これは、Kubernetes Advent Calendar 2024の10日目の記事で、以前投稿した「LangChainのRunnableをKubernetesで実行するRunnableを書いてみた」という記事の続き。
RunnableK8sとは
RunnableK8sは、LangChainのRunnalbeをラップすると、その部分をKubernetesで実行できるRunnable。
以下のような感じで、ラップしたRunnableとそのインプットをシリアライズして、Podの標準入力に流し込んで渡して、Pod内で実行し、結果をPodの標準出力経由で返す、という風に動く。
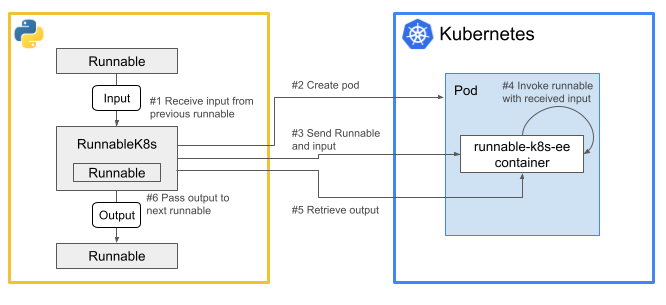
前回の記事の時点ではRunnableの最も基本的なメソッドであるinvoke()だけを実装していた。
今回の記事では、batch()とstream()を実装して動かしてみる。
batch()とstream()とは
invoke()が、ひとつのインプットを受け取り、Runnableを同期的に一回一括で実行して一つのアウトプットを生成するのに対して、batch()とstream()は以下のような感じ。
-
batch(): 複数のインプットを受け取り、(並列で)Runnableを同期的にインプットの数だけまとめて実行して、複数のアウトプットを生成する。 -
stream(): 一つのインプットを受け取り、Runnableを同期的に1回実行しつつ、アウトプットをストリームとして生成する。もう少し正確に言うと、stream()を実行すると、アウトプットの断片(chunk)を順次生成するイテレータを返す。
batch()の実装
batch()は自前のコードを書く必要がなかった。
Runnableクラスに実装されているbatch()のデフォルト実装が、インプットの数だけスレッドを立ち上げてinvoke()を呼ぶというもので、それで十分なので継承したものをそのまま採用。
このbatch()を実行するサンプルコードは以下。
import sys
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from runnables.runnable_k8s import RunnableK8s
prompt = ChatPromptTemplate.from_messages([
(
"system",
"あなたはポケモンのエキスパートです。ユーザの質問に答えてください。",
),
(
"human",
"質問: {input}",
)
])
llm = ChatOpenAI(model="gpt-4o-mini")
chain = prompt | RunnableK8s(bound=llm) | StrOutputParser()
outputs = chain.batch([
{'input': sys.argv[1]},
{'input': sys.argv[2]},
{'input': sys.argv[3]},
])
for o in outputs:
print(o + '\n')
このコードは、コマンドラインから受け取った3つのポケモンに関する質問について、プロンプトを生成し、OpenAIに投げて、回答をテキストに変換して標準出力に吐く、というのをbatch()でまとめて実行する。
OpenAIに投げる部分をRunnableK8sでラップしているので、そこだけKubernetesで実行される。
これを実行した様子は以下。
RunnableK8sが3つのpodを同時に作って、質問を並列で処理できている。
回答は全部間違ってるけど。
stream()の実装
stream()は、Runnableクラスのデフォルト実装が単にinvoke()を呼び出すというもので、ストリーム処理になってないので、自前で実装した。
実装の中身は、冒頭の図のような処理をするinvoke()と大きく変わらないが、podのなかでRunnableのstream()を実行し、そのchunkを順次標準出力に吐き、RunnableK8s側のイテレータで順次返すようにした。
このstream()を実行するサンプルコードは以下。
import sys
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from runnables.runnable_k8s import RunnableK8s
prompt = ChatPromptTemplate.from_messages([
(
"system",
"あなたはポケモンのエキスパートです。ユーザの質問に答えてください。",
),
(
"human",
"質問: {input}",
)
])
llm = ChatOpenAI(model="gpt-4o-mini")
chain = prompt | RunnableK8s(bound=llm) | StrOutputParser()
for output in chain.stream({'input': sys.argv[1]}):
print(f'{output}/', end='', flush=True)
print()
このコードは、コマンドラインから受け取った1つのポケモンに関する質問について、プロンプトを生成し、OpenAIに投げて、回答をテキストに変換して標準出力に吐く、というのをstream()でストリーム実行する。
RunnableK8sでラップしたOpenAIのLLMからは回答がchunkで分割されて順次くるので、それを標準出力に吐くときに、chunkの間に/を挟んで切れ目をわかりやすくしている。
これを実行した様子は以下。

RunnableK8sでストリーム処理できた。
回答もちょっとくどいけど合ってる。