はじめに
2026年3月17日、Mistral AIが Mistral Small 4 と Mistral Forge を同時発表した。Small 4は119Bパラメータの Mixture of Experts(MoE)モデルで、推論・マルチモーダル・コーディングの3系統を単一アーキテクチャに統合している。Apache 2.0ライセンスで公開され、API経由でもローカルでも利用できる。
Forgeはエンタープライズ向けのカスタムモデル訓練プラットフォームで、自社データによる事前学習からRLHFまでをワンストップで提供する。Ericsson、欧州宇宙機関(ESA)、シンガポールのDSOなどがすでにパートナーとして参画している。
この記事では、Small 4のアーキテクチャと性能、APIおよびローカルでの利用方法、そしてForgeの概要をまとめる。
この記事で学べること
- Mistral Small 4の128エキスパートMoEアーキテクチャの仕組み
- Python(OpenAI互換API)での推論・ツール呼び出し・画像入力の実装方法
- vLLMを使ったローカルデプロイ手順
- Mistral Forgeによるカスタムモデル訓練の概要
対象読者
- LLMのAPI利用やローカルデプロイに関心があるエンジニア
- オープンソースLLMの選定を検討している方
- エンタープライズ向けカスタムAI基盤を評価している方
TL;DR
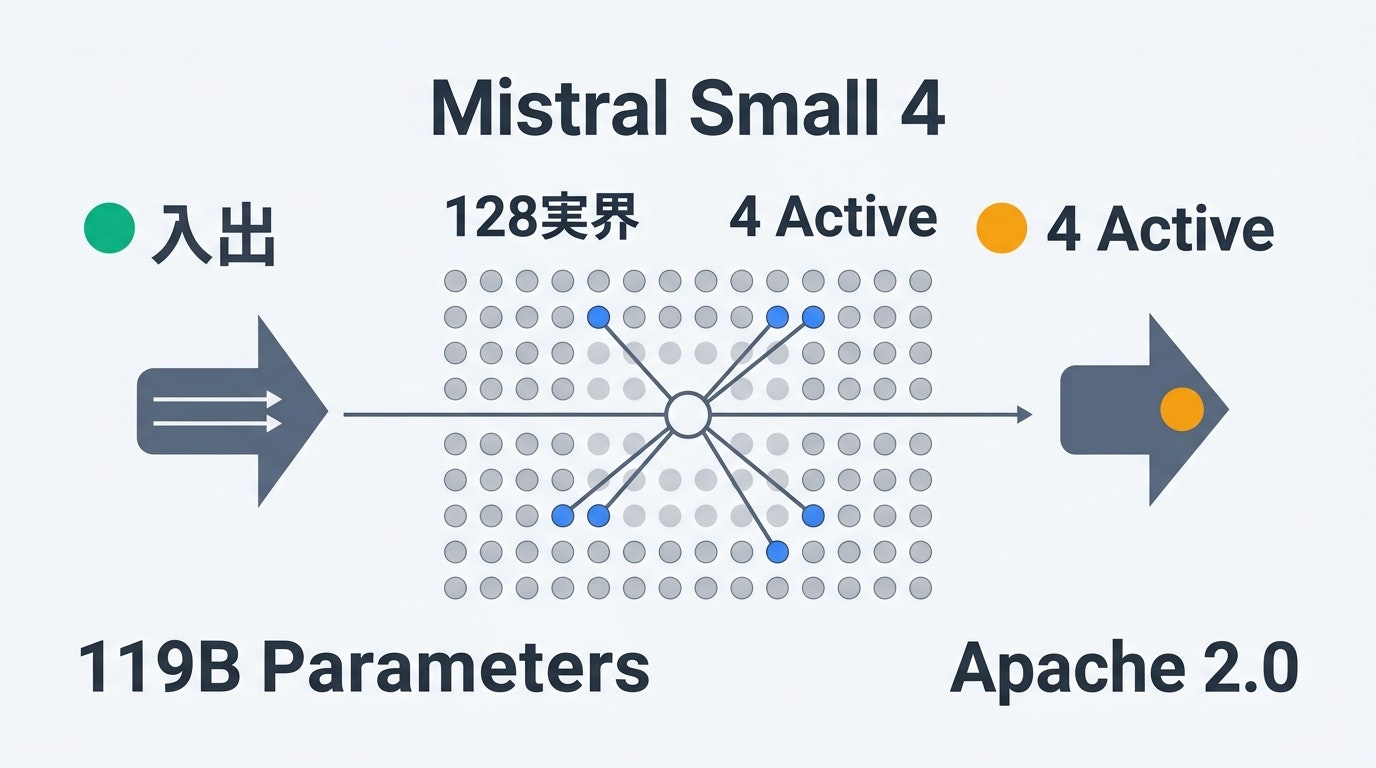
- Mistral Small 4: 119Bパラメータ / 128エキスパート / 4アクティブ(6Bアクティブパラメータ)のMoEモデル。256kコンテキスト対応
- 3モデル統合: Magistral(推論)+ Pixtral(マルチモーダル)+ Devstral(コーディング)を1つのアーキテクチャに統合
- 性能: Mistral Small 3比で遅延40%削減・スループット3倍。LiveCodeBenchでGPT-OSS 120Bを上回る
- 料金: $0.15 / 1M入力トークン、$0.60 / 1M出力トークン(API利用時)
- Mistral Forge: 自社データでのカスタムモデル訓練プラットフォーム。ASML、Ericsson、ESAなどが採用
Mistral Small 4のアーキテクチャ
MoE(Mixture of Experts)の基本構造
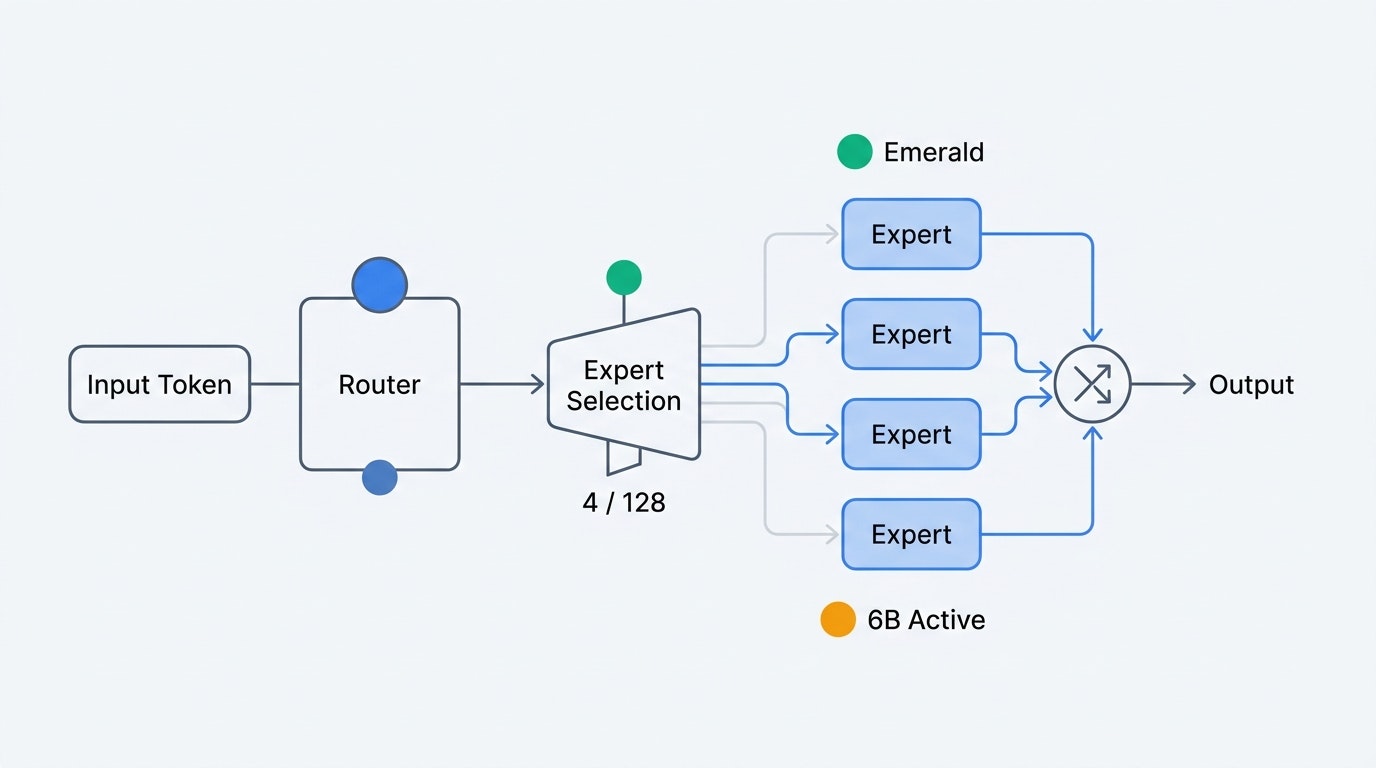
Mistral Small 4の最大の特徴は、128個のエキスパートモジュールを持つMoEアーキテクチャにある。各入力トークンに対して4つのエキスパートだけがアクティブになるため、総パラメータ数119Bに対してトークンあたりのアクティブパラメータは約6B(埋め込み・出力層を含めると8B)に抑えられる。
| 項目 | 値 |
|---|---|
| 総パラメータ数 | 119B |
| エキスパート数 | 128 |
| トークンあたりアクティブエキスパート | 4 |
| アクティブパラメータ(推論時) | 6B(埋め込み含む8B) |
| コンテキストウィンドウ | 256,000トークン |
| テンソル形式 | BF16, F8_E4M3 |
| ライセンス | Apache 2.0 |
MoEの利点は、密(dense)モデルと同等の品質を保ちつつ、推論コストとレイテンシを大幅に削減できることにある。Small 4は128個のエキスパートそれぞれが異なるタスク領域に特化しており、ルーティング機構がトークンごとに最適な4つを選択する。
3系統の統合
Small 4は、Mistral AIがこれまで個別に開発してきた3つのモデル系統を単一アーキテクチャに統合している。
| 統合元モデル | 担当領域 | Small 4での機能 |
|---|---|---|
| Magistral | 推論・論理思考 |
reasoning_effort パラメータで推論深度を制御 |
| Pixtral | マルチモーダル | テキスト+画像入力に対応 |
| Devstral | コーディング | コード生成・エージェントタスクに最適化 |
タスクの性質に応じて内部的にエキスパートの組み合わせが切り替わるため、ユーザーが明示的にモデルを使い分ける必要がない。これにより、Mistral Small 3比でエンドツーエンドの完了時間が40%短縮され、スループットは3倍に向上したとMistral AIは報告している。
ベンチマーク性能
主要ベンチマーク結果
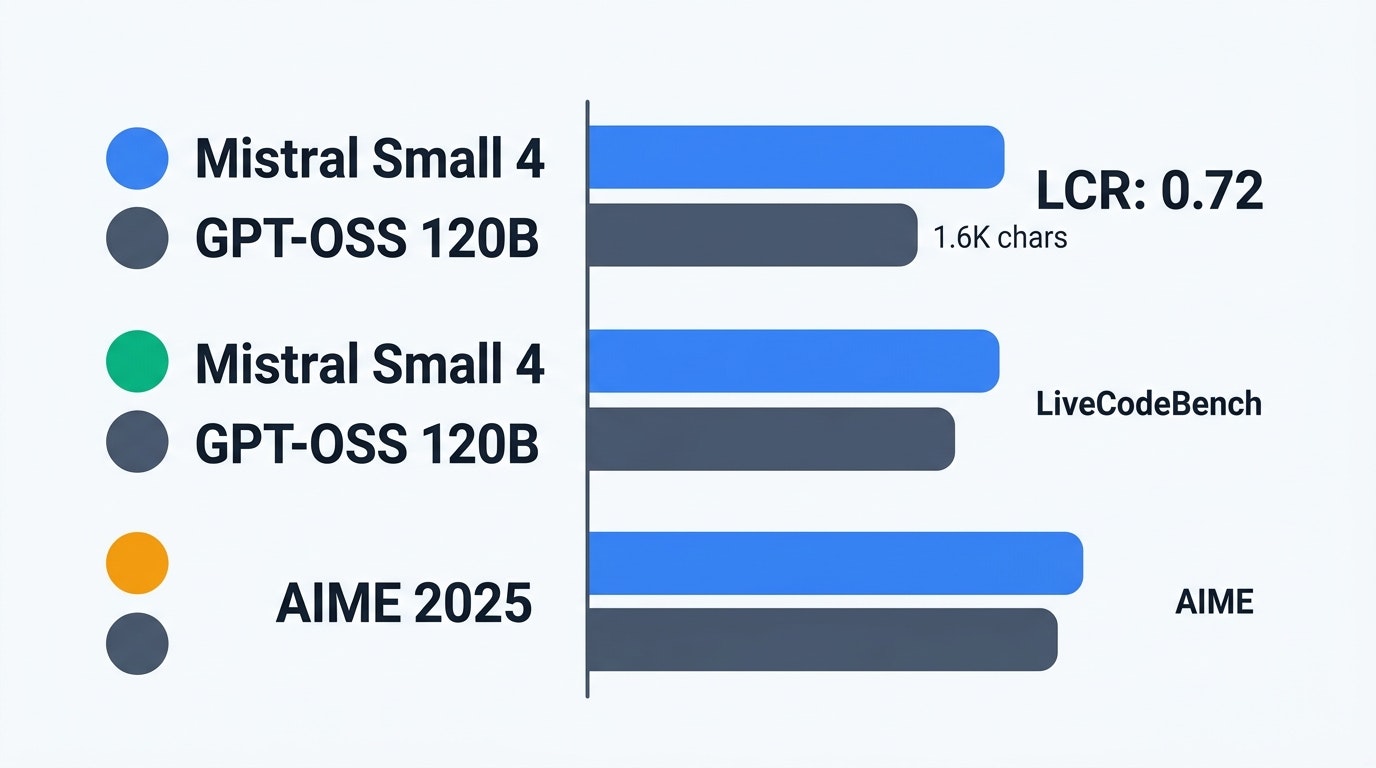
公式ブログおよびサードパーティの検証によると、Small 4は同規模のオープンソースモデルに対して競争力のある結果を出している。
| ベンチマーク | Mistral Small 4 | GPT-OSS 120B | 備考 |
|---|---|---|---|
| AA LCR(論理推論) | 0.72(出力1.6K文字) | 同等 | Qwenモデルは同等性能に5.8-6.1K文字を要する |
| LiveCodeBench | GPT-OSS 120Bを上回る | — | 出力量が20%少ない状態で達成 |
| AIME 2025 | GPT-OSS 120Bと同等以上 | — | — |
特筆すべきは出力効率である。Small 4は競合モデルより少ないトークン数で同等の精度を達成しており、API利用時のコスト効率に直結する。
推論努力の制御
reasoning_effort パラメータにより、レスポンスの速度と深度をトレードオフできる。
| 設定値 | 挙動 | 推奨温度 | ユースケース |
|---|---|---|---|
"none" |
高速応答(Small 3.2相当) | 0.0〜0.7(デフォルト0.1) | チャット、簡易タスク |
"high" |
深い推論(Magistral相当) | 0.7 | 数学、論理問題、コード設計 |
API料金とモデルID
料金体系
Mistral Small 4はMistral APIで即時利用可能である。
| 項目 | 料金 |
|---|---|
| 入力トークン | $0.15 / 1Mトークン |
| 出力トークン | $0.60 / 1Mトークン |
Claude Sonnet 4.6(入力 $3 / 出力 $15 per 1M)やGPT-5.4(入力 $2.50 / 出力 $15 per 1M)と比較すると、1桁以上安価な料金設定である。
モデルID
| プラットフォーム | モデルID |
|---|---|
| Mistral API |
mistral-small-2603 または mistral-small-latest
|
| HuggingFace | mistralai/Mistral-Small-4-119B-2603 |
| NVIDIA NIM | mistralai/mistral-small-4-119b-2603 |
PythonでのAPI利用
Mistral Small 4はOpenAI互換のAPIインターフェースを提供しているため、 openai ライブラリでそのまま利用できる。
基本的なチャット
from openai import OpenAI
client = OpenAI(
api_key="YOUR_MISTRAL_API_KEY",
base_url="https://api.mistral.ai/v1",
)
response = client.chat.completions.create(
model="mistral-small-latest",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "PythonでFibonacci数列を生成する関数を書いてください"},
],
temperature=0.1,
extra_body={"reasoning_effort": "none"},
)
print(response.choices[0].message.content)
推論モード(深い思考)
response = client.chat.completions.create(
model="mistral-small-latest",
messages=[
{"role": "user", "content": "以下の数学の問題を解いてください: ..."},
],
temperature=0.7,
extra_body={"reasoning_effort": "high"},
)
reasoning_effort="high" を指定すると、内部で思考チェーンを展開してから回答を生成する。数学・論理問題やアーキテクチャ設計の検討など、精度を優先するタスクに適している。
ツール呼び出し(Function Calling)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "指定都市の現在の天気を取得する",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "都市名(例: Tokyo)",
},
},
"required": ["city"],
},
},
},
]
response = client.chat.completions.create(
model="mistral-small-latest",
messages=[
{"role": "user", "content": "東京の天気を教えてください"},
],
tools=tools,
tool_choice="auto",
temperature=0.1,
)
tool_call = response.choices[0].message.tool_calls[0]
print(tool_call.function.name) # get_weather
print(tool_call.function.arguments) # {"city": "Tokyo"}
画像入力(マルチモーダル)
response = client.chat.completions.create(
model="mistral-small-latest",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "この画像に写っているものを説明してください",
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/photo.jpg"
},
},
],
},
],
temperature=0.3,
)
Pixtral系統の統合により、テキストと画像を同一のリクエストで処理できる。ドキュメント解析やUIスクリーンショットの読み取りなどに活用可能である。
vLLMによるローカルデプロイ
Apache 2.0ライセンスのため、自社サーバーへのデプロイも自由に行える。公式にはvLLMが推奨されている。
ハードウェア要件
| 構成 | GPU |
|---|---|
| 最小構成 | NVIDIA H100 x 4、H200 x 2、または DGX B200 x 1 |
| 推奨構成 | H100 x 4、H200 x 4、または B200 x 2 |
4bit量子化版( Mistral-Small-4-119B-2603-NVFP4 )を使用すれば、より少ないGPUメモリで動作させることも可能である。
vLLMでのサーバー起動
# 公式Dockerイメージを使用
docker pull mistralllm/vllm-ms4:latest
docker run --gpus all -p 8000:8000 mistralllm/vllm-ms4:latest
手動でセットアップする場合は以下の手順で起動する。
vllm serve mistralai/Mistral-Small-4-119B-2603 \
--max-model-len 262144 \
--tensor-parallel-size 2 \
--attention-backend FLASH_ATTN_MLA \
--tool-call-parser mistral \
--enable-auto-tool-choice \
--reasoning-parser mistral \
--max_num_batched_tokens 16384 \
--max_num_seqs 128 \
--gpu_memory_utilization 0.8
起動後は http://localhost:8000/v1 でOpenAI互換APIが利用できるため、前述のPythonコードの base_url を差し替えるだけで動作する。
高速化オプション
推論速度をさらに向上させるための公式オプションが2つ用意されている。
| オプション | HuggingFace リポジトリ | 効果 |
|---|---|---|
| Speculative Decoding | mistralai/Mistral-Small-4-119B-2603-eagle |
投機的デコーディングでレイテンシ削減 |
| 4bit量子化 | mistralai/Mistral-Small-4-119B-2603-NVFP4 |
GPU メモリ使用量を大幅に削減 |
Mistral Forge — エンタープライズ向けカスタムモデル訓練
Forgeの概要
Mistral Forgeは、企業が自社の独自データを使ってカスタムAIモデルを構築・改善するためのプラットフォームである。既存のファインチューニングサービスとは異なり、事前学習(pre-training)からpost-training、RLHFまでの全訓練ライフサイクルをカバーする。
主な機能
| 機能 | 説明 |
|---|---|
| フルスタック訓練 | 事前学習 → post-training → RLHFの全フェーズ対応 |
| MoE / Dense対応 | MoEアーキテクチャと密(dense)アーキテクチャの両方をサポート |
| エージェント連携 | 自律エージェントによるハイパーパラメータ探索・合成データ生成 |
| オンプレミス対応 | 自社GPUクラスタでの実行時はコンピュート費用不要(ライセンス料のみ) |
| Forward-Deployed Engineers | Mistralのエンジニアが顧客チームに常駐して支援 |
料金モデル
Forgeは従来のクラウドAIサービスとは異なる料金構造を採用している。
- オンプレミス利用: ライセンス料 + オプションのデータパイプライン / エンジニア支援費用(コンピュート費用なし)
- クラウド利用: 詳細は個別見積もり
Mistral AI CEOのArthur Menschによると、このエンタープライズ集中戦略により、同社は2026年中に年間経常収益(ARR)10億ドルの突破を見込んでいる。
採用パートナー
| パートナー | 業種 |
|---|---|
| ASML | 半導体製造装置 |
| Ericsson | 通信インフラ |
| 欧州宇宙機関(ESA) | 宇宙開発 |
| Reply | ITコンサルティング |
| DSO National Laboratories | 防衛研究(シンガポール) |
| HTX(Home Team Science and Technology Agency) | 公共安全技術(シンガポール) |
既存モデルとの使い分け
Mistral Small 4の位置づけを、主要なオープンソースLLMおよびプロプライエタリモデルと比較する。
| モデル | パラメータ | 特徴 | 料金(入力/出力 per 1M) |
|---|---|---|---|
| Mistral Small 4 | 119B(6B active) | MoE、推論+マルチモーダル+コーディング統合 | $0.15 / $0.60 |
| Devstral 2 | — | コーディング特化(SWE-bench 72.2%) | — |
| Llama 4 Maverick | 400B(17B active) | マルチモーダル、1Mコンテキスト | — |
| Claude Sonnet 4.6 | — | 汎用、長文コンテキスト | $3.00 / $15.00 |
| GPT-5.4 | — | Computer Use、Tool Search | $2.50 / $15.00 |
Small 4は「コスト効率の高いオープンソース汎用モデル」という位置づけにある。プロプライエタリモデルの1/10〜1/20の料金でありながら、推論・マルチモーダル・コーディングの3軸をカバーしている点が差別化要因である。
注意点
- ハードウェア要件: ローカルデプロイにはH100クラスのGPUが複数台必要であり、個人開発者にはAPI利用が現実的である
- Forge: 現時点では早期アクセスの段階であり、一般公開のスケジュールは未公表である
- 量子化版の精度: 4bit量子化(NVFP4)はメモリ削減に有効だが、一部タスクで精度低下の可能性がある。本番利用前の検証を推奨する
まとめ
Mistral Small 4は、128エキスパートMoEアーキテクチャにより、119Bパラメータモデルの品質を6Bアクティブパラメータのコストで実現したオープンソースLLMである。推論・マルチモーダル・コーディングの3系統を統合し、 reasoning_effort パラメータで速度と精度のトレードオフを制御できる。
Apache 2.0ライセンスでの公開、OpenAI互換API、vLLMによるローカルデプロイ対応と、開発者にとっての選択肢の幅が広い。エンタープライズ向けにはMistral Forgeが自社データによるカスタムモデル訓練を提供し、IBMやPalantirに近い「Forward-Deployed Engineers」モデルで顧客支援を行っている。
LLM選定において「コスト効率の高いオープンソース汎用モデル」を検討している場合、Small 4は有力な候補に入る。
参考リンク
- Mistral Small 4 公式発表 — Mistral AI公式ブログ
- Mistral-Small-4-119B-2603 — HuggingFace モデルカード
- Mistral Forge発表記事 — TechCrunch
- Mistral AI API Pricing — 料金ページ
- NVIDIA NIM Mistral Small 4 — NVIDIA NIMモデルカード