日本語BERTモデルに対する高速・軽量化手法(量子化とMAX_LENGTH短縮)の効果を、ニュース記事分類タスクで評価した。精度は低下したものの(94%→84%~75%)、性能は5~8倍に向上した。
背景
- NLP分野での最高精度獲得競争では、巨大な学習済みモデルを利用する手法が全盛(BERT系、GPT系)
- しかし、これらのモデルは、学習時だけでなく、推論時にも多くの計算リソースが必要
- 現実の問題に適用しようとすると、運用コストが高くならないか心配
↓
推論時だけでも、軽く動かせないか
できればGPUなしCPUのみで動かしたい
BERTの推論速度を最大10倍に?
こんな記事を発見:
BERTの推論速度を最大10倍にしてデプロイした話とそのTips → すごい!(本当?)
再現コードは公開されていなかったので、自分で書いて、実験してみた。
何とか動いた。以下はその実験結果。
コードはgithubに公開 → kagiya00/speedingup-bert
評価条件
以下の軽量化/高速化手法について、適用前と適用後のモデルを構築し、推論時の精度と性能を比較評価した。
- 量子化(quantization): 学習後、推論前に、ニューラルネットワークのパラメータを浮動小数点型から整数型に変換
- MAX_LENGTHの縮小: 推論時の入力文の語数の上限値(=足切りライン) を下げる。文の先頭から足切りラインまでの語だけで推論を行うことになる。
ベースモデル:
東北大学 日本語BERT cl-tohoku/bert-base-japanese-whole-word-masking
これの大元は BERT BASE (Parameter数=110M個=1億1000万個)
評価タスク: ニュース記事の分類(9クラス)
データセット: livedoor ニュース コーパス
評価環境: Google Colaboratory
評価結果
以下の6モデルを比較評価した。
CPUを用いたベースモデル(base_CPU)に対し、量子化とMAX_LENGTHの縮小を行ったモデル(q_ml128, q_ml064)では、精度は低下するものの(94%→84%~75%)、性能は5~8倍に向上。
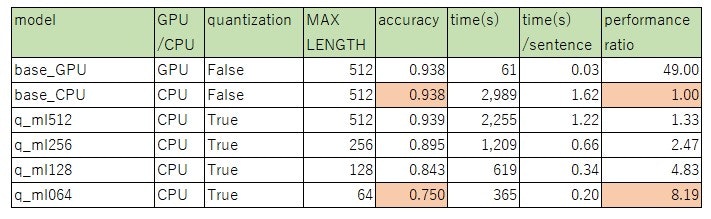
表の読み方:
- GPU/CPU列: "GPU"は推論にGPUを使用したモデルであることを表す。"CPU"は推論にCPUを使用したモデルであることを表す。
- quantization列: Trueはquantizationを実施したモデル。
- MAX_LENGTH: 入力文の足切りラインとする語数。例えば、MAX_LENGTH=64 は、文の先頭の64語のみで推論することを表す。
- accuracy: 正解率
- time(s): 1842件(=1842文)のテストデータの推論にかかった所要時間。単位は秒。
- time(s)/sentence: 1文の推論にかかった平均所要時間。単位は秒。1文の長さは平均599語。
- performance ration: base_CPUを1としたときの、time(s)の逆数の比。
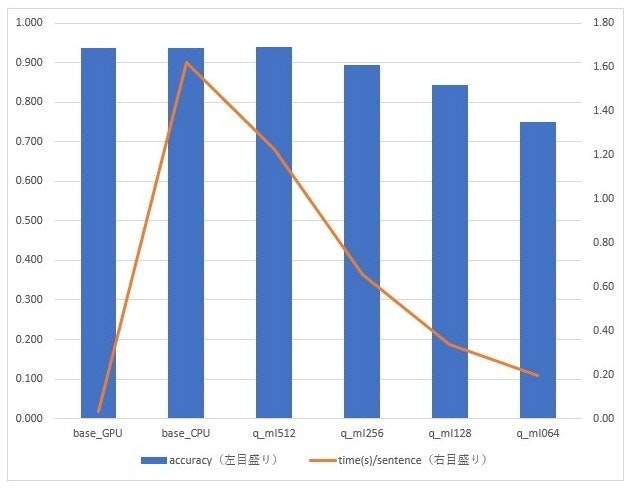
考察
今回の実験では1種類のデータセットでの評価しかしていないので安易に一般化できないが、以下のようなことは期待できるだろうと思う。
- 他の軽量化・高速化手法(distillationなど)を追加で適用すれば、性能10倍は実現できそう。ただし、「強い」軽量化・高速化手法を適用すれば、予測精度の低下は避けられない。当然のことだが、目的に応じて、性能と予測精度のバランスをとることが必要。
- BERT BASE(パラメータ数1.1億個)ぐらいのそれほど巨大ではない規模のBERTモデルならば、軽量化・高速化手法を使わなくても、CPUだけでも推論の性能はある程度確保できそう(1文平均2秒以内で返ってくる)。難易度の高くないタスクならば、CPU環境でも、BERT系のモデルを活用できそう。これも当然のことだが、目的に応じた目標性能を設定して、モデルが達成できるか評価することが必要。
- 軽量化・高速化手法の量子化とMAX_LENGTHの縮小は適用が容易。1~2行のコードの追加・修正のみで実現できる。
- 量子化では、予測精度への影響は限定され、性能向上の効果は高い。今回の実験では、25%程度の所要時間の短縮効果があった(1.22/1.62=0.75)。
- 文の先頭だけで概ね推論できそうなタスクならば、MAX_LENGTHの縮小は積極的に利用を検討したほうがよい。精度を維持しつつ、性能の向上を期待できそう。
- 今回のテストデータの語数は平均599語だったが、先頭の256語だけでも90%近い精度を確保できた。
- MAX_LENGTHの縮小は、性能に概ねリニアに効きそう。
参考:他のモデルで出ている精度(追記2021/9/14)
他のモデルや、チューニングしたBERTで出ている精度を調べてみた。精度の追求は本記事のテーマではないけれど、このあたりの相場感を無視して、BERTの精度と性能のバランスを検討するのもナンセンスなので。
Qiitaの記事"[Python]文書分類における文書ベクトル表現手法の精度比較"によると、古典的な手法bowやtfidfにより、95~96%の精度(accuracy)が同じデータセットに対して出ている。これは今回のBERTの精度を上回っている。BERTの最大長512を超える語数のサンプルを多く含むデータセットでは、BERTの長所を活かしずらいのかもしれない。いずれ、このあたりの評価をしてみたい。また、これも当然のことかもしれないが、個別のモデルに対して精度と性能のバランスのチューニングを始める前に、主要なモデルについて精度と性能の比較をしておいた方がよさそう。
Qiitaの記事"BERTを使った文書分類"によると、BERTでもチューニングすれば、95~96%の精度(accuracy)が同じデータセットに対して出るよう。
リファレンス
- BERTの推論速度を最大10倍にしてデプロイした話とそのTips
- 実験再現コード kagiya00/speedingup-bert
- PyTorch QUANTIZATION
- 東北大学 日本語BERT cl-tohoku/bert-base-japanese-whole-word-masking
- livedoor ニュース コーパス
- [Python]文書分類における文書ベクトル表現手法の精度比較
- BERTを使った文書分類
- BERTの元論文: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
以上