はじめに
アーキテクチャシミュレータGem5を使ってみる。
- その1 インストールと実行まで
- その2 OoOを実感する
実行環境としては以下を想定している。
- リモート(プログラムのコンパイル環境): Linux (CentOS + GCC)
- ローカル(Gem5の実行環境): Mac
OoO実行について
OoOとは「Out of Order実行」のことだ。CPUがプログラムを実行する時には、
- Fetch:命令をメモリからとってくる
- Decode: 命令を解釈する
- Issue: 命令を適切な実行ユニットに投げて実行する
- Write Back: 結果を書き戻す
といった順番で実行される。しかし、例えば命令を実行するのに必要なレジスタが他の命令によって使われている時、そのレジスタが使用可能になるまでその命令の実行を待たなければならない。これをストールと呼び、CPUはその分だけ空回りする。
OoOは、「待ち」に入った命令の後に実行可能な命令があれば、それを先に実行してしまうことで、なるべくCPUや演算器を遊ばせない仕組みだ。この様子をGem5を使って見てみよう、というのが本稿の趣旨である。
Gem5におけるx86のOoOシミュレーションについて
Gem5は、O3CPUというCPUモデルが実装されている。O3は「Out of Order」のことだ。x86命令セットに対応しているが、このCPUモデルはx86ではなくAlpha 21264を模したものであることに注意。従って、x86命令をGem5でシミュレートした時、これはx86実機と必ずしも同じ動作をしない。
また、x86では一つのCISC命令を複数のRISC的命令にバラして実行する「μOPS」という仕組みがあり、Gem5はこれをサポートしているため、実行時に一つの命令が複数の命令として実行されているように見える。筆者の知る限り、IntelからμOPSに対する公式なドキュメントは公開されていない。有志による情報としては、以下の二つが有名。
- Agner FogによるPDF 様々な石でのx86のレイテンシやスループットを集めた表。x86でチューニングをする人なら一度はお世話になったことがあるはず。μOPSの命令数も書いてある。
- uops.info 命令ごとのμOPSの数がまとめられた表。ウェブで検索できるので便利
Konataによる可視化
Gem5には、パイプラインを可視化するためのツールo3-pipeview.pyがあり、trace.outを食わせて色付きのテキストファイルを出力することができるが、あくまでもビューワがlessなのでいろいろ使いづらい。ここは塩谷さんのKonataというツールを使うのが便利だ。Konataの使い方についてはこちらのスライド(PDF)が詳しいので一読されたい。
最低限のプログラム
Gem5でプログラムを実行する際、普通にCプログラムをコンパイルし、-staticでリンクしてしまうと、プログラムが大きくなりすぎてしまい、欲しい情報が見づらくなってしまう。例えば「Hello World」を表示するだけのプログラム、
# include <stdio.h>
int main(){
printf("Hello Wordl\n");
return 0;
}
を、普通にコンパイル、リンクしても、大した情報量はない。
$ gcc test.c
$ objdump -S ./a.out | wc
182 982 8187
しかし、Gem5のために静的にリンクすると、実行バイナリが膨れ上がる。
$ gcc test.c -static
$ objdump -S ./a.out | wc
150290 1071310 8097726
なんと15万行である。みたいところはほんの数行〜数十行なのに、15万行もあるといろいろ面倒くさい。
そこで、「必要最低限」のアセンブリで実行バイナリを作ってしまうのが良い。
詳しくはtanakmuraさんの実践的低レイヤプログラミングのリンカの稿を参照して欲しいが、例えば以下のようなプログラムが「Gem5で実行可能な最小のプログラム」である。
.globl _start
_start:
call main
mov $60, %rax
syscall
main:
ret
最初のエントリポイントである_startでmainを呼び、mainは何もせずにretして、最後にプログラムの終了処理のシステムコールをしておしまいである。
ここから以下のように実行バイナリを作る。
$ as test.s -o test.o
$ ld test.o
$ ./a.out
何もしないプログラムが完成した。実行バイナリも非常に小さい。
$ objdump -S ./a.out | wc
./a.out: ファイル形式 elf64-x86-64
セクション .text の逆アセンブル:
0000000000400078 <_start>:
400078: e8 09 00 00 00 callq 400086 <main>
40007d: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
400084: 0f 05 syscall
0000000000400086 <main>:
400086: c3 retq
これをKonataで可視化しよう。
まずは実行バイナリをローカルに落としてきて、Gem5に食わせてtrace.outを出力させる。
$ ./build/X86/gem5.opt --debug-flags=O3PipeView --debug-file=trace.out configs/example/se.py --cpu-type=DerivO3CPU --caches -c ./a.out
これにより、カレントディレクトリにm5outというディレクトリができて、その中にtrace.outが出力されるので、Konataを起動してそこにドラッグアンドドロップすると、実行状況が可視化される。
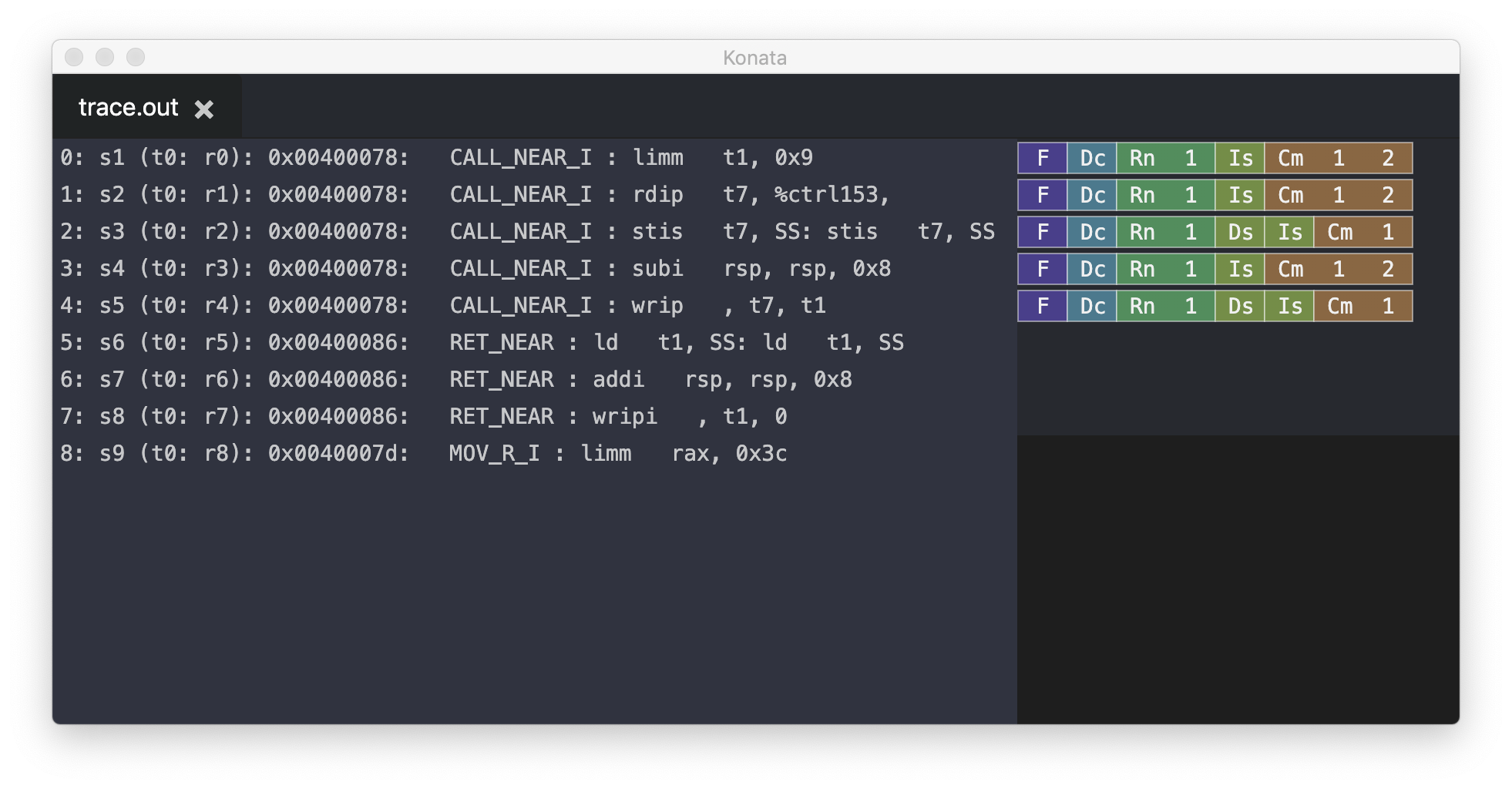
例えばcallqはobjdumpにより400078にあるが、Konataの可視化でも0x00400078にあることがわかる。
ここで、callqにあたる「CALL_NEAR_I」が、同じアドレス(0x00400078)で、5つの命令として並んでいることに注意。uops.infoでは4ないし5と書いてあるが、Gem5では5opsを採用しているようだ。
OoOの確認
In-Order 実行
さて、早速Out of Order実行を確認してみよう。まずはこんなコードを書いてみる。
.globl _start
_start:
call main
mov $60, %rax
syscall
main:
mov $1, %rax
mov $2, %rbx
mov $3, %rcx
mov $4, %rdx
add %rbx, %rax
add %rdx, %rcx
ret
ただ、rax,rbx,rcx,rdxにそれぞれ1,2,3,4の即値を代入して、rax+rbx、rcx+rdxを実行するだけのコードだ。
先程と同様な方法で実行バイナリを作ると、そのままアセンブリになっていることがわかる。
$ as test1.s -o test1.o
$ ld test1.o
$ objdump -S ./a.out
./a.out: ファイル形式 elf64-x86-64
セクション .text の逆アセンブル:
0000000000400078 <_start>:
400078: e8 09 00 00 00 callq 400086 <main>
40007d: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
400084: 0f 05 syscall
0000000000400086 <main>:
400086: 48 c7 c0 01 00 00 00 mov $0x1,%rax
40008d: 48 c7 c3 02 00 00 00 mov $0x2,%rbx
400094: 48 c7 c1 03 00 00 00 mov $0x3,%rcx
40009b: 48 c7 c2 04 00 00 00 mov $0x4,%rdx
4000a2: 48 01 d8 add %rbx,%rax
4000a5: 48 01 d1 add %rdx,%rcx
4000a8: c3 retq
これをGem5で実行して、パイプラインを可視化してみよう。
$ ./build/X86/gem5.opt --debug-flags=O3PipeView --debug-file=trace.out configs/example/se.py --cpu-type=DerivO3CPU --caches -c ./a.out
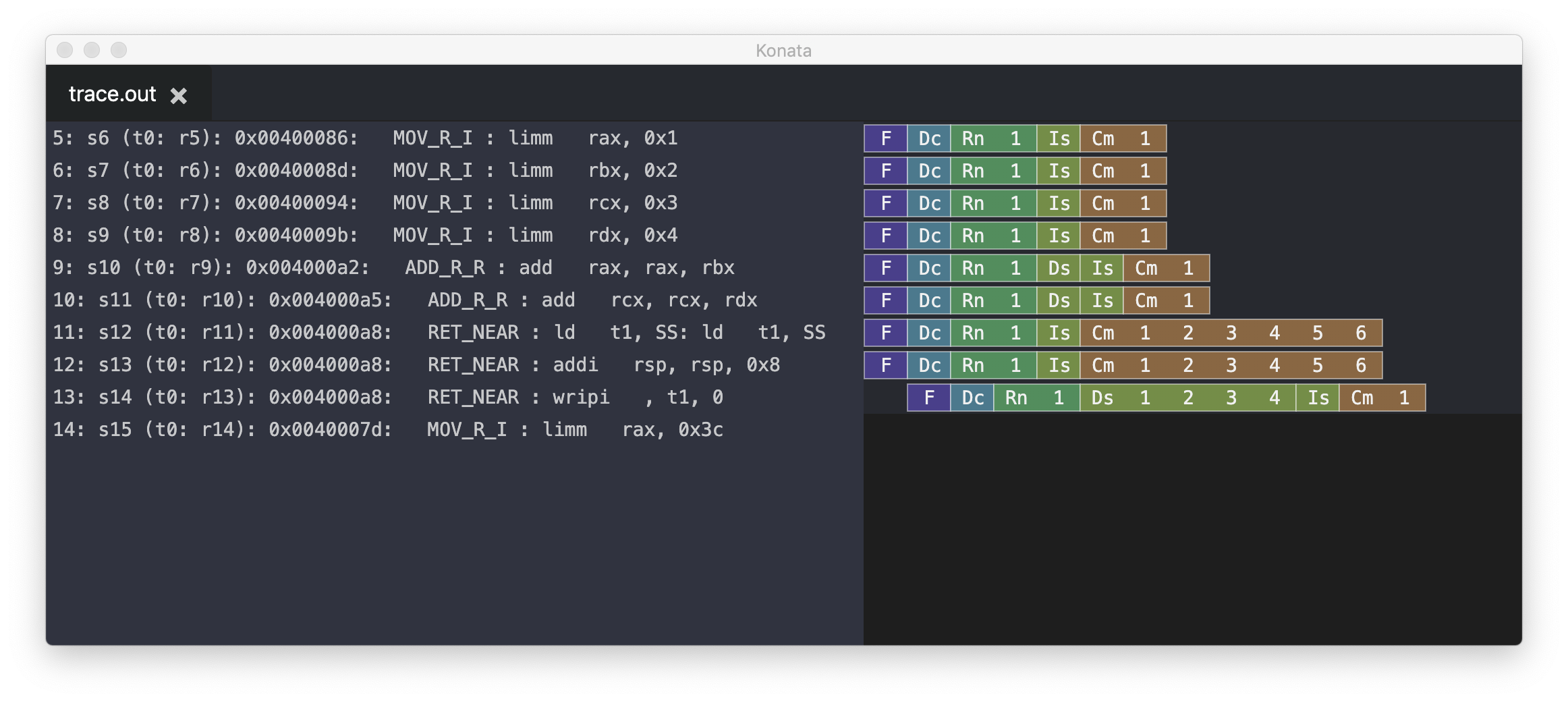
何も不思議なことは起きていない。4つのMov命令が同時に実行(Issue: Is)され、その1クロック後にAdd命令が二つ実行されているだけである。なお、ここではretq由来のRET_NEARが3つのμOPSに分解され、そのうち2つがMovと同時にissueされているが、ここでは詳細は省く。
Out-of-Order 実行
次に、命令の順番を少し変えてみよう。
.globl _start
_start:
call main
mov $60, %rax
syscall
main:
mov $1, %rax
mov $2, %rbx
add %rbx, %rax
mov $3, %rcx
mov $4, %rdx
add %rdx, %rcx
ret
今度は、mov $2, %rbxの直後にadd %rbx, %raxを置いた。add %rbx,%raxは直前のmov $0x2,%rbxの実行が完了するまで実行できない。その実行を待っていると、玉突き的に次の命令も待たされてしまう(この例ではスーパースカラによって実行できてしまうのだが、ここでは詳細は省く)。
これを先程と同じような手続きで実行バイナリにして、Gem5で実行しよう。ただし今回はtrace2.outという名前でトレースファイルを吐く(--debug-file=trace2.out)。
$ ./build/X86/gem5.opt --debug-flags=O3PipeView --debug-file=trace2.out configs/example/se.py --cpu-type=DerivO3CPU --caches -c ./a.out
Konataで可視化するとこうなる。
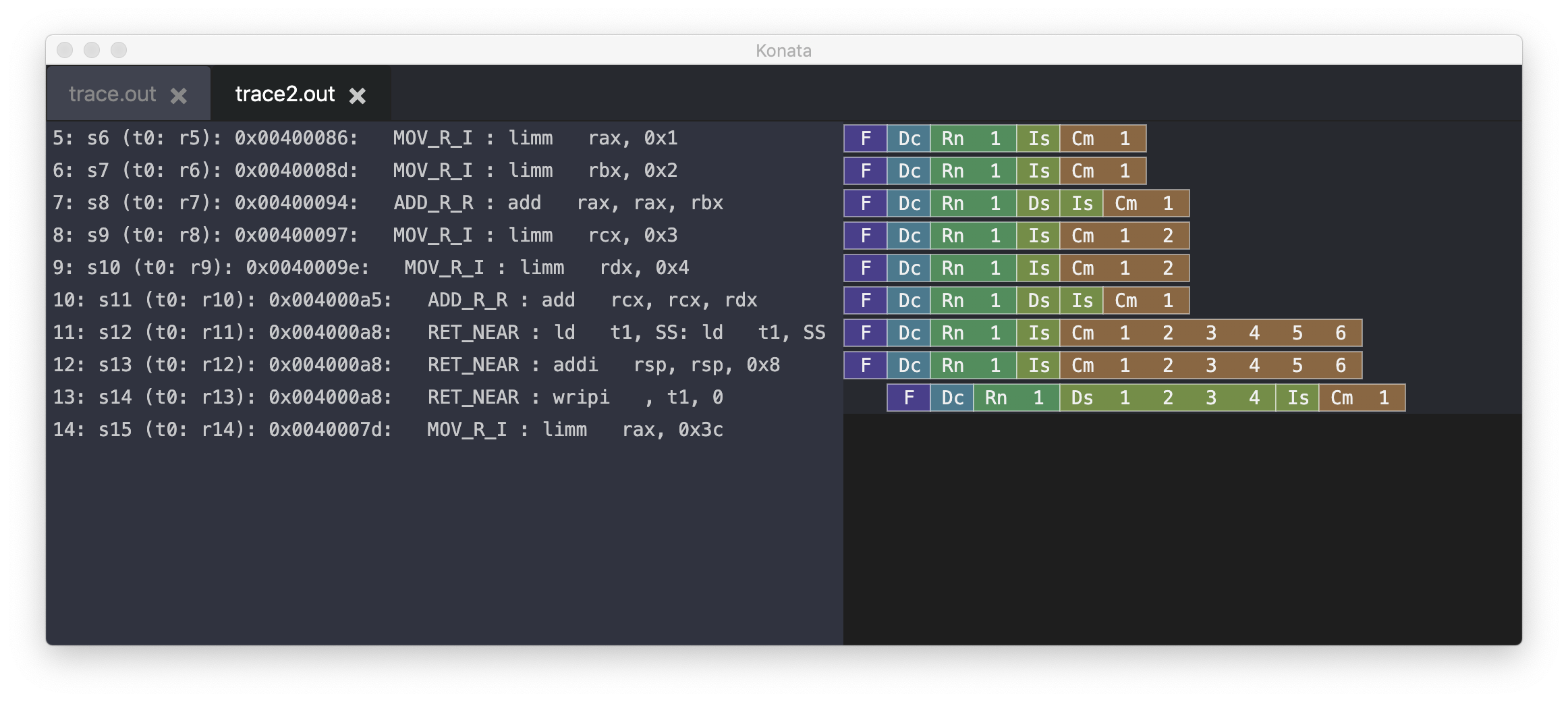
limm rcx, 0x3やlimm rdx, 0x4といったmov命令(limmはおそらくload immediateの略)が、その前にあるadd rax, rax, rbxの実行(Is)を飛び越して実行(Is:issue)されていることがわかるだろう。これがOut of Order実行である。
なお、近年のOoOの石では、「命令のフェッチ」と「命令の終了(Retire)」はアセンブリの順序を守る。なので、途中で命令の実行順序が入れ替わっても、フェッチ(F)と実行終了(Cmのお尻)は順番通りに並ぶ。順序が入れ替わるのはあくまで命令の実行(Issue, IS)である。
Konataには「Transparent Mode」というものがあり、二つのトレース情報を重ねて表示できる。
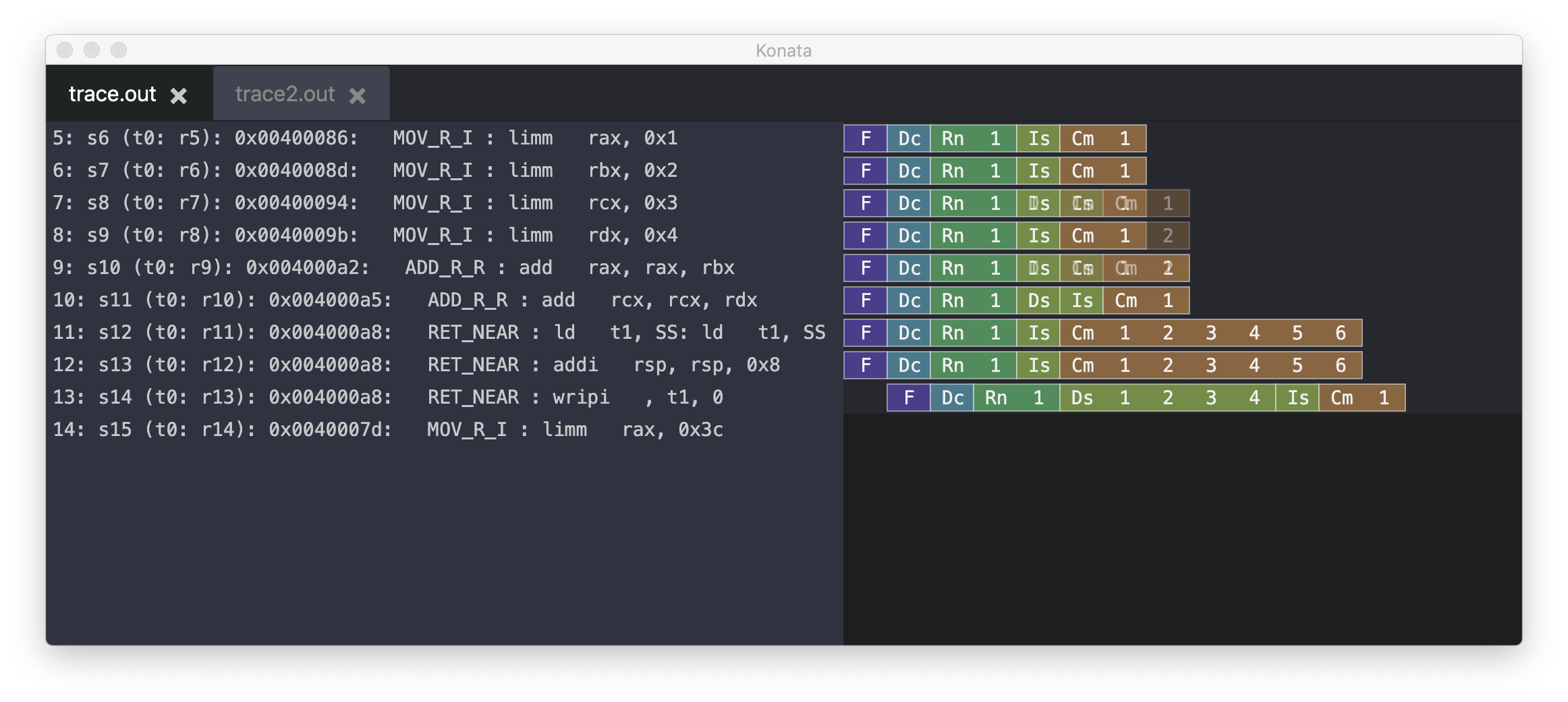
二つの実行プロファイルで、命令の実行順序は入れ替わっても、命令の終了時刻(クロック)は変わらないことがわかるであろう。
まとめ
Gem5により、x86のOut of Order実行による命令の実行順序入れ替えをシミュレートしてみた。Gem5はあくまでAlpha 21264を模したCPUモデルを採用しており、必ずしもx86の実行をエミュレートしているわけではないのだが、とりあえず「OoOだなぁ」と実感することはできたと思う。また、Gem5を使うのに普通のc言語からコンパイルするとバイナリが膨れ上がっていろいろ面倒なので、ここに挙げたシンプルなバイナリを作るアセンブリで解析するのが楽じゃないかな。トレースファイルも小さくなるし。
ちなみにガチでx86の性能予測をしようとすると、OoOやμOPS、スーパースカラ、分岐予測などが絡んでくるので非常に難しい、というか常人には不可能だと思う。
追記
x86のコードアナライザとしてIntelからIntel Architecture Code Analyzer (IACA)というものが公開されており、uops.infoでも実測値とIACAの値が併記されているのだが、現在ステータスがEnd Of Lifeになっているそうだ(thx, hiroさん)。同様なツールとして、LLVMからllvm-mca - LLVM Machine Code Analyzerというものが出ており、IACAもそっちを使うことを推奨しているようなので、興味のある方は参照されたい。