はじめに
本記事では、Microsoft Cognitive Servicesの機能であるText Analytics API、Content Moderatorを紹介します。ユーザの口コミ情報をスコアづけする、投稿の中の不適切な言葉を監視するといった要件に人工知能APIを利用できないかと思い調べてみました。
なお、本記事は2017年12月現在の情報をもとに執筆してます。
Cognitive Servicesとは
Cognitive ServicesはMicrosoft AI Platformの一部で、様々な機能をAPI経由で簡単に利用でき、 わずか数行のコードで強力なアルゴリズムを持つインテリジェントなアプリの作成が可能になります。
2017年12月現在 、視覚、音声、言語、ナレッジ、検索の5つのカテゴリで、29の機能(プレビューを含む)が公開されています。

Cognitive Servicesを使ってみる
Cognitive Services のAPIを動かすまでの流れを簡単に説明します。
API利用の準備
Cognitive Servicesは、30日間の試用版として利用する方法と、Microsoft Azureのサービスとして利用する方法があります。
30日間の試用版として利用する場合は、Cognitive Services 試用エクスペリエンス からAPIキーを取得します。
Microsoft Azureのサービスとして 利用する場合は、 Azureの ポータル画面にログイン後、メニューから、インテリジェンス+分析グループにある Cognitive Services を選択します。Cognitive Serviceの中から利用する機能を選択しデプロイします。デプロイ後にRESOURCE MANAGEMENTのKeysからAPIキーを取得します。
なお、APIキーは、KEY1、KEY2の2つ表示されますが、どちらを利用しても同じです。
APIの実行
各機能のAPI仕様は、APIリファレンスのページで説明されています。
APIリファレンスのページから、Open API testing consoleを使用するとブラウザベースでAPIを実行できます。
-
APIリファレンス
-
Open API testing console
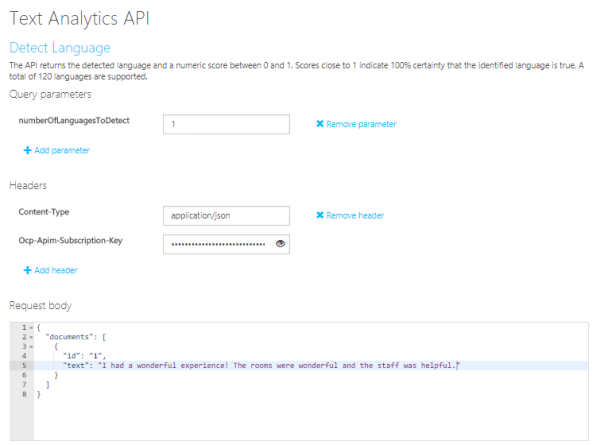
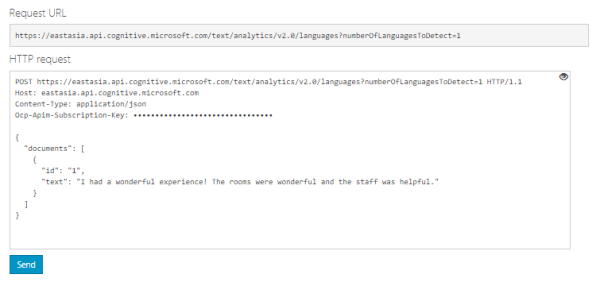
-
実行結果
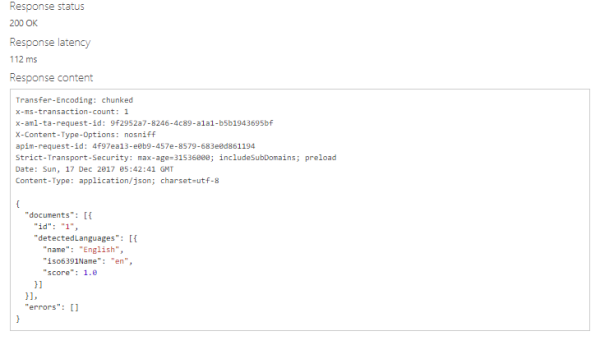
また、プログラムから実行する方法として、各言語の実装サンプルも確認できます。
テキストから情報を抽出する
「Text Analytics API」を使うと、テキストの言語、センチメント、キー フレーズを識別できます。今回は公開されているサンプルと同じ英文を使って説明しますが、日本語にも対応しています。
言語の識別
Detect Language APIを利用して、言語の識別をします。
リクエストパラメータ「numberOfLanguagesToDetect」に識別する言語の数を、リクエストヘッダ「Content-Type」にリクエストボディのメディアタイプ、「Ocp-Apim-Subscription-Key」にAPIキーを指定します。
リクエストボディにテキストを指定してAPIを実行します。
{
"documents": [
{
"id": "1",
"text": "I had a wonderful experience! The rooms were wonderful and the staff was helpful."
}
]
}
レスポンスとして、識別した言語の種類と、スコア(0~1)が返却されます。スコアが1に近づくほど識別結果が正確であることを示します。下記の実行結果は、指定したテキストが英語のテキストであることを識別できました。
{
"documents": [{
"id": "1",
"detectedLanguages": [{
"name": "English",
"iso6391Name": "en",
"score": 1.0
}]
}],
"errors": []
}
キーフレーズの抽出
Key Phrases APIを利用して、キーフレーズの抽出をします。
リクエストヘッダ「Content-Type」にリクエストボディのメディアタイプ、「Ocp-Apim-Subscription-Key」にAPIキーを指定します。
リクエストボディにテキストの言語とテキストを指定してAPIを実行します。
{
"documents": [
{
"language": "en",
"id": "1",
"text": "I had a wonderful experience! The rooms were wonderful and the staff was helpful."
}
]
}
レスポンスとして、指定したテキストのキーフレーズが返却されます。下記の実行結果は、指定したテキストから、「wonderful experience」、「staff」、「rooms」の3つのキーフレーズを抽出できました。
{
"documents": [{
"keyPhrases": ["wonderful experience", "staff", "rooms"],
"id": "1"
}],
"errors": []
}
センチメントの評価
Sentiment APIを利用して、センチメントの評価をします。
リクエストヘッダ「Content-Type」にリクエストボディのメディアタイプ、「Ocp-Apim-Subscription-Key」にAPIキーを指定します。
リクエストボディにテキストの言語とテキストを指定してAPIを実行します。
{
"documents": [
{
"language": "en",
"id": "1",
"text": "I had a wonderful experience! The rooms were wonderful and the staff was helpful."
},
{
"language": "en",
"id": "2",
"text": "I had a terrible time at the hotel. The staff was rude and the food was awful."
}
]
}
レスポンスとして、指定したテキストのセンチメントの評価結果のスコア(0~1)が返却されます。スコアは、1に近づくほど肯定的なテキストであることを、0に近づくほど否定的なテキストであることを示します。下記の実行結果は、1番目のテキスト(id:1)を肯定的、2番目のテキスト(id:2)を否定的と評価できました。
{
"documents": [{
"score": 0.95819461345672607,
"id": "1"
}, {
"score": 0.0020827054977416992,
"id": "2"
}],
"errors": []
}
テキストをモデレートする
「Content Moderator」の「Text Moderation API」を使うと、侮蔑的になり得る語句を検出、カスタムリストとの自動照合、個人を特定できる情報 (PII) の可能性の有無をチェックできます。今回は公開されているサンプルと同じ英文を使って説明しますが、日本語にも対応しています。
テキストのスクリーニング
Text - Screen APIを利用して、侮蔑的になり得る語句、個人を特定できる情報を検出します。
リクエストパラメータ「autocorrect」で自動訂正の実行有無(boolean)、「PII」に個人を特定できる情報の検出有無(boolean)、「listId」にカスタムリストのID、「language」に言語を指定します。
リクエストヘッダ「Content-Type」にリクエストボディのメディアタイプ、「Ocp-Apim-Subscription-Key」にAPIキーを指定します。
リクエストボディにテキストを指定してAPIを実行します。
Is this a crap email abcdef@abcd.com, phone: 6657789887, IP: 255.255.255.255, 1 Microsoft Way, Redmond, WA 98052
レスポンスとして、検出した侮蔑的になり得る語句、個人を特定できる情報が返却されます。下記の実行結果は、個人を特定できる情報として、Email、IPアドレス(IPA)、Phone、Addressを、侮蔑的になり得る語句(Terms)として「crap」を検出できました。
{
"OriginalText": "Is this a crap email abcdef@abcd.com, phone: 6657789887, IP: 255.255.255.255, 1 Microsoft Way, Redmond, WA 98052",
"NormalizedText": "Is this a crap email abide@ abed. com, phone: 6657789887, IP: 255. 255. 255. 255, 1 Microsoft Way, Redmond, WA 98052",
"AutoCorrectedText": "Is this a crap email abide@ abed. com, phone: 6657789887, IP: 255. 255. 255. 255, 1 Microsoft Way, Redmond, WA 98052",
"Misrepresentation": null,
"PII": {
"Email": [{
"Detected": "abcdef@abcd.com",
"SubType": "Regular",
"Text": "abcdef@abcd.com",
"Index": 21
}],
"IPA": [{
"SubType": "IPV4",
"Text": "255.255.255.255",
"Index": 61
}],
"Phone": [{
"CountryCode": "US",
"Text": "6657789887",
"Index": 45
}],
"Address": [{
"Text": "1 Microsoft Way, Redmond, WA 98052",
"Index": 78
}]
},
"Language": "eng",
"Terms": [{
"Index": 10,
"OriginalIndex": 10,
"ListId": 0,
"Term": "crap"
}],
"Status": {
"Code": 3000,
"Description": "OK",
"Exception": null
},
"TrackingId": "ae732ecc-1797-4acf-bce3-fbc8c5fd8678"
}
カスタムリストとの自動照合
「Content Moderator」の「List Management」を使うと、テキストのスクリーニングで使うカスタムリストを作成できます。
カスタムリストは以下の順番で作成します。
- リストの作成
Term Lists - Create APIでリストを作成します。
リクエストボディにリストの名前等を指定してAPIを実行します。
{
"Name": "MyCustomList",
"Description": "My custom lists of terms",
"Metadata":
{
"Category": "Test"
}
}
listId:7のリストが作成できました。
{
"Id": 7,
"Name": "MyCustomList",
"Description": "My custom lists of terms",
"Metadata": {
"Category": "Test"
}
}
- 語句の追加
Term - Add Term APIで作成したリストに語句を追加します。
リクエストパラメータに、リストのID(listId)、語句(term)、言語(language)を指定してAPIを実行します。
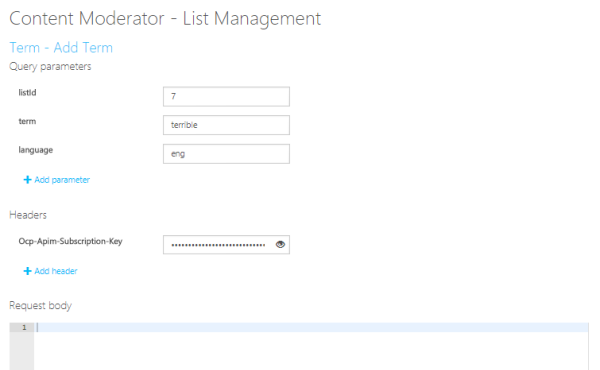
「terrible」を追加しました。
- サーチインデックスの更新
Term Lists - Refresh Search Index APIで更新したリストを反映します。
リクエストパラメータに、リストのID(listId)、言語(language)を指定してAPIを実行します。
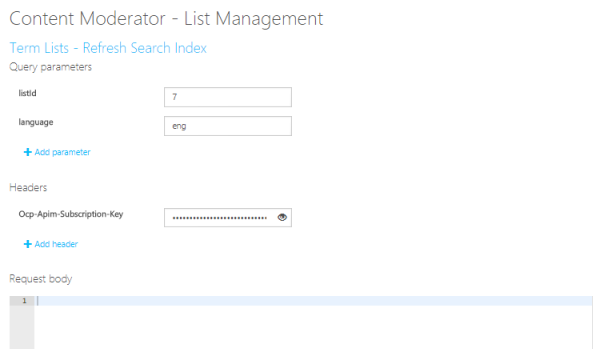
以下のテキストを指定して、Text - Screen APIを実行してみます。
I had a terrible time at the hotel. The staff was rude and the food was awful.
Is this a crap email abcdef@abcd.com, phone: 6657789887, IP: 255.255.255.255, 1 Microsoft Way, Redmond, WA 98052
下記の実行結果で、カスタムリストに指定した「terrible」を自動照合できました。
{
"OriginalText": "I had a terrible time at the hotel. The staff was rude and the food was awful.\nIs this a crap email abcdef@abcd.com, phone: 6657789887, IP: 255.255.255.255, 1 Microsoft Way, Redmond, WA 98052",
"NormalizedText": "I had a terrible time at the hotel. The staff was rude and the food was awful. \nIs this a crap email abcdef@ abcd. com, phone: 6657789887, IP: 255. 255. 255. 255, 1 Microsoft Way, Redmond, WA 98052",
"Misrepresentation": null,
"PII": {
"Email": [{
"Detected": "abcdef@abcd.com",
"SubType": "Regular",
"Text": "abcdef@abcd.com",
"Index": 100
}],
"IPA": [{
"SubType": "IPV4",
"Text": "255.255.255.255",
"Index": 140
}],
"Phone": [{
"CountryCode": "US",
"Text": "6657789887",
"Index": 124
}],
"Address": [{
"Text": "1 Microsoft Way, Redmond, WA 98052",
"Index": 157
}]
},
"Language": "eng",
"Terms": [{
"Index": 8,
"OriginalIndex": 8,
"ListId": 7,
"Term": "terrible"
}, {
"Index": 89,
"OriginalIndex": 89,
"ListId": 0,
"Term": "crap"
}],
"Status": {
"Code": 3000,
"Description": "OK",
"Exception": null
},
"TrackingId": "0dfd0059-b53f-4e80-90d7-06441ebcd1ed"
}
おわりに
Microsoft Cognitive Servicesの 機能であるText Analytics API、Content Moderatorを試してみました。Web APIを使うことでこれらの機能を簡単に利用でき、テキストから様々な情報が得られることはとても便利だと思いました。
日本語の認識についても対応していることを確認できましたが、抽出されるキーワードや、センチメントの評価結果の強弱のつき方と、実際にテキストを読んで得られる印象との間にはまだギャップがあるという感想も持ちました。現時点では得られた情報をどのように扱うかも活用のポイントになりそうです。
今回は機能の紹介となりましたが、日本語の文章をWeb APIで自在に解析でき、その結果をみながらシナリオを組み立てられるようになっていくと面白いですね。