LangChainで書く処理(i.e. chain)は、RunnableをLCELでつないだワークフローみたいな感じになる。
Argo WorkflowsとかTektonみたいなクラウドネイティブなワークフロー実行エンジンには、ワークフローの各ステップを個別のコンテナで実行するようなのがある。
ならばRunnableもコンテナで実行したらどうかという思いつき。
LangChainとは
LangChainは、LLMを使ったアプリケーションを開発するためのPythonのフレームワーク。
LangChainを使うと、様々なLLMの呼び出しや周辺の処理を一貫したインターフェースで扱えて、RAGやチャットモデルやLLMエージェントの開発が楽になる。
LangChain Expression Language (LCEL)というのがLangChainの特徴的な機能で、プロンプトの生成、LLM呼出し、ベクトルDB検索、出力の成型みたいな、LLMアプリに必要な様々な処理をどう組み合わせるかを宣言的に表現できる。
LCELでつなぎ合わせた一連の処理をchainという。
chainに組み込む個々の処理はRunnableインターフェースを実装していて、入力パラメータと出力パラメータを合わせればRunnable間を自由につなげるし、chainもRunnableになるのでchainを組み合わせることもできるし、さまざまな処理をするRunnableを一貫した方法で実行できる。
LangChainコード例
例えば、コマンドラインから受け取ったポケモンに関する質問をOpenAIのLLMに投げて、回答を表示するプログラムは以下のように書ける。
import sys
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# プロンプトを生成するRunnable
prompt = ChatPromptTemplate.from_messages([
(
"system",
"あなたはポケモンのエキスパートです。ユーザの質問に答えてください。",
),
(
"human",
"質問: {input}",
)
])
# プロンプトを受け取ってLLMに投げるRunnable
llm = ChatOpenAI(model="gpt-4o-mini")
# LLMの出力から回答を抽出するRunnable
output_parser = StrOutputParser()
# LCELでchain化
chain = prompt | llm | output_parser
# chain実行
print(chain.invoke({'input': sys.argv[1]}))
このコードは、プロンプトを生成するRunnableと、プロンプトを受け取ってLLMに投げるRunnableと、LLMの出力(i.e. 回答とメタデータを含む構造化データ)から回答を抽出するRunnableのインスタンスを作り、LCELでつないでchainにして実行する。
このコードはOpenAIのLLMを使うので、実行する際は、環境変数にOpenAIのAPIキーを設定しておく必要がある。
$ export OPENAI_API_KEY=sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxx
$ python sample.py "ピカチュウの進化前は?"
ピカチュウの進化前は「ゼニガメ」です。ゼニガメは最初のポケモンの中で、最初の進化を持つポケモンです。
ただし、ピカチュウの進化前は「ポッチャマ」とも言われています。
実際には、ピカチュウは「ピチュー」というポケモンから進化します。
ピチューは第二世代のポケモンで、ピカチュウの前の進化形です。
実行はできたけど、LLMの回答はいまいち。
一応ぎりぎり正答。
RunnableK8s
上で説明したようなRunnableを、Kubernetes上のコンテナで実行するRunnable、それがRunnableK8s。
ソースはGitHubに置いた。
RunnableK8sを使って、LLM呼出しをKubernetes上で実行するように前節のコードを書き換えると以下のようになる。
import sys
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
+from runnables.runnable_k8s import RunnableK8s
# プロンプトを生成するRunnable
prompt = ChatPromptTemplate.from_messages([
(
"system",
"あなたはポケモンのエキスパートです。ユーザの質問に答えてください。",
),
(
"human",
"質問: {input}",
)
])
# プロンプトを受け取ってLLMに投げるRunnable
llm = ChatOpenAI(model="gpt-4o-mini")
# LLMの出力から回答を抽出するRunnable
output_parser = StrOutputParser()
# LCELでchain化
-chain = prompt | llm | output_parser
+chain = prompt | RunnableK8s(bound=llm) | StrOutputParser()
# chain実行
print(chain.invoke({'input': sys.argv[1]}))
LLMを呼ぶRunnableをRunnableK8sでラップした。
これを実行する際には、前節でやったように環境変数を設定する代わりに、コンテナを実行するKubernetesにSecretでOpenAIのAPIキーを設定しておく。
$ kubectl create secret generic runnable-k8s-ee --from-literal=OPENAI_API_KEY=sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxx
あとはkubeconfigを設定して、通常通りに実行すればいい。
$ python sample.py "ピカチュウの進化前は?"
ピカチュウの進化前は「ポッチャマ」です。ピカチュウは「ピチュー」というポケモンから進化します。
ピチューは第二世代のポケモンで、ピカチュウは第一世代のポケモンです。
ピチューは「幸せの種」を持っていると進化することができます。
(幸せの種?)
実行した結果の見た目はRunnableK8s使用前と変わらないけど、chain実行時に以下のようなことが起こる。
- Kubernetes上でkaitoy/runnable-k8s-ee:latest
というコンテナイメージがpullされ、defaultネームスペースでrunnable-k8s-eeという名のpodが起動し、さっきつくったSecretがマウントされる。 - LLMを呼ぶRunnableのインスタンスと、そのインプットとなるプロンプトがpodに送信され、pod内でLLMが実行される。
- RunnableK8sがpodからLLM実行結果を取得し、最後のRunnableであるStrOutputParserに渡す。
LLM実行がpodのなかで起こるので、OpenAIのAPIキーはKubernetesに登録しておけばよくて、コマンドラインを実行する人は知らなくていい。
RunnableK8sにはこの辺りの、セキュリティとか権限の分離とかのユースケースがありそうな気がする。
あとは負荷分散とか?
ちなみに、chainもRunnableなので、RunnableK8sでchain全体をラップすることもできる。
import sys
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from runnables.runnable_k8s import RunnableK8s
# プロンプトを生成するRunnable
prompt = ChatPromptTemplate.from_messages([
(
"system",
"あなたはポケモンのエキスパートです。ユーザの質問に答えてください。",
),
(
"human",
"質問: {input}",
)
])
# プロンプトを受け取ってLLMに投げるRunnable
llm = ChatOpenAI(model="gpt-4o-mini")
# LLMの出力から回答を抽出するRunnable
output_parser = StrOutputParser()
# LCELでchain化
-chain = prompt | RunnableK8s(bound=llm) | StrOutputParser()
+chain = RunnableK8s(bound=prompt | llm | StrOutputParser())
# chain実行
print(chain.invoke({'input': sys.argv[1]}))
この場合、プロンプト生成から回答の抽出まで全部podで実行される。
$ python sample.py "ピカチュウの進化前は?"
ピカチュウの進化前は「プラスル」と「マイナン」という2つのポケモンが存在しますが、ピカチュウ自体は「ポッチャマ」というポ ケモンの進化形ではありません。
ピカチュウの進化前は「ゼニガメ」です。
ピカチュウは「ピカチュウ」を進化させることで「ライチュウ」になります。最初の進化は「ピチュー」です。
ピチューは「しんかのきせき」などの条件を満たすことでピカチュウに進化します。
実際に実行してみても違いは分かりにくいけど。
LLMがなぜか大混乱してるのはRunnableK8sのせいではない。
RunnableK8sの仕組み
RunnableK8sはRunnableの実装で、Runnableインターフェースにはいくつもメソッドがあるけど、今回やった実装で重要なのは、自分に課せられた処理を実行するinvoke()だけ。
Runnableのinvoke()は、インプットを受け取って、処理を実行して、アウトプットを返す同期メソッド。
RunnableK8sの場合、invoke()の中で実行する処理は、ラップしたRunnableをKubernetes上でinvoke()すること。
RunnableK8sが実行されたときに走る処理を図にするとこんな感じ。
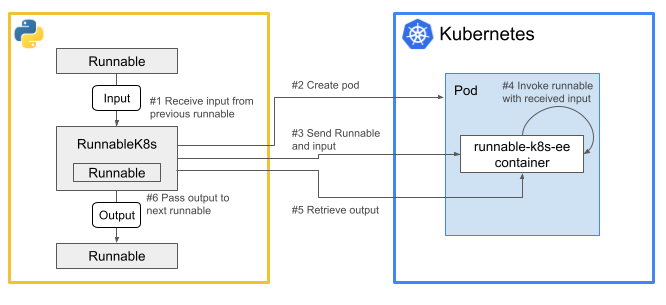
上図の処理の流れを詳しく書くと以下のようになる。(番号は図内のものに対応。)
- RunnableK8sの
invoke()が呼ばれて、前のRunnableのアウトプットがインプットとして渡される。 - RunnableK8sがKubernetesにアクセスしてPodを作る。Podの中ではrunnable-k8s-eeコンテナが起動して、標準入力からのデータを待つ。
- RunnableK8sが、runnable-k8s-eeコンテナの標準入出力にアタッチし、ラップしたRunnableとインプットをシリアライズして標準入力に流し込む。
- runnable-k8s-eeコンテナ側で、標準入力から受け取ったRunnableとインプットをデシリアライズして実行し、そのアウトプットをシリアライズして標準出力に吐く。
- RunnableK8sが、runnable-k8s-eeコンテナの標準出力を読み、アウトプットを受け取り、デシリアライズする。
- デシリアライズしたアウトプットをreturnする。
Runnableのシリアライズは、langchain_core.load.dumps()でJSON形式にしてから、Base64エンコードしてる。
インプット・アウトプットのシリアライズは、pickle.dumps()してからBase64エンコードしてる。
実際はどっちもlangchain_core.load.dumps()でいいかもしれないし、どっちもpickle.dumps()でいいのかもしれない。
langchain_core.load.dumps()は対応してないオブジェクトがまあまあありそう。
標準入出力でpodとやりとりするのは、Ansible Automation Controllerがジョブの実行環境のpodにプレイブックを送ったり実行結果を受け取ったりするときの方式をまねた。
Ansible Automation Controllerはansible/receptorのKubernetes workという機能でこの方式を実現してるので、それを活用する手もあるかもしれない。
現時点でRunnableK8sにはstream()は実装できてないけど、標準入出力を使う方式だとpodとデータを順次やり取りできるので、理屈では実装できそうな気がする。
関連記事
以前のLangChain、LangServe、LangGraphに関する記事: