はじめに
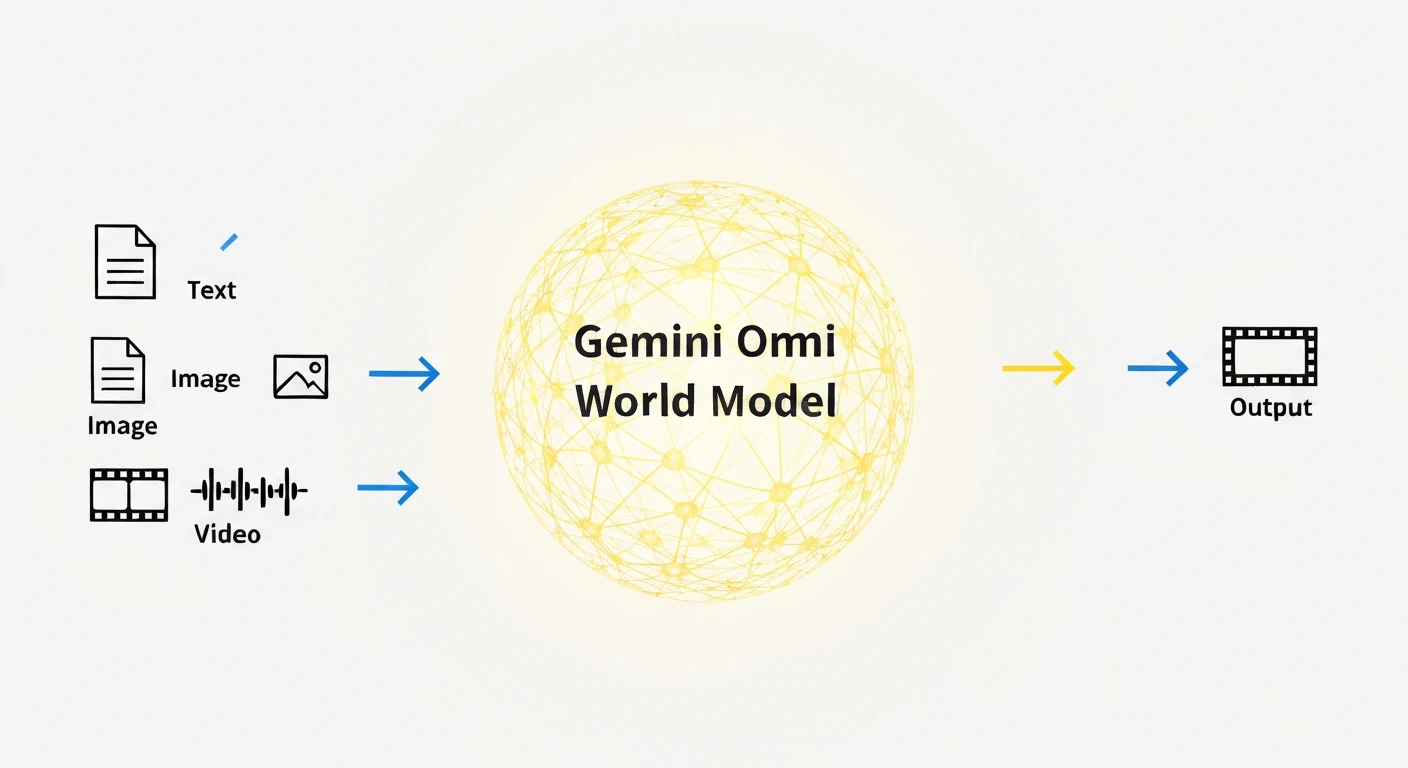
2026年5月19日のGoogle I/O 2026で、GoogleはGemini Omniを発表しました。テキスト・画像・音声・動画を同時に入力として受け取り、物理シミュレーション付きの動画を生成する「any-to-any」統合マルチモーダルモデルです。
単なる動画生成ツールではなく、重力・照明・流体力学といった物理法則を内部的に理解・シミュレートする「ワールドモデル」として設計されています。
この記事で学べること
- Gemini Omniの設計思想と技術アーキテクチャ
- 従来のVeo 3.xとの違いと棲み分け
- 4コンポーネント統合(Gemini + Veo + Nano Banana + Project Genie)
- 現在利用可能な機能と開発者向けAPI提供予定
- YouTube Shorts・Google Flowとの統合
対象読者
- AI動画生成技術を追っているエンジニア
- Gemini APIを業務・個人開発で活用している方
- マルチモーダルAIの最新動向に関心がある方
TL;DR
- Gemini OmniはGeminiの推論能力と動画・画像生成を1アーキテクチャに統合した「ワールドモデル」
- 入力: テキスト・画像・音声・動画(複合入力可)/ 出力: 音声付き動画(10秒クリップ)
- 物理シミュレーション(重力・流体・照明)付きで「物理法則通りに振る舞う動画」を生成
- YouTube Shorts Remixとの統合でGeminiアプリ・無料ユーザーにも提供開始
- 開発者向けAPIは「数週間以内」のロールアウト予定(2026年5月時点)
Gemini Omniとは
Gemini OmniはGoogle DeepMindが発表した次世代マルチモーダルモデルです。公式には「any-to-any model(何からでも何でも生成できるモデル)」と説明されています。
公式ブログによると、Gemini Omniはシーンを「リアルに見せる」だけでなく「物理的に正しく振る舞わせる」ことを目指して設計されており、重力・運動エネルギー・流体力学に対する直感的な理解を組み込んでいます。
最初のリリースモデルはGemini Omni Flashです。段階展開の一環として、将来的に画像・音声の単体出力にも対応予定と公式ページに記載されています。
技術アーキテクチャ: 4コンポーネント統合
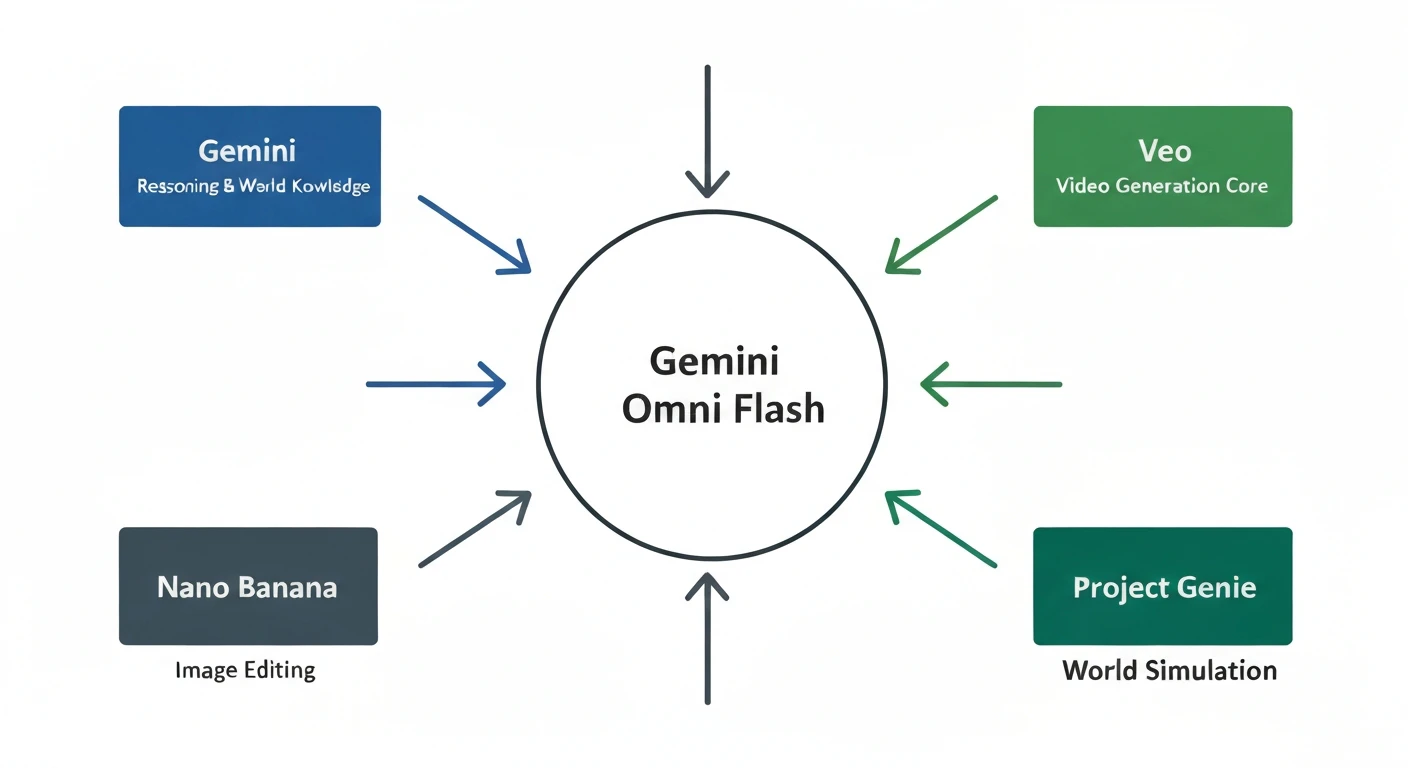
Google DeepMindのDemis Hassabis CEOはGemini Omni公式発表で、Gemini Omniが以下の4コンポーネントを単一アーキテクチャに統合していると説明しました。
| コンポーネント | 役割 |
|---|---|
| Gemini(メインモデル) | 推論・世界知識(歴史・科学・文化的文脈) |
| Veo | 動画生成コア |
| Nano Banana | 画像編集 |
| Project Genie(Genie 3ベース) | インタラクティブなワールドシミュレーション |
この統合により、「次に何が起きるべきか」をGeminiの世界知識と物理的直観を組み合わせて推論しながら動画を生成・編集します。連続する編集指示をまたいで、物理的一貫性・キャラクター一貫性・シーン記憶を維持するのが特徴です。
物理シミュレーション機能
Gemini Omniが従来の動画生成モデルと大きく異なる点は、物理シミュレーションへのアプローチです。
従来のVeo: 視覚的リアリズムを重視 — 「リアルに見える動き」の生成
Gemini Omni: 物理的振る舞いの正確さを重視 — 「世界の法則通りに振る舞う動き」の生成
具体的には以下の物理要素を内部的にシミュレートします。
- 重力・運動エネルギー: 落下・跳ね返り・慣性の正確な表現
- 流体力学: 液体・煙・布の動き
- 照明・影: 光源の移動に伴うシーン内の影の変化
- 空間コンテキスト: 物体間の相互作用(衝突・積み重ねなど)
Google I/Oキーノートで示されたデモでは、「音付きで弾むマーブル動画」(音声・重力・接触物理を統合)や「タンパク質折り畳みのクレイアニメーション解説動画」(素材感・ナレーション・多段ストーリー展開)が紹介されました。
主要機能と現在の仕様
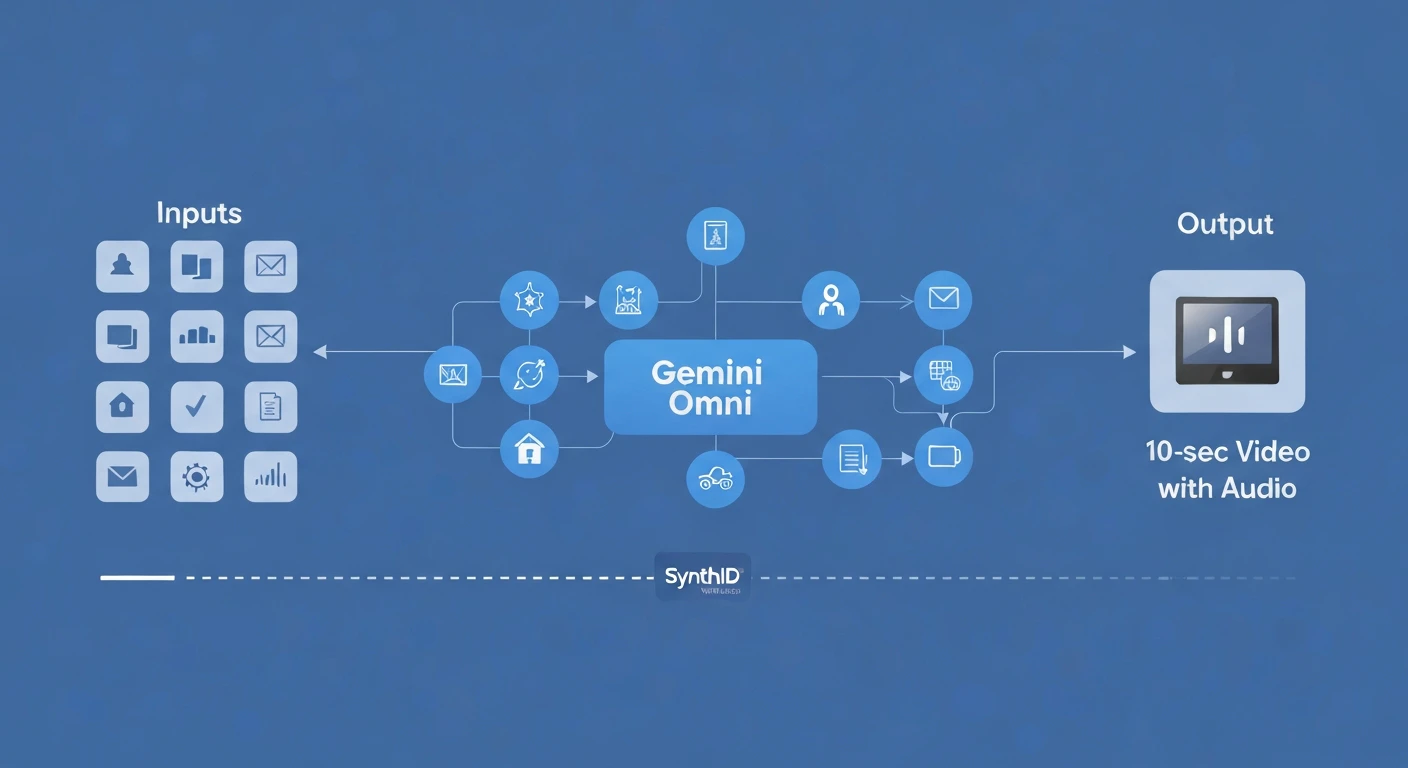
マルチモーダル入出力
入力モダリティ(現在):
- テキスト
- 画像
- 音声
- 動画クリップ
- ※上記の複合入力に対応
出力モダリティ(現在):
- 動画(音声付き同期、10秒クリップ)
画像・音声の単体出力は「今後提供予定」とされており、音声編集(speech editing)は現時点では保留中です。この10秒クリップという制限はモデルの能力上限ではなく、段階的展開のための意図的な制限とされています。
会話型インターフェース
従来のAI動画生成ツールでは、編集のたびにプロンプトを書き直す「再プロンプト方式」が主流でした。Gemini Omniは会話型インターフェースを採用しており、以下のような自然な指示の積み重ねが可能です。
「背景の人物を消して」
→「照明を暖かくして」
→「ナレーターを女性の声にして」
各指示は直前の状態から差分的に適用され、シーン記憶を保ちながら進行します。
SynthIDウォーターマーク
公式ブログによると、Gemini Omniが生成した全動画にはSynthIDウォーターマークが自動付与されます。これはオプションではなく強制適用であり、GeminiアプリやChrome、Google SearchでSynthIDの検証が可能です。
Veo 3.xとの違い・棲み分け
Gemini Omniの登場後も、Veo APIラインは継続提供されます。用途と設計思想で明確に棲み分けられています。
| 比較軸 | Veo 3.1 | Gemini Omni Flash |
|---|---|---|
| 設計思想 | 専用動画生成モデル | 統合マルチモーダル生成モデル |
| 入力 | テキスト・静止画 | テキスト・画像・音声・動画(複合) |
| 出力 | 動画(高品質・長尺) | 動画(音声付き、10秒クリップ) |
| 物理推論 | 視覚的リアリズム重視 | 物理的振る舞いの正確さを重視 |
| 編集方式 | 再プロンプト方式 | 会話型インターフェース |
| 今後の位置づけ | 専門動画APIとして継続 | Geminiアプリ内でVeoを将来置き換え |
使い分けの目安:
- 長尺・高品質な動画生成: Veo 3.1 API
- 物理的に正確な短尺動画・会話型編集: Gemini Omni
- マルチモーダル統合アプリ: Gemini Omni(API公開後)
利用可能なプラットフォームと料金
Google AIサブスクリプション更新ブログに基づく情報です(2026年5月19日時点)。
一般ユーザー向け(Geminiアプリ・Google Flow)
| プラン | 月額 | Google Flow Credits |
|---|---|---|
| AI Plus | $7.99 | 200 Credits |
| AI Pro | $19.99 | 1,000 Credits |
| AI Ultra | $99.99 | 10,000 Credits |
| AI Ultra(上位) | $200 | 25,000 Credits |
従来のAI Ultra($250/月)は$200/月に値下げされ、新たに$99.99/月の入門向けAI Ultraプランが追加されました(公式)。
YouTube Shorts Remix(無料ユーザーを含む)
YouTube公式ブログによると、YouTube Shorts RemixへのGemini Omni統合は5月19日の週からロールアウト開始し、無料ユーザーにも提供されます。
機能の概要:
- 既存Shortへのテキストプロンプトまたは画像を投入してシーンを丸ごと再生成・編集
- 会話型反復編集に対応
- AI生成タグと元動画へのリンクが自動付与
- チャンネルオーナーはShorts Remixを無効化可能
開発者向けAPI
2026年5月20日時点でGemini API(ai.google.dev/api)にGemini Omniのエントリーはまだ存在しません。公式発表では「数週間以内」のロールアウトが予告されており、モデルID・エンドポイント・料金等の確定情報は公開されていません。
API提供開始後に確認すべきURL:
- Gemini API公式リファレンス: https://ai.google.dev/api
- Vertex AI (Google Cloud): https://cloud.google.com/vertex-ai
2026年5月時点の注意: 開発者向けAPIは未公開です。本記事はGoogle I/O 2026の公式発表に基づく情報整理であり、APIの具体的なパラメータ・料金等が確定次第、別途ガイド記事を公開予定です。
Google Flowとの統合
Google Labsのフロー更新ブログによると、Gemini OmniはGoogle FlowおよびGoogle Flow Musicに組み込まれています。
Google Flow: 映像制作ワークフロー全体をAIとの会話で進行。スタイル・被写体・シーン・カット割りを自然言語で指定しながら動画を制作。
Google Flow Music: 音楽動画の監督をAIと会話しながら実施。楽曲のナラティブ・ペーシングに合わせた映像ガイドが可能。
開発者向け展望
Gemini Omniの開発者向けAPIが公開されると、以下のようなユースケースが実現可能になると考えられます。
教育コンテンツ生成
- テキスト原稿から物理的に正確な解説動画を自動生成
- 科学現象の可視化(タンパク質折り畳み、流体シミュレーションなど)
eコマース・広告
- 製品画像から動的なプロモーション動画を自動生成
- 複数バリエーションのA/Bテスト素材の一括生成
ゲーム・インタラクティブメディア
- Project Genieのワールドシミュレーション機能を活用した動的なゲームアセット生成
- ユーザー入力に応じてリアルタイムで変化するインタラクティブ動画コンテンツ
マルチモーダルエージェント
- テキスト・音声・動画を統合的に処理するエージェントパイプラインへの組み込み
- Gemini APIとの統合によるコンテキスト継続型のマルチメディア生成
まとめ
- Gemini OmniはGemini推論・Veo動画生成・Nano Banana画像編集・Project Genie物理シミュレーションを統合した「ワールドモデル」
- 現在の出力は音声付き10秒動画クリップ。画像・音声の単体出力は今後の予定
- 物理シミュレーション(重力・流体・照明)付きで「視覚的リアリズム」を超えた「物理的正確性」を実現
- YouTube ShortsのRemix機能から無料ユーザーにも展開開始(5月19日の週)
- 開発者向けAPIは「数週間以内」のロールアウト予定。確定情報は公式ドキュメントを参照
マルチモーダルAIが「入力の多様化」から「出力の多様化」へと進化する転換点として、Gemini Omniの展開は注目に値します。
参考リンク
- Introducing Gemini Omni — Google公式ブログ(2026-05-19)
- Gemini Omni — Google DeepMind — DeepMind公式モデルページ
- All the news from the Google I/O 2026 Developer keynote — Google開発者ブログ
- Google Flow updates — Google Labs公式(2026-05-19)
- Google AI subscription updates from Google I/O 2026 — 料金プラン公式(2026-05-19)
- YouTube: Ask YouTube and Gemini Omni for Shorts Remix — 9to5Google
- Google's Gemini Omni turns images, audio, and text into video — TechCrunch
- Gemini API reference — 開発者向けAPIリファレンス