はじめに
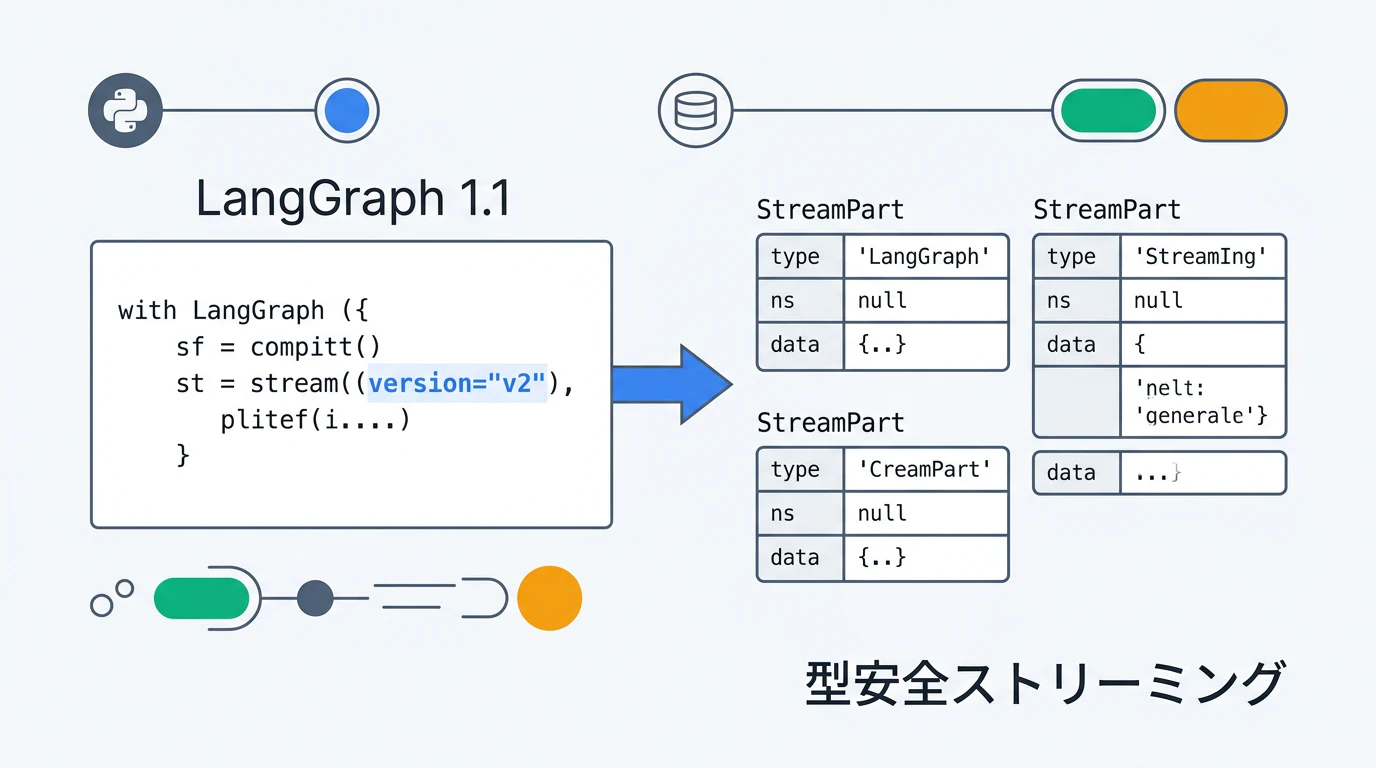
2026年3月10日、LangGraph 1.1 がリリースされました。最大の変更点は version="v2" によるオプトイン型安全ストリーミングです。
LangGraph 1.0 以前は、複数の stream_mode を同時指定したときに返ってくるチャンクの形式が不定で、型チェックや Pydantic モデルとの統合に苦労するケースがありました。1.1 では version="v2" を渡すだけで、すべてのストリームチャンクが統一された StreamPart 型に変換されます。
この記事で学べること
- LangGraph の基本アーキテクチャ(StateGraph / nodes / edges)
-
version="v2"型安全ストリーミングの仕組みと移行方法 -
invoke()の新しいGraphOutput型と割り込み情報の取得 - Pydantic モデルとの自動型強制変換
- 本番採用事例(Klarna・LinkedIn・Uber)
対象読者
- LangGraph を使っている / 使い始めたい Python エンジニア
- AIエージェントのストリーミングレスポンスを型安全に扱いたい方
- LangGraph 1.0 から 1.1 への移行を検討している方
前提環境
- Python 3.10 以上
pip install langgraph>=1.1.0
TL;DR
- LangGraph 1.1 の中心機能は
version="v2"によるオプトイン型安全ストリーミング -
stream()/invoke()の呼び出し時にversion="v2"を追加するだけで移行完了 - 破壊的変更なし — 既存コードはそのまま動く
- Pydantic / dataclass で状態スキーマを定義すると、v2 出力が自動的に型インスタンスに変換される
LangGraph の基本アーキテクチャ

LangGraph は LangChain から派生した、AIエージェントのワークフローを有向グラフで定義するフレームワークです。2025年10月に v1.0 が GA、2026年3月10日に v1.1 がリリースされました。PyPI でのステータスは Production/Stable です。
3 つの構成要素
StateGraph(グラフ)
エージェント全体のワークフローを表すオブジェクト。状態スキーマ(TypedDict または BaseModel)を受け取り、ノードとエッジを登録してグラフを定義します。
Node(ノード)
グラフの処理単位。通常の Python 関数や非同期関数として実装します。引数として現在の状態を受け取り、更新後の状態を返します。
Edge(エッジ)
ノード間の接続を定義します。3 種類あります。
| 種別 | 説明 |
|---|---|
| 通常エッジ | 固定の遷移先(add_edge) |
| 条件付きエッジ | 状態によって遷移先が変わる(add_conditional_edges) |
| START / END | グラフの入口と出口 |
最小実装例
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
class State(TypedDict):
messages: list[str]
def llm_call(state: State) -> dict:
# LLM への呼び出し処理
reply = "返答テキスト" # 実際は LLM API を呼び出す
return {"messages": state["messages"] + [reply]}
def should_continue(state: State) -> str:
if len(state["messages"]) >= 5:
return "end"
return "continue"
# グラフ構築
builder = StateGraph(State)
builder.add_node("llm_call", llm_call)
builder.add_edge(START, "llm_call")
builder.add_conditional_edges(
"llm_call",
should_continue,
{"continue": "llm_call", "end": END},
)
graph = builder.compile()
version="v1" の課題
LangGraph 1.0 では、複数の stream_mode を指定したときに返ってくるチャンクの形式が統一されていませんでした。
# v1 — 複数 stream_mode 指定時の型が不定
for chunk in graph.stream(
inputs,
stream_mode=["updates", "custom"],
):
# tuple が返る場合も、裸のデータが返る場合もある
# 型チェッカーは推論できない
print(type(chunk)) # バラバラ
この設計では、型アノテーションや isinstance() チェックが機能せず、Pydantic モデルで状態スキーマを定義していても、ストリーム出力時には素の dict に変換されてしまうという問題がありました。
version="v2" による型安全ストリーミング

StreamPart 統一フォーマット
version="v2" を指定すると、すべてのストリームチャンクが StreamPart という統一フォーマットの辞書で返されます。
# StreamPart の shape(常に固定)
{
"type": "values" | "updates" | "messages" | "custom" | "checkpoints" | "tasks" | "debug",
"ns": (), # サブグラフのネームスペース(タプル)
"data": ..., # ペイロード(type によって内容が異なる)
}
type フィールドによる Discriminated Union 設計なので、型チェッカーが data の型を正しく推論できます。
実装例
# v2 — 統一された StreamPart でチャンクを受け取る
for chunk in graph.stream(
inputs,
stream_mode=["updates", "custom", "messages"],
version="v2",
):
if chunk["type"] == "updates":
for node_name, state_update in chunk["data"].items():
print(f"ノード '{node_name}' が状態を更新:")
print(state_update)
elif chunk["type"] == "custom":
print(f"カスタムデータ: {chunk['data']}")
elif chunk["type"] == "messages":
msg, metadata = chunk["data"]
print(msg.content, end="", flush=True)
langgraph.types から各型をインポートして型アノテーションに活用できます。
from langgraph.types import (
ValuesStreamPart,
UpdatesStreamPart,
MessagesStreamPart,
CustomStreamPart,
CheckpointStreamPart,
TasksStreamPart,
DebugStreamPart,
StreamPart, # Union 型
)
invoke() の変更点 — GraphOutput と割り込み情報
v1 の問題
v1 の invoke() は素の dict を返していたため、ヒューマン・イン・ザ・ループ(Human-in-the-loop)処理で必要な割り込み情報が __interrupt__ という特殊キーとして通常の出力に混入していました。
# v1 — __interrupt__ が通常の状態と混在
result = graph.invoke(inputs)
if "__interrupt__" in result:
# 割り込み処理
pass
v2 の GraphOutput
version="v2" を使うと、invoke() は GraphOutput オブジェクトを返します。
# v2 — 構造化された GraphOutput
result = graph.invoke(inputs, version="v2")
# 実際の出力値
output_state = result.value # dict または Pydantic モデル
# 割り込み情報(存在しない場合は空リスト)
for interrupt in result.interrupts:
print(f"割り込みタイプ: {interrupt.value}")
# ユーザー確認や承認フローを挿入できる
割り込み情報が value と分離されたことで、ヒューマン・イン・ザ・ループ実装がシンプルになります。
Pydantic モデルとの自動型強制変換

状態スキーマに Pydantic BaseModel または dataclass を使用している場合、version="v2" では出力が自動的に宣言した型のインスタンスに変換されます。
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END
class AgentState(BaseModel):
query: str
results: list[str] = []
is_complete: bool = False
def search_node(state: AgentState) -> dict:
return {"results": ["結果1", "結果2"]}
def check_complete(state: AgentState) -> str:
return "end" if state.is_complete else "search"
builder = StateGraph(AgentState)
builder.add_node("search", search_node)
builder.add_edge(START, "search")
builder.add_conditional_edges("search", check_complete, {"search": "search", "end": END})
graph = builder.compile()
# v2 ストリーミング — AgentState インスタンスが返る
for chunk in graph.stream(
{"query": "LangGraph 最新情報", "results": [], "is_complete": True},
stream_mode="values",
version="v2",
):
state_data = chunk["data"]
assert isinstance(state_data, AgentState) # True
print(f"クエリ: {state_data.query}")
print(f"結果数: {len(state_data.results)}")
v1 では同じコードを書いても state_data は素の dict が返るため、.query のようなドット記法でのアクセスができませんでした。
v1 から v2 への移行手順
後方互換性があるため、移行は段階的に行えます。
ステップ 1: パッケージ更新
pip install "langgraph>=1.1.0"
ステップ 2: stream() に version="v2" を追加
既存の stream() 呼び出しに version="v2" を追加します。stream_mode が単一の文字列の場合も動作します。
# Before
for chunk in graph.stream(inputs, stream_mode="updates"):
print(chunk) # {"node_name": {...}} 形式
# After
for chunk in graph.stream(inputs, stream_mode="updates", version="v2"):
if chunk["type"] == "updates":
print(chunk["data"]) # 同じ内容
ステップ 3: invoke() を更新(必要な場合のみ)
割り込み処理を使っている場合は invoke() も更新します。単純な用途なら result.value でこれまでの result 相当の値が取得できます。
# Before
result = graph.invoke(inputs)
# After
output = graph.invoke(inputs, version="v2")
result = output.value # これまでと同じデータ
ステップ 4: 状態スキーマの型活用(オプション)
TypedDict から Pydantic に状態スキーマを移行すると、v2 の自動型変換の恩恵を受けられます。
# Before
class State(TypedDict):
messages: list[str]
# After(より型安全)
from pydantic import BaseModel
class State(BaseModel):
messages: list[str] = []
本番採用事例
LangGraph は 2026年3月時点で複数の企業が本番採用しています(公式ブログの事例情報に基づきます)。
| 企業 | 用途 | 公開されている成果 |
|---|---|---|
| Klarna | 8,500 万ユーザー向けカスタマーサポート AI | 解決時間 80% 削減 |
| 採用担当向け AI リクルーター、SQL Bot | — | |
| Uber | 5,000 人エンジニア向けコード移行・テスト生成ツール | 数億行規模のコードに対応 |
| AppFolio | 物件管理コパイロット Realm-X | 週 10 時間以上の工数削減 |
| Elastic | リアルタイム脅威検出 AI エージェント | — |
注意点
version="v1" がデフォルトのまま
現時点では version="v2" はオプトインです。既存コードは何も変えなくても動き続けます。将来のメジャーバージョンでデフォルトが変わる可能性についての公式アナウンスは 2026年3月時点では出ていません。
GraphOutput の dict アクセスは非推奨
result = graph.invoke(inputs, version="v2") の戻り値は GraphOutput オブジェクトですが、後方互換のため result["key"] のような dict 形式アクセスも一応できます。ただし非推奨警告が出るため、result.value["key"] の形式に移行することを推奨します。
Python 3.10 以上が必要
LangGraph 1.1 は Python 3.10 以上をサポートします。3.9 以下の環境ではアップグレードが必要です。
まとめ
- LangGraph 1.1 は 2026年3月10日リリース。破壊的変更なし
-
version="v2"を追加するだけで、ストリームチャンクがStreamPart統一フォーマットに変換される - Pydantic / dataclass で状態スキーマを定義していれば、v2 出力が自動的に型インスタンスに変換される
-
invoke()の戻り値がGraphOutputになり、割り込み情報がinterruptsフィールドに分離される - 既存コードはそのまま動くため、段階的な移行が可能
型安全なストリーミングはエージェントのデバッグと保守性を大幅に向上させます。既存の LangGraph プロジェクトがあれば、version="v2" を試してみることをおすすめします。