はじめに
2026年5月5日、Subquadratic社が SubQ 1M-Preview をリリースしました。これは世界初の「完全サブクアドラティックアーキテクチャ」を採用したLLMです。
従来のTransformerベースモデルが抱える根本的な課題として、注意機構の計算量がコンテキスト長の二乗(O(n²))で増大するという問題があります。SubQはこの制約をアーキテクチャレベルで解決し、計算量を 線形(O(n)) に抑えることに成功しています。
この記事で学べること
- SubQの核心技術「SSA(Subquadratic Sparse Attention)」の仕組み
- ベンチマーク性能の実際(RULER・SWE-Bench・MRCR v2)
- OpenAI互換APIでの利用方法
- 従来LLMとのコスト・性能比較
- SubQが実用的なユースケース
対象読者
- LLMをAPIで活用しているエンジニア
- 大規模コンテキスト処理(コードベース解析、長文書処理)に関心がある方
- LLMのアーキテクチャ動向をキャッチアップしたい方
前提環境
- Python 3.10+
- SubQ APIアクセス(プライベートベータ、ウェイトリスト申請が必要)
TL;DR
- SubQは計算量 O(n) のサブクアドラティックアーキテクチャ採用した世界初の商用LLM
- プロダクション環境で 1Mトークン のコンテキストを処理(研究構成では12Mトークン達成)
- FlashAttentionより 52倍高速・63%計算量削減
- RULER 128Kベンチマークで 95.6%(Claude Opus 4.6の94.8%を上回る)
- OpenAI互換APIで利用可能(プライベートベータ中)
なぜサブクアドラティックが重要なのか
従来のTransformerの限界
現在の主要LLM(GPT-5.5、Claude、Geminiなど)はすべて、Vaswani et al., 2017のAttention Is All You Need以来のTransformerアーキテクチャを採用しています。
Transformerの注意機構では、長さnのシーケンスに対して以下の演算を行います:
Attention(Q, K, V) = softmax(QK^T / √d_k) V
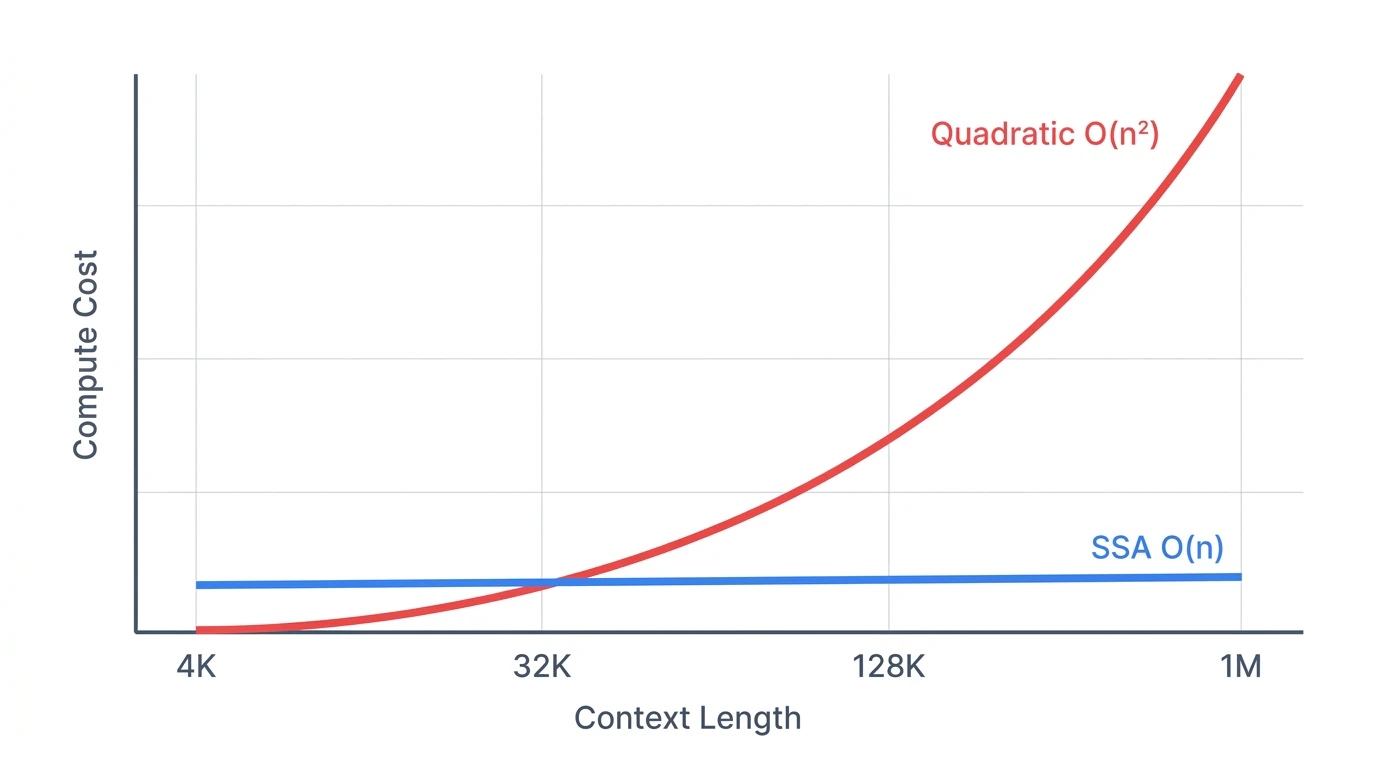
この QK^T の計算が O(n²) の計算量を生じさせます。コンテキスト長が2倍になると、計算量は4倍になります。
# 各モデルのコンテキスト長とコスト(概算)
context_4k: cost × 1
context_32k: cost × 64 (8倍の長さ → 64倍のコスト)
context_128k: cost × 1024 (32倍の長さ → 1024倍のコスト)
context_1M: cost × 62500以上
この「クアドラティック爆発」が、実用的な超長コンテキスト処理の最大の障壁でした。
SSA(Subquadratic Sparse Attention)の仕組み
SubQが採用する SSA(Subquadratic Sparse Attention) は、従来の近似手法(局所的注意、ランダムスパースネス等)とは根本的に異なるアプローチです。
SSAの核心:コンテンツ依存スパース注意
公式ブログによると、SSAはクエリトークンごとに「どのキートークンに注意を向けるべきか」を動的に学習する コンテンツ依存型 のスパース注意機構です。
従来のスパース化手法との違いを整理します:
| アプローチ | スパース化の方法 | 限界 |
|---|---|---|
| Local Attention | 固定ウィンドウ内のみ注意 | 長距離依存関係を捕捉できない |
| Random Sparse | ランダムにトークンを選択 | タスクに関係ないトークンに注意が向く |
| Linformer等 | 低ランク近似 | 精度劣化が生じやすい |
| SSA | コンテンツを見て動的に選択 | 精度を保ちながらO(n)を実現 |
SSAは各クエリトークンが関連するキートークンのみを選択し、その小さなサブセットに対して 完全な注意計算 を実行します。これにより:
- 情報の損失なし(近似ではなくスパース選択)
- 計算量がO(n)に収まる
- FlashAttentionより52倍高速(アーキテクチャレベル比較)
- 63%の計算量削減
アーキテクチャ設計の特徴
Subquadraticは11名の博士研究者(Meta、Google、Oxford、Cambridge出身)が「数学的基礎から設計した」と説明しています。既存モデルの修正ではなく、ゼロから設計された点が重要です。
ベンチマーク性能
公式サイト(subq.ai/introducing-subq)が公開しているベンチマーク結果を整理します。
RULER 128K — 長コンテキスト理解
RULERは長コンテキスト処理能力を測定するNVIDIAのベンチマークです。128Kトークンの文書から情報を取得する能力を評価します。
| モデル | RULER 128K スコア |
|---|---|
| SubQ 1M-Preview | 95.6% |
| Claude Opus 4.6 | 94.8% |
※ スコアはSubquadratic公式ブログ(2026年5月5日)掲載の自社公開値。
※ DeepSeek V4 Pro: SubQ公式比較表では「DeepSeek 4.0 Pro」と表記。
SWE-bench Verified — コーディング能力
SWE-Benchは実際のGitHubのIssueを自動解決する能力を測定します。
| モデル | SWE-bench Verified |
|---|---|
| SubQ 1M-Preview | 81.8% |
| Claude Opus 4.6 | 80.8% |
| DeepSeek V4 Pro ※ | 80.0% |
MRCR v2 — 超長コンテキスト多段記憶
MRCR v2(8-needle, 1M tokens)は、1Mトークンのコンテキスト内に散在する8つの情報を同時に取得する高難度タスクです。
| モデル | MRCR v2(1Mトークン) |
|---|---|
| GPT-5.5 | 74.0% |
| SubQ 1M-Preview | 65.9% |
| Claude Opus 4.7 | 32.2% |
| Gemini 3.1 Pro | 26.3% |
注意: Subquadraticの「1,000倍の効率化」という主張に対して、VentureBeatは独立した研究者がその証明を求めていると報じています(参照)。ベンチマーク数値については公式ページを参照し、今後の独立検証を待つことを推奨します。
APIの使い方
SubQ APIはOpenAI互換のRESTエンドポイントを提供しています。現在はプライベートベータのため、subq.aiでウェイトリスト申請が必要です。
セットアップ
import openai
# SubQ APIはOpenAI互換エンドポイントを提供
client = openai.OpenAI(
api_key="your-subq-api-key",
base_url="https://api.subq.ai/v1"
)
基本的な使い方
# 標準的なチャット補完
response = client.chat.completions.create(
model="subq-1m-preview",
messages=[
{
"role": "user",
"content": "以下のコードベースを解析して、バグを報告してください。"
}
],
max_tokens=4096
)
print(response.choices[0].message.content)
長コンテキストを活用するユースケース
SubQの最大の強みは大規模コンテキストの処理です。実際のユースケースとして、大規模コードベースの一括解析が考えられます。
import os
import openai
from pathlib import Path
def analyze_codebase(directory: str) -> str:
"""コードベース全体を単一リクエストで解析する"""
client = openai.OpenAI(
api_key=os.environ["SUBQ_API_KEY"],
base_url="https://api.subq.ai/v1"
)
# ディレクトリ内の全Pythonファイルを収集
code_files = []
for path in Path(directory).rglob("*.py"):
content = path.read_text(encoding="utf-8", errors="ignore")
code_files.append(f"## {path}\n\n```python\n{content}\n```")
full_codebase = "\n\n".join(code_files)
# 1Mトークンのコンテキストを活用して一括解析
response = client.chat.completions.create(
model="subq-1m-preview",
messages=[
{
"role": "system",
"content": (
"あなたはコードレビューの専門家です。"
"提示されたコードベース全体を分析し、"
"セキュリティ上の脆弱性、パフォーマンス問題、"
"設計上の問題点を報告してください。"
)
},
{
"role": "user",
"content": f"以下のコードベースを解析してください:\n\n{full_codebase}"
}
],
max_tokens=8192,
stream=True
)
result = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
result += chunk.choices[0].delta.content
return result
# 使用例
report = analyze_codebase("./my_project")
print(report)
上記のコードは公式ドキュメントの仕様(OpenAI互換API、モデルID
subq-1m-preview)に基づいて構成しています。実際のAPIの詳細は subq.ai の公式ドキュメントを参照してください。
SubQ Codeの活用
SubQ Codeは、SubQを組み込んだCLIエージェントです。大規模コードベースを丸ごとコンテキストに載せて、自律的なコード解析・修正を実行できます。
# SubQ Code CLIのインストール(プライベートベータ)
pip install subq-code
# コードベース全体を解析
subq-code analyze ./my_project
# 特定の機能を実装させる
subq-code implement "ユーザー認証機能を追加して、既存のコードとの整合性を保ちながら実装してください"
SubQ Code のインストールコマンドおよびCLIサブコマンドの詳細は、現時点(プライベートベータ)では非公開です。上記のコードはSubQ Code の機能をイメージするための擬似コードです。実際のインストール方法・コマンドはアクセス許可後に提供される公式ドキュメントを参照してください。
SubQ Codeの強みは、従来のClaude CodeやCodexのように分割せず、プロジェクト全体を一度に把握した上でコードを生成できる点です。
コストと従来モデルの比較
Subquadraticが公開しているコスト比較(公式発表)を整理します。
RULER 128Kのコスト比較
| モデル | RULER 128K スコア | 推定コスト |
|---|---|---|
| SubQ 1M-Preview | 95.6% | 約$8 |
| Claude Opus 4.6 | 94.8% | 約$2,600 |
同等の精度で、コストが約1/325に抑えられる計算です。この差はサブクアドラティックアーキテクチャによる線形スケーリングが直接効いています。
このコスト比較は128Kトークンの長コンテキストタスクにおける数値です。短いコンテキスト(数千トークン)ではこれほどの差は出ません。サブクアドラティックアーキテクチャの優位性はコンテキスト長が増えるほど大きくなります。
向いているユースケース
SubQの1Mトークンコンテキストが特に活きる場面を整理します。
1. 大規模コードベース解析
50万行規模のコードベースを一度に把握し、バグ探索・リファクタリング提案・アーキテクチャ分析を実行できます。
2. 大量ドキュメントの横断分析
法律事務所の大量の判例文書・契約書を一括で照会。医療分野での数千件の論文サーベイ。
3. 長期ログ解析
数百万行のサーバーログを一括解析して異常検知・根本原因分析を行う用途。
4. 書籍・長文レポートの要約・QA
1,000ページ以上の技術書・研究報告書をコンテキストに載せた質疑応答。
現時点の制限
現在のSubQ 1M-Previewには以下の制限があります:
- アクセス制限: プライベートベータ(ウェイトリスト申請が必要)
- 料金非公開: 価格はウェイトリスト申請後に案内される形式
- Windows対応: SubQ CodeのWindows対応状況は公式サイトで要確認
- クレーム検証: 性能クレームの一部は独立した第三者検証が待たれる状態
アクセス方法
- subq.ai でウェイトリスト申請
- 申請フォームにユースケース・所属を記入
- 審査後にAPIキーが発行される
SubQ Search(長文リサーチツール)は無料で利用できる場合があります。詳細は公式サイトを参照してください。
まとめ
SubQは、LLMアーキテクチャにおける根本的なブレークスルーを体現したモデルです。
- アーキテクチャの革新: O(n²) → O(n) の線形スケーリングを実現するSSA
- 実用的な性能: RULER・SWE-Bench・MRCR v2で既存フロンティアモデルと同等以上
- コスト効率: 長コンテキストタスクで従来比1/300以上のコスト削減が可能
- OpenAI互換: 既存のコードをほぼそのまま移行可能
技術的なクレームの一部は独立検証待ちの部分もありますが、「サブクアドラティックアーキテクチャ」というコンセプト自体は業界で長年待望されていたアプローチです。特に大規模コンテキスト処理が必要なエンジニアは注目する価値があります。
参考リンク
- Introducing SubQ: The First Fully Subquadratic LLM — Subquadratic公式ブログ
- How SSA Makes Long Context Practical — SSA技術解説(公式)
- SubQ by Subquadratic — Models, Pricing & API — LLM Reference
- Subquadratic launches with $29M — SiliconANGLE
- The context window has been shattered — The New Stack
- 独立した証明を求める研究者の声 — VentureBeat