はじめに
Treasure Workflowは、Treasure Data上でジョブワークフローを作成し、タスクの管理できます。
Data Connectorを使ったデータのインポート、 Presto, Hiveのクエリ実行とテーブル作成、他システムへのデータエクスポートに対応しています。
ベースとなっているエンジンはDigdagとしてOSS公開されており、様々なオペレーターを利用できます。
本記事では、Treasure Dataのクエリの実行結果を、Azureのサービスに連携(エクスポート)するTreasure Workflowの例を3つ紹介します。
- Microsoft Azure Blob Storageにファイルを出力する
- Microsoft SQL Databaseのテーブルに出力する
- Azure Webジョブを起動する
事前準備
本記事の説明に使用する分析データ、クエリについて記載します。
今回は分析データとして、Treasure Dataの初級ハンズオン(アクセスログ編)のアクセスログを使用しました。データインポート方法の手順に従ってセットアップします。
また、サンプルクエリとして、アクセスログから平均閲覧時間を集計するクエリを実行します。(使用するデータセットにあわせて、一部変更しています)
SELECT
m,
page_id,
AVG(browsing_time) AS avg_browsing_time,
VARIANCE(browsing_time) AS var_browsing_time,
COUNT(1) AS pv
FROM
(
SELECT m, page_id, 1.0*diff/60 AS browsing_time
FROM
(
-- URLを整形 (presto) --
SELECT
TD_TIME_FORMAT(time, 'yyyy-MM') AS m,
td_path AS page_id,
LEAD(time) OVER (PARTITION BY td_client_id, TD_TIME_FORMAT(time, 'yyyy-MM-dd') ORDER BY time) - time AS diff
FROM
access_log
ORDER BY time
) t1
WHERE 1.0*diff/60 < 10
) t
GROUP BY m, page_id
HAVING 10 <= COUNT(1)
ORDER BY m
クエリは、Treasure Data operatorsのtd>: Treasure Data queriesで実行できます。
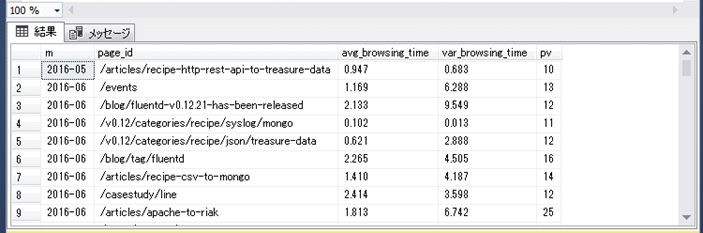
クエリの実行結果をテーブルに出力するワークフローを実行してみます。
このワークフローはqueries/browsing_time2.sqlのクエリを実行し、実行結果を使ってTreasure Databaseのbrowsing_time2テーブル作成します。
timezone: "Asia/Tokyo"
_export:
td:
database: td_test_db
+create_new_table_using_result_of_select:
td>: queries/browsing_time2.sql
create_table: browsing_time2
Treasure Databaseにテーブルが作成されています。
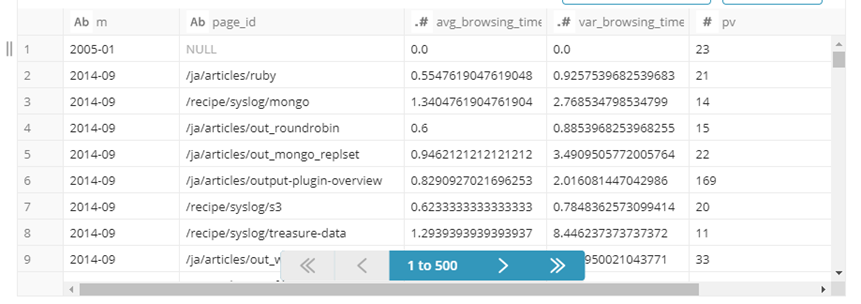
このクエリの実行結果を外部システムにエクスポートするデータとして使います。
| 項目名 | 説明 | サンプルデータ |
|---|---|---|
| m | 年月 | 2014-09 |
| page_id | ページ | /ja/articles/ruby |
| avg_browsing_time | 閲覧時間(平均) | 0.5547619047619048 |
| var_browsing_time | 閲覧時間(分散) | 0.9257539682539683 |
| pv | 閲覧数 | 21 |
Microsoft Azure Blob Storageにファイルを出力する
td>: Treasure Data queriesでクエリの実行結果を外部システムに出力するために、result_connection、result_settingsを使用します。result_connectionで利用するconnectionを指定し、result_settingsで追加設定をします。
クエリの実行結果をMicrosoft Azure Blob Storageに出力する手順を説明します。
Connectionの作成
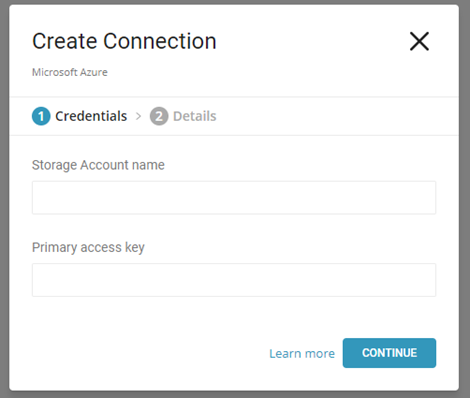
まず、Treasure Data consoleより、Connectionを作成します。
- 「Connections」より「Microsoft Azure」を選択します

- 「Storage Account name」、「Primary access key」を入力し、「CONTINUE」をクリックします
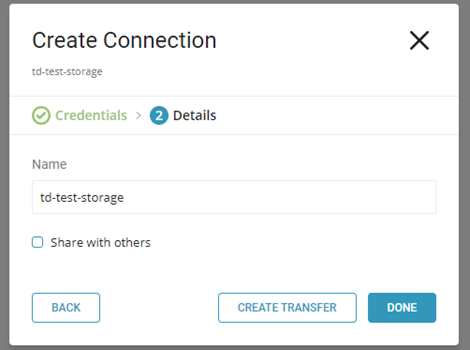
- 「Name」にConnectionの名前を入力し、「DONE」をクリックします
Treasure Workflowの実行
Treasure Workflowで次のタスクを実行します。
このワークフローはqueries/browsing_time2.sqlのクエリを実行し、実行結果をconnectiontd-test-storage使ってAzure Blob StorageにCSVファイルを出力します。
+td_result_into_azureblobstorage:
td>: queries/browsing_time2.sql
database: ${td.database}
result_connection: td-test-storage
result_settings:
container: treasure-data-export
path_prefix: browsing_time/output.csv
format: csv
header_line: true
delimiter: ","
null_string: ""
newline: CRLF
- result_connectionに作成したConnectionの名前を指定します
- containerにBlob Storageのコンテナ名を指定します
connectionに設定したBlob Storageのコンテナ(treasure-data-export)にファイル(browsing_time/output.csv)が出力されます。
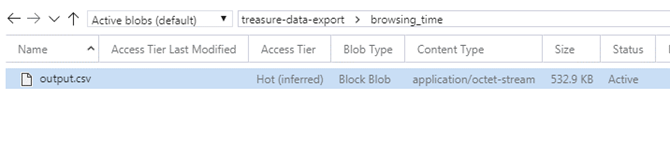
m,page_id,avg_browsing_time,var_browsing_time,pv
2005-01,,0.0,0.0,23
2014-09,/articles/in_udp,0.9636094674556215,3.1683421190632735,169
2014-09,/ja/articles/buffer-plugin-overview,2.3216666666666663,6.697920875420874,100
2014-09,/datasources/twitter,1.1973333333333334,4.552538888888889,25
2014-09,/articles/collect-glusterfs-logs,0.9666666666666666,2.8293079922027293,58
2014-09,/ja/articles/install-by-deb,1.7263774104683194,5.418272069049605,242
2014-09,/articles/high-availability,1.7484508547008546,4.976295377355463,312
2014-09,/ja/articles/in_unix,0.6159817351598175,1.2691700490444784,73
result_settingsに指定できるパラメータは以下となります。
| パラメータ名 | 型 | 必須 | デフォルト |
|---|---|---|---|
| container: | string | ○ | |
| path_prefix: | string | ○ | |
| file_ext: | string | ○ | |
| format: | string(csv|tsv) | - | csv |
| compression: | string(None|gz) | - | None |
| header_line: | boolean | - | true |
| delimiter: | string(","|"tab"|"|") | - | "," |
| null_string: | string(""|"\N"|NULL|null) | - | "" |
| new_line: | string(CRLF|CR|LF) | - | CRLF |
Microsoft SQL Databaseのテーブルに出力する
クエリの実行結果をMicrosoft SQL Databaseのテーブルに出力する手順を説明します。
Connectionの作成
Microsoft Azure Blob Storageの場合と同様に、Treasure Data consoleより、Connectionを作成します
- 「Connections」より「SQL Server」を選択します
- 「Host」、「Port」、「User」、「Password」を入力し、「CONTINUE」をクリックします
- 「Name」にConnectionの名前を入力し、「DONE」をクリックします
Treasure Workflowの実行
Treasure Workflowで次のタスクを実行します。
このワークフローではqueries/browsing_time2.sqlのクエリを実行し、実行結果をconnectiontd-test-sqlserver使ってSQL DatabaseのTdTestDbのBrowsingTime2テーブルに挿入します。
+td_result_into_sqlserver:
td>: queries/browsing_time2.sql
database: ${td.database}
result_connection: td-test-sqlserver
result_settings:
instance: MSSQLSERVER
database: TdTestDb
table: BrowsingTime2
batch_size: 3000
mode: insert
- result_connectionに作成したConnectionの名前を指定します
- databaseにDB名、tableにテーブル名を指定します
connectionに設定したSQL Databaseのテーブル(BrowsingTime2)にクエリの実行結果が出力されます。
result_settingsに指定できるパラメータは以下となります。
| パラメータ名 | 型 | 必須 | デフォルト |
|---|---|---|---|
| instance: | string | ○ | |
| database: | string | ○ | |
| table: | string | ○ | |
| timezone: | string | - | UTC |
| batch_size: | integer | - | 16777216 |
| mode: | string(insert|insert_direct|truncate_insert|replace) | - | insert |
Treasure Workflowの実行時のエラー(1)
SQL Databaseにテーブル未作成の状態でTreasure Workflowを実行すると次のエラーが発生しました。
[ERROR] (main): org.embulk.spi.util.RetryExecutor$RetryGiveupException: java.sql.SQLException: Column or parameter 'm' has type
'text' and collation 'Japanese_XJIS_140_CI_AS'. The legacy LOB types do not support UTF-8 or UTF-16 encodings. Use types varchar(max), nvarchar(max) or a collation which does not have the _SC or _UTF8 flags.
この時のCreate Table文を確認するとText型のカラムを作成しようとしていました。
[INFO] (0001:transaction): SQL: CREATE TABLE "BrowsingTime2_00000167b0c67dcc_embulk000" ("m" TEXT, "page_id" TEXT, "avg_browsing_time" DOUBLE PRECISION, "var_browsing_time" DOUBLE PRECISION, "pv" BIGINT)
SQL Databaseに事前にテーブルを作成しておくとそのカラム型でテーブルが作成されるようになり、Treasure Workflowが正常終了しました。
[INFO] (0001:transaction): SQL: CREATE TABLE "BrowsingTime2_00000167b0cb4e43_embulk000" ("m" NVARCHAR(10), "page_id" NVARCHAR(500), "avg_browsing_time" NUMERIC(5,3), "var_browsing_time" NUMERIC(5,3), "pv" NUMERIC(8,0))
Treasure Workflowの実行時のエラー(2)
result_settingsのbatch_sizeをデフォルト値(16777216)のまま実行すると次のエラーが発生しました。
[ERROR] (main): java.sql.BatchUpdateException: I/O Error: Connection reset
Azure SQL Databaseは、マルチテナントサービスのためタイムアウトが発生する場合があるようです。3. FAQ for Microsoft SQL Server Result Output
の回避策を参考にbatch_sizeを3000に変更するとTreasure Workflowが正常終了しました。
Azure Webジョブを起動する
Network operatorsのhttp>: Making HTTP requestsを利用するとTreasure WorkflowからHTTPリクエストを発行できます。
このオペレータを利用してAzure Webジョブを起動する手順を説明します。
Treasure Workflowの実行
事前にHttp TriggerのWebジョブを作成しておき、Treasure Workflowで次のタスクを実行します。
このワークフローではWebジョブのエンドポイントhttps://tdtestappservicejobs.scm.azurewebsites.net/api/triggeredwebjobs/td-test-job/runにPOSTリクエストを発行します。
+making_http_request:
http>: https://tdtestappservicejobs.scm.azurewebsites.net/api/triggeredwebjobs/td-test-job/run
method: POST
headers:
- Authorization: "Basic ${conf.credentials}"
-
${conf.credentials}には、Basic認証の「userid:password」をBase64エンコードした文字列を設定します
おわりに
Treasur Workflowでは、簡単なコードでクエリの実行、結果のエクスポートができます。Azureにエクスポートして利用する方法の検討のなかで動作確認した内容をまとめてみました。今後、実際の分析の要件や、分析対象のデータ、利用者の要件などを考慮したときには、細かな課題や工夫が必要なポイントが出てくるのではないかと思います。有用なものがあれば紹介したいと思います。
最後に今回紹介したAzure連携以外にも、Workflow ExamplesにTreasure Workflowの様々なサンプルが公開されています。