はじめに
劇場版malIoc、もう見ましたか?ラストで無人在来チャンクがヒープに突っ込んでくシーンなんか鳥肌ものそろそろ怒られるのでやめよう
これまでmallocの様々な動作を確認してきました。
- mallocの動作を追いかける(mmap編)
- mallocの動作を追いかける(prev_size編)
- mallocの動作を追いかける(main_arenaとsbrk編)
- mallocの動作を追いかける(fastbins編)
- mallocの動作を追いかける(マルチスレッド編) ← イマココ
- mallocの動作を追いかける(環境変数編)
これだけでもかなりややこしいですね。っていうかソース読むよりgdb経由で解析したほうがわかりやすいってどういうことよ?
さて、これまではシングルスレッドでの動作のみを考えてきました。たいがいのものは並列だの分散だのになった瞬間に考えなければいけないことが滅茶苦茶増えてシングルスレッドだけ考えればよかった幸せな世界は終わり誰もあなたを愛しません。しかし、この世にマルチスレッドというものがある以上、mallocもマルチスレッドに対応しなければなりません。幸いにというか、mallocのマルチスレッド対応はそこまで複雑ではないので、今回はそのあたりの振る舞いを調べることにします。
なお、僕はmallocド素人芸人なので、(これまでの記事を含めて)マサカリを歓迎します。
アリーナ
既に見たように、mallocはメモリをチャンクという単位で管理しており、そのチャンクを管理するのがアリーナである。そのアリーナを管理する構造体malloc_stateの冒頭にはmutex用の領域がある。あるスレッドがmallocの管理するチャンクのリストを繋ぎ変えている最中に別のスレッドがそのリストを使ったらおかしなことになる。そこで、アリーナを使い始める時にアリーナをロックし、使い終わってからロックを解放することで排他処理をする。
さて、ユーザからmalloc要求があったのでmain_arenaを触りにいったら、誰かがロックしていた。このままロック終了まで待つわけにはいかないので、なんとかして別の領域を確保してユーザに返さないといけない。そこでmallocはmain_arenaがロックされている時にはmmapで新たなアリーナを確保する。
シングルスレッドのときにも、馬鹿でかいメモリを確保する際にはmmapで確保していたが、その場合は単純に孤立したチャンクとして扱っていた。マルチスレッドで扱う場合には、mmapで確保した領域をヒープっぽく使うのが異なる。
まずは、マルチスレッドでmallocしたら、返ってくるアドレスがヒープじゃないやつが混ざってくる様子を見てみよう。
こんなコードを書いてみる。
# include <cstdio>
# include <cstdlib>
# include <omp.h>
const int N = 24;
int
main(void){
char *buf[N];
# pragma omp parallel for
for(int i=0;i<N;i++){
buf[i] = (char*)malloc(1);
free(buf[i]);
}
# pragma omp parallel for
for(int i=0;i<N;i++){
buf[i] = (char*)malloc(1);
}
for(int i=0;i<N;i++){
size_t size = (size_t)(*(buf[i]-8));
printf("buf[%d]->0x%lx (0x%lx) ",i,buf[i],size);
if(size & 4)printf(":mmapped_arena\n");
else printf("main_arena\n");
}
}
手元に12コアCPUの2ソケットマシンがあったので、これを24スレッドで実行する。
$ g++ -fopenmp test.cpp
$ OMP_NUM_THREADS=16 ./a.out
buf[0]->0x2aaab00008b0 (0x25) :mmapped_arena
buf[1]->0x2aaab00008d0 (0x25) :mmapped_arena
buf[2]->0x605eb0 (0x21) main_arena
buf[3]->0x605ed0 (0x21) main_arena
buf[4]->0x605e70 (0x21) main_arena
buf[5]->0x605e90 (0x21) main_arena
buf[6]->0x605e10 (0x21) main_arena
buf[7]->0x605e30 (0x21) main_arena
buf[8]->0x605f90 (0x21) main_arena
buf[9]->0x605fb0 (0x21) main_arena
buf[10]->0x605db0 (0x21) main_arena
buf[11]->0x605dd0 (0x21) main_arena
buf[12]->0x605fd0 (0x21) main_arena
buf[13]->0x605ff0 (0x21) main_arena
buf[14]->0x605ef0 (0x21) main_arena
buf[15]->0x605f10 (0x21) main_arena
buf[16]->0x2aaab0000910 (0x25) :mmapped_arena
buf[17]->0x605f30 (0x21) main_arena
buf[18]->0x605e50 (0x21) main_arena
buf[19]->0x605f50 (0x21) main_arena
buf[20]->0x2aaab00008f0 (0x25) :mmapped_arena
buf[21]->0x2aaab40008b0 (0x25) :mmapped_arena
buf[22]->0x605df0 (0x21) main_arena
buf[23]->0x605f70 (0x21) main_arena
実行するたびに結果が変わるのだが、この実行結果から
- チャンクの
sizeにis_non_mainarenaフラグ(下位3bit目)が立っている奴がちらほらいる - メインアリーナでない奴らのアドレスは、0x2aaab0000000系列と0x2aaab4000000系列がいるらしい
ということがわかる。図解するとこんな感じ。
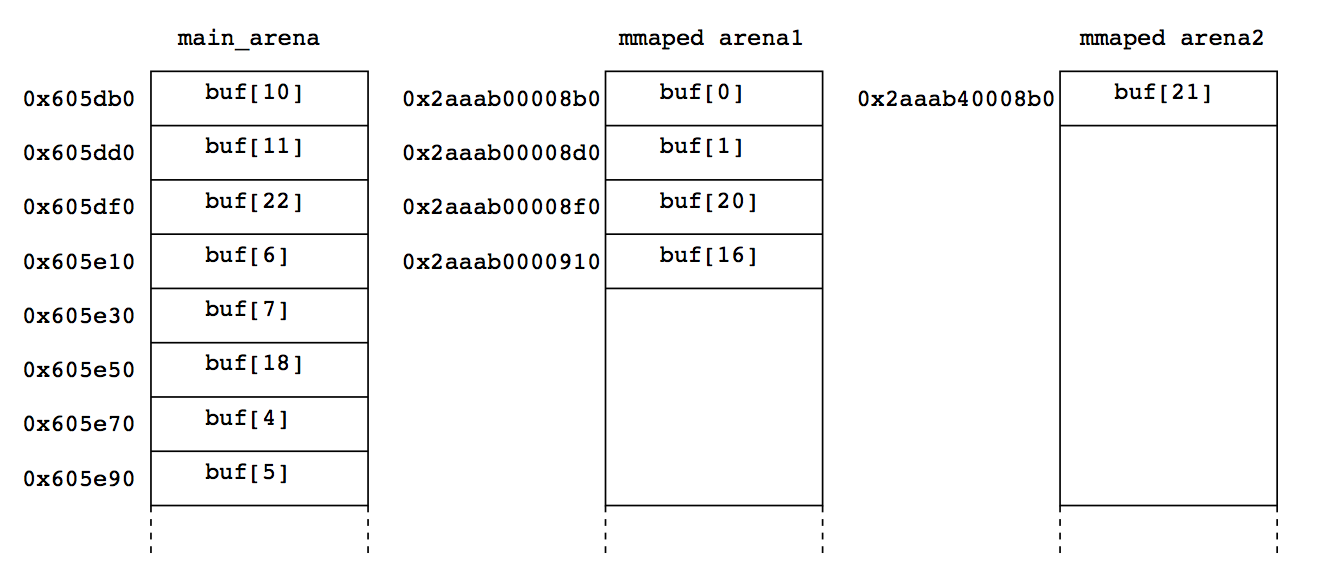
メインアリーナに19個、一つ目のmmappedアリーナに4個、二つ目のアリーナに1個のチャンクが作られたことがわかる。
アリーナのリンクリスト
あるスレッドがmain_arenaを触っている時に、別のスレッドがmain_arenaを触りにいったらロックされているので、mmapにより別のアリーナを作ってそこを触りに行くということを既に述べた。では、さらに別のスレッドがアリーナを触りに来たらどうするか?
第二のスレッドは、main_arenaがロックされていたので、別のアリーナを作るが、その際にmain_arenaに新しいアリーナをリンクする。第三のスレッドはmain_arenaがロックされていることを知る。その時、main_arenaに新しいアリーナがリンクされていることを知り、それをたどって新しいアリーナでチャンクを確保しようとする。もし新しいアリーナもロックされていたら、新たなアリーナを作ってそこにリンクする。
もちろん新しいアリーナを作っている最中に別のスレッドがそのアリーナへのリンクをいじろうとしたらおかしなことが起きるので、そこにもロックが必要。ソースをざっと見た限り、こちらは別のスレッドがロックを解放するまで待っているっぽい。
その「アリーナからアリーナへのリンク」は、malloc_state構造体のnextメンバに記載がある。それを見るためにこんな手抜き構造体定義をしよう。
const int NBINS=128;
# define BINMAPSHIFT 5
# define BITSPERMAP (1U << BINMAPSHIFT)
# define BINMAPSIZE (NBINS / BITSPERMAP)
struct malloc_state{
int mutex;
int flags;
size_t *fastbinsY[10];
size_t *top;
size_t *last_remainder;
size_t *bins[128*2-2];
unsigned int binmap[BINMAPSIZE];
malloc_state *next;
};
typedef malloc_state* mstate;
//mstate ma = (mstate)0x2aaaab813e80;
mstate ma = (mstate)0x2aaaabc40e80;
プログラムを-fopenmpつきでコンパイルするとmain_arenaのアドレスが変わるのでそれに対応している。また、構造体の最後にmalloc_state *nextというメンバが増えている。これを参照することで「次のアリーナ」を見ることができる。
こんなコードを書いてみよう。先程のコードにアリーナのリンクをたどるコードを追加したものである。
# include <cstdio>
# include <cstdlib>
# include <omp.h>
# include "malloc.h"
const int N = 24;
int
main(void){
char *buf[N];
# pragma omp parallel for
for(int i=0;i<N;i++){
buf[i] = (char*)malloc(1);
free(buf[i]);
}
# pragma omp parallel for
for(int i=0;i<N;i++){
buf[i] = (char*)malloc(1);
}
for(int i=0;i<N;i++){
size_t size = (size_t)(*(buf[i]-8));
printf("buf[%d]->0x%lx (0x%lx) ",i,buf[i],size);
if(size & 4)printf(":mmapped_arena\n");
else printf("main_arena\n");
}
printf("---arena_chain---\n");
mstate p = ma;
do{
printf("0x%lx->0x%lx\n",p,p->next);
p = p->next;
}while(p != ma);
}
実行してみる。
$ g++ -fopenmp test2.cpp
$ ./a.out
buf[0]->0x608970 (0x21) main_arena
buf[1]->0x608a10 (0x21) main_arena
buf[2]->0x2aaab40008b0 (0x25) :mmapped_arena
buf[3]->0x2aaab0000910 (0x25) :mmapped_arena
buf[4]->0x608850 (0x21) main_arena
buf[5]->0x6089d0 (0x21) main_arena
buf[6]->0x6088d0 (0x21) main_arena
buf[7]->0x2aaab00008f0 (0x25) :mmapped_arena
buf[8]->0x6088f0 (0x21) main_arena
buf[9]->0x6087f0 (0x21) main_arena
buf[10]->0x608810 (0x21) main_arena
buf[11]->0x2aaab00008d0 (0x25) :mmapped_arena
buf[12]->0x608830 (0x21) main_arena
buf[13]->0x608910 (0x21) main_arena
buf[14]->0x6088b0 (0x21) main_arena
buf[15]->0x608890 (0x21) main_arena
buf[16]->0x608a30 (0x21) main_arena
buf[17]->0x608930 (0x21) main_arena
buf[18]->0x608990 (0x21) main_arena
buf[19]->0x608950 (0x21) main_arena
buf[20]->0x2aaab00008b0 (0x25) :mmapped_arena
buf[21]->0x6089b0 (0x21) main_arena
buf[22]->0x608870 (0x21) main_arena
buf[23]->0x6089f0 (0x21) main_arena
---arena_chain---
0x2aaaabc40e80->0x2aaab4000020
0x2aaab4000020->0x2aaab0000020
0x2aaab0000020->0x2aaaabc40e80
先程と結果が異なるが、やはりメインアリーナ以外に二つアリーナができていることがわかる。最初の0x2aaaabc40e80のアドレスはmain_arenaである(先程のmalloc.h参照)。そこから、0x2aaab4000020というアドレスのアリーナ、さらにそこから0x2aaab0000020というアドレスのアリーナにリンクされており、最後のアリーナからmain_arenaにリンクが帰ってきたことから、これでアリーナが全部であることがわかる。
リンクを図解するとこんな感じ。
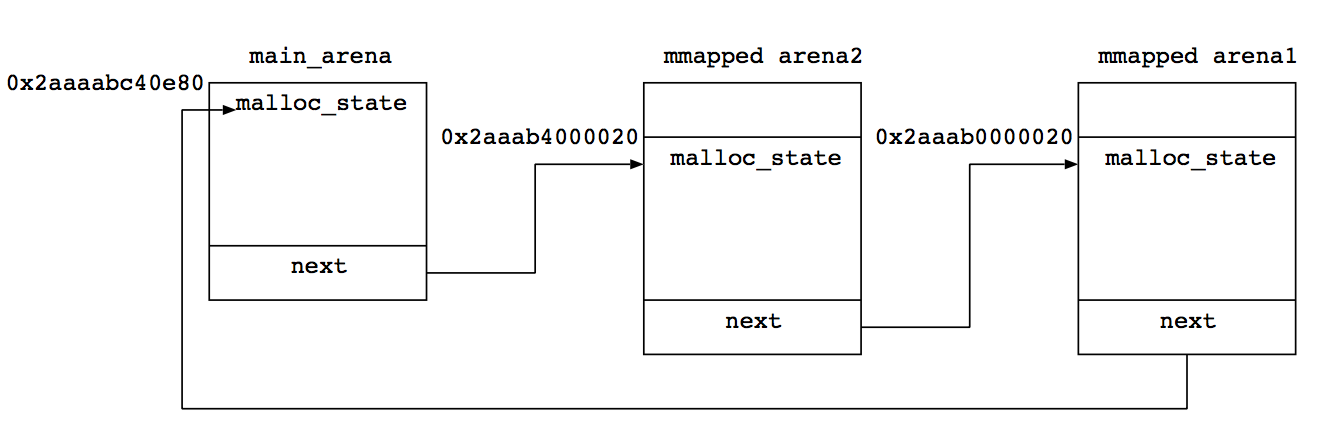
二番に作られたmmappedアリーナが、一番目とmain_arenaの間に割り込む形になっている。
heap_info
さて、アリーナの情報が0x2aaab0000020や、0x2aaab4000020といった、ちょっとキリが悪いアドレスになっているのが気になると思う。実はアリーナの先頭は0x2aaab0000000や0x2aaab0000000というキリの良いアドレスになっており、その先頭にはヒープ情報が格納されている。ヒープ情報は以下のようなheap_info構造体で記述される。
typedef struct _heap_info {
mstate ar_ptr;
struct _heap_info *prev;
size_t size;
size_t pad;
} heap_info;
メンバそれぞれの意味は以下の通り。
-
ar_ptrこのヒープのアリーナを管理するmalloc_stateへのポインタ -
prevアリーナをさらにmmapで拡張した場合、その領域を指すためのポインタ -
sizeアリーナのサイズ -
padメモリ境界をそろえるためのパディング
これらの情報も表示させてみよう。test2.cppを以下のように書き換える。
# include <cstdio>
# include <cstdlib>
# include <omp.h>
# include "malloc.h"
typedef struct _heap_info {
mstate ar_ptr;
struct _heap_info *prev;
size_t size;
size_t pad;
} heap_info;
const int N = 24;
int
main(void){
char *buf[N];
# pragma omp parallel for
for(int i=0;i<N;i++){
buf[i] = (char*)malloc(1);
free(buf[i]);
}
# pragma omp parallel for
for(int i=0;i<N;i++){
buf[i] = (char*)malloc(1);
}
for(int i=0;i<N;i++){
size_t size = (size_t)(*(buf[i]-8));
printf("buf[%d]->0x%lx (0x%lx) ",i,buf[i],size);
if(size & 4)printf(":mmapped_arena\n");
else printf("main_arena\n");
}
printf("---arena_chain---\n");
mstate p = ma;
do{
printf("0x%lx->0x%lx\n",p,p->next);
if(p==ma){
printf(" main_arena\n");
}else{
heap_info *hi = (heap_info*)((char*)p-0x20);
printf(" ar_ptr:0x%lx\n",hi->ar_ptr);
printf(" prev:0x%lx\n",hi->prev);
printf(" size:0x%lx\n",hi->size);
}
p = p->next;
}while(p != ma);
}
冒頭でheap_info構造体を定義し、アリーナポインタから0x20バイト前をheap_info構造体へのポインタだと思って代入する。その後、3つのメンバを表示している。実行結果はこんな感じ。
$ g++ -fopenmp test3.cpp
$ ./a.out
buf[0]->0x6087f0 (0x21) main_arena
buf[1]->0x6089f0 (0x21) main_arena
buf[2]->0x2aaab0000930 (0x25) :mmapped_arena
buf[3]->0x608970 (0x21) main_arena
buf[4]->0x608870 (0x21) main_arena
buf[5]->0x2aaab00008b0 (0x25) :mmapped_arena
buf[6]->0x6088b0 (0x21) main_arena
buf[7]->0x608810 (0x21) main_arena
buf[8]->0x2aaab40008b0 (0x25) :mmapped_arena
buf[9]->0x2aaab00008d0 (0x25) :mmapped_arena
buf[10]->0x608930 (0x21) main_arena
buf[11]->0x6088f0 (0x21) main_arena
buf[12]->0x6089b0 (0x21) main_arena
buf[13]->0x2aaab0000910 (0x25) :mmapped_arena
buf[14]->0x608890 (0x21) main_arena
buf[15]->0x6088d0 (0x21) main_arena
buf[16]->0x6089d0 (0x21) main_arena
buf[17]->0x608850 (0x21) main_arena
buf[18]->0x608910 (0x21) main_arena
buf[19]->0x2aaab0000950 (0x25) :mmapped_arena
buf[20]->0x608990 (0x21) main_arena
buf[21]->0x608830 (0x21) main_arena
buf[22]->0x608950 (0x21) main_arena
buf[23]->0x2aaab00008f0 (0x25) :mmapped_arena
---arena_chain---
0x2aaaabc40e80->0x2aaab4000020
main_arena
0x2aaab4000020->0x2aaab0000020
ar_ptr:0x2aaab4000020
prev:0x0
size:0x21000
0x2aaab0000020->0x2aaaabc40e80
ar_ptr:0x2aaab0000020
prev:0x0
size:0x21000
最初のアリーナはmain_arenaなのでheap_infoは無い。次のアリーナ(mmapped arena2)は、先程見たようにmalloc_state構造体の場所は0x2aaab4000020であり、prevがゼロなのでこのアリーナは拡張されておらず、アリーナのサイズは0x21000バイトであることがわかる。これは最初のmallocが呼ばれた時のヒープ拡張サイズと一緒と同じサイズになっている。
heap_infoまで含めて図解するとこんな感じ。
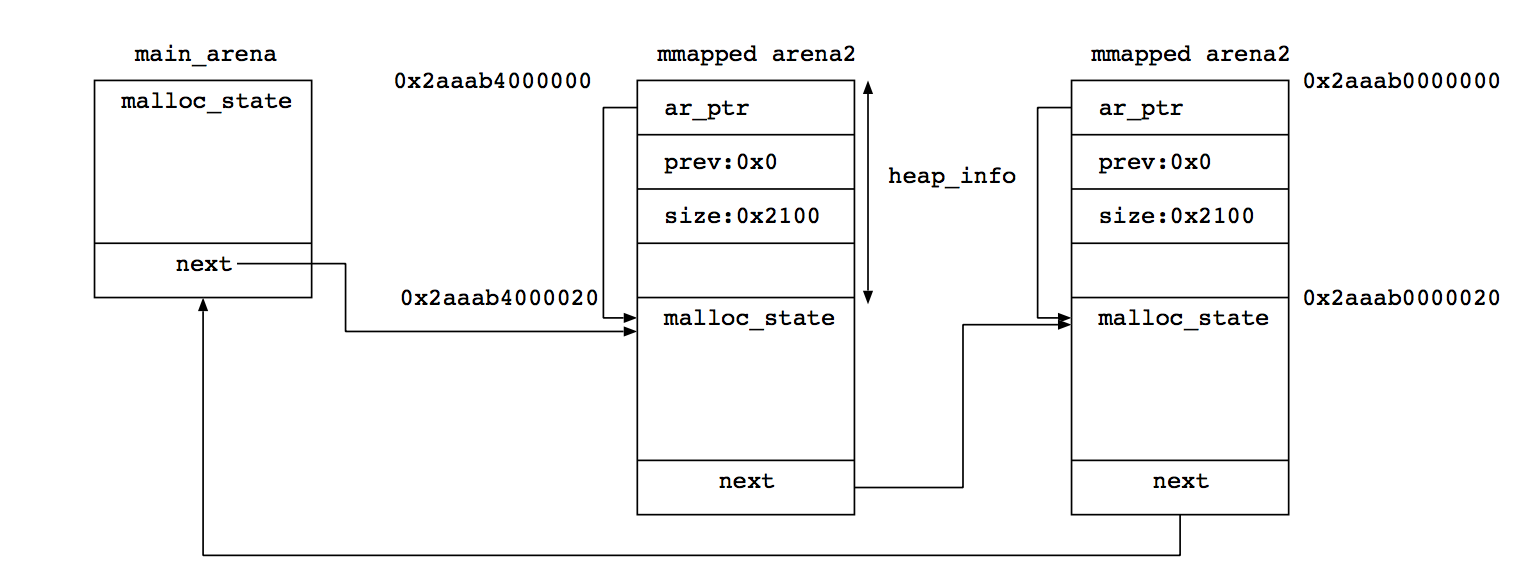
さて、チャンクをfreeする際に、自分がどこのアリーナに所属するか調べないといけない。sizeメンバの3bit目のフラグが立っていることから自分がメインアリーナにいないことはわかるが、ではどこにアリーナ情報(malloc_state構造体)があるのか? 普通に考えると、mallocする際にアリーナ情報もチャンクヘッダに書き込みたくなるけど、それではメモリ効率が悪くなる。
そこで、「mmappedされたアリーナは必ず1MBアラインするように確保する。するとポインタのアドレスと~0xFFFFFと論理積を取ればアリーナの先頭アドレスが取れる」という、滅茶苦茶力技なことをする。mmapped arenaの先頭アドレスが0x2aaab0000000とか0x2aaab4000000みたいにきれいな数字になっているのはこういう事情による。
まとめ
mallocのマルチスレッド対応を見てみた。スレッドがアリーナの使用で競合したら、新たにアリーナを作ること、そのアリーナは1MBアラインするのでポインタ操作だけでアリーナの先頭アドレスがわかるようになっていることなどを確認した。っていうか、アリーナの数は最終的にスレッド数くらいで落ち着くと思うけれど、スレッドがmalloc要求するたびにどのアリーナのメモリが返ってくるかわからないとか、アリーナの数が実行ごとに違うとか、キャッシュ効率とか考えたらどうなのとか、考えると無限に面倒くさい。
そもそも同じアリーナを複数のスレッドで共有するから面倒くさいんで、最初からスレッドの数だけ別々のアリーナを確保して、他のスレッドの情報がほしければ明示的に情報コピーを要求したほうがメモリ管理的には極めてシンプルになる・・・ってそれって要するに分散メモリ並列ですな。
こういうことを書くとまた「MPIを愛している」とか言われそうだけど、別にMPIを愛しているわけではなくて、単に「共有メモリ並列」に良い思い出が無いだけです。まぁ、共有、分散にかかわらず、並列プログラミングに「良い思い出」を持ってるユーザ側の人ってあまりいなそうだけど。
続く・・・可能性はかなり低い。
参考
- malloc動画 元動画(ってなに?)
- mallocの旅(glibc編) 上の動画のスライド。マルチスレッドがらみはこれだけ読めばわかると思う。
- malloc(3)のメモリ管理構造 説明がわかりやすい記事。
- malloc.c mallocのソース
- A Memory Allocator mallocマスター、Doug Lea氏によるmalloc解説。やや記述は古いがmallocの思想が垣間見えて興味深い。