
はじめに
Claude Code のエージェントスキルは、SKILL.md ファイルに自然言語で指示を書くだけで Claude の行動を拡張できる仕組みです。しかし「スキルを書いたはいいけど、本当に効いているの?」という疑問は付きまといます。
2026年3月3日、Anthropic は skill-creator プラグイン のメジャーアップデートを発表しました。このアップデートにより、スキルの品質をソフトウェアテストと同じ厳密さで評価・改善できるようになりました。具体的には Evals(評価テスト)、Benchmark(性能測定)、A/B テスト、そして Improve(自動改善)の 4 モードが利用可能です。
この記事では、公式ドキュメントと公開情報をもとに skill-creator Evals の仕組みと使い方を解説します。
この記事で学べること
- Claude Code のスキルとは何か(基本的な仕組み)
- skill-creator の 4 モード(Create / Eval / Improve / Benchmark)の概要
- Eval パイプラインのアーキテクチャ(4 つのサブエージェント)
- テストケースの書き方(evals.json の構造)
- A/B テストとベンチマークの活用場面
対象読者
- Claude Code でエージェントスキルを開発・運用しているエンジニア
- AI エージェントの品質管理に課題を感じている方
- スキルの効果を定量的に測定したい方
前提環境
- Claude Code(最新版)
- Claude.ai または Cowork アカウント(skill-creator プラグインを使用する場合)
TL;DR
- Claude Code スキルは SKILL.md ファイルで定義し、Claude の行動を拡張する仕組み
- skill-creator v2 は Create / Eval / Improve / Benchmark の 4 モードを提供
- Eval パイプラインは Executor / Grader / Comparator / Analyzer の 4 サブエージェントで構成
- A/B テストは「スキルあり vs なし」をブラインドで比較し、効果を定量的に検証
- Benchmark モードはモデル更新後の品質デグレを検出するために活用
Claude Code スキルとは

Claude Code のスキル(Skills)は、.claude/skills/<skill-name>/SKILL.md に配置する Markdown ファイルです。公式ドキュメントによると、スキルには大きく 2 種類あります。
| 種別 | 説明 | 例 |
|---|---|---|
| Capability Uplift Skills | モデルの機能自体を拡張する | 特定の技術仕様や高度な手順の付与 |
| Workflow/Preference Skills | 既存の Claude 能力を好みの順序で組み合わせる | コードレビュー手順の標準化 |
スキルは /skill-name のようなスラッシュコマンドで手動実行することも、Claude が会話の文脈から自動的に判断して実行することもできます。
SKILL.md の基本構造
---
name: code-review
description: セキュリティとパフォーマンスの観点でコードをレビューする
disable-model-invocation: false
allowed-tools: Read, Grep
---
コードをレビューする際は以下の観点で確認してください:
1. 入力バリデーションの欠如
2. 非同期処理のエラーハンドリング
3. SQL インジェクションやXSS リスク
4. N+1 クエリ問題
各問題には重大度(high/medium/low)を付けて報告してください。
YAML フロントマターで動作を細かく制御でき、context: fork を指定するとサブエージェントで独立実行されます。
skill-creator とは — 4 つのモード
2026年3月3日のアップデートで、skill-creator は次の 4 モードを備えた包括的な開発ツールへと進化しました。
/skill-creator [mode]
モード:
Create — 新しいスキルを対話形式で作成する
Eval — テストケースを定義してスキルの品質を検証する
Improve — Eval の結果をもとにスキル説明文を自動改善する
Benchmark — モデル更新時の性能変化を継続的に追跡する
それぞれの役割をソフトウェア開発のアナロジーで整理すると:
| skill-creator モード | ソフトウェア開発の対応 |
|---|---|
| Create | 機能実装 |
| Eval | ユニットテスト実行 |
| Improve | テスト失敗を受けてコードをリファクタリング |
| Benchmark | CI/CD での継続的パフォーマンス測定 |
Eval パイプラインのアーキテクチャ
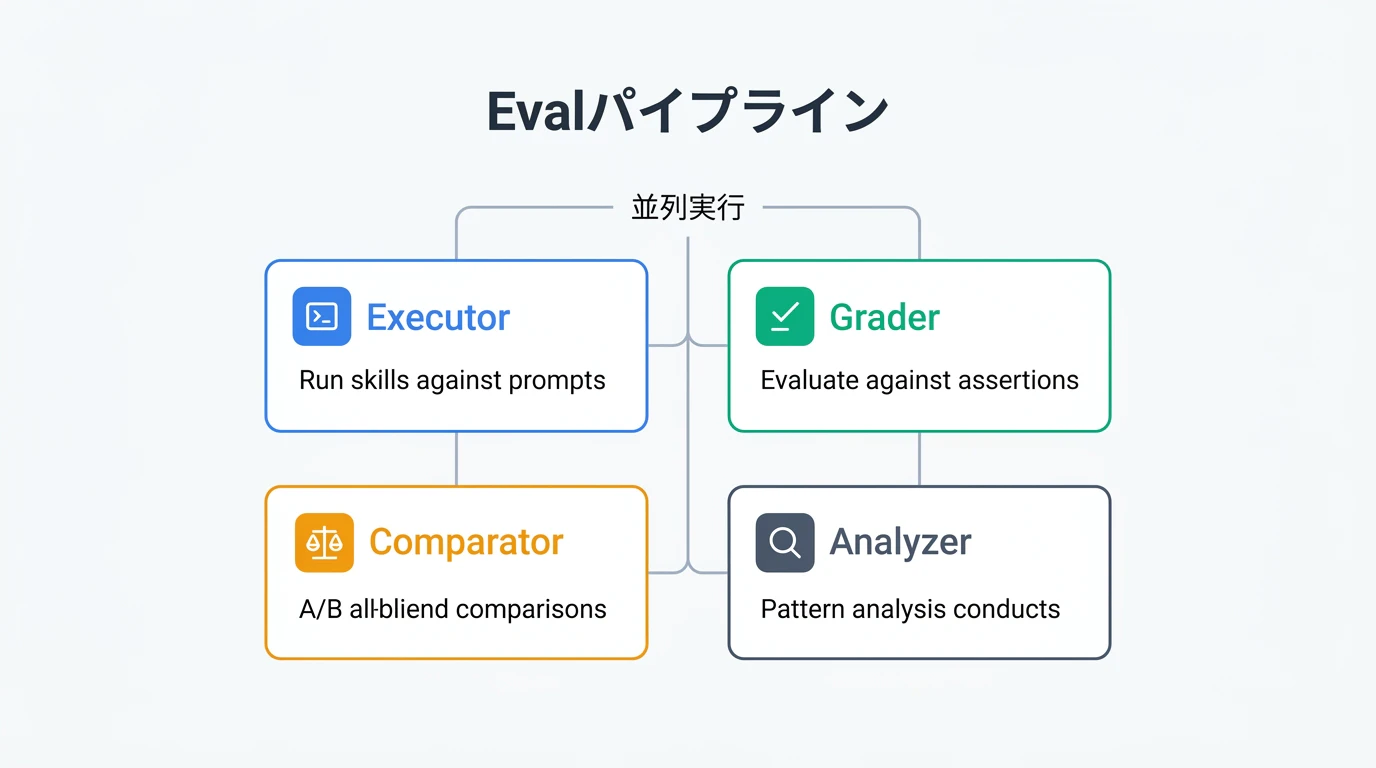
Eval モードは単一の処理で動くのではなく、4 つの専門サブエージェントが協調して動作するパイプライン構成を採用しています。
4 つのサブエージェント
Executor(実行エージェント)
テストケースのプロンプトに対してスキルを実行します。スキルあり・なしの両方で実行し、出力を収集します。
Grader(評価エージェント)
Executor の出力を、テストケースに定義したアサーション(検証項目)と照合します。各アサーションが pass/fail のどちらかを判定します。
Comparator(比較エージェント)
A/B テストを担当します。スキルあり vs なしの出力をブラインドで比較し、どちらがアサーションをより多く満たすかを判定します。
Analyzer(分析エージェント)
集計統計では見えにくいパターンを分析します。どのテストケースで失敗が集中しているか、スキルの記述のどの部分が問題かを分析してレポートします。
並列実行により、テストが相互汚染しません。公式ドキュメントによると「各エージェントがクリーンなコンテキストで独立して動作する」ため、テスト結果の再現性が確保されます。
テストケースの書き方
Eval モードのテストケースは JSON ファイルで定義します。公開情報によると、構造は以下のようになります。
evals.json の基本構造
{
"skill_name": "code-review",
"evals": [
{
"id": "eval-001",
"prompt": "この関数のセキュリティレビューをしてください:\n\nasync function getUser(id) {\n const query = `SELECT * FROM users WHERE id = ${id}`;\n return await db.query(query);\n}",
"expected_output": "SQLインジェクションの脆弱性を指摘し、プリペアドステートメントを推奨すること",
"assertions": [
{
"name": "sql_injection_detected",
"description": "SQLインジェクションリスクを high 重大度で指摘している"
},
{
"name": "parameterized_query_suggested",
"description": "パラメータ化クエリまたはプリペアドステートメントを推奨している"
},
{
"name": "async_error_handling_noted",
"description": "async/await のエラーハンドリング不足を指摘している"
}
]
}
]
}
良いアサーションの条件
公式ドキュメントは、アサーションの品質について次の点を強調しています。
- 客観的に検証可能であること(「良い説明」より「SQLインジェクションを指摘している」が優れている)
- 説明文が明確であること(ベンチマーク画面で一目で内容が分かる)
- 最初はアサーションなしでプロンプトだけ書くことを推奨(実行結果を見てからアサーションを追加する)
A/B テストの活用
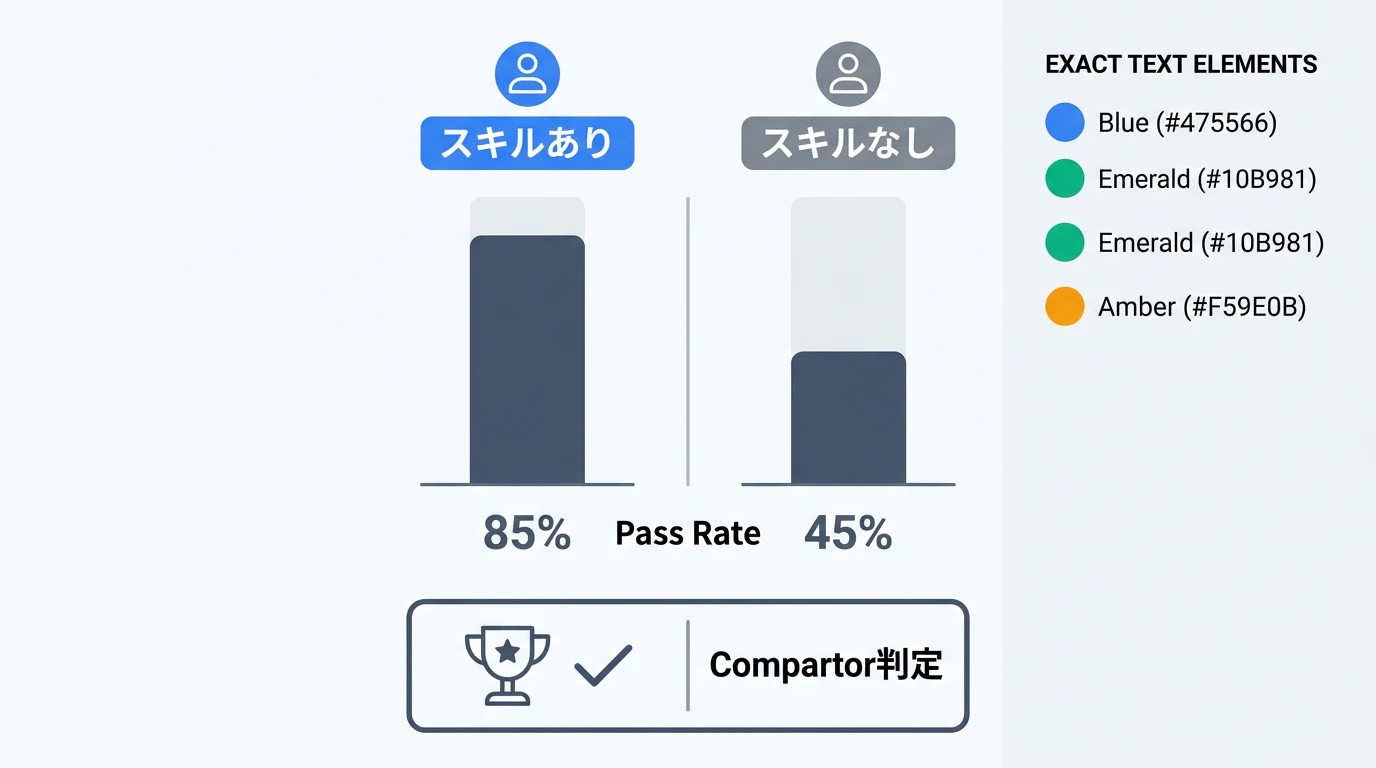
Comparator エージェントによる A/B テストは、スキルが本当に効果を持つかを定量的に確認する仕組みです。
比較の仕組み
テストケース × N回
├── [A] スキルあり で実行 → 出力A
└── [B] スキルなし で実行 → 出力B
Comparator がブラインドで判定:
- 出力A と 出力B、どちらがアサーションを満たすか
- Analyzer がパターンを分析
HTML レポートを生成:
"SKILL vs without SKILL" のパスレート比較
公式情報によると、両方のスコアが同じ場合は「テストをより難しくするか、モデルが本当に苦手な領域を対象にすべき」という意味のシグナルとして扱います。つまり A/B テストは「スキルの有効性確認」と「テスト設計の品質確認」の両方に使えます。
実際の計測指標
Benchmark モードでは以下の指標をトラッキングします。
| 指標 | 説明 |
|---|---|
| Pass rate | テストケースのアサーション通過率(%) |
| Elapsed time | スキル実行にかかった時間(秒) |
| Token usage | 1 回の実行で消費したトークン数 |
Improve モード — スキル記述の自動改善
Eval で問題が見つかった場合、Improve モードがスキルの説明文を自動的に改善します。
改善プロセス
公開情報によると、Improve モードは以下の手順で動作します。
- eval セットをトレーニング用とテスト用に分割
- 現在のスキル説明文を評価(各クエリを複数回実行してトリガー率を計測)
- Claude が失敗パターンを分析し、改善案を提案
- 改善案をトレーニングセットとテストセットの両方で再評価
- 複数イテレーションを繰り返してスキル説明文を洗練させる
Anthropic の公式ブログによると、Improve モードの適用後、公開されている 6 つのドキュメント作成スキルのうち 5 つでトリガー精度が改善したと報告されています。
利用方法
skill-creator プラグインのインストール
Claude.ai または Claude Code から skill-creator プラグインをインストールします。
Claude Code の場合は Skill Creator プラグインページ にアクセスし、「Install in Claude Code」ボタンをクリックします。Claude.ai の場合は Plugins メニューから「Skill Creator」を検索してインストールします。
使用例
# スキルを新規作成する
/skill-creator Create a new skill that reviews PRs for security issues
# 既存スキルの Eval を実行する
/skill-creator Eval my code-review skill
# Eval 結果に基づいて改善する
/skill-creator Improve my deploy skill based on these test cases
# 10 回のベンチマークを実行して分散を確認する
/skill-creator Benchmark my skill across 10 runs and show variance
Benchmark モードの活用場面
Benchmark モードが特に有効なのは以下の場面です。
Claude のモデル更新時
新しいモデルバージョンにアップデートした際、既存スキルのパスレートが低下していないかを確認します。「モデルが進化してスキルが不要になった」場合も Benchmark が検出します。
スキルのデプロイ前
チームに配布する前に、品質基準(例: pass rate 90% 以上)をクリアしているかを確認します。
スキルのリファクタリング後
スキル説明文を変更した際に、既存のアサーションがすべて通過することを確認します(リグレッション防止)。
スキルの設計指針
skill-creator Evals を効果的に活用するための設計指針を整理します。
テスト可能なスキルを書く
アサーションで検証しやすいスキルを設計するためのポイントです。
# 良い例: 出力フォーマットが明確
---
name: security-review
description: コードのセキュリティレビューをhigh/medium/low重大度付きで報告する
---
セキュリティレビューの結果は以下の形式で報告してください:
## セキュリティレビュー結果
### High
- [問題の説明] — [修正方法]
### Medium
- ...
### Low
- ...
フォーマットが一定であれば、Grader がアサーションを判定しやすくなります。
スキルの粒度
公式ドキュメントは SKILL.md を 500 行以内に収め、詳細なリファレンスは別ファイルに分割することを推奨しています。大きなスキルより、小さくテスト可能なスキルの組み合わせが好ましいとされています。
まとめ
Claude Code の skill-creator Evals は、エージェントスキルの開発にソフトウェアテストの文化をもたらす取り組みです。
- Eval モード: テストケースを定義してスキルの品質を検証
- A/B テスト(Comparator): スキルの有効性を定量的に確認
- Improve モード: 失敗パターンからスキル説明文を自動改善
- Benchmark モード: モデル更新後の品質デグレを継続監視
公式ドキュメントが指摘するように、この仕組みの本質は「スキルをソフトウェアの一部として扱う」ことです。テスト・ベンチマーク・リファクタリングのサイクルをスキル開発にも適用することで、長期的に信頼できるエージェントシステムを構築できます。
現時点では Claude.ai、Cowork、および GitHub リポジトリ(anthropics/skills)経由で利用可能です。