Elasticsearchを使って、青空文庫検索エンジンの作り方を 1 から丁寧に解説してみる では自前でスクリプトを書いて取り込んだけど Logstash で Elasticsearch に取り込んで見ました。
手っ取り早くテストデータが欲しいときの自分用のメモです。
環境構築は 5分でできるElastic stack(Elasticsearch, Logstash, Kibana)環境構築 が楽です。
作業用ディレクトリ
diff --git a/docker-compose.yml b/docker-compose.yml
index ccfe7ae..bf7ef6c 100644
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -40,6 +40,9 @@ services:
source: ./logstash/pipeline
target: /usr/share/logstash/pipeline
read_only: true
+ - type: bind
+ source: ./logstash/work
+ target: /usr/share/logstash/work
logstash設定
logstash/pipeline/logstash_aozora_csv.conf
input {
file {
codec => "json"
path => ["/usr/share/logstash/work/*.csv"]
sincedb_path => "/usr/share/logstash/work/aozora_since"
start_position => "beginning"
}
}
filter {
csv {
skip_header => true
separator => ","
columns => [
"author_id","author","book_id","title","kana_type","translator","inputer","editor","status","date","original_name",
"publisher","input_version","edit_version"
]
}
# 雑ですが登録日が入っていたのでそれをkibanaのtimestampとして使います
date {
match => [ "date", "yyyy-MM-dd" ]
target => "timestamp"
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
user => "elastic"
password => "changeme"
index => "aozora%{+YYYYMMdd}"
}
# 読み込まれない!などはデバッグ出力を見ると良い
# stdout { codec => rubydebug }
}
CSV
作家別作品一覧拡充版:全て(CSV 形式、UTF-8、zip 圧縮) を取得して logstash/work に置く。
Kibana
- id: elastic
- password: changeme
changemeとある通り、このまま本番運用とか絶対ダメですよ。
設定からindex patternを登録しまして。
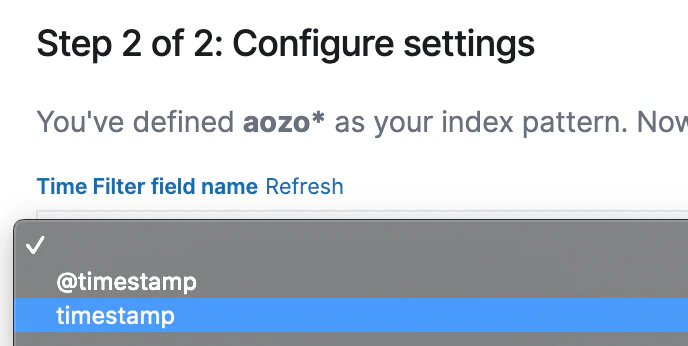
timestampを設定。
@付きの方は登録した日付が入っています。
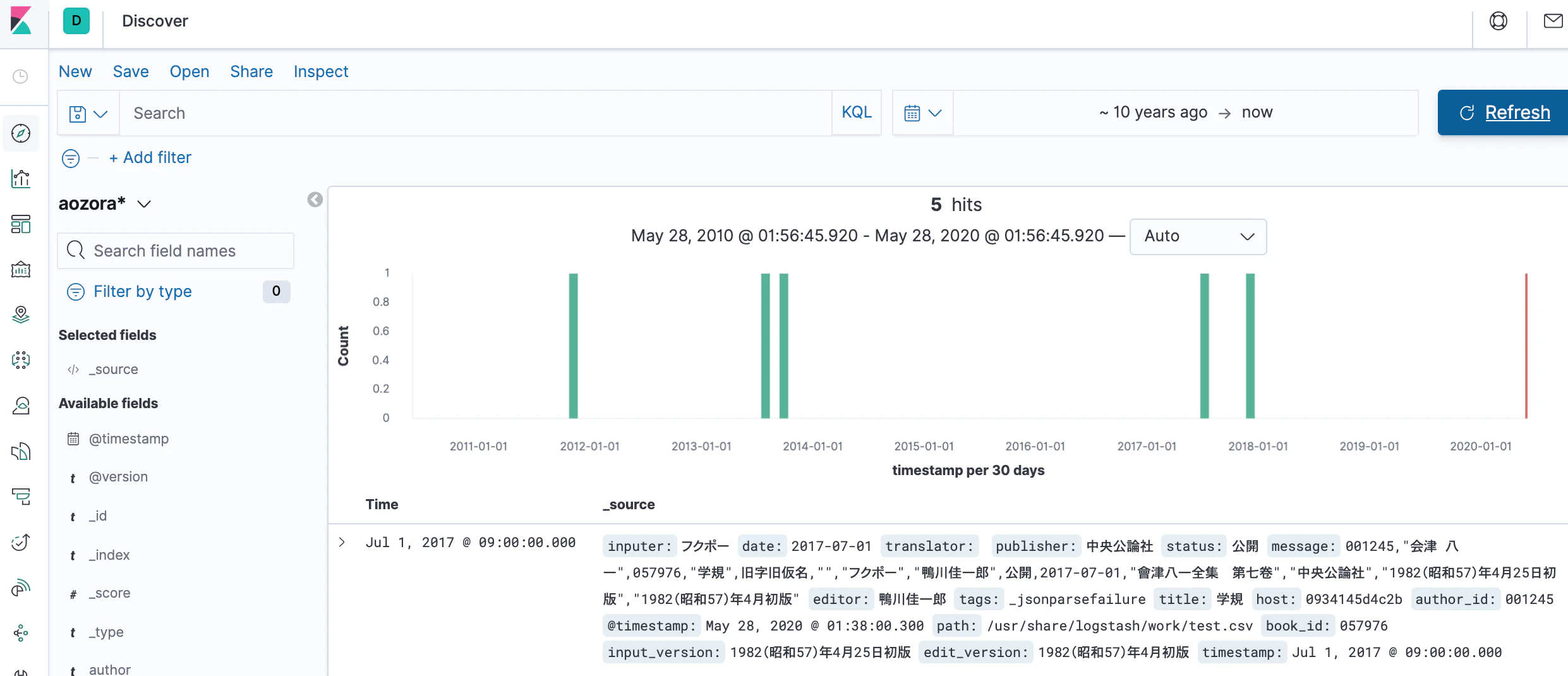
日付の範囲を 10 yeas ago とかにするとデータを確認できます。