はじめに
2026年2月5日、OpenAIは GPT-5.3-Codex をリリースしました。これは単なるコード補完ツールではなく、ソフトウェア開発ライフサイクル全体を自律的にこなせるエージェント型AIです。
最大の特徴は「自分自身のトレーニングに参加した初のモデル」であること。Codexチームが初期版を使って自らのトレーニングのデバッグ、デプロイ管理、テスト評価を行いました。AIが次世代AIの開発を支援するという、新しい時代の始まりとも言えます。
この記事で解説すること
- GPT-5.3-Codexの主な特徴とベンチマーク性能
- 従来モデル(GPT-5.2-Codex)・後継(GPT-5.4)との違い
- Python APIを使った基本実装
- ツール呼び出し・エージェント活用のサンプルコード
- 料金・コンテキスト長・利用可能な環境
対象読者
- OpenAI APIを使って開発しているエンジニア
- Codexシリーズの最新動向を把握したい方
- AIエージェントを本番環境に導入検討中の方
前提環境
- Python 3.10 以上
- OpenAI Python SDK(
openaiパッケージ) - OpenAI APIキー(有料プラン)
TL;DR
- GPT-5.3-Codex はコーディング × エージェントを融合した OpenAI の最強モデル(2026-02-05リリース)
- SWE-Bench Pro 56.8%、Terminal-Bench 2.0 77.3%、OSWorld-Verified 64.7% を達成
- モデルID は
gpt-5.3-codex、最大 400K トークンコンテキスト、128K トークン出力 - ツール呼び出し対応・推論 effort 設定で「どれだけ深く考えるか」を制御可能
- Cursor・VS Code にネイティブ統合済み
- 純粋なコーディング性能では後継の GPT-5.4 より Terminal-Bench 2.0 で優位
GPT-5.3-Codex とは
概要
GPT-5.3-Codexは、前世代の GPT-5.2-Codex(コーディング特化)と GPT-5.2(汎用推論)を1つのモデルに統合した設計になっています。OpenAIの公式アナウンスによると、前世代比で 25% 高速化しつつ両方の強みを引き継いでいます。
| 項目 | 仕様 |
|---|---|
| モデルID | gpt-5.3-codex |
| コンテキスト長 | 400,000 tokens |
| 最大出力 | 128,000 tokens |
| 知識カットオフ | 2025年8月31日 |
| 推論 effort | low / medium / high / xhigh |
| ツール呼び出し | 対応 |
「自己訓練参加」という画期的な特徴
GPT-5.3-Codexは、OpenAIが Preparedness Framework において初めて「サイバーセキュリティに関してHigh capability」と分類したモデルです。ソフトウェア脆弱性を特定する能力が特に高く、Codexチームはこの特性を逆用し、早期バージョンで自らのトレーニングコードのデバッグ・デプロイ管理・評価診断を行いました。
"GPT-5.3-Codex is OpenAI's first model that was instrumental in creating itself."
— OpenAI公式ブログ
ベンチマーク性能
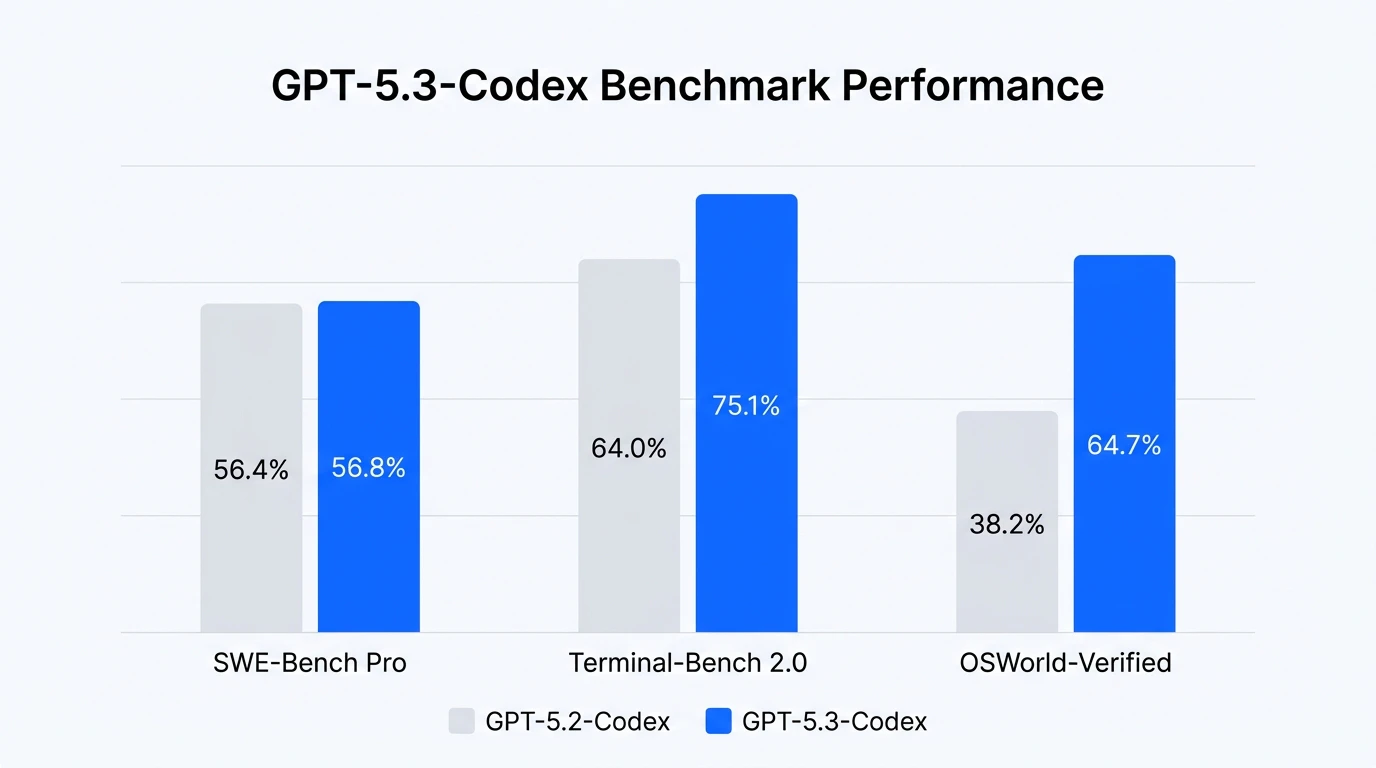
主要ベンチマーク比較
| ベンチマーク | GPT-5.2-Codex | GPT-5.3-Codex | 改善幅 |
|---|---|---|---|
| SWE-Bench Pro | 56.4% | 56.8% | +0.4pp |
| Terminal-Bench 2.0 | 64.0% | 77.3% | +13.3pp |
| OSWorld-Verified | 38.2% | 64.7% | +26.5pp |
ベンチマークの解説
- SWE-Bench Pro: Python・TypeScript・Java・Go など4言語にわたるソフトウェアエンジニアリングタスク。SWE-Bench Verifiedより難易度が高く汚染耐性も強い
- Terminal-Bench 2.0: ターミナル操作・CLIを使った実世界タスク。エージェントとしての端末操作能力を測定
- OSWorld-Verified: デスクトップ環境での実際のコンピュータ操作タスク。OSWorld-Verifiedは最も実世界に近い評価指標
Terminal-Bench 2.0 での+13.3ppの向上は特筆に値します。GPT-5.4(75.1%)がリリースされた後も、GPT-5.3-Codex(77.3%)はこの指標では+2.2pp優位に立っています(NxCode比較記事参照)。
Python API 実装ガイド
インストール
pip install openai
基本的な使い方
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.chat.completions.create(
model="gpt-5.3-codex",
messages=[
{
"role": "system",
"content": "You are an expert software engineer. Answer concisely and provide working code."
},
{
"role": "user",
"content": "Write a Python function to find all duplicate elements in a list."
}
]
)
print(response.choices[0].message.content)
推論 effort の設定
GPT-5.3-Codexは reasoning_effort パラメータで思考の深さを制御できます。
response = client.chat.completions.create(
model="gpt-5.3-codex",
reasoning_effort="high", # low / medium / high / xhigh
messages=[
{
"role": "user",
"content": "このコードのセキュリティ脆弱性を分析してください:\n\n```python\ndef login(username, password):\n query = f\"SELECT * FROM users WHERE username='{username}' AND password='{password}'\"\n return db.execute(query)\n```"
}
]
)
xhigh に設定すると最も深い推論が行われますが、トークン消費量も増加します。単純なコード補完なら low、セキュリティ監査やアーキテクチャ設計なら high / xhigh が適切です。
ツール呼び出し(Function Calling)
GPT-5.3-Codexはツール定義に対応しており、外部APIやデータソースと連携するエージェントを構築できます。
import json
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
# ツール定義
tools = [
{
"type": "function",
"function": {
"name": "run_tests",
"description": "指定されたPythonファイルのユニットテストを実行する",
"parameters": {
"type": "object",
"properties": {
"file_path": {
"type": "string",
"description": "テスト対象のPythonファイルパス"
},
"test_framework": {
"type": "string",
"enum": ["pytest", "unittest"],
"description": "使用するテストフレームワーク"
}
},
"required": ["file_path"]
}
}
}
]
# エージェントループ
messages = [
{
"role": "user",
"content": "src/utils.py のテストを実行して、失敗があれば修正コードを提案してください。"
}
]
response = client.chat.completions.create(
model="gpt-5.3-codex",
reasoning_effort="medium",
tools=tools,
tool_choice="auto",
messages=messages
)
# ツール呼び出しの処理
if response.choices[0].message.tool_calls:
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
print(f"ツール呼び出し: {tool_call.function.name}")
print(f"引数: {args}")
エージェントとしての活用シナリオ
GPT-5.3-Codexは「コードを書く」だけでなく、ソフトウェア開発ライフサイクル全体に対応しています。OpenAI公式ブログでは以下のユースケースが挙げられています。
開発ライフサイクル全体をカバー
| カテゴリ | 具体的なタスク |
|---|---|
| コーディング | 機能実装、リファクタリング、コードレビュー |
| デバッグ | バグ特定、根本原因分析、修正提案 |
| デプロイ | CI/CD設定、インフラコード生成、環境構築 |
| テスト | テストケース生成、カバレッジ分析 |
| ドキュメント | README作成、API仕様書生成 |
| セキュリティ | 脆弱性スキャン、セキュアコーディング提案 |
| データ分析 | スプレッドシート分析、レポート生成 |
コーディング以外の活用
公式情報によると、GPT-5.3-Codexはコードに限らず「スライドデッキ作成」「データシート分析」なども対応しています。Terminal-Bench 2.0での+26.5ppの大幅向上は、ターミナル経由でのファイル操作・コマンド実行・Webブラウジングなどの複合タスクに対応できるようになったことを示しています。
料金・プランについて
注意: 料金は変動する可能性があります。最新情報はOpenAI公式料金ページで確認してください。
2026年3月時点の情報をもとにした参考値:
| 料金項目 | 参考値 |
|---|---|
| 入力トークン | $1.75 / 1M tokens |
| 出力トークン | $14.00 / 1M tokens |
OpenRouter でも同じ料金が確認されています。最新情報は必ずOpenAI公式料金ページで確認してください。
ChatGPT サブスクリプションでの利用: Plus($20/月)・Pro($200/月)・Business($30/ユーザー/月)に含まれます。クレジット上限を超えた場合は追加購入が可能です。
GPT-5.4との使い分け
GPT-5.4(2026-03-05リリース)はGPT-5.3-Codexの後継として、コーディング性能を引き継ぎつつ汎用推論を強化しました。以下の基準で使い分けるのが適切です。
| 判断基準 | GPT-5.3-Codex | GPT-5.4 |
|---|---|---|
| ターミナル操作が多い | 推奨 | 可 |
| 純粋なコーディング | 推奨 | 可 |
| 入力コスト重視 | 推奨(安い) | ― |
| 汎用的な推論タスク | ― | 推奨 |
| Computer Use(GUI操作) | ― | 推奨 |
| Tool Search | ― | 推奨 |
GPT-5.3-Codex(77.3%)はTerminal-Bench 2.0でGPT-5.4(75.1%)を上回っており、CLI・エージェント・コーディング特化のワークロードでは現時点でもベストな選択肢です。
Cursor / VS Code でのネイティブ統合
GPT-5.3-Codexは Cursor と VS Code(GitHub Copilot 経由)にネイティブ統合されています(2026年2月9日より一般提供)。IDE内から直接利用でき、コードベース全体のコンテキストを保ちながらエージェント的なタスクを実行できます。
Codex CLI での利用例:
# Codex CLIインストール
npm install -g @openai/codex
# エージェントタスク実行
codex --model gpt-5.3-codex "src/utils.py のバグを特定して修正してください"
注意点
- APIアクセス: 2026年3月時点で段階的に展開中。利用可能かどうかはOpenAI Playgroundで確認してください(community.openai.com)
- 知識カットオフ: 2025年8月31日。それ以降の情報はWebSearchツール等で補完が必要
-
コスト管理: xhigh reasoning effortはトークン消費が多くなるため、バッチ処理では
lowまたはmediumを基本に
まとめ
GPT-5.3-Codexは、コーディングとエージェント機能を融合させたOpenAIの中核モデルです。
- Terminal-Bench 2.0 77.3%: ターミナル操作・CLI作業の実用性は現行最高水準(GPT-5.4の75.1%を上回る)
- OSWorld-Verified 64.7%: 前世代比+26.5ppの大幅改善でリアルワールドタスクに強い
- 自己訓練参加: AIがAIの開発を支援する新時代を象徴するマイルストーン
- 25%高速化: GPT-5.2-Codexより速く、同等以上の性能
純粋なコーディング・エージェントワークロードでは、後継のGPT-5.4が登場した現在でも GPT-5.3-Codex は有力な選択肢です。特にコスト効率とターミナル操作性能を重視する場合は積極的に採用できます。
参考リンク
- Introducing GPT-5.3-Codex | OpenAI — 公式発表(2026-02-05)
- GPT-5.3-Codex System Card | OpenAI — セキュリティ評価・能力評価詳細
- GPT-5.3-Codex Model | OpenAI API Docs — APIリファレンス
- Pricing | OpenAI — 最新料金
- GPT-5.3 Codex: From Coding Assistant to General Work Agent | DataCamp — 詳細解説記事
- GPT-5.3-Codex - OpenRouter — API料金参考