TL;DR
- Markdownからdocxへの変換はpandoc使え
- 著者はそれに気が付かずにRubyでXMLをいじってdocxへの変換スクリプトを書いてしまったのでここに埋葬
- RubyでXMLをいじる練習には良いかもしれない
ソースは以下の場所にある
https://github.com/kaityo256/md2docx
はじめに
いろんなところで言い尽くされていることだが、Microsoft Wordは文書作成に向いていない。VCSとの相性が悪いし、履歴をファイルに保存させるとどんどん重くなる。そもそも長期間修正を続けていくとファイルが疲れていく。個人的に一番困るのが、大きなファイルを修正していると、時々とんでもなく遠くのリストが論理的につながってしまい、数字がおかしくなったりすること。例えばいつのまにか30ページ目の箇条書きのうちの4番目のリストだけが2ページ目の箇条書きの一部として認識されていたりする。
そんなわけで「Wordは文書作成ツールではなく、文書装飾ツールである」と割り切って使いたいものだが、社会人として生きていると、どうしても最終生成物がMS Wordでなければならない時がある。でもWordで文書を作成するのはイヤだ。というわけで、通常はMarkdownないしLaTeXで文章を作成し、必要に応じてそこからdocxに変換することにしたい。
で、そういう変換ツールとしてpandocが有名で、それを使えば良いのだが、僕が試した時にはpandocでうまく変換できなくて、変換スクリプトを作った後に、ふと手元のpandocのバージョンが古いことに気が付き、最新版を試したらあっさり変換できてしまった。なのでもう変換スクリプトは必要ないのだが、せっかく作ったのでここに葬っておきたい。
方針
これは趣味ではなく業務で使うものなので、なるべく簡単に済ませたい1。そんなわけで以下のような方針で作った。
- なるべく楽をする
- 必要最低限のMarkdownの書式に対するパーサを自分で書く
- テンプレートとなるdocxファイルをいじる
なるべく楽をする
まず、「なるべく楽をする」という方針から、できればMarkdownパーサは世の中に落ちているものを使いたくなる。しかし、多くのパーサは、リストの処理が入れ子構造になる。つまり、
* list1
* list2
* list3
みたいなリストが与えられた時、latexなら
\begin{itemize}
\item list1
\begin{itemize}
\item list2
\begin{itemize}
\item list3
\end{itemize}
\end{itemize}
\end{itemize}
HTMLなら
<ul>
<li> list1
<ul>
<li> list2
<ul>
<li> list3
</ul>
</ul>
</ul>
みたいになる。しかし、WordのXMLは、こういう入れ子構造ではなく、ただフラットに並べられたものとなる。入れ子構造を前提としたパーサを使ってフラットな構造を作るのをちょっと試してみたがすごく面倒だったので、自分でリストのパーサを書いた方が楽だと判断した。
必要最低限のMarkdownの書式に対するパーサを自分で書く
自分でMDパーサを書くことにしたので、対応するMDの文法は最小限とした。具体的には以下の記法のみに対応する。
# header1
## header2
### header3
* bullet item 1
* bullet item 2
* bullet item 3
1. numeric item 1
1. numeric item 2
1. numeric item 3
ヘッダ、リスト、それぞれ3段階までのみ。これだけならパーサを書くのも簡単。
テンプレートとなるdocxファイルをいじる
よく知られているようにdocxファイルはzipされたXMLなので、対応するXMLを吐けば良い2。しかし、全てのコンポーネントを吐くのは大変なので、既存のdocxファイルを改造することにする。つまり、
- テンプレートとして適当なdocxファイルを用意し
- それを一時ディレクトリにunzipし
- RubyからREXMLで処理して修正
- それをまたzipして新しいdocxファイルにする
という処理を行う。具体的には以下のような処理となろう。
outputfile = "output.docx"
templatefile = "template.docx"
inputfile = "input.md"
Dir.mktmpdir(nil,'./') do |dir|
puts "Using #{templatefile}"
`cd #{dir};unzip ../#{templatefile}`
files = Dir.glob(dir+"/*").map{|f| File.basename(f)}
puts "Reading #{inputfile}"
MD2XML.new.convert(dir,inputfile)
puts "Generating #{outputfile}"
`cd #{dir};zip -r ../#{outputfile} #{files.join(" ")}`
puts "Done."
end
ほぼ上記の処理そのままなので解説は不要かと思う。zipを使うのにziprubyとかrubyzipとか使おうと思ったが、やってみると意外に面倒なので、外部コマンドのzip/unzipを呼ぶことにした3。Dir.mktmpdirで一時ディレクトリを作ってそこに展開。その際に展開されたファイルリストをDir.globで覚えておき、あとでそれをzip -rすることで完成。
あとは変換の中身であるMD2XML.new.convert(dir,inputfile)を作り込んで行けばよい。
テンプレートファイルの解析
まず、こんなテンプレートファイルを用意する。

対応することに決めたMarkdown記法にそれぞれ対応する。これをそのままunzipすると、
- word/document.xml にドキュメントの本体(実体は段落情報のリスト)
- word/numbering.xml にリストの情報
- word/styles.xml にスタイル情報
がそれぞれ保存されていることがわかる。このうち、最も重要なのはリストの情報である。これが「どのリストアイテムがどのリストアイテムと論理的に同じグループか」を整理しているため、これがバグると、冒頭で述べたような「とんでもないところにあるリストアイテムが論理的につながってしまう」といった事象が起きる。
スタイルについては触らないことにする。あとはdocumentの中身をいちど全部削除し、Markdownを解析しながらどんどんXMLを追加していけば良い。
MD2XMLの実装
さて、MD2XMLクラス(クラスにする必要があるかどうか微妙だが)を作る。外とのインタフェースはconvertとし、docxを展開した一時ディレクトリ名と入力のMarkdownファイルを引数としよう。
具体的にはこんな感じ。
@id = 0
make_numhash(dir)
@in_list = false
@list_id = Array.new(10)
@stylehash = Hash.new
@current_level = 0
@numIdhash = Hash.new
make_document(dir,mdfile)
make_numbering(dir)
end
リスト関連でごちゃごちゃやっているが、このうちmake_documentというのがdocumetのxmlをいじるところである。
ドキュメントの解析
まず、テンプレートファイルのdocumentを解析する。目的は、テンプレートファイルで指定されたスタイルを保存すること。ただし、ヘッダと通常のパラグラフについてはstyleに設定されたものをそのまま使うので不要。必要なのはリストのスタイル(実際にはスタイル番号)の取得。
最初に、unzipされたxmlファイルを一気に読み込み、REXML::Documentオブジェクトを作る。
file = dir + '/word/document.xml'
doc = REXML::Document.new(File.read(file))
そのあと、w:bodyタグを取得し、以後このオブジェクトに対して操作する。
body = REXML::XPath.first(doc.root,"w:body")
docxのドキュメントは、このw:bodyノードにひたすらw:pノードがぶら下がる形になっている。これらを辿ってenum1とかbullet2とか、予め決めておいた単語を探し、その単語を含むパラグラフノードをハッシュに保存しておく。
REXML::XPath.each(body,"w:p") do |e|
if e.to_s =~/(enum[1-9])/ or e.to_s =~/(bullet[1-9])/
@stylehash[$1] = e
end
end
それが終わったら、w:bodyが持つ全てのw:pノードを削除する。
REXML::XPath.each(body,"w:p").collect{|e| body.delete_element e}
これで準備完了。空になったドキュメントをパーサに渡し、Markdownを解析しながらパラグラフを追加していくことにする。
マークダウンパーサ
make_documentの中の、以下のwhile文がMarkdownをパースしているところ。
open(mdfile) do |f|
while line = f.gets
parse(line,body)
end
end
テーブルとか、複数行に渡る何かはサポートしないことにしたので、パーサを組むのは簡単。実際、これだけで書ける。
def parse(line,body)
if line=~/^(#+) (.*)/
add_header($2,$1.size,body)
elsif line=~/^(\s*)[0-9]+\. (.*)/
level = $1.length/4+1
add_listitem($2,level,"enum"+level.to_s,body)
elsif line=~/^(\s*)\* (.*)/
level = $1.length/4+1
add_listitem($2,level,'bullet'+level.to_s,body)
else
add_paragraph(line,body)
end
end
要するに、
- 行頭が#から始まったらヘッダ。レベルは#の数。
- 行頭が空白+*で始まったら箇条書き。レベルは空白の数/4。
- 行頭が空白+数字+ピリオドで始まったら番号付きリスト。レベルは空白の数/4。
- それ以外はパラグラフ
というだけ。
パースが終わったら、docに全情報が入っているはずなので、それをファイルに保存すれば良い。
File.write file, doc.to_s
パラグラフ
最も簡単なのがパラグラフ。つまり「地の文」。構造はw:pの中にw:rがあり、その中にw:tタグがあって、そこにテキストが入っている。
<w:p>
<w:r>
<w:t>
ここがテキスト
</w:t>
</w:r>
</w:p>
なので、そういうXMLを作れば良い。特に難しいところはないと思う。
def add_paragraph(text,body)
@in_list = false
p = REXML::Element.new('w:p',body)
r = REXML::Element.new('w:r',p)
REXML::Element.new('w:t',r).text = text
end
@in_listとか言うのは、あとでリスト処理をするためのもの。
ヘッダ
ヘッダも難しくない。ヘッダのタイトルの構造は通常のパラグラフと同じ。ただし、スタイルを指定するところが入ってくる4。
<w:p>
<w:pPr>
<w:pStyle w:val='1'/>
</w:pPr>
<w:r>
<w:t>
section 1
</w:t>
</w:r>
</w:p>
<w:p>
<w:pPr>
<w:pStyle w:val='2'/>
</w:pPr>
<w:r>
<w:t>
section 1.1
</w:t>
</w:r>
</w:p>
ここで、スタイル番号がw:pStyleのw:valattributeで指定されている。実際に、どのレベルのヘッダがどの番号になるかが固定されているかどうかは僕は知らない。本当はテンプレートを解析して調べないといけないのかもしれないが、ここでは1番が、レベル1のヘッダ、2番がレベル2のヘッダ・・・となっていることを仮定して、決め打ちで作ってしまおう。そういうテンプレートを用意すれば問題は起きない。ヘッダの追加コードはこんな感じになる。
def add_header(text,level,body)
@in_list = false
node = REXML::Element.new('w:p',body)
pPr = REXML::Element.new('w:pPr',node)
REXML::Element.new('w:pStyle',pPr).add_attribute("w:val",level)
r = REXML::Element.new('w:r',node)
REXML::Element.new('w:t',r).text = text
end
w:pStyleのw:valattributeにレベルを指定するところが追加されただけで、あとは通常のパラグラフと同じ処理になる。
リスト
さて、最も面倒なのがリストの処理である。といってもリストに対応するXMLの出力はさほど難しくない。難しいというか面倒なのは「論理グループの処理」である。それは後述することにして、まずリストのXMLの構造はこうなっている。
<w:p>
<w:pPr>
<w:pStyle w:val='a3'/>
<w:numPr>
<w:ilvl w:val='0'/>
<w:numId w:val='6'/>
</w:numPr>
</w:pPr>
<w:r>
<w:t>
enum1
</w:t>
</w:r>
</w:p>
テキストがw:r/w:tに入ってるのは同じ。w:pPrには、w:pStyle、w:numPrがある。それぞれ、
- w:pPr
- w:pStyle (スタイル番号)
- w:numPr
- w:ilvl (レベル)
- w:numId (グループ番号)
という関係になっている。スタイル番号は、別途定義されたスタイルへのポインタ。レベルはネスト深さ。そしてグループ番号は、同じ番号をもつリストが、論理的に同じグループに所属するということを表す。例えば、
1. enum1
1. enum2
1. enum3
1. enum2
という構造は

と変換されてほしい。この時同じレベルの「enum2」は同じグループに属してほしい。しかし、同じグループである「enum2」にぶら下がっている「enum3」は異なるグループでなければならない。
しかし、同じレベルであっても、異なるグループにいる場合には異なるグループ番号を与えなければならない。例えば
1. hoge1
1. hoge2.1
1. hoge2.2
1. fuga1
1. fuga2.1
1. fuga2.2
は
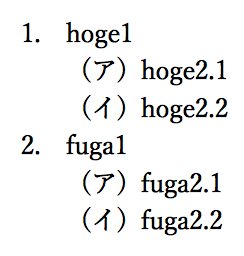
のようになって欲しいが、このうち「hoge2.1, hoge2.2」と「fuga2.1」「fuga2.2」は同じスタイルだが異なるグループ番号にならないといけない。さらに「hoge1」と「fuga1」は同じグループ番号に所属させる必要がある。そういう処理をするのがちょっと面倒くさい。
以上の処理を実装するとこんな感じ。
def add_listitem(text,level,style,body)
if !@in_list
@in_list = true
@id = @id + 1
@list_id[level] = @id
end
if level > @current_level
@id = @id + 1
@list_id[level] = @id
end
@current_level = level
myid = @list_id[level]
node = REXML::Element.new('w:p',body)
pPr = REXML::Element.new('w:pPr',node)
pStyle = REXML::Element.new('w:pStyle',pPr)
numPr = REXML::Element.new('w:numPr',pPr)
REXML::Element.new('w:ilvl',numPr).add_attribute("w:val",(level-1).to_s)
REXML::Element.new('w:numId',numPr).add_attribute("w:val",myid)
pstyle_val = REXML::XPath.first(@stylehash[style],"w:pPr/w:pStyle").attribute("w:val")
pStyle.add_attribute("w:val",pstyle_val)
REXML::Element.new('w:ind',pPr).add_attribute("w:leftChars","0")
r = REXML::Element.new('w:r',node)
REXML::Element.new('w:t',r).text = text
numid = REXML::XPath.first(@stylehash[style],'w:pPr/w:numPr/w:numId').attribute('w:val').to_s
@numIdhash[myid] = @numhash[numid]
end
ちょっとややこしいが、同じグループに属すノードに同じグループ番号(myid)が振られるようにしてある。レベルはw:pPr/w:numPr/w:ilvlのw:valattributeに設定する。
スタイル番号は、同じスタイルを持ったノードをハッシュ(@stylehash)に入れてあるので、そこからw:pPr/w:pStyleのw:valを参照している。最後、numberingをいじるためのハッシュ@numIdhashを作っているが後述。
w:indのw:leftCharsattriubuteが何をしているか理解できていないのだが、これやらないとインデントが乱れるので入れている。
numberingの出力
さて、docx出力の最大の難関は番号付け、つまりword/numbering.xmlの出力である。僕も仕様を理解している自信がないのだが、とりあえずnumbering.xmlの構造はこうなっている。
<w:abstractNum w:abstractNumId='0' w15:restartNumberingAfterBreak='0'> ... </w:abstractNum>
<w:abstractNum w:abstractNumId='1' w15:restartNumberingAfterBreak='0'> ... </w:abstractNum>
<w:num w:numId='1'>
<w:abstractNumId w:val='0'/>
</w:num>
<w:num w:numId='2'>
<w:abstractNumId w:val='1'/>
</w:num>
最初にずらずらとw:abstractNum要素がある。これは、レベル1からレベル9までのリストのフォーマット情報()が含まれている。例えば、レベル1の番号付きリストなら、
<w:numFmt w:val='decimal'/>
<w:lvlText w:val='%1.'/>
となっており、decimalで、%1が数字に置換されるので、例えば15番目なら「15.」となる、みたいな情報が入っている。
次にw:num要素がならんでおり、これはw:abstractNum要素へのポインタになっている。リスト要素のw:pPr/w:numPr/w:numIdは、このw:num要素の番号を指しており、それを経由してw:abstractNum要素を指している。
同じ論理グループに属すw:pPr/w:numPr/w:numIdが同じ数字であることから、w:numがグループ番号と思いたくなるが、どうも異なるw:numへのポインタであっても、それらが同じw:abstractNum要素を指していると、同じグループとみなされてしまうらしい5。
したがって、同じスタイルを持つリストであっても、異なるグループに所属させるためには、異なるw:abstractNumを用意してやる必要があるため、グループの数だけ、全く同じ中身のw:abstractNum要素を用意してやる必要がある。
さらに、word/numbering.xmlファイルは、要素の順番が重要になる。つまり、最初にw:abstractNum要素、次にw:num要素となるように、数字の順番で並べてやる必要がある。
そんなわけで、
- 最初に
word/numbering.xmlを解析しておく - Markdownをパースし、グループ解析をしておく
- 異なるグループが異なる
w:abstractNumを指すように、w:abstractNumをグループの数だけコピペする - 最後にグループの数だけ
w:num要素をならべる
という処理をしている。繰り返すが、これが最善の方法なのか自信がない。そういうことをやっているのがソースの中のmake_numhash(dir)とmake_numbering(dir)である。
make_numberingは、パースされた情報をもとにword/numberingを再構築するコードで、中身はこうなっている。
def make_numbering(dir)
file = dir + '/word/numbering.xml'
doc = REXML::Document.new(File.read(file))
abstractNumIds = REXML::XPath.each(doc.root,"w:abstractNum").collect{|e| e}
nums = REXML::XPath.each(doc.root,"w:num").collect{|e| e}
REXML::XPath.first(doc.root).each{|e| doc.root.delete e }
@numIdhash.each do |k,v|
e_abs = Marshal.load(Marshal.dump(abstractNumIds[v]))
e_abs.add_attribute("w:abstractNumId",abstractNumIds.size)
n = REXML::Element.new("w:num")
n.add_attribute("w:numId",k)
REXML::Element.new("w:abstractNumId",n).add_attribute("w:val",abstractNumIds.size)
abstractNumIds.push e_abs
nums.push n
end
abstractNumIds.size.times do |i|
e = abstractNumIds[i]
REXML::XPath.first(e,"w:nsid").add_attribute("w:val",sprintf("%08d",i))
doc.root.add e
end
nums.each{|e| doc.root.add e}
File.write file, doc.to_s
end
処理は
- '/word/numbering.xml'の中身を
REXML::Documentオブジェクトとしてdocに受け取る - 既存の
w:abstractNum要素とw:num要素を保存しておく -
docの中身を空にする - パースで得られたグループの数だけ
w:abstractNum要素をコピペする(Marshal.loadとMarshal.dumpのところ) -
w:abstractNumIdにあらためて通し番号をふりながらdocに追加 -
w:num要素をdocに追加 - ファイルに保存して完成
という流れ。以上でMarkdownからdocxへの変換は完成である。
結果
こんなMarkdownをくわせてみる。
# md2docxのサンプル
## パラグラフ
ここはパラグラフです。
## リスト
### 番号付きリスト
1. hoge1
1. hoge2.1
1. hoge2.2
1. fuga1
1. fuga2.1
1. fuga2.2
### 箇条書き
* bullet1
* bullet2
* bullet3
* bullet1
* bullet2
* bullet3
### まざったもの
* bullet1
1. enum1
* bullet3
1. enum2
$ ruby md2docx.rb
Using template.docx
Reading input.md
Generating output.docx
Done.
できあがったdocxファイルはこんな感じ。

なんかできてるっぽいですね。
まとめ
RubyでMarkdownからdocxファイルを作ってみた。僕はこれを自分の業務で使っている。これを作ったことでだいぶ幸せになった。幸せポイントを列挙する。
- 比較的大きな文書(提出はdocx)をmarkdownで執筆できるようになった。これでGitなどのVCSと相性が良くなり、コマンドラインからdiffが簡単にとれたり、Redmineのリポジトリ表示機能と連携したりできるようになった。
- 「2つの異なるWordファイルがあり、片方が片方に強く依存していて、どちらかを書き換えたらもう片方を書き換えないといけない」という制約があったのだが、これも、「片方をmarkdownで書いて、もう片方はそちらから自動生成し、最後にどちらもdocxに変換」ということがmake一発でできるようになった。これで「片方の修正をもう片方に反映忘れ」とかがなくなった。
- 「大きな修正」があるときにはレビューがあり、そのときにWordの変更履歴の表示をした状態の資料を印刷する必要があったのだが、「修正前」と「修正後」のMarkdownファイルからそれぞれdocxファイルを作り、Wordの「文書の比較」をすることで「Wordの変更履歴の表示をした状態の資料」が作れるようになった。
まぁ、なんといっても一番大きいのは、「MS Wordで大きな文書を編集しなくて良くなった」ということに尽きる。普段使っているエディタに比べて、何をするにしてもレスポンスが「ワンテンポ」遅く、それが極めてストレスフルな上に、コピペしているとリストの論理関係がごちゃごちゃになり、かつ「同じスタイルを使っているけど異なる論理グループに属すリスト」のスタイルを一括で変更する手段がないので、何かスタイルを変更する際にはちまちま全部修正していかないといけない(そして一部忘れたりする)・・・
一部zipを使うために外部コマンドを呼んだり、テンプレートdocxを用意してそれを改造する「ズル」をしているが、それを考えても150行足らずのスクリプトでMarkdownからdocxが作れてしまうので、ちょっと遊んでみるには面白いと思う。6
本記事が「MS Wordは嫌いだけど、仕事上どうしてもそれを使わなきゃいけないような人」の参考になれば幸いである。
-
それなら最新版のpandocでできることに早く気がつけよという感じだが、まぁなんというか、こういう文書仕事をしていると気が滅入ってくるので、たまにこういうスクリプト書いてないと正気を保てないのよ。 ↩
-
WIN32OLEとかAppleScriptとか使うことも考えたんだけど、いろいろやってみて、XMLいじっちゃった方が早い気がしてきた。OS選ばないしね・・・。 ↩
-
言うまでもないけど重大なセキュリティホールになるから、こういうことをサーバ側のプログラムとかでやっちゃ駄目ですよ。ローカルのスクリプトなら何やってもいいけど。 ↩
-
実は通常のパラグラフにもスタイルを指定する
w:rPrタグを含む。そういう意味で、ヘッダとパラグラフの構造は同じ。 ↩ -
もしそうだとすると、なぜわざわざ
w:num要素とw:abstractNum要素を分離したか理解できないのだが・・・。識者のコメント求む。 ↩ -
っていうか今書いてて思ったけど、RubyじゃなくてもっとDOMの操作に向いた言語(JavaScriptとか?)で組んだ方が楽だった気がする。 ↩