はじめに
AIエージェントの多くはクラウドAPIに依存しているが、プライバシー・レイテンシ・コストの観点から「ローカルで動くエージェント」への需要が高まっている。2026年3月、Stanford大学のScaling Intelligence Lab(Stanford SAIL)が公開した OpenJarvis は、この課題に正面から取り組むオープンソースフレームワークだ。
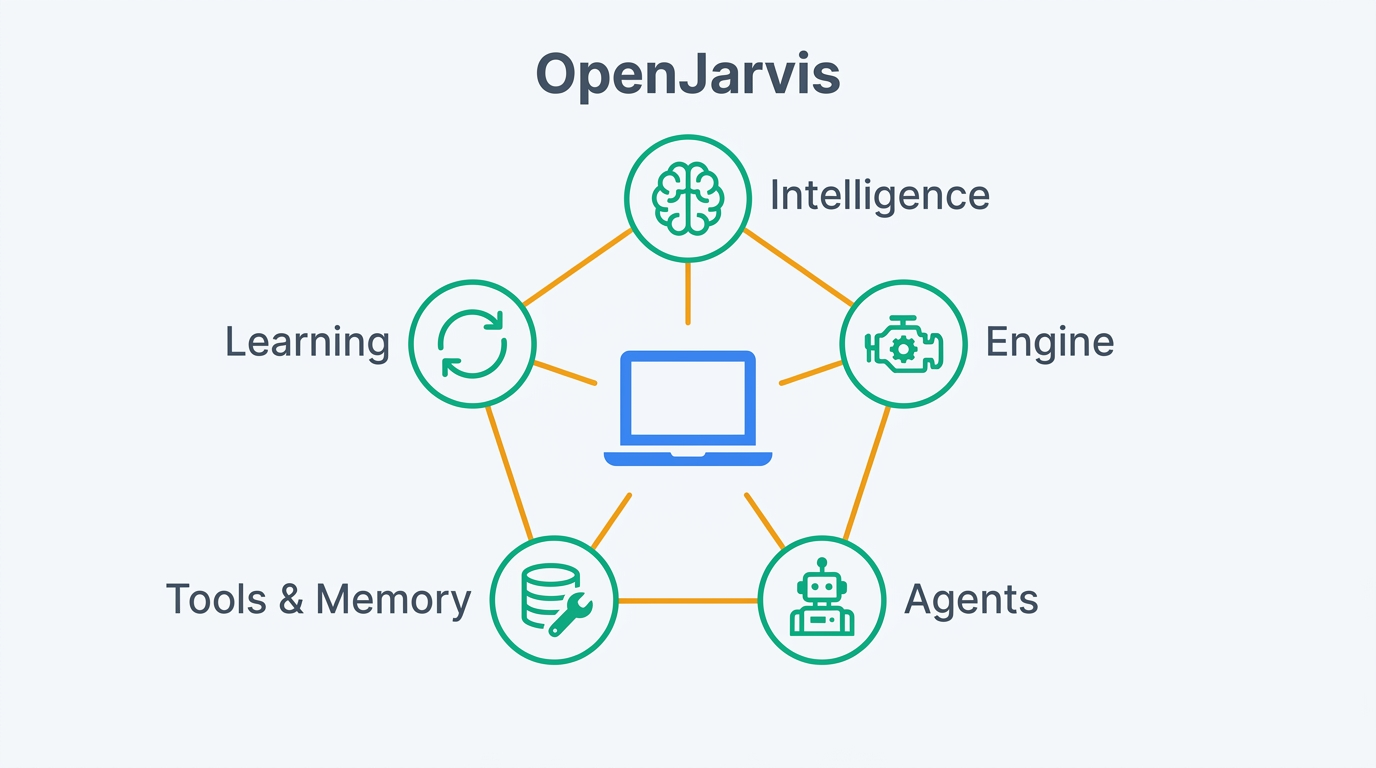
OpenJarvisは「Personal AI, On Personal Devices」をコンセプトに、5つのコアプリミティブで構成されるモジュラー設計を採用している。MCP(Model Context Protocol)やA2A(Agent-to-Agent)といった標準プロトコルにも対応しており、ローカル推論をデフォルトとしつつ、必要に応じてクラウドにフォールバックする柔軟なアーキテクチャが特徴だ。
この記事で学べること
- OpenJarvisの5プリミティブ設計と各コンポーネントの役割
- セットアップからPython SDKによるエージェント構築までの手順
- MCP/A2Aプロトコル対応の仕組み
- ローカルLLMが処理可能なクエリ範囲と性能特性
対象読者
- ローカルファーストのAIエージェントに関心があるエンジニア
- プライバシーを重視したAIシステムを構築したい開発者
- MCP/A2Aエコシステムとの統合を検討しているチーム
TL;DR
- OpenJarvisはStanford SAILが公開したローカルファーストのAIエージェントフレームワーク
- Intelligence・Engine・Agents・Tools & Memory・Learningの5プリミティブで構成され、各コンポーネントを独立に差し替え可能
- Ollama・vLLM・MLX・llama.cppなど8種以上の推論バックエンドに対応し、ハードウェアを自動検出して最適なエンジンを選択
- MCP・A2A対応により、外部ツール連携やエージェント間通信が標準プロトコルで実現可能
- Stanford SAILの研究によると、ローカルLLMは単一ターンのチャット・推論クエリの88.7%を対話的なレイテンシで処理可能
OpenJarvisの5プリミティブ設計
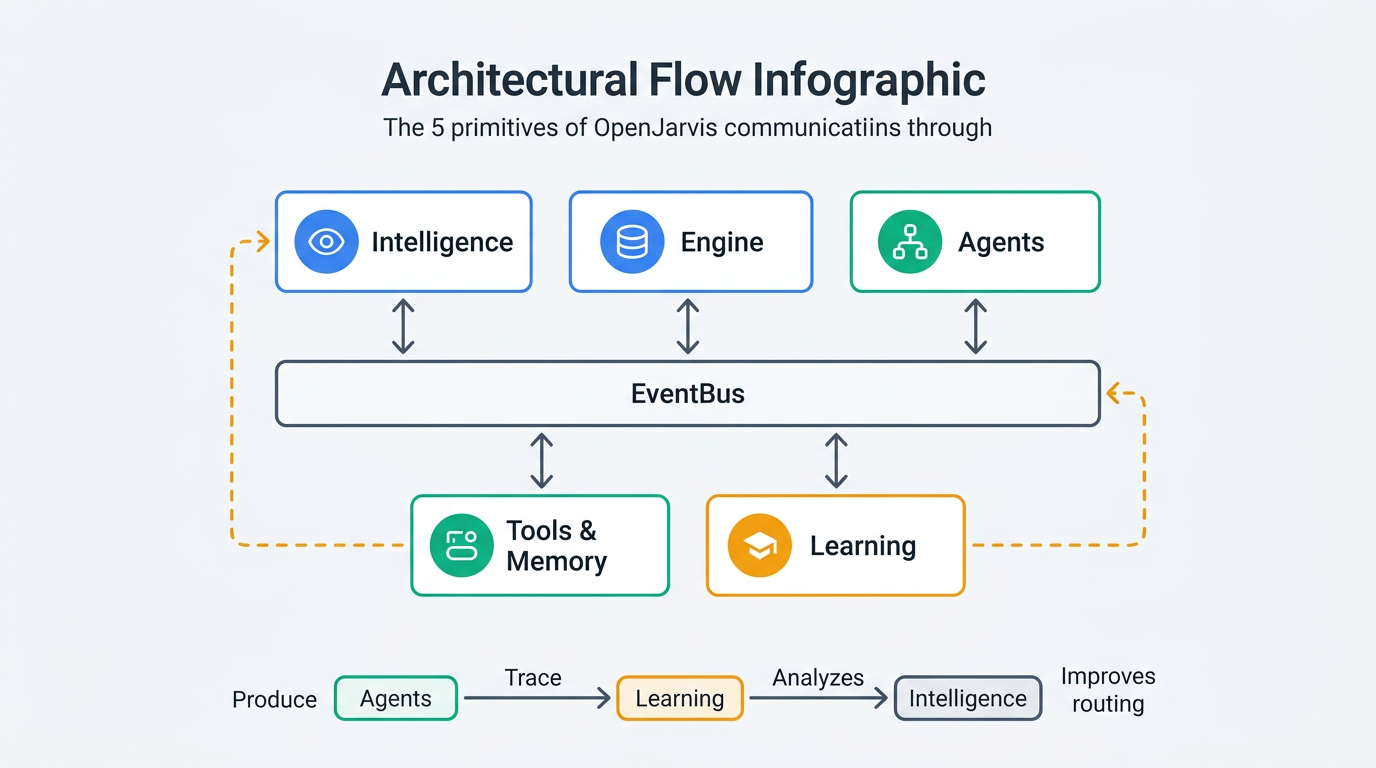
OpenJarvisのアーキテクチャは、5つの独立したプリミティブ(抽象レイヤー)で構成されている。各プリミティブはデコレータベースのレジストリパターンで管理され、実行時に動的に発見・登録される設計だ。
1. Intelligence — モデルカタログ
Intelligenceプリミティブは、ローカルおよびクラウドのLLMメタデータを統合管理するモデルカタログだ。パラメータ数、コンテキスト長、VRAM要件、量子化形式などのメタデータを保持し、実行中のエンジンから発見されたモデルは ModelRegistry に自動マージされる。
# IntelligenceConfigの概要
# モデルID、重みパス、量子化形式、推奨エンジン、
# フォールバックチェーン、生成パラメータ(temperature, max_tokens等)を定義
開発者がモデルごとのハードウェア適合性やメモリトレードオフを手動で管理する必要がなくなる点が、このプリミティブの価値だ。
2. Engine — 推論ランタイム
Engineプリミティブは InferenceEngine 抽象基底クラスを実装した推論ランタイム層だ。すべてのバックエンドが統一インターフェース( generate() 、 stream() 、 list_models() 、 health() )を実装するため、バックエンドの切り替えがコード変更なしで可能になる。
対応バックエンド一覧:
| バックエンド | 主な用途 | ハードウェア |
|---|---|---|
| Ollama | 汎用ローカル推論 | NVIDIA / AMD / Apple Silicon |
| vLLM | 高スループット推論 | NVIDIA GPU |
| SGLang | 構造化生成 | NVIDIA GPU |
| llama.cpp | CPU / 軽量推論 | x86 / ARM |
| MLX | Apple Silicon最適化 | Apple M系チップ |
| Exo | 分散推論 | 複数デバイス |
| LiteLLM | クラウドAPI統合 | - |
| Cloud APIs | OpenAI / Anthropic / Google | - |
エンジン発見機能は、登録済みバックエンドすべてにヘルスチェックを実行し、正常なエンジンをユーザー設定のデフォルト順でソートして返す。
3. Agents — エージェントロジック
Agentsプリミティブは、モデルの能力を構造化されたアクションに変換する振る舞いレイヤーだ。 BaseAgent 抽象基底クラスと ToolUsingAgent を軸に、9種類のエージェント実装が提供されている。
| エージェント | 用途 |
|---|---|
| SimpleAgent | 単純なQ&A |
| OrchestratorAgent | マルチステップタスクの分解・実行 |
| NativeReActAgent | ReAct(Reasoning + Acting)パターン |
| NativeOpenHandsAgent | コード実行特化 |
| ClaudeCodeAgent | Claude Code互換インターフェース |
| OperativeAgent | 操作タスク実行 |
| MonitorOperativeAgent | 監視 + 操作の組み合わせ |
| RLMAgent | 強化学習ベースのルーティング |
| SchedulerAgent | cron式の定期タスク実行 |
サンドボックスモジュールにより、Docker/Podmanでの隔離実行もサポートされている。
4. Tools & Memory — ツールと永続記憶
Toolsプリミティブは、Web検索・電卓・ファイルI/O・コードインタプリタ・MCPサーバー接続などの外部機能を提供する。Memoryプリミティブは5種類のストレージバックエンドを持つ永続的な文書検索システムだ。
メモリバックエンド:
| バックエンド | 方式 | 特徴 |
|---|---|---|
| SQLite/FTS5 | 全文検索 | デフォルト、依存関係ゼロ |
| FAISS | 密ベクトル検索 | 高速なセマンティック検索 |
| ColBERTv2 | 遅延相互作用 | 高精度な文書検索 |
| BM25 | 単語頻度ベース | クラシックな情報検索 |
| Hybrid | RRF融合 | 複数バックエンドの統合 |
ドキュメントのインジェスト、チャンク分割、エンベディング生成、そして agent.context_from_memory が有効な場合の自動コンテキスト注入までをパイプラインとして処理する。
5. Learning — トレースベース学習
Learningプリミティブは、他の4つのプリミティブを接続するフィードバックシステムだ。エージェントの全インタラクションから Trace を生成し、ルーティング判断・メモリ検索・推論呼び出し・ツール実行・最終応答の一連のステップを記録する。
TraceDrivenPolicy がトレースデータを分析し、クエリタイプごとに最適なモデル・エージェント・ツールの組み合わせを学習する。これにより、使い込むほどエージェントの性能が向上する閉ループが構成される。
学習手法としては、DSPyによるプロンプト最適化、GRPOトレーナー(強化学習)、SFTトレーナー(教師あり微調整)が利用可能だ。
セットアップ
動作環境
OpenJarvisはmacOS、Linux、Windowsで動作する。ハードウェア自動検出により、以下のプラットフォームに対応している。
- NVIDIA GPU: vLLM、RAPLエネルギー監視対応
- AMD GPU: エネルギー監視対応
- Apple Silicon: MLX、Apple FM shim対応
- x86 CPU: llama.cpp、Intel省電力監視対応
インストール手順
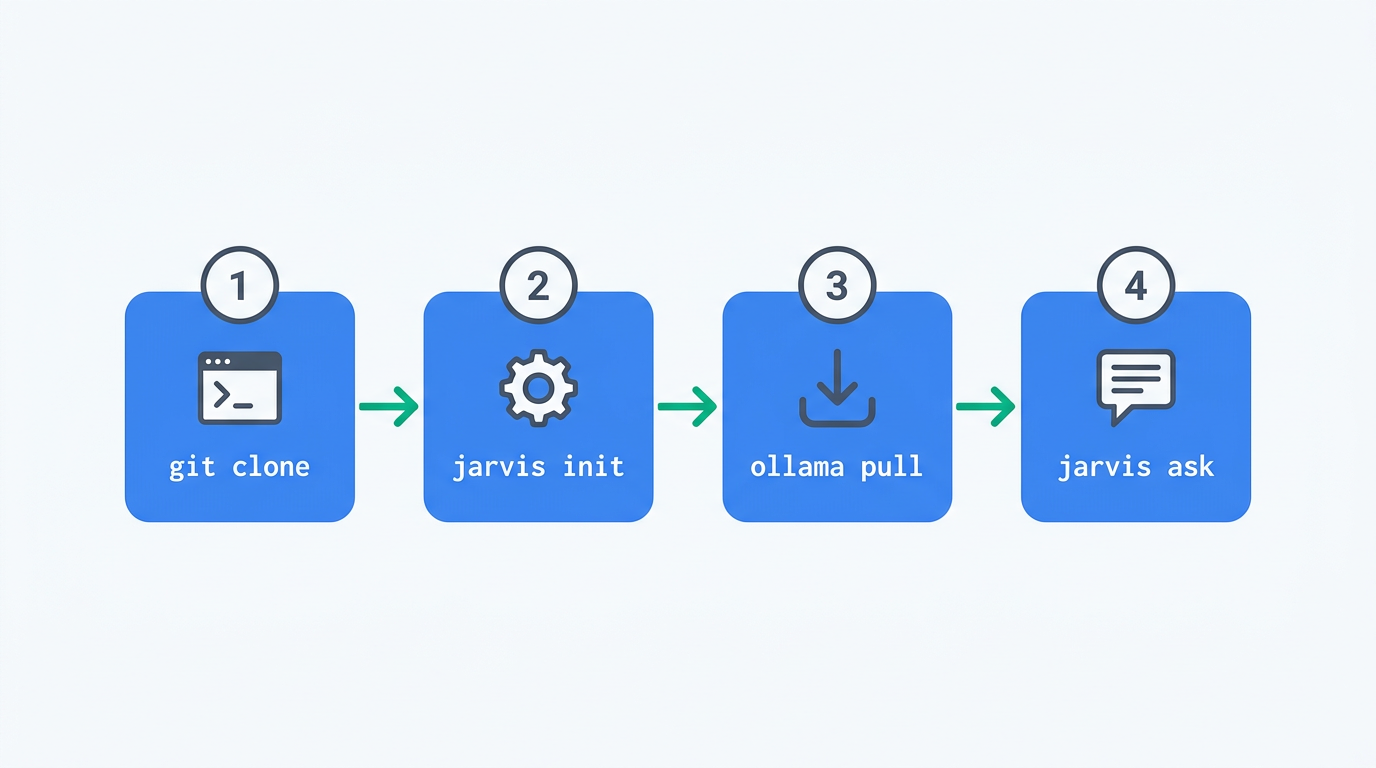
リポジトリのクローンと依存関係のインストールを行う。パッケージマネージャには uv を使用する。
git clone https://github.com/open-jarvis/OpenJarvis.git
cd OpenJarvis
uv sync
pip経由での簡易インストールも可能だ。
pip install open-jarvis
初期設定
jarvis init コマンドでハードウェアを自動検出し、最適な設定ファイルを生成する。
uv run jarvis init
このコマンドはGPUベンダー、モデル名、VRAM容量を検出し、推奨エンジンとモデルの組み合わせを自動設定する。設定に問題がある場合は jarvis doctor で診断できる。
uv run jarvis doctor
ローカルモデルのセットアップ(Ollama使用例)
Ollamaをインストールし、モデルをダウンロードする。
# Ollamaサーバーを起動
ollama serve
# モデルをダウンロード(例: Qwen3 8B)
ollama pull qwen3:8b
動作確認
CLI経由でクエリを実行する。
uv run jarvis ask "Pythonでクイックソートを実装する方法を教えてください"
エージェントとツールを指定した実行も可能だ。
uv run jarvis ask --agent orchestrator --tools calculator "100の階乗を計算してください"
Python SDKによるエージェント構築
基本的なクエリ実行
from openjarvis import Jarvis
# エンジンを自動検出してインスタンス生成
j = Jarvis()
# シンプルなクエリ
response = j.ask("クイックソートのアルゴリズムを説明してください")
print(response)
ツール付きエージェントの実行
ask_full() メソッドを使うと、ツール実行結果やモデル情報を含む詳細なレスポンスが得られる。
result = j.ask_full(
"東京の現在の天気を調べてください",
agent="orchestrator",
tools=["web_search"]
)
print(result["content"]) # エージェントの回答
print(result["tool_results"]) # ツール実行の詳細
print(result["model"]) # 使用モデル名
print(result["usage"]) # トークン使用量
OpenAI互換サーバー
jarvis serve コマンドで、OpenAI互換のFastAPIサーバーを起動できる。既存のOpenAIクライアントコードをそのまま流用可能だ。
uv run jarvis serve --port 8000
from openai import OpenAI
# OpenJarvisのローカルサーバーに接続
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
response = client.chat.completions.create(
model="qwen3:8b",
messages=[{"role": "user", "content": "Hello"}]
)
メモリの活用
ローカルドキュメントをインデックス化し、RAG(Retrieval-Augmented Generation)パターンでエージェントに知識を付与できる。
# ドキュメントをインデックス化
uv run jarvis memory index ./docs/
# インデックスからセマンティック検索
uv run jarvis memory search "デプロイ手順"
MCP・A2Aプロトコル対応
OpenJarvisは、AIエージェントエコシステムの2大標準プロトコルに対応している。
MCP(Model Context Protocol)
MCPは、AIモデルが外部ツールやデータソースにアクセスするための標準プロトコルだ。OpenJarvisはMCPのクライアント・サーバー・プロトコル・トランスポートの全モジュールを実装しており、既存のMCPサーバーをツールとして直接利用できる。
A2A(Agent-to-Agent)
A2AはGoogleが策定したエージェント間通信の標準プロトコルだ。OpenJarvisはA2Aのクライアント・サーバー実装を備えており、異なるフレームワークで構築されたエージェント同士の協調動作が可能になる。
MCP・A2Aの両方に対応することで、OpenJarvisのローカルエージェントは孤立せず、外部のクラウドエージェントやツールとシームレスに連携できる設計になっている。
チャネル統合
OpenJarvisは25以上のメッセージングプラットフォームとの統合をサポートしている。
Discord、Slack、Telegram、Microsoft Teams、WhatsApp、Email、Matrix、IRC、Signal、Mastodon、Reddit、Twitchなど、主要なコミュニケーションツールからエージェントを直接操作可能だ。
セキュリティ
ローカル実行のフレームワークとして、OpenJarvisはセキュリティにも注力している。
- クレデンシャルストリッピング: 出力からの認証情報自動除去
- インジェクションスキャン: プロンプトインジェクション検出
- SSRF防御: サーバーサイドリクエストフォージェリ対策
- ファイルポリシー: ファイルアクセス制御
- レート制限: APIレート制御
- サブプロセスサンドボックス: コード実行の隔離
- テイントトラッキング: データフロー追跡
パフォーマンス特性
Stanford SAILの「Intelligence Per Watt」研究では、ローカルLLMの実用性について定量的な評価が行われている。
- ローカルLLMは単一ターンのチャット・推論クエリの 88.7% を対話的レイテンシで処理可能
- Intelligence効率は2023年から2025年にかけて 5.3倍 改善
- OpenJarvisはエネルギー消費・FLOPs・レイテンシ・コストをアキュラシーと並ぶファーストクラスの評価指標として扱う
ベンチマークデータセットとして、GAIA、SWE-bench、TerminalBench、WebChoreArena、WorkArenaなどが利用可能だ。
クラウドエージェントとの使い分け
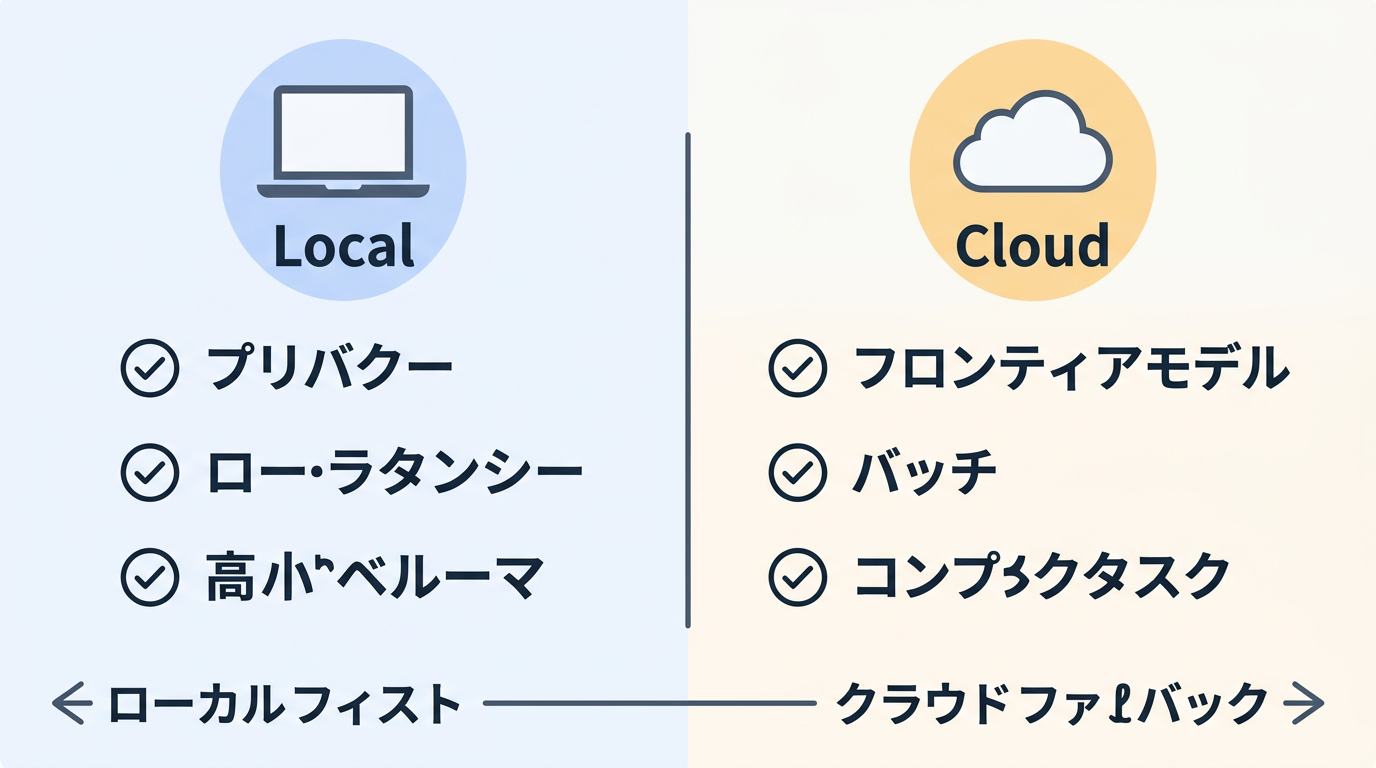
OpenJarvisはローカルファーストだが、クラウドを完全に排除するわけではない。LiteLLMバックエンドやCloud API対応により、ローカルモデルでは処理が困難なタスクをクラウドにフォールバックする設計が組み込まれている。
| 判断基準 | ローカル推奨 | クラウド推奨 |
|---|---|---|
| プライバシー | 機密データ処理 | 公開情報の分析 |
| レイテンシ | リアルタイム応答が必要 | バッチ処理 |
| コスト | 大量クエリ | 少量の高精度クエリ |
| モデル性能 | 8B〜70Bで対応可能 | 最先端モデルが必要 |
まとめ
OpenJarvisは、ローカルファーストのAIエージェント構築に必要な要素を5つのプリミティブとして体系化したフレームワークだ。
- Intelligence がモデルカタログを統合管理し、 Engine が8種以上のバックエンドを統一インターフェースで抽象化する
- Agents が9種類のエージェントパターンを提供し、 Tools & Memory が外部連携と永続記憶を担う
- Learning がトレースベースのフィードバックループで継続的に性能を改善する
- MCP・A2A対応により、ローカルエージェントが外部エコシステムと標準プロトコルで接続できる
ローカルLLMの性能向上(88.7%のクエリを処理可能、効率5.3倍改善)を踏まえると、「まずローカルで動かし、必要なときだけクラウドに頼る」というアプローチは現実的な選択肢になりつつある。プライバシー要件やコスト削減を重視するプロジェクトで、OpenJarvisの導入を検討する価値があるだろう。