AWS DeepRacerで良いモデル作るには報酬設計とハイパーパラメータ設定をそれこそ網羅的に試行錯誤してなんぼって考えてるから、Leagueがあって競い合いつつもノウハウ共有しないと、モデル作成に費やした時間分だけAWSさんが課金で(゚д゚)ウマーするだけから、みんな頑張ろうな!
— 甲斐甲⛅C++とブロックチェーン勉強中 (@k_aik_ou) May 11, 2019
ということで、AWS DeepRacerコンソールを利用してモデル作成した際の報酬関数の実装とトレーニング結果(報酬グラフと評価結果)を共有してみます。ついでにトレーニング中の動画も^^
AWS DeepRacerのトレーニング中にAWS RoboMakerで捉えた様子。強化学習なのでうまくいかないことが多いからなんだか親の気持ちになって眺めていられる。 pic.twitter.com/dHQy4bDrvn
— 甲斐甲⛅C++とブロックチェーン勉強中 (@k_aik_ou) May 14, 2019
前提
コースやアクション、ハイパーパラメータは固定
各パラメータはひとまず固定で、報酬実装をどうするか検証しました。
スピードも固定にしているので、リーグ参加時前にスピードに関する報酬実装をモデルに追加する必要があるかもしれません。(未確認)
- コース: re:Invent 2018
- アクション
- Maximum steering angle: 30 degrees
- Steering angle granularity: 7
- Maximum speed: 5 m/s
- Speed granularity: 1
- ハイパーパラメータ: 初期設定のまま
- 学習時間: 3時間

報酬実装
パラメータ取得やall_wheels_on_track による報酬設定は共通にしています。
車両がトラック中心に近いほど多くの報酬を返す
公式ドキュメントにある実装例を参考に報酬設定のしきい値と報酬値を少々いじってお試ししました。
Train and Evaluate AWS DeepRacer Models Using the AWS DeepRacer Console - AWS DeepRacer
https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-console-train-evaluate-models.html
reward_function 実装
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# 車両がトラックの中心に近いほど多くの報酬を返す
distance_from_center_reward = 0
marker_1 = 0.1 * track_width
marker_2 = 0.2 * track_width
marker_3 = 0.3 * track_width
if distance_from_center >= 0.0 and distance_from_center <= marker_1:
distance_from_center_reward = 1
elif distance_from_center <= marker_2:
distance_from_center_reward = 0.8
elif distance_from_center <= marker_3:
distance_from_center_reward = 0.6
else:
return 1e-3
print("distance_from_center_reward: %.2f" % distance_from_center_reward)
reward = distance_from_center_reward
print("total reward: %.2f" % reward)
return float(reward)
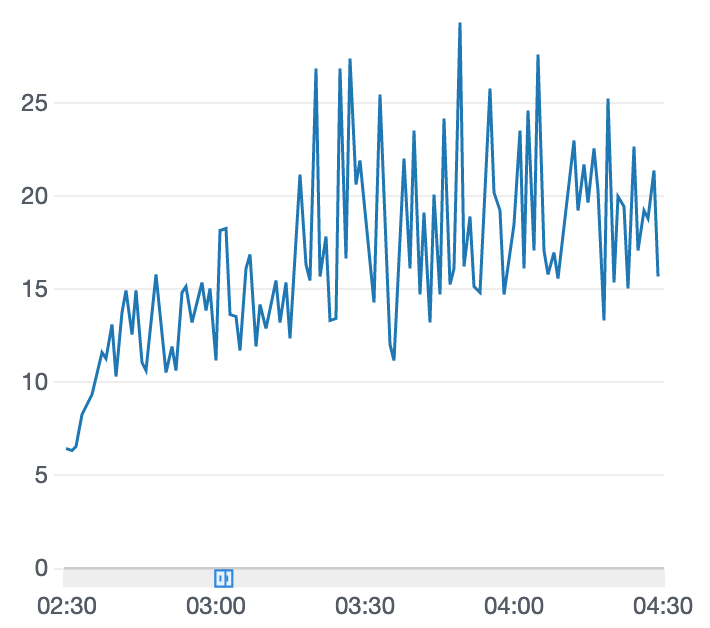
学習結果
※これだけ学習時間が2時間となっています。
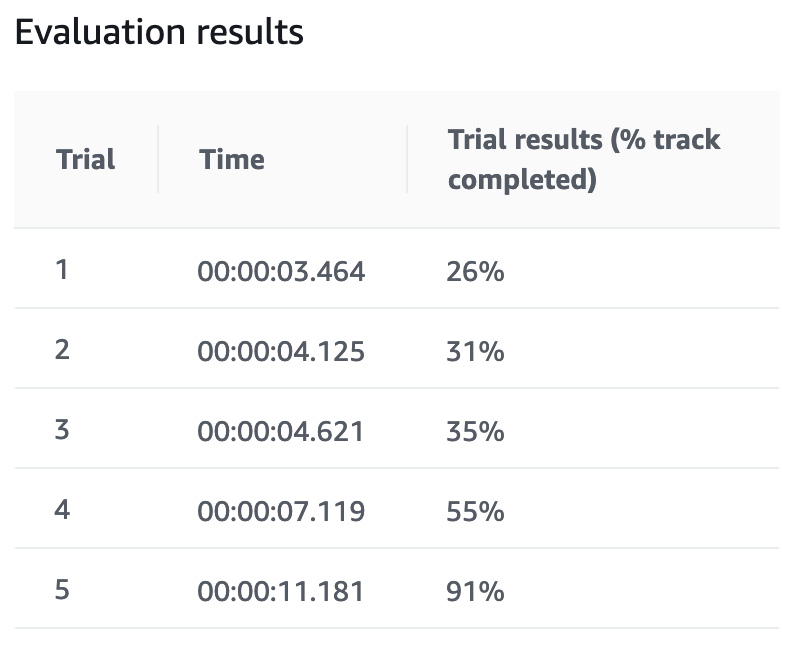
1時間を過ぎたあたりから得られる報酬が低下してきているが気になります。このまま学習を続けても変わりなしになりそうです。完走率も1回だけ91%となりました。
ステアリング操作を報酬に反映させる
is_left_of_center でトラック中心から左右どちらにいるかわかるみたいだったので利用してみました。トラックの左側にいるのにハンドルを左に切ったらコースアウトする可能性があるので、ペナルティ!みたいな感じ。
reward_function 実装
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# ステアリング操作を報酬に反映させる
# is_left_of_centerでトラック中心から左右どちらにいるかわかる
# steering_angleが正だと左、負だと右
steering_reward = 1e-3
if distance_from_center > 0:
if is_left_of_center and steering_angle <= 0:
steering_reward = 1.0
elif (not is_left_of_center) and steering_angle >= 0:
steering_reward = 1.0
else:
if steering_angle == 0:
steering_reward = 1.0
print("steering_reward: %.2f" % steering_reward)
reward += steering_reward
print("total reward: %.2f" % reward)
return float(reward)
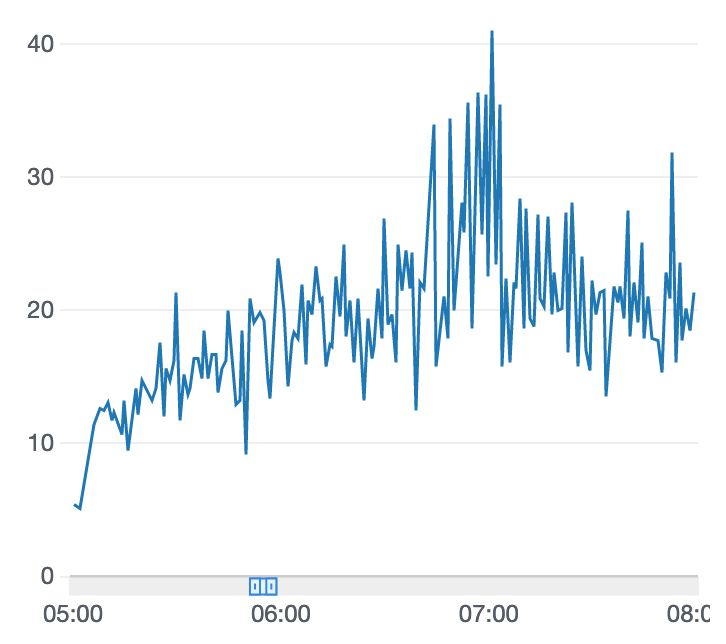
学習結果
こちらも2時間経過したところがピークで得られる報酬が下がっています。単純な報酬設定だと時間をかけてもうまく学習が進まないのかもしれません。完走率は平均すると車両がトラック中心のよりも低めでした。
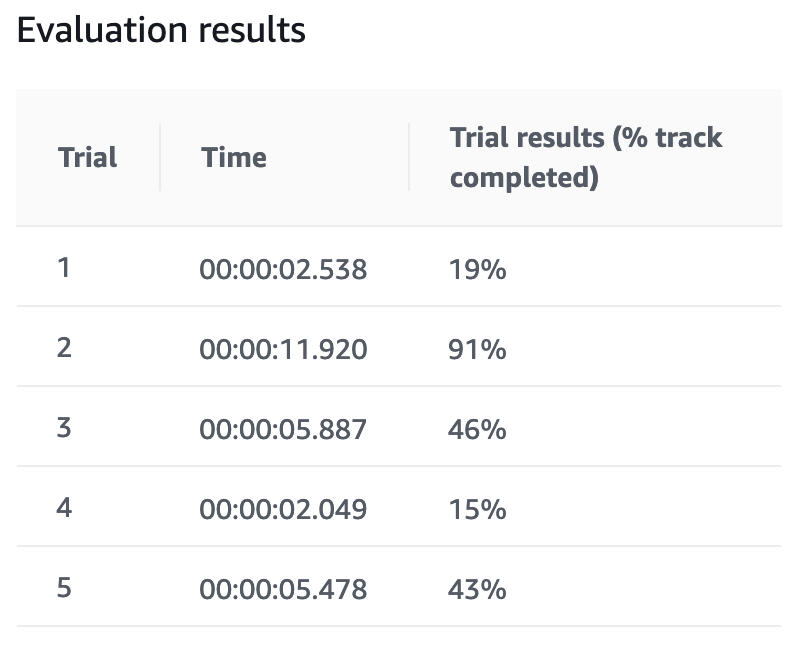
車両がトラック中心 + ステアリング操作
単純な報酬設定だと学習に限度がありそうで完走率が上がらなさそうだったので組合せてみました。
単純に車両がトラック中心とステアリング操作の報酬設定を加算しています。
reward_function 実装
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# 車両がトラックの中心に近いほど多くの報酬を返す
distance_from_center_reward = 0
marker_1 = 0.1 * track_width
marker_2 = 0.2 * track_width
marker_3 = 0.3 * track_width
if distance_from_center >= 0.0 and distance_from_center <= marker_1:
distance_from_center_reward = 1
elif distance_from_center <= marker_2:
distance_from_center_reward = 0.8
elif distance_from_center <= marker_3:
distance_from_center_reward = 0.6
else:
print("over_center")
distance_from_center_reward = 1e-3
print("distance_from_center_reward: %.2f" % distance_from_center_reward)
reward = distance_from_center_reward
# ステアリングを報酬に反映させる
# 左が正、右が負
steering_reward = 1e-3
if distance_from_center > 0:
if is_left_of_center and steering_angle <= 0:
steering_reward = 1.0
elif (not is_left_of_center) and steering_angle >= 0:
steering_reward = 1.0
else:
if steering_angle == 0:
steering_reward = 1.0
print("steering_reward: %.2f" % steering_reward)
reward += steering_reward
print("total reward: %.2f" % reward)
return float(reward)
学習結果
報酬グラフが右肩上がりを維持しています。そして、ようやく完走できるケースがでてきました。
これなら学習時間をもっと増やしてみる価値がありそうです。
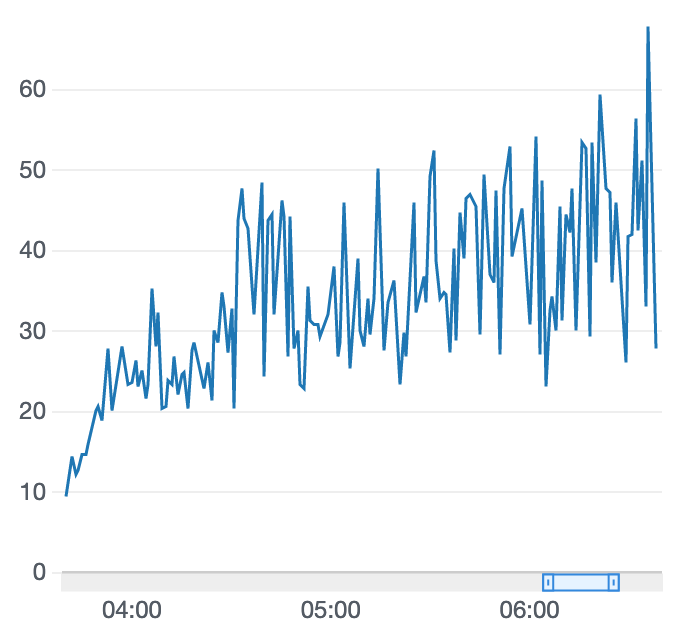
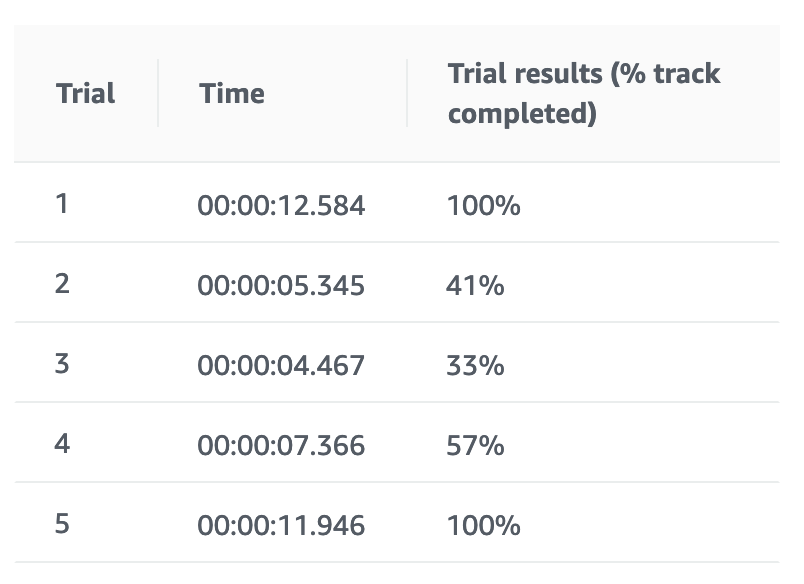
(車両がトラック中心 + ステアリング操作) x ジグザク抑制
車両がトラック中心 + ステアリング操作で完走できるケースが増えてきたので、さらに急ハンドルやジグザク走行を抑制する設定を追加してみました。ジグザク抑制は車両がトラック中心 + ステアリング操作で設定した報酬に乗じてみました。
急ハンドルやジグザク走行を抑制する実装は下記記事を参考にさせてもらいました。(感謝
AWS DeepRacerを強化する 報酬関数実装パターンあれこれ | DevelopersIO
https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of-reward-function/
reward_function 実装
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# 車両がトラックの中心に近いほど多くの報酬を返す
distance_from_center_reward = 0
marker_1 = 0.1 * track_width
marker_2 = 0.2 * track_width
marker_3 = 0.3 * track_width
if distance_from_center >= 0.0 and distance_from_center <= marker_1:
distance_from_center_reward = 1
elif distance_from_center <= marker_2:
distance_from_center_reward = 0.8
elif distance_from_center <= marker_3:
distance_from_center_reward = 0.6
else:
print("over_center")
distance_from_center_reward = 1e-3
print("distance_from_center_reward: %.2f" % distance_from_center_reward)
reward = distance_from_center_reward
# ステアリングを報酬に反映させる
# 左が正、右が負
steering_reward = 1e-3
if distance_from_center > 0:
if is_left_of_center and steering_angle <= 0:
steering_reward = 1.0
elif (not is_left_of_center) and steering_angle >= 0:
steering_reward = 1.0
else:
if steering_angle == 0:
steering_reward = 1.0
print("steering_reward: %.2f" % steering_reward)
reward += steering_reward
# ジグザク抑制
# 参考) https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of-reward-function/
# ハンドルの操作角(-30°〜30°)をparamsから取得
# 操作角の絶対値を計算(右旋回、左旋回問わず角度の大きさで判断する
steering2_reward = 1.0
# 急ハンドルを判定する為の閾値を定義して、それ以上の操作角だった場合にペナルティを与える
# 閾値は行動パターンの設定によって変動する
STEERING_THRESHOLD = 20.0
if steering_angle > STEERING_THRESHOLD:
steering2_reward = 0.8
print("steering2_reward: %.2f" % steering2_reward)
reward *= steering2_reward
print("total reward: %.2f" % reward)
return float(reward)
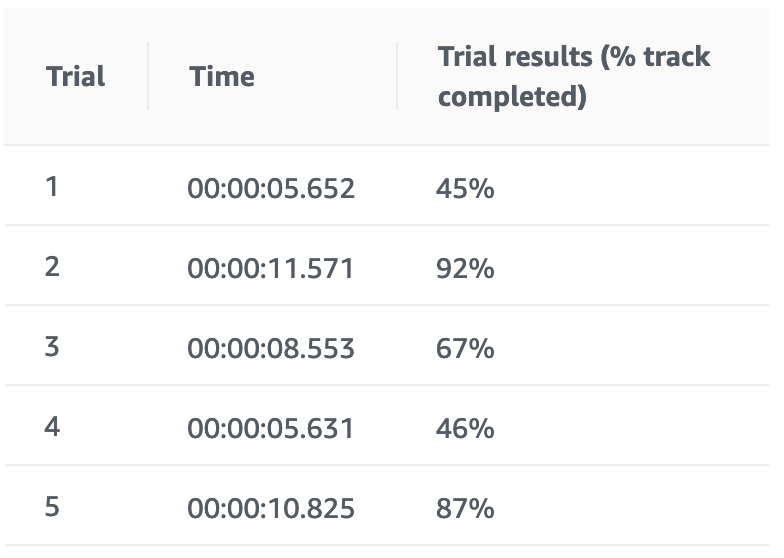
学習結果
報酬グラフは2時間過ぎてからピークアウトしてしまいました。完走率も悪化。。。ぐぬぬ。
シミュレーション状況をみるかぎりジグザク抑制の効果は微妙な感じでした。
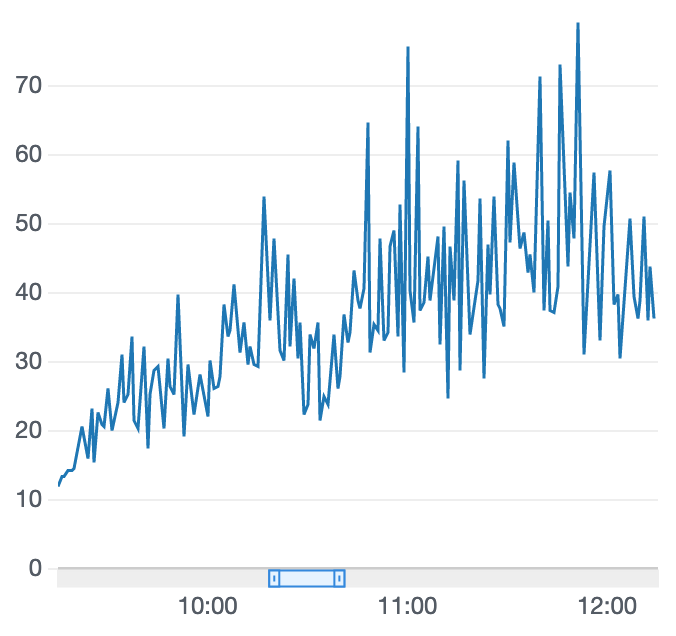
車両がトラック中心 + ステアリング操作にジグザク抑制を追いトレーニング
車両がトラック中心 + ステアリング操作でトレーニングにしたモデルをクローンしてジグザク抑制のトレーニングをしてみました。
reward_function 実装
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# ジグザク抑制
# 参考) https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of-reward-function/
# ハンドルの操作角(-30°〜30°)をparamsから取得
# 操作角の絶対値を計算(右旋回、左旋回問わず角度の大きさで判断する
steering2_reward = 1.0
# 急ハンドルを判定する為の閾値を定義して、それ以上の操作角だった場合にペナルティを与える
# 閾値は行動パターンの設定によって変動する
STEERING_THRESHOLD = 20.0
if steering_angle > STEERING_THRESHOLD:
steering2_reward = 1e-3
print("steering2_reward: %.2f" % steering2_reward)
reward += steering2_reward
print("total reward: %.2f" % reward)
return float(reward)
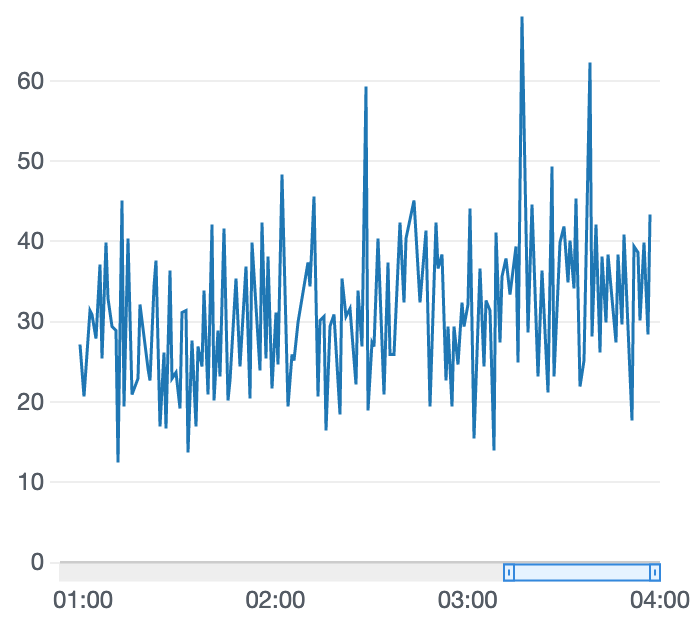
学習結果
追いトレーニングしてみましたが、報酬グラフはあまりぱっとせず。ステアリング角度によって得られる報酬を調整するのが良いのかもしれません。
途中経過を動画にしてみました。
AWS DeepRacerのトレーニング中にAWS RoboMakerで捉えた様子。強化学習なのでうまくいかないことが多いからなんだか親の気持ちになって眺めていられる。 pic.twitter.com/dHQy4bDrvn
— 甲斐甲⛅C++とブロックチェーン勉強中 (@k_aik_ou) May 14, 2019
waypoint を利用した報酬設定
こちらも下記記事にある「パターン4:コース上に設定されたポイントに向かって走るように制御する」のアイデアと実装をお試ししてみました。
AWS DeepRacerを強化する 報酬関数実装パターンあれこれ | DevelopersIO
https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of-reward-function/
reward_function 実装
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
import math
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# waypointに向かってすすめ
# 参考) https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of-reward-function/
# 規定の報酬を設定する
waypoints_reward = 1.0
# 現在の位置から最も近い次のwaypointと前のwaypointを取得する
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[0]]
# 前のwaypointから次のwaypointに向かう角度(radian)を計算する
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0])
# degreeに変換
track_direction = math.degrees(track_direction)
print("track_direction: %.2f" % track_direction)
# コース上の基準軸に対する車体の向きと直近のwaypointを繋ぐ向きの差分を取る
direction_diff = abs(track_direction - heading)
print("direction_diff: %.2f" % direction_diff)
# 算出した方向の差分から車体の向きが大きくズレている場合にペナルティを与える
# 閾値の設定はコースの種類によって調整が必要
DIRECTION_THRESHOLD = 10.0
if direction_diff > DIRECTION_THRESHOLD:
waypoints_reward = 0.5
print("waypoints_reward: %.2f" % waypoints_reward)
reward = waypoints_reward
return float(reward)
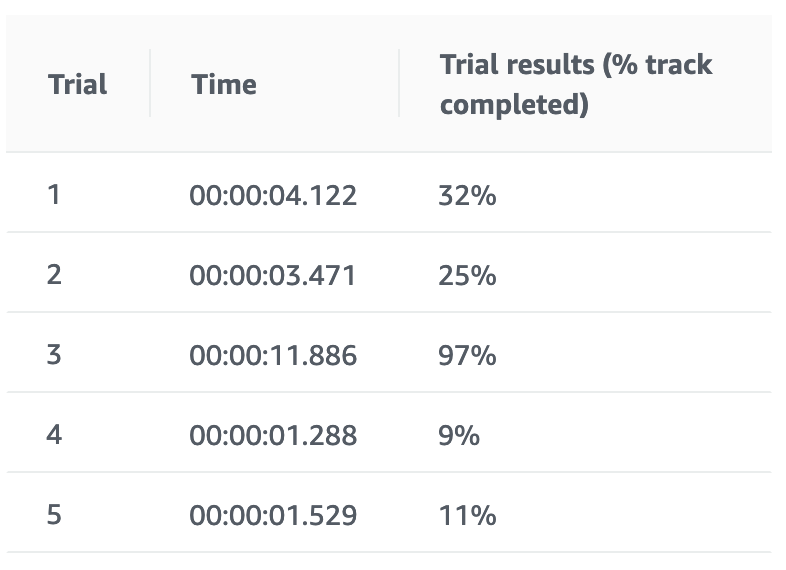
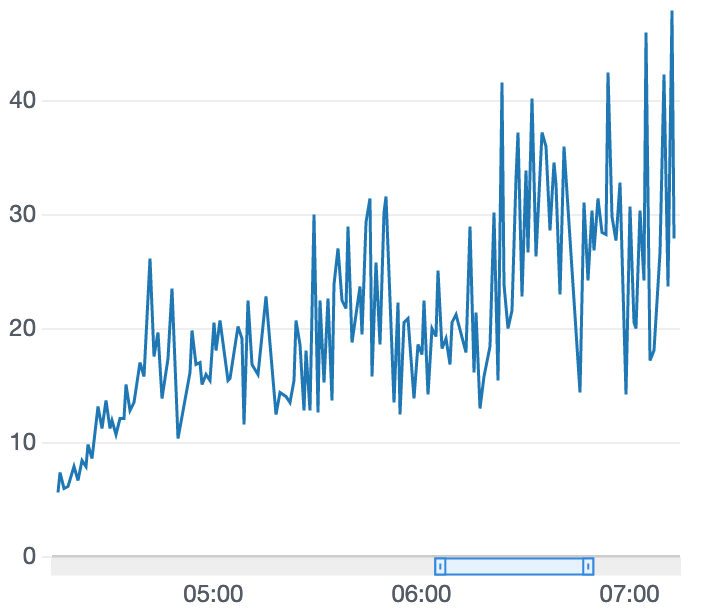
学習結果
報酬グラフが右肩上がりしているので、時間を増やせばさらに良くなるかも?という感じです。
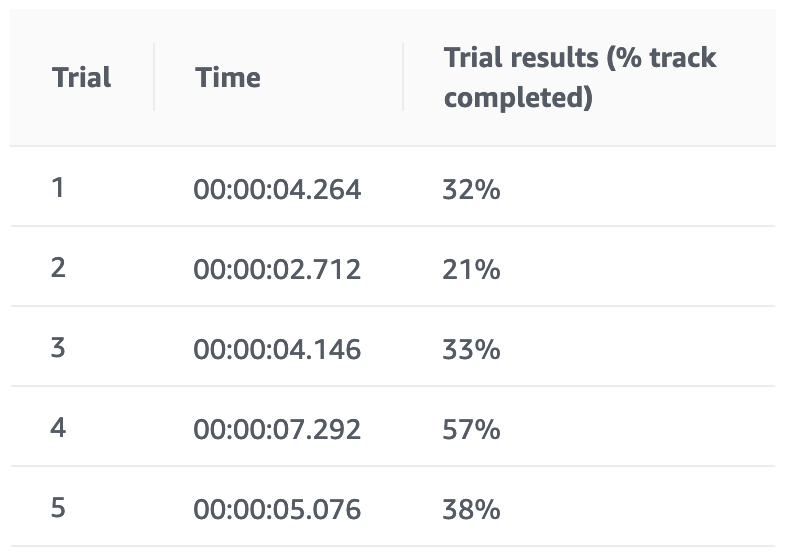
「車両がトラック中心に近いほど多くの報酬を返す」に追いトレーニング
reward_function に実装を足さずに追いトレーニングを重ねてみました。
1つめ「ステアリング操作を報酬に反映させる」
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# ステアリングを報酬に反映させる
# 左が正、右が負なので、間違い
steering_reward = 1e-3
if distance_from_center > 0:
if is_left_of_center and steering_angle >= 0:
steering_reward = 1.0
elif (not is_left_of_center) and steering_angle <= 0:
steering_reward = 1.0
else:
if steering_angle == 0:
steering_reward = 1.0
print("steering_reward: %.2f" % steering_reward)
reward += steering_reward
print("total reward: %.2f" % reward)
return float(reward)
学習結果
追いトレーニング前
追いトレーニング後
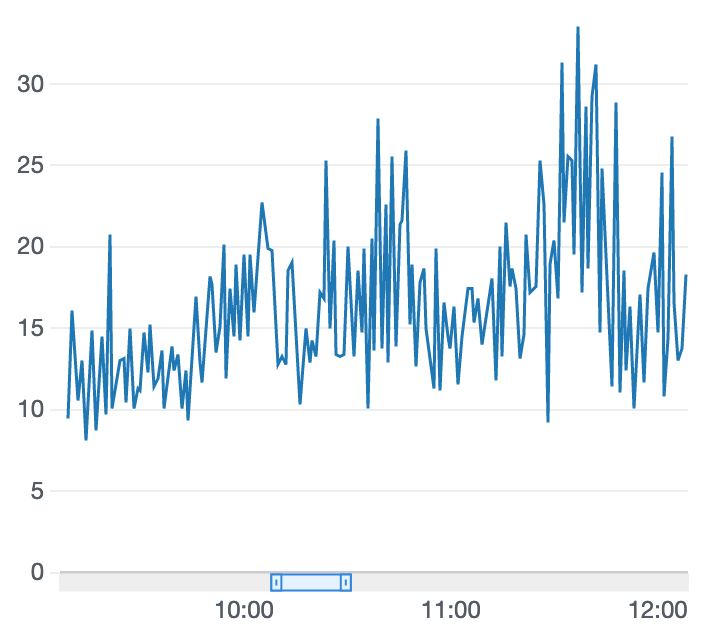
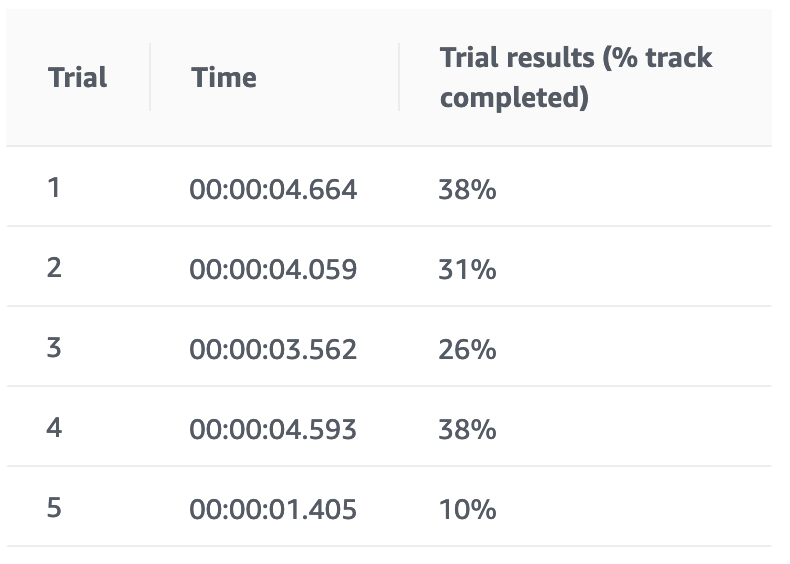
なんだか悪化したみたいです。検証のためさらに追いトレーニングしてみます。
2つめ「ジグザク抑制」
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# ジグザク抑制
# 参考) https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of-reward-function/
# ハンドルの操作角(-30°〜30°)をparamsから取得
# 操作角の絶対値を計算(右旋回、左旋回問わず角度の大きさで判断する
steering2_reward = 1.0
# 急ハンドルを判定する為の閾値を定義して、それ以上の操作角だった場合にペナルティを与える
# 閾値は行動パターンの設定によって変動する
STEERING_THRESHOLD = 20.0
if steering_angle > STEERING_THRESHOLD:
steering2_reward = 1e-3
print("steering2_reward: %.2f" % steering2_reward)
reward += steering2_reward
print("total reward: %.2f" % reward)
return float(reward)
学習結果
追いトレーニング前
追いトレーニング後
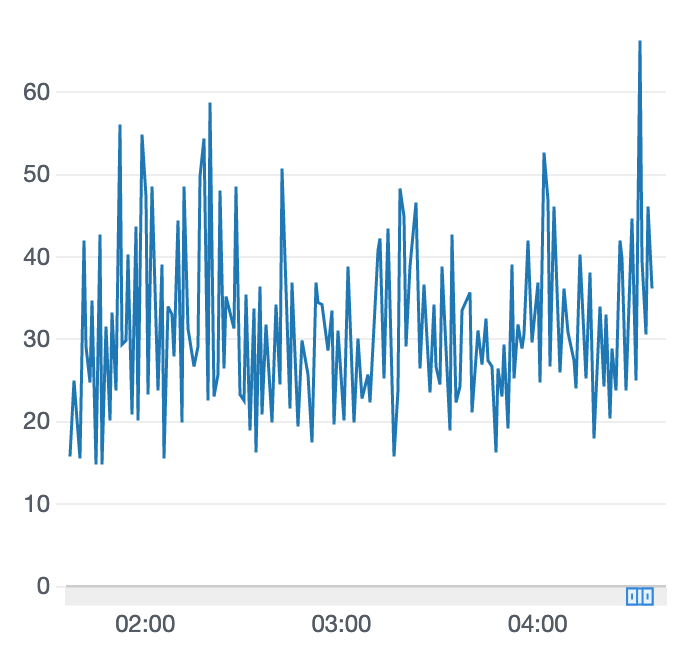
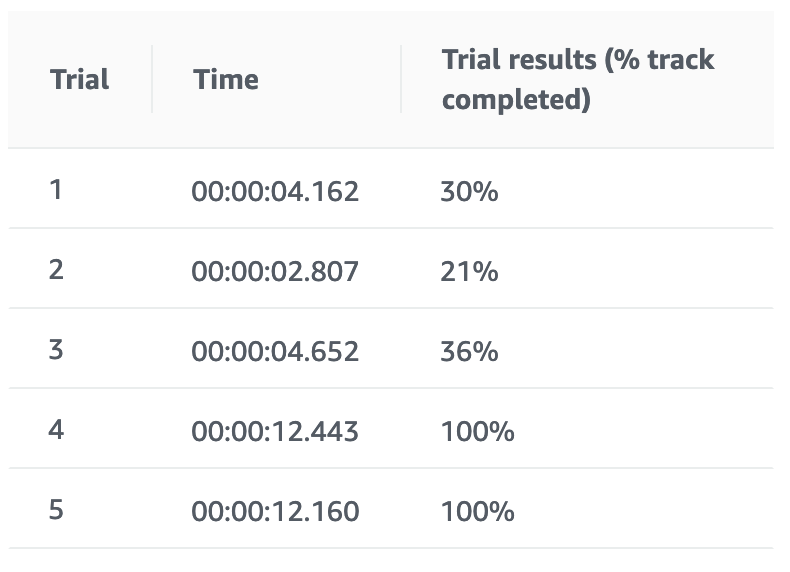
報酬グラフみただけだとどうだろなぁーって思ってたら、完走2/5となりました。
いけそう?いけそう?
3つめ「waypoint を利用した報酬設定」
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
import math
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not all_wheels_on_track:
print("off_track")
return 1e-3
# waypointに向かってすすめ
# 参考) https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of-reward-function/
# 規定の報酬を設定する
waypoints_reward = 1.0
# 現在の位置から最も近い次のwaypointと前のwaypointを取得する
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[0]]
# 前のwaypointから次のwaypointに向かう角度(radian)を計算する
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0])
# degreeに変換
track_direction = math.degrees(track_direction)
print("track_direction: %.2f" % track_direction)
# コース上の基準軸に対する車体の向きと直近のwaypointを繋ぐ向きの差分を取る
direction_diff = abs(track_direction - heading)
print("direction_diff: %.2f" % direction_diff)
# 算出した方向の差分から車体の向きが大きくズレている場合にペナルティを与える
# 閾値の設定はコースの種類によって調整が必要
DIRECTION_THRESHOLD = 10.0
if direction_diff > DIRECTION_THRESHOLD:
waypoints_reward = 0.5
print("waypoints_reward: %.2f" % waypoints_reward)
reward = waypoints_reward
return float(reward)
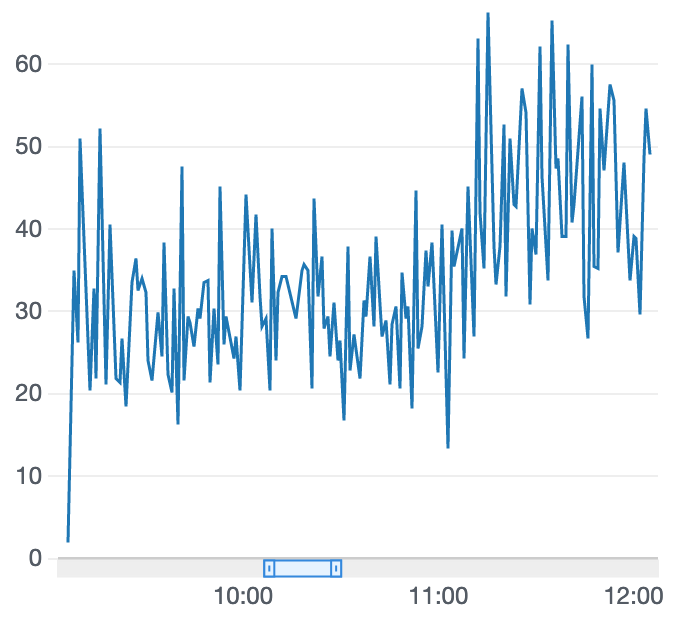
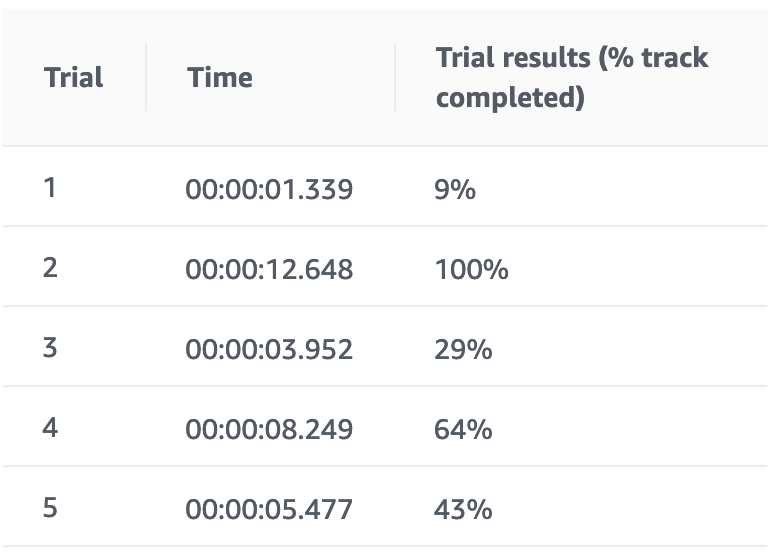
学習結果
良くなったようなそうでないような。。。
ひとまずモデルをクローンして追加でトレーニングして変化があることが確認できました。
追いトレーニング前
追いトレーニング後
試行錯誤の果て
上記報酬関数の実装を組合せたり報酬値やしきい値の調整、追加トレーニングをしてみたらLondonLoopでいい感じのタイムがでるようになってきました。
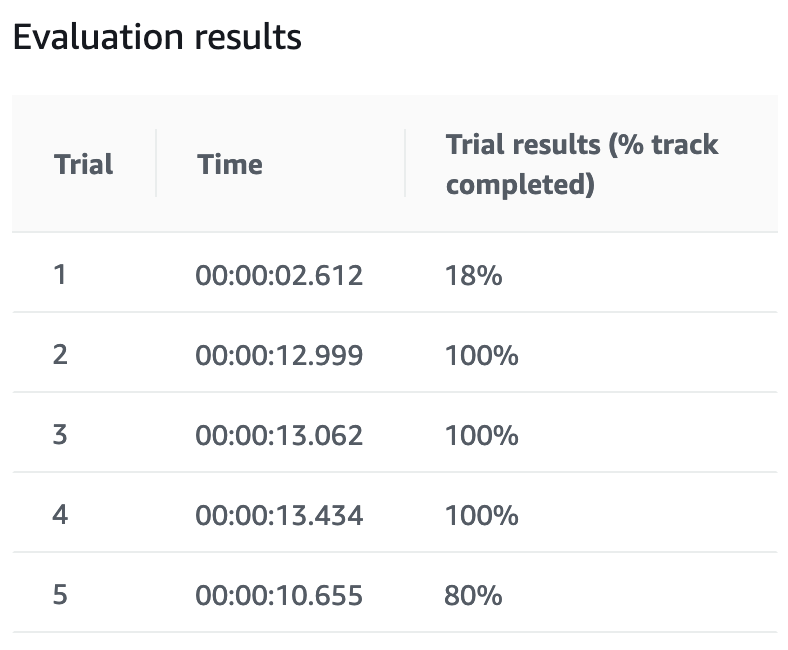
現在開催されている仮想サーキットのランキングをみると12.999だと40位〜50位くらい。。。(2019/05/22時点)
さらにモデルのトレーニングを重ねていますが、過学習で完走率が低下したりタイムが遅くなったり。。。
AWS DeepRacerのLondonLoopで12〜13秒台3/5で完走できるようになったけどそこからのトレーニングがむずい。多分ここが本当のスタートラインっぽい。
— 甲斐甲☀ヴェポライザーとDeepRacer楽しい (@k_aik_ou) May 22, 2019
これは課金がとまらなさそうだ… pic.twitter.com/4r5dXpefkN
本当の戦いはこれからだ なのかこれからがほんとうの地獄だ かわかりませんが引き続き試行錯誤してみようと思います。
失敗パターン
パラメータ仕様の読み違い
ステアリング操作を報酬に反映させる報酬実装でsteering_angle の仕様を読み違えて、トラック中心から左側にいてハンドルを左に切ってたらおk的な報酬設定になっていましたw
reward_function 実装
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
reward = 0
# 車両がトラックラインの外側に出たらペナルティ
if not on_track:
print("off_track")
return 1e-3
# ステアリングを報酬に反映させる
steering_reward = 1e-3
if distance_from_center > 0:
# (´・ω・`) 逆になってた
if is_left_of_center and steering >= 0:
steering_reward = 1.0
elif (not is_left_of_center) and steering <= 0:
steering_reward = 1.0
else:
if steering == 0:
steering_reward = 1.0
print("steering_reward: %.2f" % steering_reward)
reward += steering_reward
print("total reward: %.2f" % reward)
return float(reward)
学習結果
報酬グラフはぱっとみで怪しい感じではありませんが、結果は散々。
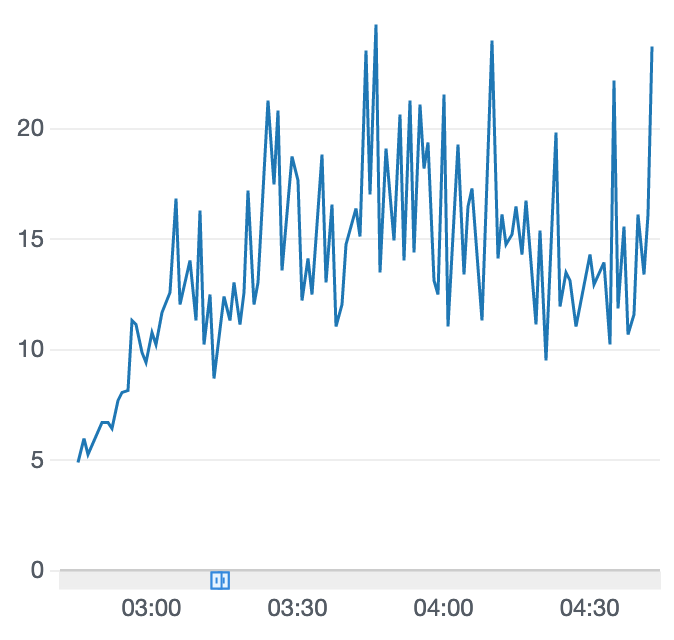
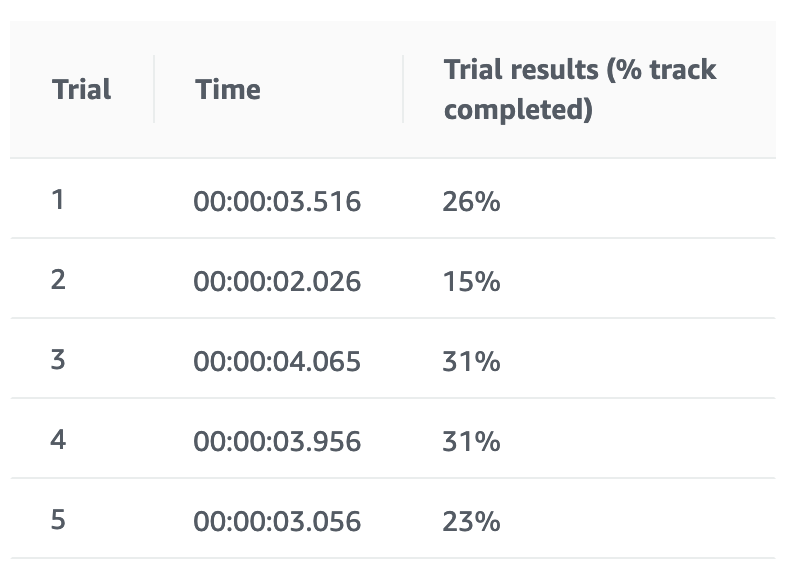
トレーニング中に引きこもる
コースアウトすると前回開始時点あたりからやり直しされるはずなのに、されなくて隅っこで引きこもり続けてしまいましたwww
報酬グラフも途中で止まってしまいます。こうなるとトレーニングを中止してやり直すしかありませんでした。
\ はたらきたくないー /

利用コストについて
2時間ないし3時間のトレーニングを8回ほど(うち数回は途中でSTOP)した時点でコストを確認してみました。
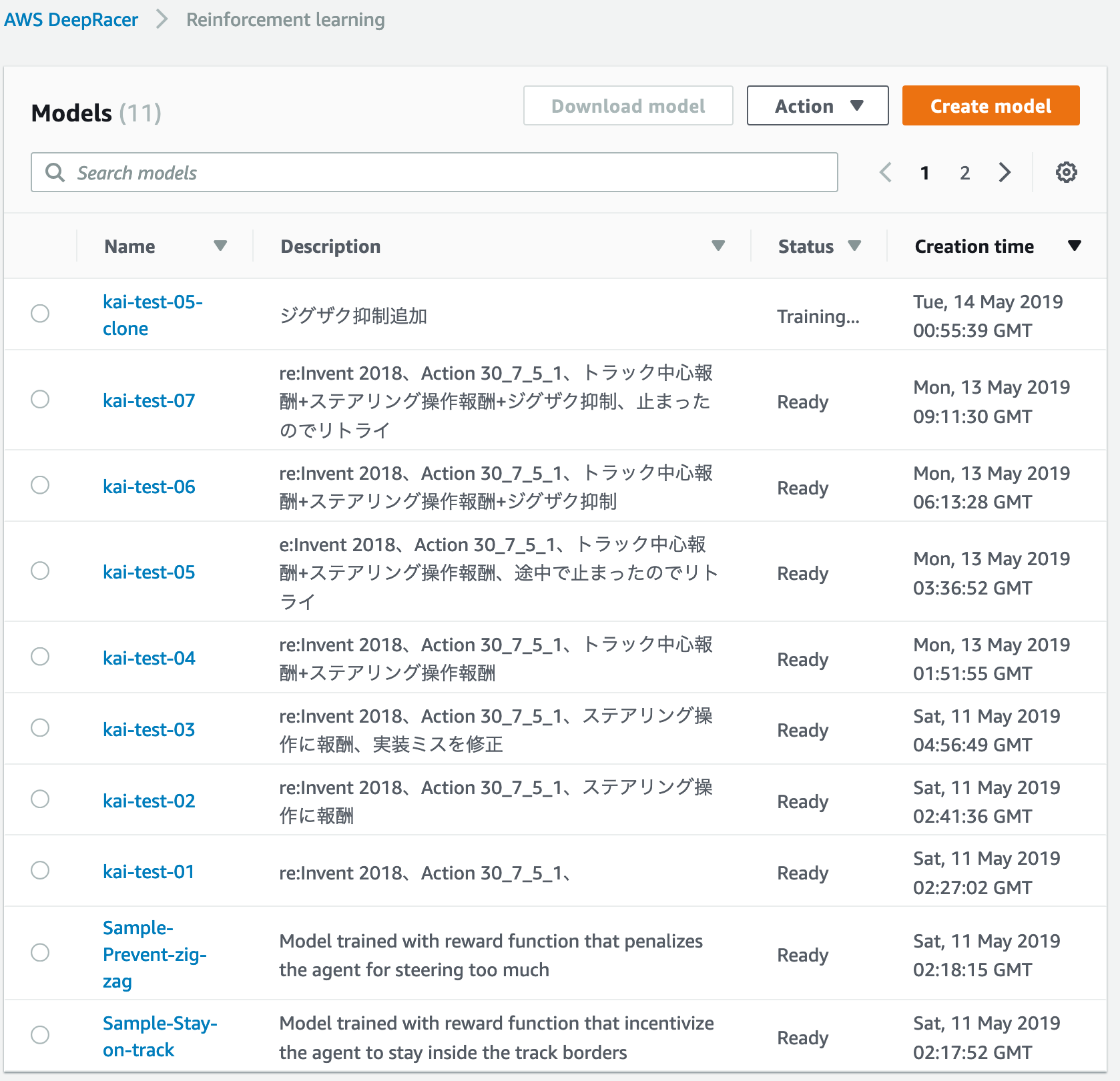
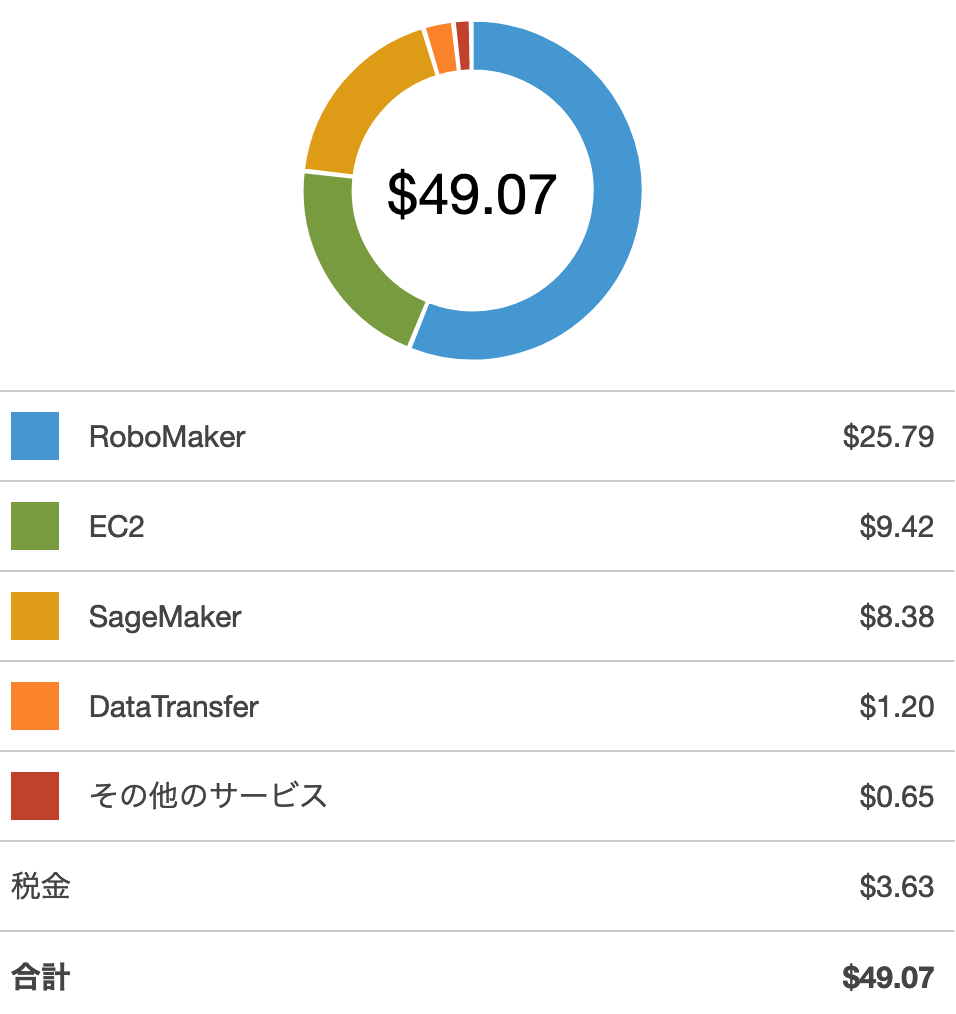
やはりAWS RoboMakerのコストが割を占めています。明細も確認しましたが、AWS RoboMakerの利用開始後にある無料枠はあっという間に使い果たしていました。
参考
Train and Evaluate AWS DeepRacer Models Using the AWS DeepRacer Console - AWS DeepRacer
https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-console-train-evaluate-models.html
AWS DeepRacerを強化する 報酬関数実装パターンあれこれ | DevelopersIO
https://dev.classmethod.jp/machine-learning/aws-deepracer-pattern-of-reward-function/