AWS DeepRacerで仮想サーキットのランキング上位を目指そうと試行錯誤していますが、なんとか50位圏内に入ることができました。(パチパチ-
AWS DeepRacerの仮想サーキットに参戦できたー
— 甲斐甲🌤️ヴェポライザーとDeepRacer楽しい (@k_aik_ou) May 23, 2019
ここからが本当の戦いだー(白目 pic.twitter.com/YQVPU2ZxyY
AWS DeepRacerで良いモデル作るには報酬設計とハイパーパラメータ設定をそれこそ網羅的に試行錯誤してなんぼって考えてるから、Leagueがあって競い合いつつもノウハウ共有しないと、モデル作成に費やした時間分だけAWSさんが課金で(゚д゚)ウマーするだけから、みんな頑張ろうな!
— 甲斐甲⛅C++とブロックチェーン勉強中 (@k_aik_ou) May 11, 2019
なので、ここまでに得たノウハウを共有してみます。
以下の記事もよろしければご参考ください。
AWS DeepRacerを利用する際に覚えておいたほうがよいこと - Qiita
https://qiita.com/kai_kou/items/5ebf54ef41d38d16f24d
AWS DeepRacerで報酬関数の実装をあれこれ試してみた - Qiita
https://qiita.com/kai_kou/items/8a45c687baca8c9465f6
AWS DeepRacer関連情報まとめ【随時更新】 - Qiita
https://qiita.com/kai_kou/items/5c02d0dca26a33dd8761
強化学習の特性を考えて報酬設計する
報酬関数の実装やハイパーパラメータを適当に触って試行錯誤するにも、暗中模索しないように公式ドキュメントなどからAWS DeepRacerで使われているアルゴリズムの特性を知った上で報酬設計しています。
AWS DeepRacer モデルのトレーニングと評価 - AWS DeepRacer
https://docs.aws.amazon.com/ja_jp/deepracer/latest/developerguide/create-deepracer-project.html
ざくっと抜粋。
- 観察データとアクションを想定される報酬にマッピングする関数
- モデルをトレーニングすることは、想定される報酬を最大化する関数を見つける、または学習すること
- 最適化されたモデルによって車両が最初から最後までトラックで走行するためにどのようなアクション (速度とステアリング角度のペア) を取れるかを規定
- 高速なトレーニングパフォーマンスのための近位ポリシー最適化 (PPO) アルゴリズムのみがサポート
- トレーニング強化学習モデルは反復プロセス
- 一度にある環境でのエージェントのすべての重要な動作をカバーする報酬関数を定義するのは困難
- 賢明な方法は、単純な報酬関数から始めて、段階的に強化していく方法
報酬関数を設計するポイントは下記が参考になります。
和訳:Environment Design Best Practices - Qiita
https://qiita.com/Alt_Shift_N/items/2c37fbb26d739b7f3046
より深くPPOアルゴリズムについて知りたい方は下記が参考になります。
【強化学習】実装しながら学ぶPPO【CartPoleで棒立て:1ファイルで完結】 - Qiita
https://qiita.com/sugulu/items/8925d170f030878d6582
トレーニングの過学習に気をつける
AWS ReepRacer コンソールの報酬グラフでトレーニングし過ぎかどうか確認するのに活用しました。
AWS DeepRacer コンソールの報酬グラフは標準設定だと過去1時間のグラフが表示されますが、CloudWatchとおなじで、グラフの表示期間が変更できます。
右肩上がりのままだからまだトレーニングしてもいいかなとか、
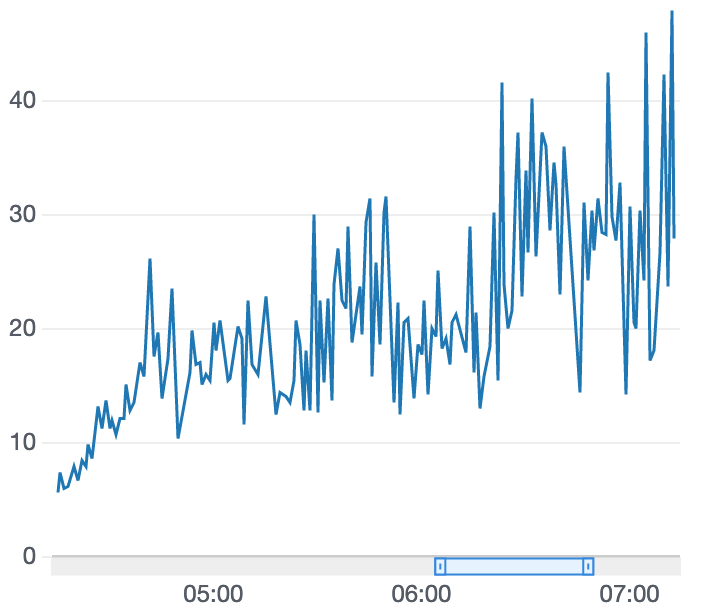
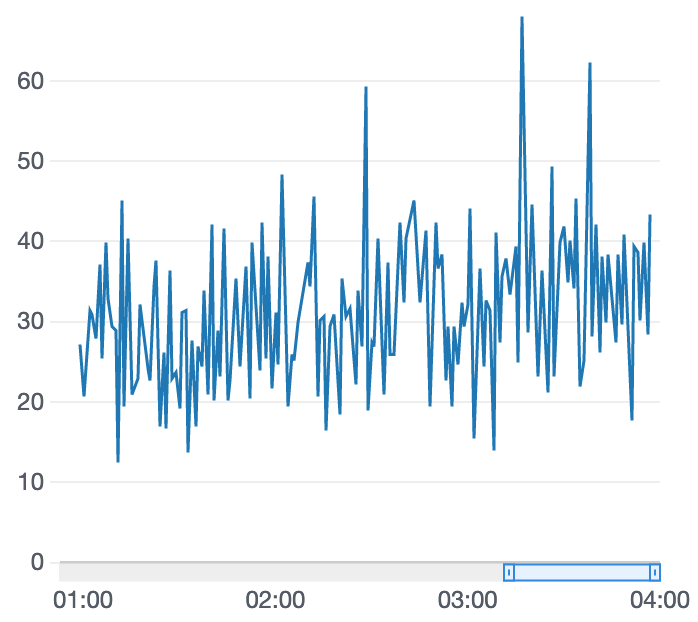
横ばいで微妙だなぁとか
ある時点から下がってきてるぞとか
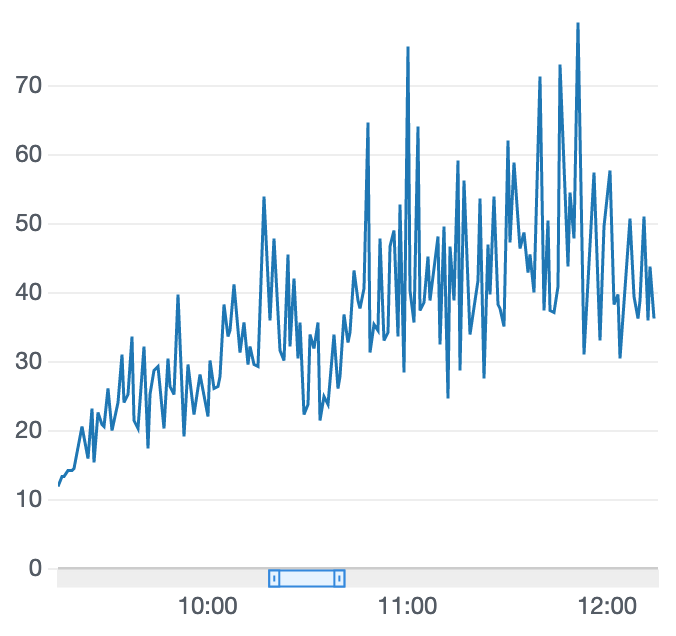
私もよくわかってなくて感覚で申し訳ありませんが、実装した報酬関数のままトレーニング継続するか、実装を見直すかなどの判断に報酬グラフを参考にしています。
モデルのクローンを活用する
公式ドキュメントにあるように、1つの報酬関数で完結するのではなくて、段階的にトレーニングするのがよさそうです。
AWS DeepRacer モデルのトレーニングと評価 - AWS DeepRacer
https://docs.aws.amazon.com/ja_jp/deepracer/latest/developerguide/create-deepracer-project.html
- 一度にある環境でのエージェントのすべての重要な動作をカバーする報酬関数を定義するのは困難
- 賢明な方法は、単純な報酬関数から始めて、段階的に強化していく方法
クローン時に報酬関数をそのままでトレーニングを継続するのか実装を変更するのかを選択できます。
アクションは変更できないので気をつけましょう。
アクション設定でスピードを最速にする
仮想サーキットのランキングで上位を狙うならば、スピードはMAXのみで良いです。
実機の場合にどうなるかは試したことがないので不明です。
ハイパーパラメータは変更しなくても50位圏内に入れる
いまのところのハイパーパラメータは初期設定のままでなんとかなっています。
おそらく報酬関数の実装とトレーニングでタイムに限界が来たら学習率を高めるのに手を入れる感じでしょうか?
ガチ勢にコツを伺いたいところです。
PPO で学習させる際のベストプラクティス - Qiita
https://qiita.com/dora-gt/items/18440bea7aa0fc8aa17f
100%完走できるモデルにこだわらない
トレーニング完了後の試走で5周すればすべて完走できるモデルにしなくても(いまのところは)良いと思います。
LondonLoopだと2周連続で完走すればラップタイムが記録されるルールになっています。
なので、5周のうち2,3回完走できるようになったら仮想サーキットに挑むのもありです。
3周完走できたモデルをSubmitしたらうまい具合に2周連続で完走してくれてラップタイム記録されました。
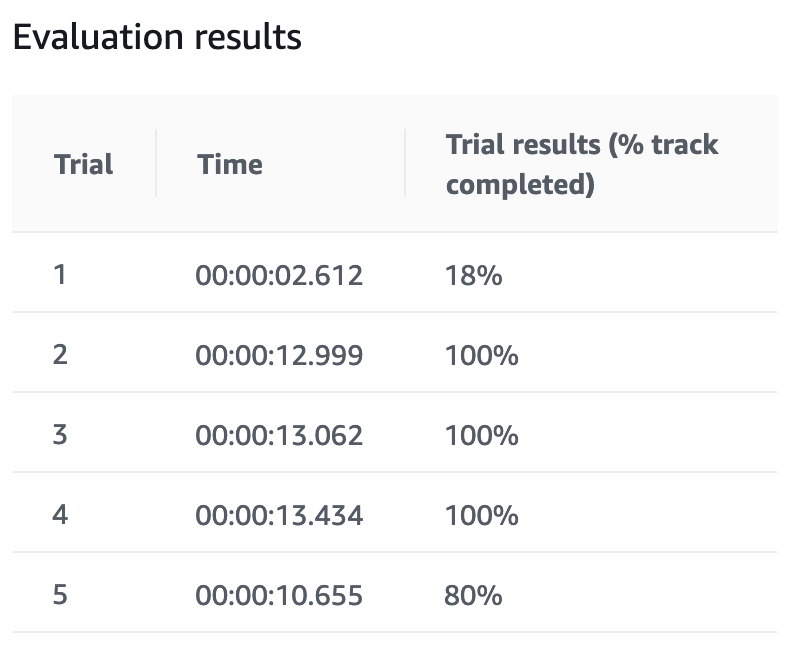
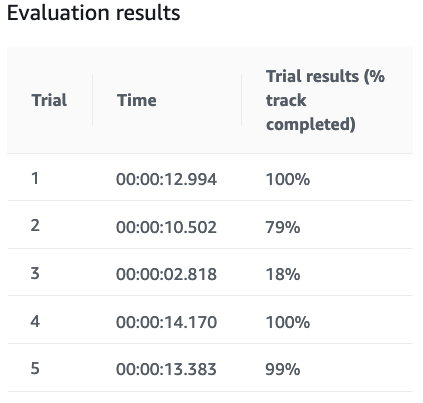
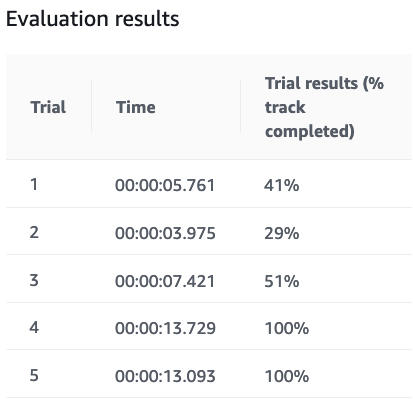
試走結果は変動する
トレーニング後に試走ができますが、必ずしも同じような完走率、タイムにはなりません。
際どい結果になった場合は試走しなおして確認するのもありです。
同じモデルで2回試走した結果。ブレます。
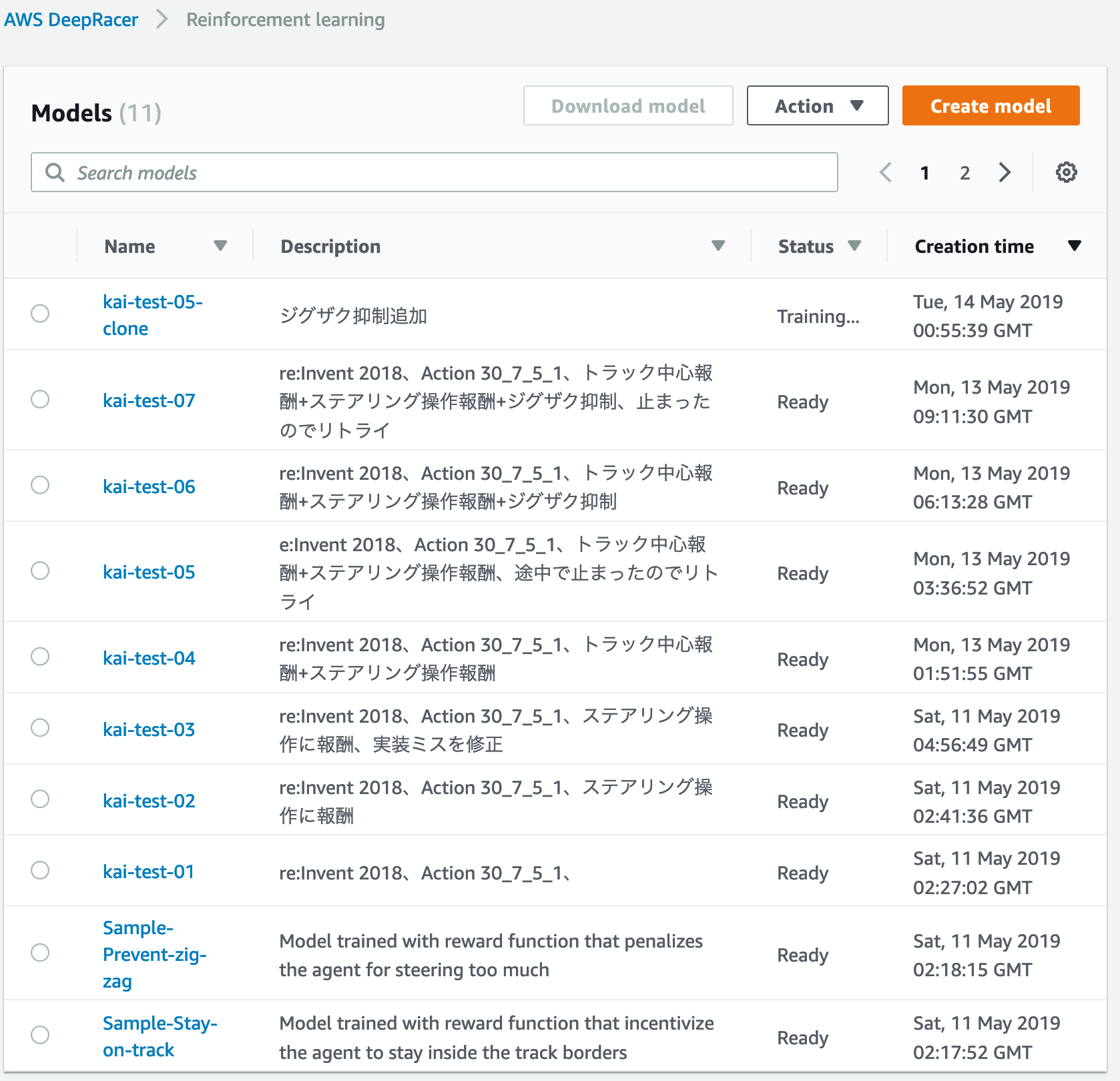
モデル作成時に詳細項目を活用する
トレーニングを繰り返しているとどのモデルが何だったか忘れます。
詳細からアクション設定や報酬関数の実装は確認できますが、クローンしてトレーニングする場合、経緯を詳細にメモっておくと役に立ちます。
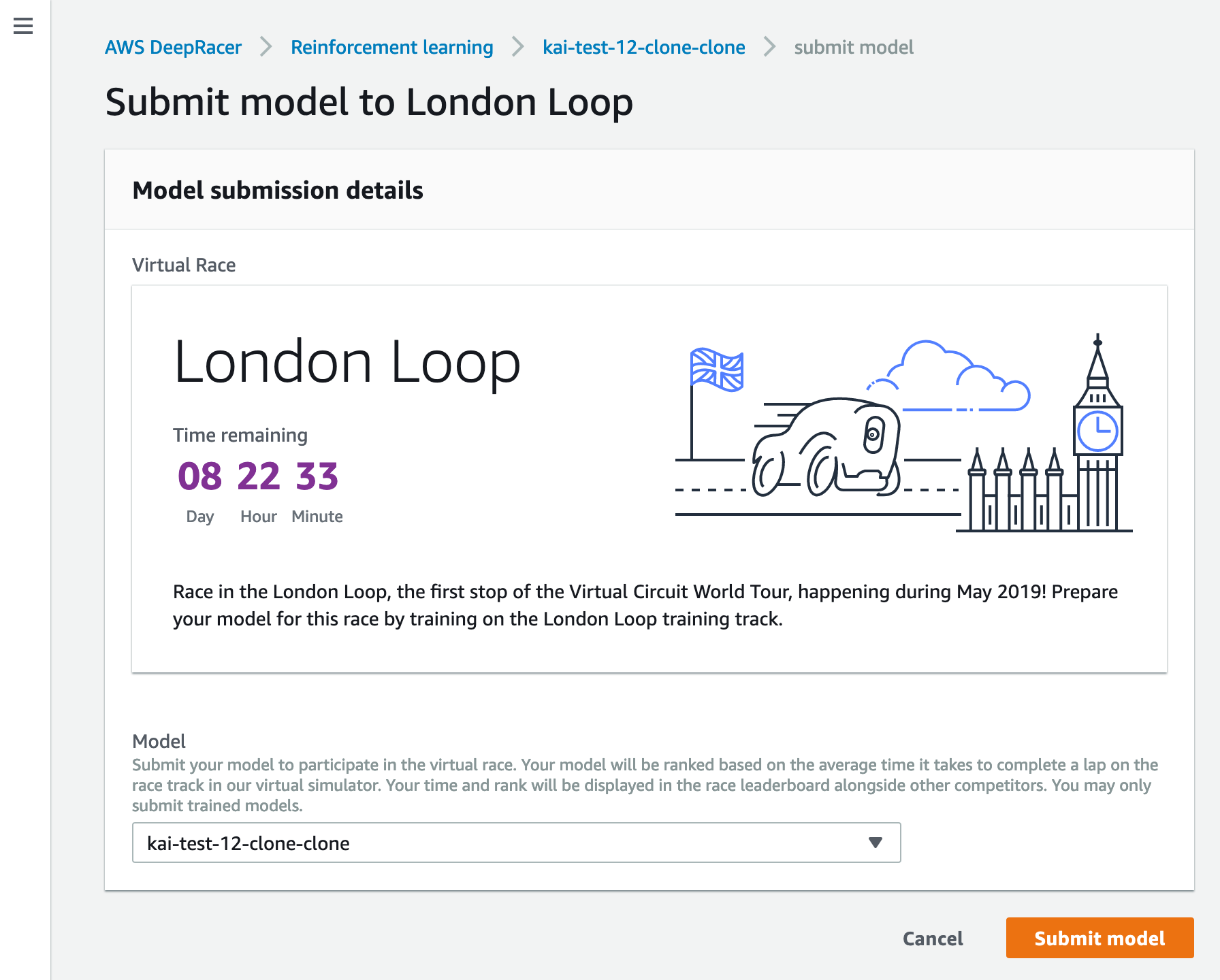
仮想サーキットのレーサー名は変更できない
仮想サーキットへモデルをSubmitする際に初回のみレーサー名の入力ができます。
初回以降は変更不可で開催される全レースで共通のレーサー名になるので気をつけましょう。
1度仮想サーキットにSubmitしたモデルは再Submitできない
5周のうち2,3回完走できるモデルを仮想サーキットにSubmitした場合、運次第で完走するしないが起こりえます。
なので、ラップタイムが記録される条件になるまで同じモデルをSubmitしたいところですが、できないみたいです。
(未確認ですが、)再度Submitしたモデルをクローンして5分くらいトレーニングすれば別モデルとみなされるかもしれません。
やっぱりコストが高い
仮想サーキットのLondonLoopで50位圏内に入るまでに費やしたコストはこちら。
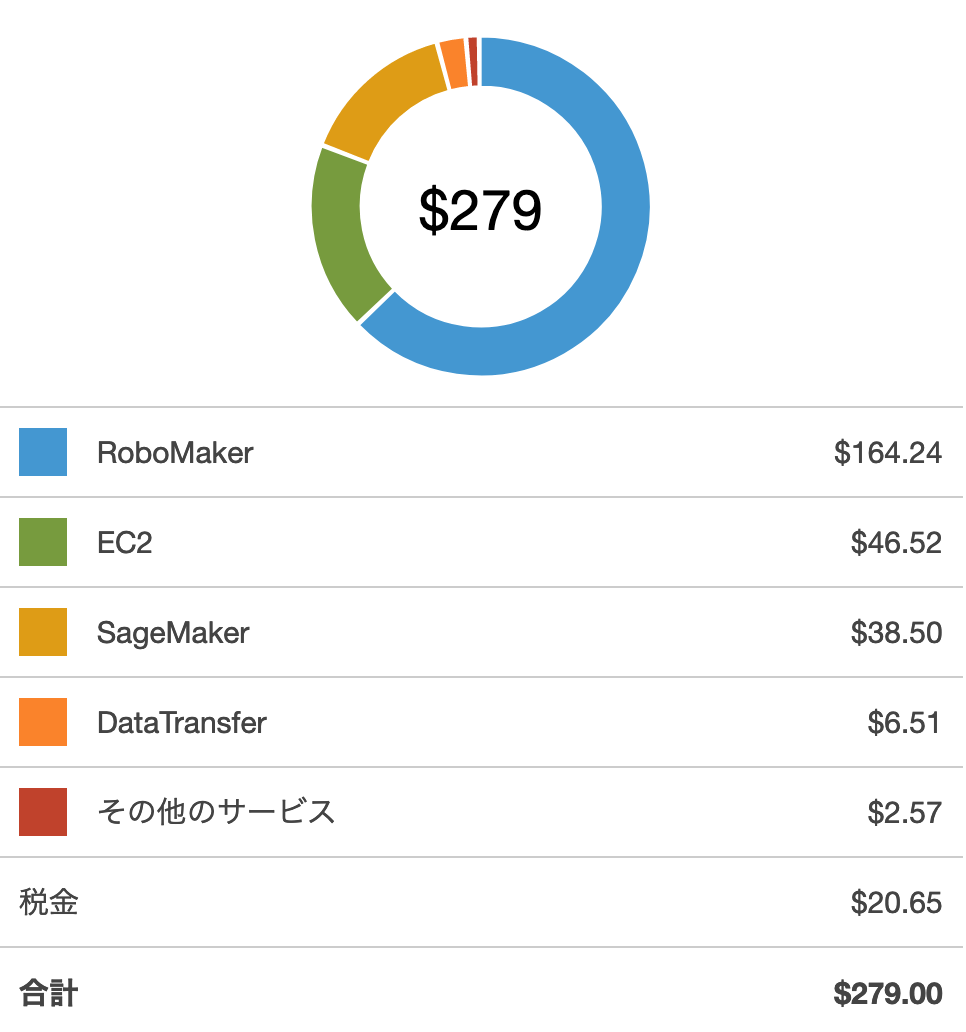
いやーきついっす。
最後に
AWS DeepRacerのLondonLoopで12〜13秒台3/5で完走できるようになったけどそこからのトレーニングがむずい。多分ここが本当のスタートラインっぽい。
— 甲斐甲☀ヴェポライザーとDeepRacer楽しい (@k_aik_ou) May 22, 2019
これは課金がとまらなさそうだ… pic.twitter.com/4r5dXpefkN
みんなで(出せるところまでは)ノウハウを共有して、ランキング上位目指しましょう!!!
参考
AWS DeepRacerを利用する際に覚えておいたほうがよいこと - Qiita
https://qiita.com/kai_kou/items/5ebf54ef41d38d16f24d
AWS DeepRacerで報酬関数の実装をあれこれ試してみた - Qiita
https://qiita.com/kai_kou/items/8a45c687baca8c9465f6
AWS DeepRacer関連情報まとめ【随時更新】 - Qiita
https://qiita.com/kai_kou/items/5c02d0dca26a33dd8761
AWS DeepRacer モデルのトレーニングと評価 - AWS DeepRacer
https://docs.aws.amazon.com/ja_jp/deepracer/latest/developerguide/create-deepracer-project.html
和訳:Environment Design Best Practices - Qiita
https://qiita.com/Alt_Shift_N/items/2c37fbb26d739b7f3046
【強化学習】実装しながら学ぶPPO【CartPoleで棒立て:1ファイルで完結】 - Qiita
https://qiita.com/sugulu/items/8925d170f030878d6582
PPO で学習させる際のベストプラクティス - Qiita
https://qiita.com/dora-gt/items/18440bea7aa0fc8aa17f