始めに
Treasure Data(以下TD)は外部サービス(S3やMySQLなど)からデータをインポートしたり、逆にデータをエクスポートすることができます。それぞれData Connector、Result Outputと呼んだりします。
ただし、残念ながらOracle Database(以下Oracle DB)からTDへデータ連携する機能(Data Connector for Oracle DB)はありません。必要とあらば自力でOracle DBから抽出した結果をcsvファイルにしTDへアップロードする、といった仕組みの作り込みが必要です。
定期的にデータ連携する必要がある場合は特に実装ハードルが高いかと思いますので、本記事にてEmbulk from Oracle DB to TDの利用方法について紹介します。
プラグインをインストールする
Oracle DBからTDへデータ連携するには下記機能が必要になります。
- Oracle DBへ接続しデータ抽出する
- TDへ接続しデータをアップロードする
Embulkはデフォルトでは上記機能が実装されていないため、プラグインという形で機能を追加する必要があります。まずはEmbulkのドキュメントにあるリストから探すのが良いかと思います。下記がリンクになります。
embulk-input-oracleは3rdパーティ製のプラグインになるため、自己責任で利用する必要がありますが、探してみると下記プラグインが良さそうです。
では早速インストールしてみましょう。
$ embulk -version
embulk 0.9.22
$ embulk gem install embulk-input-oracle
2019-12-17 18:33:51.814 +0900: Embulk v0.9.22
Gem plugin path is: /Users/kazuki.ito/.embulk/lib/gems
Fetching: embulk-input-oracle-0.10.1.gem (100%)
Successfully installed embulk-input-oracle-0.10.1
1 gem installed
$ embulk gem install embulk-output-td
2019-12-17 18:34:31.873 +0900: Embulk v0.9.22
Gem plugin path is: /Users/kazuki.ito/.embulk/lib/gems
Fetching: embulk-output-td-0.5.2.gem (100%)
Successfully installed embulk-output-td-0.5.2
1 gem installed
下記のように無事インストールできました。
$ embulk gem list | grep -e embulk-input -e embulk-output
・
・
embulk-input-oracle (0.10.1)
embulk-output-td (0.5.2, 0.5.1)
ymlファイルを作成する
下準備が完了したのでymlファイル(ここではload.ymlという名前)を作成します。
in:にはOracle DBの接続情報や抽出する条件などを、out:にはTDの接続情報や書き出し先のデータベース/テーブル名などを記述することになります。
長くなるのでインプット部分とアウトプット部分に分けて確認していきます。
インプット部分を記載する
ymlファイルの in: 部分を作成していきます。
まずは接続先のOracle DBについて確認してみましょう。
$ sqlplus /nolog
SQL*Plus: Release 19.0.0.0.0 - Production on Fri Dec 20 15:18:38 2019
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
SQL> conn <user_name>/<password>@xxxxxx:1521/kazzydb1
Connected.
SQL> select name from v$database;
NAME
---------
KAZZYDB1
SQL> desc kazzy_test_tab1;
Name Null? Type
----------------------------------------- -------- ----------------------------
COL1 NUMBER(10)
COL2 VARCHAR2(10)
COL3 NUMBER(10)
今回はシンプルに上記テーブルから数行データロードしてみます。事前にJDBCドライバをEmbulkから参照可能な場所に配置し driver_path: で指定します。後はOracle DBの接続情報や抽出したい列・条件を記載するだけでOKです。
in:
type: oracle
driver_path: ojdbc8-full/ojdbc8.jar
host: <hostname>
port: 1521
user: <user_name>
password: <password>
database: kazzydb1
table: kazzy_test_tab1
select: 'col1,col2,col3'
where: col1 between 1 and 10
ではプレビューしてみましょう。
$ embulk preview load.yml
2019-12-20 15:57:15.341 +0900: Embulk v0.9.22
2019-12-20 15:57:15.724 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2019-12-20 15:57:17.128 +0900 [INFO] (main): Gem's home and path are set by default: "/Users/kazuki.ito/.embulk/lib/gems"
2019-12-20 15:57:17.638 +0900 [INFO] (main): Started Embulk v0.9.22
2019-12-20 15:57:17.722 +0900 [INFO] (0001:preview): Loaded plugin embulk-input-oracle (0.10.1)
2019-12-20 15:57:17.751 +0900 [INFO] (0001:preview): Connecting to jdbc:oracle:thin:@<host_name>:1521:kazzydb1 options {oracle.jdbc.ReadTimeout=1800000, user=<user_name>, password=***, oracle.net.CONNECT_TIMEOUT=300000}
2019-12-20 15:57:20.264 +0900 [INFO] (0001:preview): Using JDBC Driver 19.3.0.0.0
2019-12-20 15:57:21.343 +0900 [INFO] (0001:preview): Connecting to jdbc:oracle:thin:@<host_name>:1521:kazzydb1 options {oracle.jdbc.ReadTimeout=1800000, user=<user_name>, password=***, oracle.net.CONNECT_TIMEOUT=300000}
2019-12-20 15:57:23.460 +0900 [INFO] (0001:preview): SQL: SELECT col1,col2,col3 FROM "KAZZY_TEST_TAB1" WHERE col1 between 1 and 10
2019-12-20 15:57:23.623 +0900 [INFO] (0001:preview): > 0.16 seconds
+-------------+-------------+-------------+
| COL1:double | COL2:string | COL3:double |
+-------------+-------------+-------------+
| 1.0 | test1 | 1000.0 |
| 2.0 | test2 | 1000.0 |
+-------------+-------------+-------------+
Oracle DBに接続でき、またテーブルのレコードを参照できることがわかりましたね。
ログにはどういったSQLが実行されているのか出力されています。下記のようにDB上でも同じSQLが実行されていることがわかります。
SQL> select sql_id, sql_text from v$sql where sql_text like '%KAZZY_TEST_TAB1%';
SQL_ID SQL_TEXT
------------- -------------------------------------------------------------------------------
dkktx44humhfk SELECT col1,col2,col3 FROM "KAZZY_TEST_TAB1" WHERE col1 between 1 and 10
アウトプット部分を記載する
次に out: 部分を作成していきます。
契約しているTDのリージョンがUSの場合は endpoint: は下記のようになります。
out:
type: td
apikey: <api_key>
endpoint: api.treasuredata.com
database: kazzy_test
table: kazzy_oracle_tab
mode: append
input部分とは異なりpreviewなどで試すことはできないのでこれで完了です。
Embulkを実行する
実は**設定に落とし穴がある**のでお試しいただく際は後述の対応が必要です。
ただ物は試しということで動かしてみましょう。
発生する事象やその理由に興味がない人は回避策まで飛んでください。
$ embulk run load.yml
2019-12-20 16:12:52.411 +0900: Embulk v0.9.22
2019-12-20 16:12:53.561 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2019-12-20 16:12:56.393 +0900 [INFO] (main): Gem's home and path are set by default: "/Users/kazuki.ito/.embulk/lib/gems"
2019-12-20 16:12:57.199 +0900 [INFO] (main): Started Embulk v0.9.22
2019-12-20 16:12:57.356 +0900 [INFO] (0001:transaction): Loaded plugin embulk-input-oracle (0.10.1)
2019-12-20 16:12:57.938 +0900 [INFO] (0001:transaction): Loaded plugin embulk-output-td (0.5.2)
2019-12-20 16:12:57.987 +0900 [INFO] (0001:transaction): Connecting to jdbc:oracle:thin:@<host_name>:1521:kazzydb1 options {oracle.jdbc.ReadTimeout=1800000, user=<user_name>, password=***, oracle.net.CONNECT_TIMEOUT=300000}
2019-12-20 16:13:01.127 +0900 [INFO] (0001:transaction): Using JDBC Driver 19.3.0.0.0
2019-12-20 16:13:02.273 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=8 / output tasks 4 = input tasks 1 * 4
2019-12-20 16:13:02.309 +0900 [INFO] (0001:transaction): td-client version: 0.8.4
2019-12-20 16:13:02.318 +0900 [INFO] (0001:transaction): Reading configuration file: /Users/kazuki.ito/.td/td.conf
2019-12-20 16:13:03.778 +0900 [INFO] (0001:transaction): 'time' column is generated and is set to a unix time 1576825983
2019-12-20 16:13:03.783 +0900 [INFO] (0001:transaction): Create bulk_import session embulk_20191220_071257_200000000_5abd1e80_25de_42e2_889f_970fa7bc8541
2019-12-20 16:13:04.334 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0}
2019-12-20 16:13:04.485 +0900 [INFO] (0019:task-0000): Connecting to jdbc:oracle:thin:@<host_name>:1521:kazzydb1 options {oracle.jdbc.ReadTimeout=1800000, user=<admin>, password=***, oracle.net.CONNECT_TIMEOUT=300000}
2019-12-20 16:13:06.856 +0900 [INFO] (0019:task-0000): SQL: SELECT col1,col2,col3 FROM "KAZZY_TEST_TAB1" WHERE col1 between 1 and 10
2019-12-20 16:13:07.071 +0900 [INFO] (0019:task-0000): > 0.21 seconds
2019-12-20 16:13:07.087 +0900 [INFO] (0019:task-0000): {uploading: {rows: 2, size: 140 bytes (compressed)}}
2019-12-20 16:13:08.761 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0}
2019-12-20 16:13:09.490 +0900 [INFO] (0001:transaction): Performing bulk import session 'embulk_20191220_071257_200000000_5abd1e80_25de_42e2_889f_970fa7bc8541'
2019-12-20 16:13:54.996 +0900 [INFO] (0001:transaction): job id: <job_id>
2019-12-20 16:13:55.599 +0900 [INFO] (0001:transaction): Committing bulk import session 'embulk_20191220_071257_200000000_5abd1e80_25de_42e2_889f_970fa7bc8541'
2019-12-20 16:13:55.599 +0900 [INFO] (0001:transaction): valid records: 2
2019-12-20 16:13:55.599 +0900 [INFO] (0001:transaction): error records: 0
2019-12-20 16:13:55.599 +0900 [INFO] (0001:transaction): valid parts: 1
2019-12-20 16:13:55.599 +0900 [INFO] (0001:transaction): error parts: 0
2019-12-20 16:13:55.599 +0900 [INFO] (0001:transaction): new columns:
2019-12-20 16:13:55.599 +0900 [INFO] (0001:transaction): - COL1: double
2019-12-20 16:13:55.600 +0900 [INFO] (0001:transaction): - COL2: string
2019-12-20 16:13:55.600 +0900 [INFO] (0001:transaction): - COL3: double
2019-12-20 16:14:05.770 +0900 [INFO] (0001:transaction): Deleting bulk import session 'embulk_20191220_071257_200000000_5abd1e80_25de_42e2_889f_970fa7bc8541'
2019-12-20 16:14:06.965 +0900 [INFO] (main): Committed.
2019-12-20 16:14:06.965 +0900 [INFO] (main): Next config diff: {"in":{},"out":{"last_session":"embulk_20191220_071257_200000000_5abd1e80_25de_42e2_889f_970fa7bc8541"}}
無事処理が完了したようです。TDコンソールでクエリを実行してみると、下記のようにデータロードされていることが確認できました。
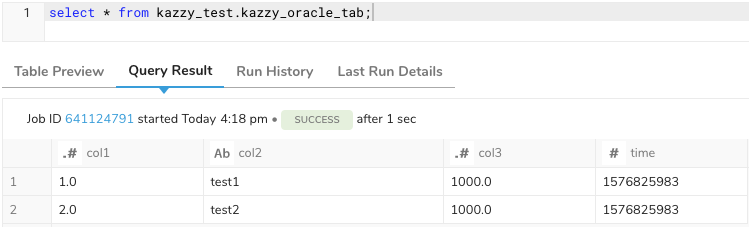
意図せずカラムが増える
先述の通り実は設定(ymlファイル)に抜け漏れがあり、複数回データ連携するとカラムが意図せず増えるという事象が発生してしまいます。
では実際に動かしてみて確認してみましょう。
まずは先程と同じymlファイルを利用して再度データ連携します。
$
16:36:29 oracle $ embulk run load.yml
2019-12-20 16:36:39.185 +0900: Embulk v0.9.22
2019-12-20 16:36:40.200 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
・
・
2019-12-20 16:36:51.431 +0900 [WARN] (0001:transaction): API request to /v3/table/create/kazzy_test/kazzy_oracle_tab/log failed: class com.treasuredata.client.TDClientHttpConflictException, cause: [TARGET_ALREADY_EXISTS] [409:Conflict] API request to /v3/table/create/kazzy_test/kazzy_oracle_tab/log has failed: ["Name has already been taken"]
・
・
2019-12-20 16:36:54.361 +0900 [INFO] (0019:task-0000): {uploading: {rows: 2, size: 140 bytes (compressed)}}
2019-12-20 16:36:55.843 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0}
2019-12-20 16:36:56.620 +0900 [INFO] (0001:transaction): Performing bulk import session 'embulk_20191220_073645_040000000_d4bdd9d4_a357_4f2a_bfa4_5f31b9dfae71'
2019-12-20 16:37:41.982 +0900 [INFO] (0001:transaction): job id: <job_id>
2019-12-20 16:37:42.527 +0900 [INFO] (0001:transaction): Committing bulk import session 'embulk_20191220_073645_040000000_d4bdd9d4_a357_4f2a_bfa4_5f31b9dfae71'
2019-12-20 16:37:42.528 +0900 [INFO] (0001:transaction): valid records: 2
2019-12-20 16:37:42.528 +0900 [INFO] (0001:transaction): error records: 0
2019-12-20 16:37:42.529 +0900 [INFO] (0001:transaction): valid parts: 1
2019-12-20 16:37:42.529 +0900 [INFO] (0001:transaction): error parts: 0
2019-12-20 16:37:42.529 +0900 [INFO] (0001:transaction): new columns:
2019-12-20 16:37:42.529 +0900 [INFO] (0001:transaction): - COL1: double
2019-12-20 16:37:42.529 +0900 [INFO] (0001:transaction): - COL2: string
2019-12-20 16:37:42.529 +0900 [INFO] (0001:transaction): - COL3: double
2019-12-20 16:37:52.805 +0900 [INFO] (0001:transaction): Deleting bulk import session 'embulk_20191220_073645_040000000_d4bdd9d4_a357_4f2a_bfa4_5f31b9dfae71'
2019-12-20 16:37:53.825 +0900 [INFO] (main): Committed.
2019-12-20 16:37:53.826 +0900 [INFO] (main): Next config diff: {"in":{},"out":{"last_session":"embulk_20191220_073645_040000000_d4bdd9d4_a357_4f2a_bfa4_5f31b9dfae71"}}
ログを見る限り無事データロードできているように見えますが、TDコンソールでテーブル定義を確認してみると下記の通りカラムが増えてしまっています。
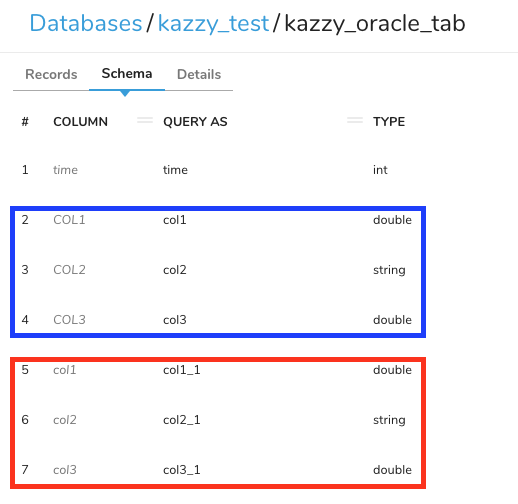
青枠部分は初回実行時に生成されたカラム、赤枠部分は2回目に実行した際に生成されたカラムです。
カラムが増える原因
Oracle DBが基本的に大文字のアルファベットでカラム名を取り扱うからか、embulk-input-oracleプラグインはカラム名内のアルファベットを大文字として設定するようです。previewコマンドの結果やログからそれがわかります。
初めてEmbulkを実行しロードすると下記状態になります。
COLUMNはインプットデータの実際のカラム名です。そのため大文字のアルファベットになります。
QUERY ASはTDにてクエリで利用する際のエイリアス(別名)のことです。TDはカラム名として小文字のアルファベット・数字・アンダースコアのみ許可しているため、エイリアスが自動生成され結果としてCOLUMNを小文字化した値になります。
| 1カラム目 | 2カラム目 | 3カラム目 | |
|---|---|---|---|
| COLUMN | COL1 | COL2 | COL3 |
| QUERY AS | col1 | col2 | col3 |
続けてEmbulkを実行すると当然初回実行時と同様に下記のようにテーブル定義を設定しようとします。
| 1カラム目 | 2カラム目 | 3カラム目 | |
|---|---|---|---|
| COLUMN | COL1 | COL2 | COL3 |
| QUERY AS | col1 | col2 | col3 |
ただ、残念ながら初回実行時の経緯(COLUMNとQUERY ASのマッピング)を認識できず、カラム名が競合してしまうと認識されてしまいます。
| 1カラム目 | 2カラム目 | 3カラム目 | |
|---|---|---|---|
| COLUMN | col1 | col2 | col3 |
| QUERY AS | col1 | col2 | col3 |
その結果、COLUMN は小文字化されます。すると当然QUERY ASも小文字化したものにしようとするのですが、初回実行時に定義されたQUERY ASと競合してしまいます。
| 1カラム目 | 2カラム目 | 3カラム目 | |
|---|---|---|---|
| COLUMN | col1 | col2 | col3 |
| QUERY AS | col1_1 | col2_1 | col3_1 |
そのためカラム名の末尾に_nを付与したものがQUERY ASとして設定されます。
この状態のまま何度もEmbulkを実行していると気づいたときには _n が末尾に付与された大量のカラムが作成されてしまっているということになりかねません。
カラムが増えていく事象の回避策
ではどうやってカラム数の増殖を防げばよいのでしょうか?
実は至って単純で、インプット設定にて定義しているカラム名のアルファベットを全て小文字化することで回避することができます。
具体的にはrename filterプラグインを利用して小文字化します。
下記のようにルールとして upper_to_lower を指定するとアルファベットを小文字化してくれます。
filters:
- type: rename
rules:
- rule: upper_to_lower
この記載が正しいかどうか、どのような結果になるのかはプレビューで確認できます。
実際に確認してみると、下記のようにカラム名が小文字になっているので正しく設定できていそうです。
$ embulk preview load.yml
2019-12-20 18:28:29.225 +0900: Embulk v0.9.22
2019-12-20 18:28:30.062 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
・
・
2019-12-20 18:28:39.229 +0900 [INFO] (0001:preview): SQL: SELECT col1,col2,col3 FROM "KAZZY_TEST_TAB1" WHERE col1 between 1 and 10
2019-12-20 18:28:39.404 +0900 [INFO] (0001:preview): > 0.17 seconds
+-------------+-------------+-------------+
| col1:double | col2:string | col3:double |
+-------------+-------------+-------------+
| 1.0 | test1 | 1000.0 |
| 2.0 | test2 | 1000.0 |
+-------------+-------------+-------------+
1からやり直すとカラムが増殖することなくデータ追加していくことが可能です。
ymlファイルの最終形
資格情報はマスキングしていますが、最終的に下記のようなymlファイルになるはずです。
$ cat load.yml
in:
type: oracle
driver_path: ojdbc8-full/ojdbc8.jar
host: <host_name>
port: 1521
user: <user_name>
password: <password>
database: kazzydb1
table: kazzy_test_tab1
select: 'col1,col2,col3'
where: col1 between 1 and 10
filters:
- type: rename
rules:
- rule: upper_to_lower
out:
type: td
apikey: <apikey>
endpoint: api.treasuredata.com
database: kazzy_test
table: kazzy_oracle_tab
mode: append
最後に
Embulkはプラグインによって柔軟にインプット/アウトプット先を追加することができます。
Oracle DBからTDへデータロードする必要がある、という場合は非機能要件次第かと思いますがEmbulkを利用してみてはいかがでしょうか?