はじめに
2026年3月15日、ByteDanceはAI動画生成モデル「Seedance 2.0」のグローバル展開を無期限停止した。Disney、Paramount、Warner Bros. Discovery、Netflix、Sony Picturesの主要5スタジオからCease-and-Desist(差止通告)が送付され、訓練データの著作権侵害と生成物のIP再現という二重の法的問題が浮上したためである。
この事件は、AI動画生成技術を利用するすべての開発者にとって他人事ではない。生成AIの出力が著作権を侵害した場合、AIプロバイダだけでなく 利用者側にも法的責任が発生しうる というのが現行法の解釈である。
この記事では、Seedance 2.0著作権危機の全貌を整理し、AI動画生成APIを活用する開発者が知るべき知財リスクと具体的な対策をまとめる。
この記事で学べること
- Seedance 2.0著作権危機の経緯と法的論点
- AI動画生成における訓練データ・出力物の二重リスク構造
- 主要プロバイダのIPガードレール比較
- 開発者が取るべき著作権リスク対策
対象読者
- AI動画生成APIを利用・検討しているエンジニア
- 生成AIプロダクトの法務・コンプライアンスを担当する方
- AIコンテンツモデレーションの設計に携わる方
TL;DR
- ByteDance Seedance 2.0は、ハリウッド主要5スタジオからの著作権訴訟圧力でグローバル展開を無期限停止した
- 問題は「訓練データの無断利用」と「生成物のIP再現」の二重構造にある
- 2026年3月時点の米国法では、AI生成コンテンツが著作権を侵害した場合、 プロバイダと利用者の両方 が責任を問われる可能性がある
- 開発者はプロンプトフィルタリング、出力検証、利用規約の確認を組み合わせた多層防御が必要
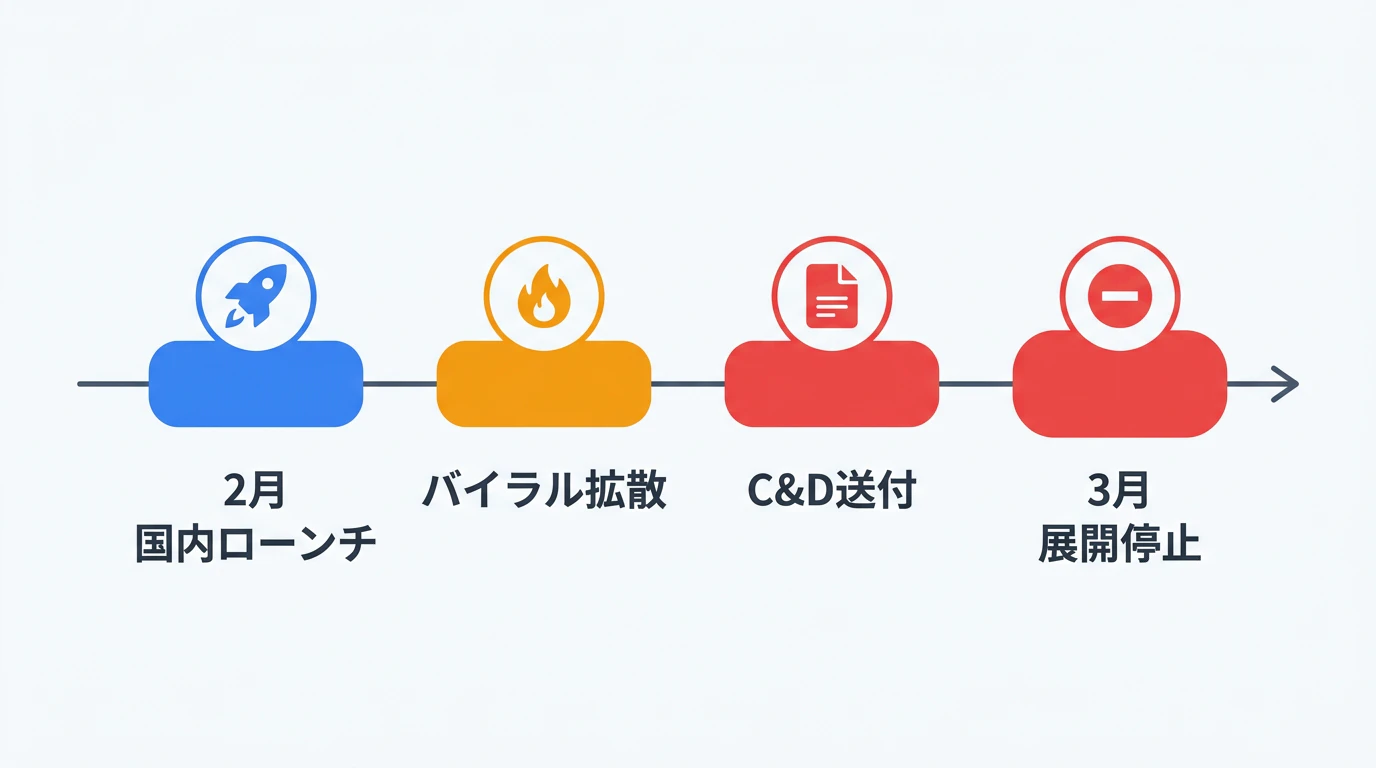
Seedance 2.0著作権危機の経緯
2026年2月:国内ローンチとバイラル拡散
ByteDanceは2026年2月にSeedance 2.0を中国国内で公開した。公開直後、Tom CruiseとBrad Pittの格闘シーン、Stranger Thingsの別エンディング、ThanosとSupermanが火星で戦うクロスオーバー動画など、著名な俳優やキャラクターを再現したAI生成動画がSNSでバイラル拡散した。
2026年2月中旬:ハリウッドの法的反撃
Disneyが最初にCease-and-Desist書簡を送付した。Disney側の主張によると、ByteDanceはSeedance 2.0を「Star Wars、Marvel、その他Disney作品の著作権キャラクターの海賊版ライブラリ」を搭載した状態で提供しており、「Disneyの貴重な知的財産をあたかもパブリックドメインのクリップアートのように扱った」と非難している。
Disney、Paramount、Warner Bros. Discovery、Netflix、Sony Pictures、さらにMPA(米国映画協会)がそれぞれCease-and-Desist書簡を送付。Spider-Man、Darth Vader、Grogu(Baby Yoda)、Peter Griffinなどのキャラクターが具体的に問題視された。
2026年2月下旬:ByteDanceの対応
ByteDanceはCNBCの取材に対し、IPセーフガードを追加すると表明した。具体的には、著作権キャラクターの検出・フィルタリング強化、実在人物の肖像を使った動画生成の制限・禁止、不可視ウォーターマークとコンテンツ追跡メカニズムの導入が予定されている。
2026年3月15日:グローバル展開の無期限停止
当初3月中旬に予定されていたグローバルAPI公開を含むすべての海外展開を無期限停止。法務チームとエンジニアがIPガードレールを構築するまで再開しない方針を発表した。中国国内では引き続き提供されている。
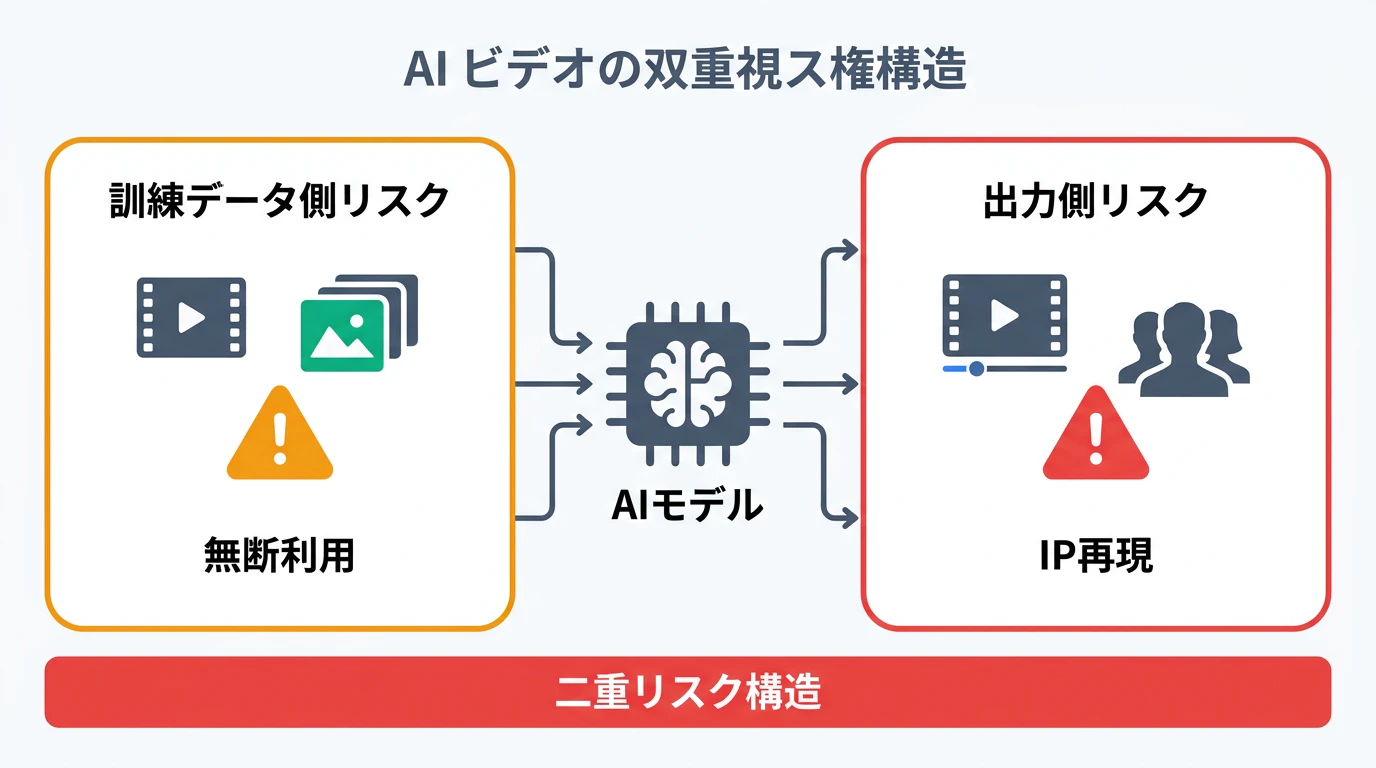
AI動画生成の著作権リスク構造
Seedance 2.0の事件は、AI動画生成における2つの異なる著作権リスクを浮き彫りにした。
リスク1:訓練データの著作権侵害(入力側)
AI動画生成モデルの訓練には大量の映像データが必要になる。Seedance 2.0に対するDisneyの主張は、訓練データにDisney作品が無断で含まれていたという点に基づいている。
この問題は業界全体に波及している。2025年8月には Anthropic が著作権侵害訴訟(Bartz v. Anthropic)で15億ドルの和解に合意した。海賊版サイトから約50万点の著作物をダウンロードして訓練に使用したとされ、米国著作権訴訟史上最大の和解金額となった(最終承認は2026年4月予定)。訓練データの合法性は、生成AIプロバイダにとって最大のリーガルリスクの一つである。
| 訴訟・事例 | 当事者 | 争点 |
|---|---|---|
| Disney vs ByteDance | Disney → ByteDance | Seedance 2.0の訓練データに著作権作品を無断使用 |
| Bartz v. Anthropic | 著作者 → Anthropic | 訓練用に海賊版コンテンツをダウンロード |
| Disney × OpenAI Sora | Disney ⇄ OpenAI | 200以上のキャラクターをSoraにライセンス供与(合法的な対比事例) |
注目すべきは、Disney自身がOpenAIのSoraに200以上のキャラクターをライセンス供与している点である。Disneyが問題視しているのは「無断利用」であり、ライセンスを取得すれば合法的にキャラクターを利用できるという構造になっている。
リスク2:生成物のIP再現(出力側)
訓練データが合法であっても、生成されたコンテンツが既存の著作物と「実質的に類似」(substantially similar)している場合、出力側で著作権侵害が成立しうる。
Seedance 2.0の事例では、ユーザーが「Tom Cruise vs Brad Pitt」というプロンプトを入力しただけで、両俳優のデジタル肖像が高精度で再現された。これはパブリシティ権(肖像権)の侵害にも該当する可能性がある。
Disney側の訴状では、「プラットフォームは暴力やポルノのプロンプトをブロックしているのに、著作権コンテンツの生成は何も防止していない」という 選択的ガードレール の問題が指摘されている。この論点は、コンテンツモデレーション設計に携わるエンジニアにとって特に重要である。
開発者の法的責任
米国における現行法の解釈
2026年3月時点の米国著作権法では、AI生成コンテンツの著作権侵害について以下の責任構造が成り立つとされている。
| 責任類型 | 対象 | 条件 |
|---|---|---|
| 直接侵害(Direct Infringement) | AI利用者 | 著作権侵害コンテンツの生成を指示するプロンプトを入力した場合 |
| 寄与侵害(Contributory Infringement) | AIプロバイダ | 侵害行為を知りながら実質的に助長した場合 |
| 代位侵害(Vicarious Infringement) | AIプロバイダ | 侵害行為を監督する権利・能力を持ち、直接的な経済的利益を得ている場合 |
重要な点として、 プロンプトを入力した利用者自身が直接侵害の責任を問われる可能性がある 。利用者が著作権侵害を意図していなくても、生成結果が既存作品と実質的に類似していれば責任が発生しうる。
米国最高裁の判断
2026年3月2日、米国最高裁はStephen Thalerの上告を棄却し、「人間の創作者なしに生成されたAI作品は著作権保護の対象外」とする下級審判決を維持した。これにより、AI生成コンテンツ自体は著作権で保護されない一方、既存の著作物を侵害するリスクは依然として存在するという非対称な状況が生じている。
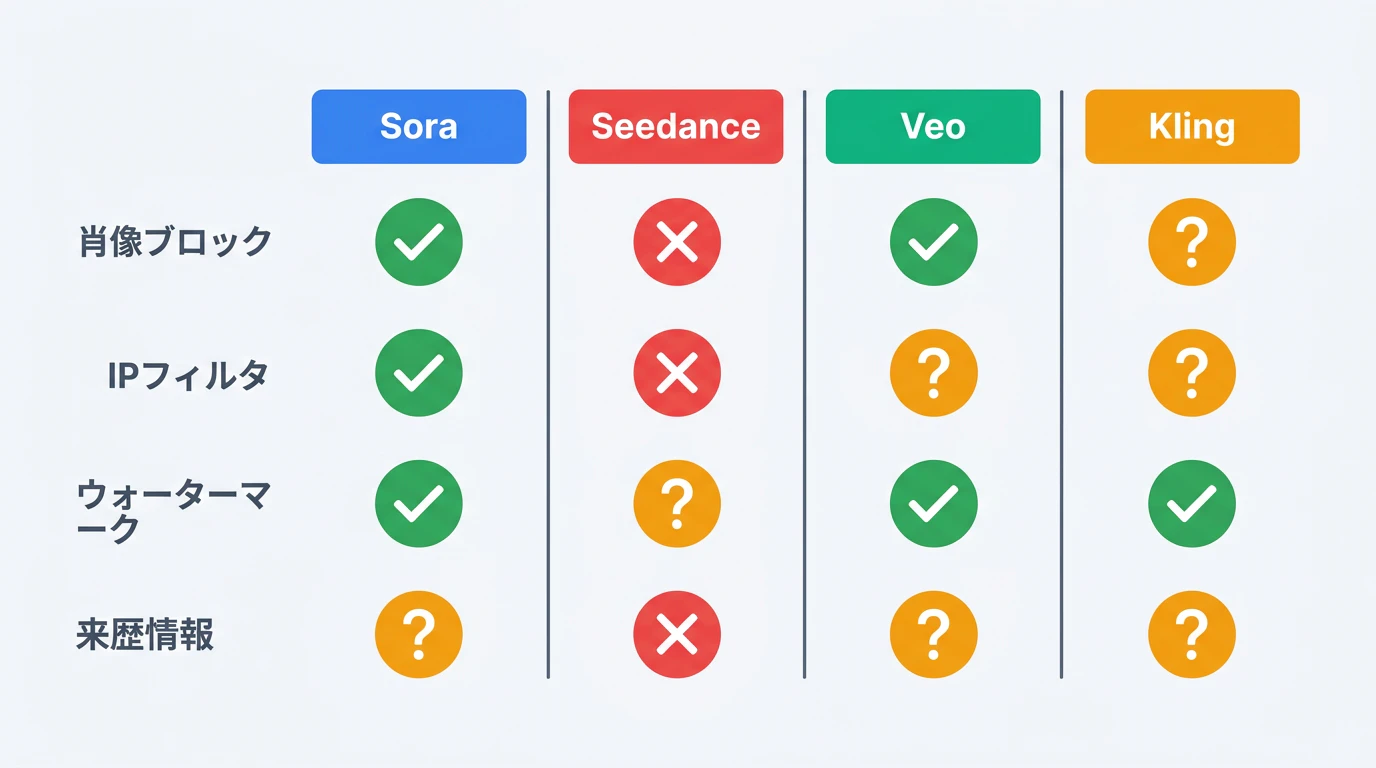
主要プロバイダのIPガードレール比較
Seedance 2.0の事件を受け、各AI動画生成プロバイダのIPガードレール対応を整理する。
| 項目 | OpenAI Sora | ByteDance Seedance 2.0 | Google Veo 3.1 | Kuaishou Kling 3.0 |
|---|---|---|---|---|
| 著名人肖像ブロック | あり | 導入予定(停止中) | あり | 一部あり |
| 著作権キャラフィルタ | あり(Disney 200+キャラはライセンス済) | 導入予定(停止中) | あり | 不明 |
| 不可視ウォーターマーク | C2PA対応 | 導入予定 | SynthID | 不明 |
| コンテンツ来歴情報 | C2PA準拠 | 未実装 | C2PA準拠 | 未実装 |
| APIレベルのセーフティ | セーフティフィルタ内蔵 | 海外API未提供 | セーフティ設定パラメータ | 基本フィルタ |
OpenAIはDisneyと正式なライセンス契約を締結し、200以上のキャラクターをSoraで利用可能にしている。これは「訓練データの合法的取得 + 出力の正式許諾」という二重の合法性を担保するアプローチであり、業界のベストプラクティスとなりつつある。
開発者が取るべき対策
AI動画生成APIを利用するプロダクトを開発する場合、以下の多層防御アプローチが推奨される。
対策1:プロバイダ選定時の確認事項
API選定時に以下のポイントを確認する。
チェックリスト:
□ 訓練データの合法性に関する公式見解があるか
□ コンテンツモデレーション(セーフティフィルタ)が組み込まれているか
□ 利用規約で著作権侵害の責任分界が明記されているか
□ C2PA / SynthID等のコンテンツ来歴技術に対応しているか
□ 生成コンテンツの商用利用条件が明確か
対策2:入力側のガードレール(プロンプトフィルタリング)
ユーザーからのプロンプトに対して、自社側でも著作権リスクの高いキーワードをフィルタリングする。
# プロンプトフィルタリングの基本構造(概念コード)
BLOCKED_PATTERNS = [
# 著名キャラクター名(主要スタジオ)
r"\b(spider-?man|darth vader|grogu|baby yoda|mickey mouse)\b",
# 著名人の氏名パターン
r"\b(tom cruise|brad pitt|taylor swift)\b",
# スタジオ・ブランド名
r"\b(disney|marvel|star wars|pixar|dc comics)\b",
# 映画・番組タイトル
r"\b(stranger things|avengers|frozen)\b",
]
import re
def check_prompt_ip_risk(prompt: str) -> dict:
"""プロンプトのIP侵害リスクを検出する"""
prompt_lower = prompt.lower()
risks = []
for pattern in BLOCKED_PATTERNS:
matches = re.findall(pattern, prompt_lower, re.IGNORECASE)
if matches:
risks.extend(matches)
return {
"has_risk": len(risks) > 0,
"matched_terms": risks,
"action": "block" if risks else "allow"
}
ただし、このアプローチには限界がある。ブロックリストは網羅的にはなりえず、婉曲表現(「クモの能力を持つヒーロー」など)を検出することは困難である。プロンプトフィルタリングは多層防御の一層として位置づけ、これだけに依存しないことが重要である。
対策3:出力側の検証
生成された動画コンテンツに対して、既知の著作権キャラクターや著名人の肖像が含まれていないかを検証する。
# 出力検証の概念的なアプローチ
def verify_output_ip_safety(video_path: str) -> dict:
"""生成動画のIP安全性を検証する"""
results = {
"watermark_present": check_synth_watermark(video_path),
"c2pa_metadata": extract_c2pa_provenance(video_path),
"face_detection": detect_known_faces(video_path),
"character_detection": detect_known_characters(video_path),
}
results["safe_for_distribution"] = (
not results["face_detection"]["matches"]
and not results["character_detection"]["matches"]
)
return results
顔認識APIやキャラクター検出モデルを組み合わせることで、出力側の自動検証パイプラインを構築できる。ただし、これらの検出精度は100%ではないため、高リスクなユースケースでは人間によるレビューを組み合わせることが望ましい。
対策4:利用規約と免責条項の設計
自社プロダクトの利用規約に以下を明記する。
- ユーザーが著作権侵害コンテンツを意図的に生成することを禁止する条項
- 生成コンテンツの著作権侵害に関する責任はユーザーに帰属する旨の免責条項
- DMCA(デジタルミレニアム著作権法)テイクダウン手続きの明示
- 違反者に対するアカウント停止ポリシー
対策5:コンテンツ来歴の記録
C2PA(Coalition for Content Provenance and Authenticity)やSynthIDなどのコンテンツ来歴技術を活用し、生成コンテンツのメタデータに「AI生成であること」を記録する。
{
"c2pa:manifest": {
"claim_generator": "MyApp/1.0",
"assertions": [
{
"label": "c2pa.actions",
"data": {
"actions": [
{
"action": "c2pa.created",
"digitalSourceType": "trainedAlgorithmicMedia",
"description": "Generated by AI video model via API"
}
]
}
}
]
}
}
YouTubeは2026年時点で、AI生成コンテンツの開示ラベルを義務化している。コンテンツ来歴情報を適切に付与することで、プラットフォームポリシーへの準拠と法的リスクの軽減を両立できる。
今後の展望
ライセンスモデルの標準化
Disney × OpenAI Soraのライセンス契約は、AIプロバイダと権利者の間の新しい共存モデルとして注目されている。今後、スタジオ側がAIプロバイダに対して標準的なライセンス条件を提示する動きが加速する可能性がある。
規制の動向
米国議会では生成AIと著作権に関する法案審議が進行中である。EUのAI Actでは高リスクAIシステムに対する透明性要件が2026年に段階的に施行される。開発者は各法域の規制動向を継続的にモニタリングする必要がある。
技術的対策の高度化
コンテンツ来歴技術(C2PA)、AIウォーターマーク(SynthID)、リアルタイム著作権検出モデルの精度向上により、技術的な知財保護の手段は充実しつつある。AIプロバイダ側のセーフティフィルタも、暴力・ポルノだけでなく著作権コンテンツのフィルタリングを標準機能として搭載する方向に向かっている。
まとめ
Seedance 2.0著作権危機は、AI動画生成技術の急速な発展と既存の知的財産権制度の衝突を象徴する事件である。開発者として押さえるべきポイントを整理する。
- 訓練データと出力物の二重リスク を認識すること。どちらか一方だけでなく、両方のレイヤーで著作権侵害が成立しうる
- 利用者にも法的責任が発生しうる という現行法の解釈を理解すること。「APIを呼んだだけ」では免責されない
- 多層防御 (プロバイダ選定 → プロンプトフィルタ → 出力検証 → 利用規約 → コンテンツ来歴)を実装すること
- ライセンスモデルの動向 を注視すること。Disney × Soraのような正式ライセンスが業界標準になる可能性がある
AI動画生成は強力な技術であるが、著作権リスクを無視したデプロイは法的・ビジネス上の重大なリスクとなる。技術的なガードレールと法務的な備えの両面から、責任あるAI活用の基盤を構築することが重要である。
参考リンク
- ByteDance reportedly pauses global launch of its Seedance 2.0 video generator — TechCrunch
- ByteDance Halts Global Seedance 2.0 Launch After Hollywood Legal Threats — Dataconomy
- Disney sends cease and desist letter to ByteDance over Seedance 2.0 — Axios
- Disney Blasts ByteDance With Cease And Desist Letter — Deadline
- ByteDance says it will add safeguards to Seedance 2.0 — CNBC
- Generative Artificial Intelligence and Copyright Law — Congress.gov
- AI-Generated Content and Copyright Law — Built In