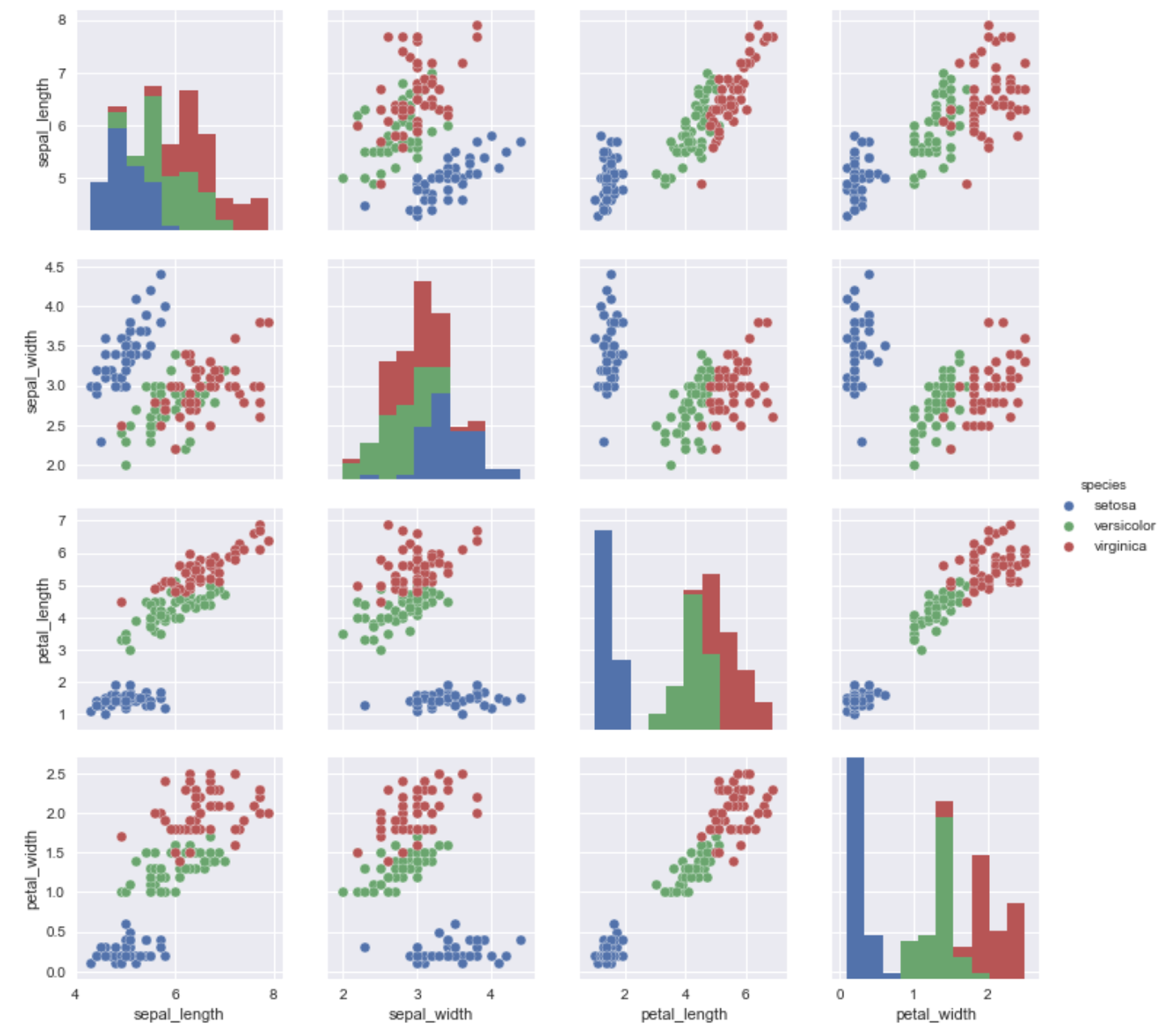
とりあえずデータが手元にあるけど、何もわかっていない。どこから手をつけたらいいのやら、、、となった場面でもseabornが活躍します。irisのデータセットを用います。pairplot()関数を用いることで一気に関係性を可視化できます。これは、データを触りはじめる一番最初にやりたいことです。
sns.pairplot(iris, hue="species", size=2.5)
まとめ
seabornを使ってデータを可視化してみました。今までmatplotlibを使ってデータを可視化していた自分としては、素晴らしいの一言につきます。データを触っている以上、それを可視化してインサイトを得ることは基本中の基本なので、これだけ便利にかつ高性能に可視化をしてくれるツールは使わなければなりません。
ブログも書いているのでぜひ!