Exercise 1
First, we are going to finish boot_alloc(), it's pretty easy since the behavior of this function is described in the comment. What we need to know is that, because the kernel is located at virtual memory address KERNBASE, nextfree is always greater than KERNBASE. That is to say, to determine whether it is out of memory, we should compare the difference between nextfree and KERNBASE with the amount of physical memory it has. And here is my implemention:
// Allocate a chunk large enough to hold 'n' bytes, then update
// nextfree. Make sure nextfree is kept aligned
// to a multiple of PGSIZE.
result = nextfree;
if (n > 0) {
nextfree = ROUNDUP(nextfree + n, PGSIZE);
if (((uint32_t) nextfree - KERNBASE) > (npages * PGSIZE)) {
panic("boot_alloc: out of memory. Requested %uK, available %uK.\n", (uint32_t) nextfree / 1024, npages * PGSIZE / 1024);
}
}
return result;
What is needed to be finished in mem_init() is also simple. Just follow the instructions. Here is my code.
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. 'npages' is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
pages = (struct PageInfo *)boot_alloc(npages * sizeof(struct PageInfo));
memset(pages, 0, npages * sizeof(struct PageInfo));
For the page_init(), we need to know the definition of struct PageInfo, which is near the end of inc/memlayout.h
struct PageInfo {
// Next page on the free list.
struct PageInfo *pp_link;
// pp_ref is the count of pointers (usually in page table entries)
// to this page, for pages allocated using page_alloc.
// Pages allocated at boot time using pmap.c's
// boot_alloc do not have valid reference count fields.
uint16_t pp_ref;
};
It is not hard to see that it is a typical linked list. And in kern/pmap.c, there global variable page_free_list contains a free list of physical pages.
The comment asks us to questions
Where is the kernel in physical memory? Which pages are already in use for page tables and other data structures?
The first question is not important as we can convert virtual memory address to physical address using the PADDR() macro. I think the kernel was in the [0, 4MB) area of physical memory as I mentioned in Exercise 3 of Lab 1. For the second question, let's back to the mem_init(), we have already allocated pages for page tables and other data structures before calling page_init() and they were allocated by boot_alloc(). The boot_alloc() allocates memory in linear order, so pages from nextfree are always free.
Remembering that calling boot_alloc(0) returns the address of the next free page without allocating, I believe now there isn't any trouble for implementing page_init(). Here is my code:
void
page_init(void)
{
size_t i;
pages[0].pp_ref = 1;
for (i = 1; i < npages_basemem; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
for (i = IOPHYSMEM / PGSIZE; i < EXTPHYSMEM / PGSIZE; i++) {
pages[i].pp_ref = 1;
}
for (i = EXTPHYSMEM / PGSIZE; i < npages; i++) {
if (i < PADDR(boot_alloc(0)) / PGSIZE) {
pages[i].pp_ref = 1;
} else {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
}
page_alloc() hints us to use page2kva() and memset(). page2kva() will return the virtual address of a struct PageInfo and memset() works the same as it's in the C standard library. Implemeting it is not difficult.
struct PageInfo *
page_alloc(int alloc_flags)
{
struct PageInfo *result;
if (page_free_list == NULL) {
return NULL;
}
result = page_free_list;
page_free_list = page_free_list->pp_link;
result->pp_link = NULL;
if (alloc_flags & ALLOC_ZERO) {
memset(page2kva(result), 0, PGSIZE);
}
return result;
}
page_free() maybe is the easiest one in this exercise.
void
page_free(struct PageInfo *pp)
{
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
if (pp->pp_ref != 0 || pp->pp_link != NULL) {
panic("page_free: cannot free page");
}
pp->pp_link = page_free_list;
page_free_list = pp;
}
At last, remember to remove or comment out this line in mem_init().
// Remove this line when you're ready to test this function.
panic("mem_init: This function is not finished\n");
Now run QEMU and it will print some information like this:
check_page_free_list() succeeded!
check_page_alloc() succeeded!
Exercise 3
As I mentioned above or what is described in kern/entry.S, virtual address [KERNBASE, KERNBASE+4MB) maps to physical address [0, 4MB). So for any ADDR in [0, 4MB), using xp ADDR in QEMU monitor will always print the same value as using x ADDR+KERNBASE in GDB. Here is my running result:
(qemu) xp/16x 0x10
0000000000000010: 0xf000ff53 0xf000ff53 0xf000ff53 0xf000ff53
0000000000000020: 0xf000fea5 0xf000e987 0xf000d62c 0xf000d62c
0000000000000030: 0xf000d62c 0xf000d62c 0xf000ef57 0xf000d62c
0000000000000040: 0xc0005479 0xf000f84d 0xf000f841 0xf000e3fe
(gdb) x/16x 0x10+0xf0000000
0xf0000010: 0xf000ff53 0xf000ff53 0xf000ff53 0xf000ff53
0xf0000020: 0xf000fea5 0xf000e987 0xf000d62c 0xf000d62c
0xf0000030: 0xf000d62c 0xf000d62c 0xf000ef57 0xf000d62c
0xf0000040: 0xc0005479 0xf000f84d 0xf000f841 0xf000e3fe
Question 1
value is a char * and its actual value is a virtual address, so mystery_t should be a data type representing a virtual address, which means the type of x should be uintptr_t here.
Exercise 4
Section 5.2 of Intel 80386 Reference Manual will help a lot for this lab.
In short, x86 processors use a 2-level page table shown in Figure 5-9.

And the format of DIR ENTRY and PG TBL ENTRY is illustrated in Figure 5-10.
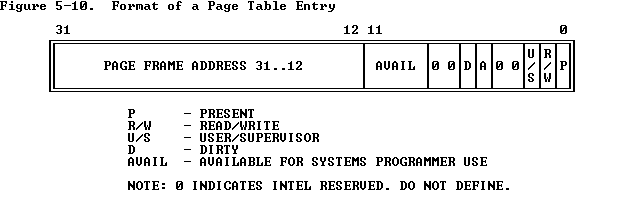
Because both page tables and pages are located on 4K boundaries, the lower 12 bits of their address is always zero. The PTE only needs 20 bits to indicate the starting physical address.
The inc/mmu.h provides a PTE_ADDR() macro to convert page frame address to physical address. It also provides PDX() and PTX() macros to calculate page directory index or page table index. Another helpful macro is the KADDR() in 'kern/pmap.h` which returns the kernel virtual address of a physical address.
Now we can implement the pgdir_walk() according to the comment.
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// Fill this function in
pde_t *pde = &pgdir[PDX(va)];
uint32_t *pt_addr;
if (!(*pde & PTE_P)) {
if (!create) {
return NULL;
}
struct PageInfo *pp;
if ((pp = page_alloc(ALLOC_ZERO)) == NULL) { // allocate and clear the page
return NULL;
}
pp->pp_ref++;
*pde = page2pa(pp) | PTE_P | PTE_W | PTE_U;
}
pt_addr = KADDR(PTE_ADDR(*pde));
return (pte_t *)(pt_addr + PTX(va));
}
Then boot_map_region(). Since size is a multiple of PGSIZE and va and pa are both page-aligned, this function doesn't need any roundup, quite easy.
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
size_t i;
for (i = 0; i < size / PGSIZE; i++) {
pte_t *pte;
if ((pte = pgdir_walk(pgdir, (void *)va, 1)) == NULL) {
panic("boot_map_region: allocation failure");
}
*pte = pa | perm | PTE_P;
va += PGSIZE;
pa += PGSIZE;
}
}
Then page_lookup(), just follow what the comment askes to do. Notice that if the present bit of a page is not set, it also means "there is no page mapped at va". So don't forget to check if the page is present, otherwise it will lead to a great bug in Lab 5 which is extremely hard to debug. (That's really a painful experience for me)
struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
pte_t *pte;
if ((pte = pgdir_walk(pgdir, va, 0)) == NULL || (*pte & PTE_P) == 0) {
return NULL;
}
if (pte_store) {
*pte_store = pte;
}
return pa2page(PTE_ADDR(*pte));
}
Then page_remove(), also follow the comment.
void
page_remove(pde_t *pgdir, void *va)
{
struct PageInfo *pp;
pte_t *pte;
if ((pp = page_lookup(pgdir, va, &pte)) == NULL) {
return;
}
page_decref(pp);
*pte = 0;
tlb_invalidate(pgdir, va);
}
Now it comes to the page_insert(). If we follow the comment we can write some code like that.
# error "This code is buggy"
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
pte_t *pte;
if ((pte = pgdir_walk(pgdir, va, 1)) == NULL) {
return -E_NO_MEM;
}
if (*pte & PTE_P) {
page_remove(pgdir, va);
}
pp->pp_ref++;
*pte = page2pa(pp) | perm | PTE_P;
return 0;
}
And we can find the comments shows a corner case, that what makes the code above buggy. It cannot handle the situation that the same pp is re-inserted at the same virtual address in the same pgdir, or when page2pa(pp) == PTE_ADDR(*pte).
To figure out what leads to the bug, I traced into page_remove(), then page_decref(). The page_decref() will free the pp if there are no more refs, and the corner case will cause the pp to be freed, which we do not want. To distinguish the corner case, we can change the code like this:
# warning "this is not elegant"
if (*pte & PTE_P) {
if (page2pa(pp) == PTE_ADDR(*pte)) {
pp->pp_ref--; // this re-implements page_remove()
*pte = 0;
tlb_invalidate(pgdir, va);
} else {
page_remove(pgdir, va);
}
}
But this is not the elegant way the comment hints. As we analyzed above, what actually leads to the free is the pp->pp_ref comes to 0. To bypass this, we can just increase the pp_ref before calling page_remove(). Here is my final code:
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
pte_t *pte;
if ((pte = pgdir_walk(pgdir, va, 1)) == NULL) {
return -E_NO_MEM;
}
pp->pp_ref++;
if (*pte & PTE_P) {
page_remove(pgdir, va);
}
*pte = page2pa(pp) | perm | PTE_P;
return 0;
}
Now run QEMU and it shall print this line:
check_page() succeeded!
Exercise 5
This exercise is pretty easy, just call boot_map_region() according to the comment.
// Map 'pages' read-only by the user at linear address UPAGES
boot_map_region(kern_pgdir, UPAGES, PTSIZE, PADDR(pages), PTE_U | PTE_P);
// Map kernel stack from [KSTACKTOP-PTSIZE, KSTACKTOP)
boot_map_region(kern_pgdir, KSTACKTOP - KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W | PTE_P);
// Map all of physical memory at KERNBASE.
boot_map_region(kern_pgdir, KERNBASE, 0xffffffff - KERNBASE, 0, PTE_W | PTE_P);
Now run QEMU and it will print these lines:
check_kern_pgdir() succeeded!
check_page_free_list() succeeded!
check_page_installed_pgdir() succeeded!
Then run make grade it shall pass all the tests.
running JOS: (0.8s)
Physical page allocator: OK
Page management: OK
Kernel page directory: OK
Page management 2: OK
Score: 70/70
Question 2
After mem_init() is executed, run info pg in QEMU console can list the current page directory.
VPN range Entry Flags Physical page
[ef000-ef3ff] PDE[3bc] -------UWP
[ef000-ef3ff] PTE[000-3ff] -------U-P 0011b-0051a
[ef400-ef7ff] PDE[3bd] -------U-P
[ef7bc-ef7bc] PTE[3bc] -------UWP 003fd
[ef7bd-ef7bd] PTE[3bd] -------U-P 0011a
[ef7bf-ef7bf] PTE[3bf] -------UWP 003fe
[ef7c0-ef7df] PTE[3c0-3df] ----A--UWP 003ff 003fc 003fb 003fa 003f9 003f8 ..
[ef7e0-ef7ff] PTE[3e0-3ff] -------UWP 003dd 003dc 003db 003da 003d9 003d8 ..
[efc00-effff] PDE[3bf] -------UWP
[efff8-effff] PTE[3f8-3ff] --------WP 0010e-00115
[f0000-f03ff] PDE[3c0] ----A--UWP
...
[f0400-f7fff] PDE[3c1-3df] ----A--UWP
[f0400-f7fff] PTE[000-3ff] ---DA---WP 00400-07fff
[f8000-ffbff] PDE[3e0-3fe] -------UWP
[f8000-ffbff] PTE[000-3ff] --------WP 08000-0fbff
[ffc00-fffff] PDE[3ff] -------UWP
[ffc00-ffffe] PTE[000-3fe] --------WP 0fc00-0fffe
According to the Section 5.2.3 of Intel 80386 Reference Manual. The page directory addresses up to 1K page tables of the second level. A page table of the second level addresses up to 1K pages. So a page directory entry can point a 0x400000 (4MB) area of memory.
Now we can complete the table by looking at the QEMU output and mem_init() function.
| Entry | Base Virtual Address | Points to (logically) |
|---|---|---|
| 1023 | 0xffc00000 | Page table for top 4MB of physical memory |
| 1022 | 0xff800000 | Page table for second top 4MB of physical memory |
| ... | ... | ... |
| 960 | 0xf0000000 | Page table for first 4MB of physical memory |
| 959 | 0xefc00000 | First 8 PDEs are page table for bootstack
|
| 957 | 0xef400000 | Page directory itself |
| 956 | 0xef000000 |
pages data structure |
| 955 | 0xeec00000 | Unmapped |
| ... | ... | Unmapped |
| 2 | 0x00800000 | Unmapped |
| 1 | 0x00400000 | Unmapped |
| 0 | 0x00000000 | Unmapped |
Question 3
Here it uses the protection mechanism of x86 protected mode, especially the page-Level protection. Both PDEs and PTEs have its permission bits shown in Figure 6-10.

Kernel and user programs are running in different modes of the processor, or protection rings. Usually, the kernel runs in ring 0 and user applications run in ring 3.
When referencing a specified memory address, MMU will check the permission bits. If the current procedure does not have sufficient privilege to access the indicated page, a page fault exception will be thrown.
Question 4
To be honest, this question is the hardest one I've ever met.
Many articles online say it supports 2GB physical memory, as pages takes 4MB space, and sizeof(struct PageInfo) = 8, the pages array can contain 4MB / 8 = 524,288 entries, or pages. Each page is of 4KB size, the maximum physical memory supported is 524,288 * 4KB = 2GB. But when I added -m 2G argument to GNUMakefile:143, QEMU throws a triple fault. Even -m 1.8G or -m 1.5G leads to a triple fault. GDB shows the fault is caused by memset() when initializing all struct PageInfo to 0 in mem_init().
When I was taking a shower, something came to my mind and that's the answer. XD
What leads the fault is the memset() of this part of mem_init():
pages = (struct PageInfo *)boot_alloc(npages * sizeof(struct PageInfo));
memset(pages, 0, npages * sizeof(struct PageInfo));
These codes are executed before page_init(), or before virtual memory is set up. Here, pages is still a part of kernel memory at KERNBASE. Though after mapping pages can take the 4MB space starting at UPAGES, it can only take the space at KERNBASE now. The only mapping available now is [KERNBASE, KERNBASE+4MB) => [0, 4MB), which means the pages cannot exceed the KERNBASE+4MB limit.
Remembering that boot_alloc(0) returns the address of the next free page without allocating, we can determine the first free page after KERNBASE before allocating space for pages.
On my machine, the value is 0xf011b000. There is only 0xf0400000 - 0xf011b000 = 2964KB space for pages at most. And it can store the pages array of 2964KB / 8 * 4KB = 1482MB, about 1.447GB.
To prove this, I ran with -m 1482M argument, JOS was successfully booted. But even run with -m 1517632K (64KB larger than 1482MB, QEMU allocates 64KB memory as a minimum unit) would lead to a triple fault.
The space left for pages may be varied from environments, but the calculation process is the same.
My final answer is 1482 MB.
Question 5
Maximum space overhead occurs when there is no empty PDEs. It consists:
- PD: 1024 entries * 4 bytes = 4 KB
- PT: 1024 PTs * 1024 entries * 4 bytes = 4 MB
The total overhead is 4MB + 4KB = 4100 KB.
Question 6
The transition happens after the jump to $relocated. In kern/entrypgdir.c, both virtual address [0, 4MB) and [KERNBASE, KERNBASE+4MB) are mapped to physical address [0, 4MB). It's necessary because the rest of the kernel is mapped to high addresses in kern_pgdir, and after kern_pgdir is loaded, VA [0, 4MB) no longer maps to [0, 4MB). Another reason is that [0, 4MB) is not designated for the kernel. It is just loaded there temporarily before paging is enabled as high addresses like 0xf0000000 is unavailable at that time.