TL; DR
日本語文書分類タスクを機械学習で解くとき、下記の文書ベクトル表現手法ごとの精度を比較しました。
Github: https://github.com/nekoumei/Comparison-DocClassification/tree/master/src
※最近のGithub、jupyter notebookのレンダリングがよく失敗するのでnbviewerも貼っておきます
https://nbviewer.jupyter.org/github/nekoumei/Comparison-DocClassification/tree/master/src/
- Bag of Words
- TF-IDF
- Word2Vecの平均値
- Doc2Vec
- SCDV
- SWEM
結論としては下記の3点です。
- 問題によるので銀の弾丸はない(あたりまえ)
- BoW, TF-IDFのような古典的手法も案外悪くない
- 個人的にはSWEM推し
なんて定性的な結論なんだ、、
問題設定
以下2つの問題について実験しました。
Livedoorニュースコーパスのカテゴリ分類
利用データ
https://www.rondhuit.com/download.html
9カテゴリの日本語ニュース記事です。1カテゴリ500~1000記事くらいあります。
日本語の文書分類についてググるとよく出てくるデータセットです。
各記事の文書から、どのカテゴリに属するかを解くマルチクラス分類問題として扱います。
記事ごとにファイルが分かれていてちょっとめんどくさいので1csvに変換するNotebookもつくりました。
https://nbviewer.jupyter.org/github/nekoumei/Comparison-DocClassification/blob/master/src/NewsParser.ipynb
Twitterツイートネガポジ分類
利用データ
http://bigdata.naist.jp/~ysuzuki/data/twitter/
詳細は上記ページに書いてありますが、特定のトピックに関するツイートのネガポジをアノテーションしたデータです。
ツイート本文はTwitter API規約のため公開されていないため、statusIDを用いて自分でAPIを叩いて取ってくる必要があります。
今回は、ルンバに関するツイートがネガティブか、ポジティブか予測する2クラス分類問題を考えます。
APIを使ってツイートを取得するNotebookも下記に公開しています。(API KEY, ツイート本文は載せていません)
https://nbviewer.jupyter.org/github/nekoumei/Comparison-DocClassification/blob/master/src/GetTweetText.ipynb
ルンバに関するツイートは2000件ほどありますが、現時点でapiで取ってこれたのは半分くらいでした。ネガポジも半々くらい。
比較する文書ベクトル表現手法
下記のとおりです。細かい説明はしないです。
- Bag of Words
- TF-IDF
- Bag of Words + Truncated SVD
- TF-IDF + Truncated SVD
- BoWやTF-IDFはすごい高次元になるのでSVDで次元削減して使うこともあるのでやりました(kaggleでたまに見る)
- Word2Vecの平均値
- 文書中に登場する単語ベクトルの平均値を文書のベクトルとする手法です。思考停止でよくやる(私が)
- SWEM -max
- 文書中に登場する単語ベクトルのmaxを取る手法です。arXivにもあります。詳しくは下記のブログがとても参考になりました。
- https://nykergoto.hatenablog.jp/entry/2019/02/24/%E6%96%87%E7%AB%A0%E3%81%AE%E5%9F%8B%E3%82%81%E8%BE%BC%E3%81%BF%E3%83%A2%E3%83%87%E3%83%AB%3A_Sparse_Composite_Document_Vectors_%E3%81%AE%E5%AE%9F%E8%A3%85
- arXiv: https://arxiv.org/abs/1805.09843
- SCDV
- 実装についてはSWEMで紹介した記事での実装を参照しました。本当にありがとうございます!
- SCDV -raw
- 上記ブログ記事にも書かれていますが、SCDVの元実装には最後に小さいベクトルをゼロに押しつぶす(compress)処理が入っています。理由がよくわからない(スパースにして計算量を減らすためか?)ので上記記事同様この処理を除いた場合もやりました。
- Doc2Vec
- Doc2Vec - epochs=30
- なぜかよく精度が悪いDoc2Vecですが、下記記事の解説によるとデフォルトのエポック数だと不十分らしいです。
- そこでエポック数を30にした場合も追加しました。
- https://buildersbox.corp-sansan.com/entry/2019/04/10/110000
また、上記手法のうちword2vecを用いる手法(w2v平均、SWEM、SCDV)については対象データセットを用いてword2vecを学習した場合と、学習済ベクトルを利用する場合の2パターン試しました。
学習済ベクトルは下記のfasttextでWikipedia日本語を学習したものを利用しています。ありがとうございます。
https://qiita.com/Hironsan/items/513b9f93752ecee9e670
前提
環境
Ubuntu18.04 LTS
Python3.7
メモリ32GB
下記記事で自作したPCです。
https://qiita.com/nekoumei/items/9304f355d66a247215f3
比較方法
- 文書を一切前処理せずMeCab+NEologdで分かち書きする。
- 上述の文書ベクトル表現手法でベクトルにする。
- LightGBMで5-folds CVする。 (Stratified Kfold)
- Out Of FoldのAccuracy5つずつと、モデルの学習+推論にかかった時間を比較する。
実験Notebook
ニュースカテゴリ分類: https://nbviewer.jupyter.org/github/nekoumei/Comparison-DocClassification/blob/master/src/Classification_News.ipynb
ルンバツイートネガポジ分類: https://nbviewer.jupyter.org/github/nekoumei/Comparison-DocClassification/blob/master/src/Classification_Roomba.ipynb
どちらもやってることはほぼ同じです。ちゃんとメソッドかクラスにすればよかった。
結果
ニュース記事カテゴリ分類
Accuracyのboxplot+swarmplot
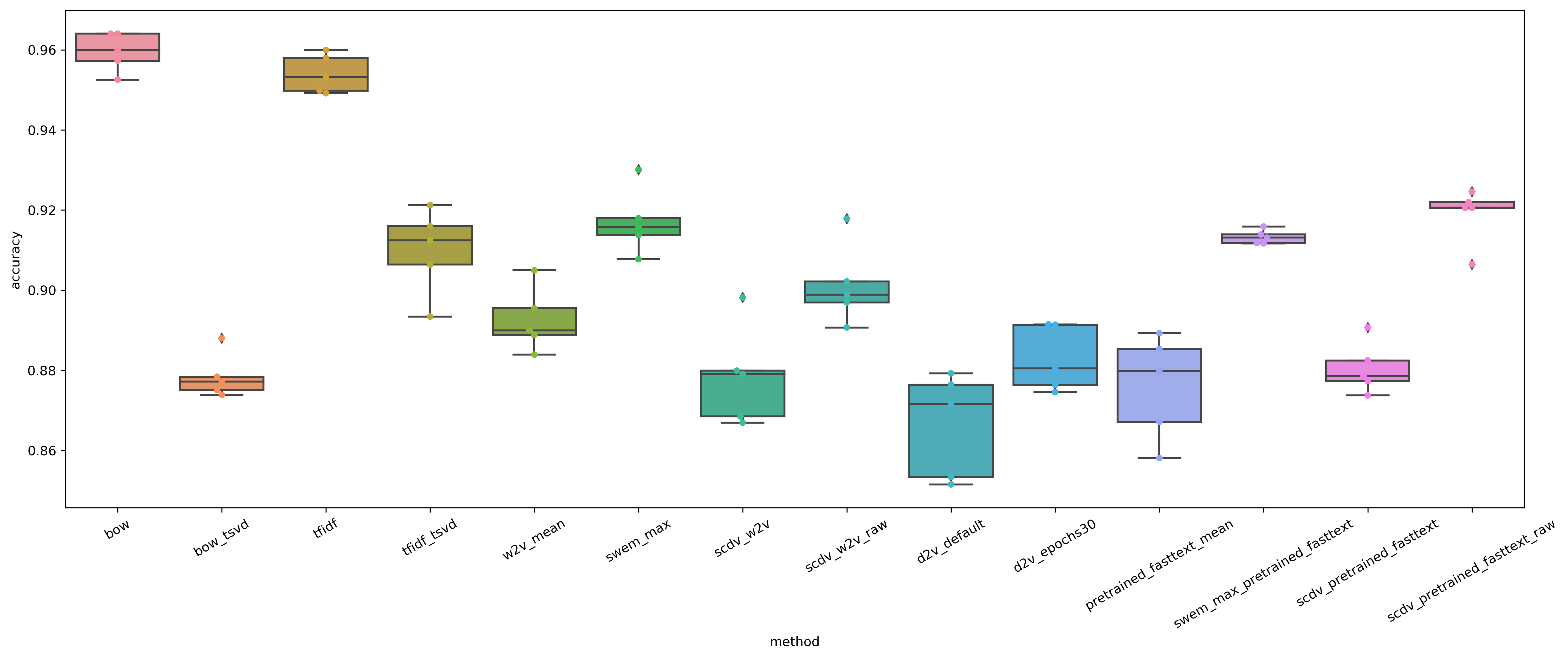
BoWが一番精度良い、という結果になりました。面白いですね。
カテゴリの分類って、特定の単語を含むかどうかで分類できそうなので確かにそれはそうな気もします。
BoW、TF-IDF以外ではcomporessしないSCDV(学習済ベクトル利用)が良さそうです。このへんは上述のGOTOさんの記事と同様ですね。
個人的には、w2vのmeanが比較的良くないこと、SWEMがシンプルな手法なのにめっちゃ良い感じなのが印象的です。
また、BoW、TF-IDFについては未知語へのロバストネスがちょっと懸念なのでこの結果を見て「BoW最強!!」ってわけではないと思っています。
ちなみにBoW、TF-IDFはだいたい80,000次元くらい、SCDVが18,000次元、SWEM他w2v系手法は300次元です。
Accuracy(mean)とモデル学習時間のscatterplot

学習にかかった時間と精度の関係性を可視化しました。
かかった時間にはベクトル化する時間は含めてません。純粋にfitしてpredictする時間のみです。ベクトル化時間を含めるとSCDVが更に増えます。
BoW, TF-IDFが次元の割に計算時間短いのは、疎なのでLightGBMがうまくやってくれたんでしょうね。
これを見るとSCDVの時間のかかり方が特徴的ですね。
学習時間に制約があるケースだとSWEMとかの方が良いかもしれません。(問題による)
ルンバツイートネガポジ分類
Accuracyのboxplot+swarmplot
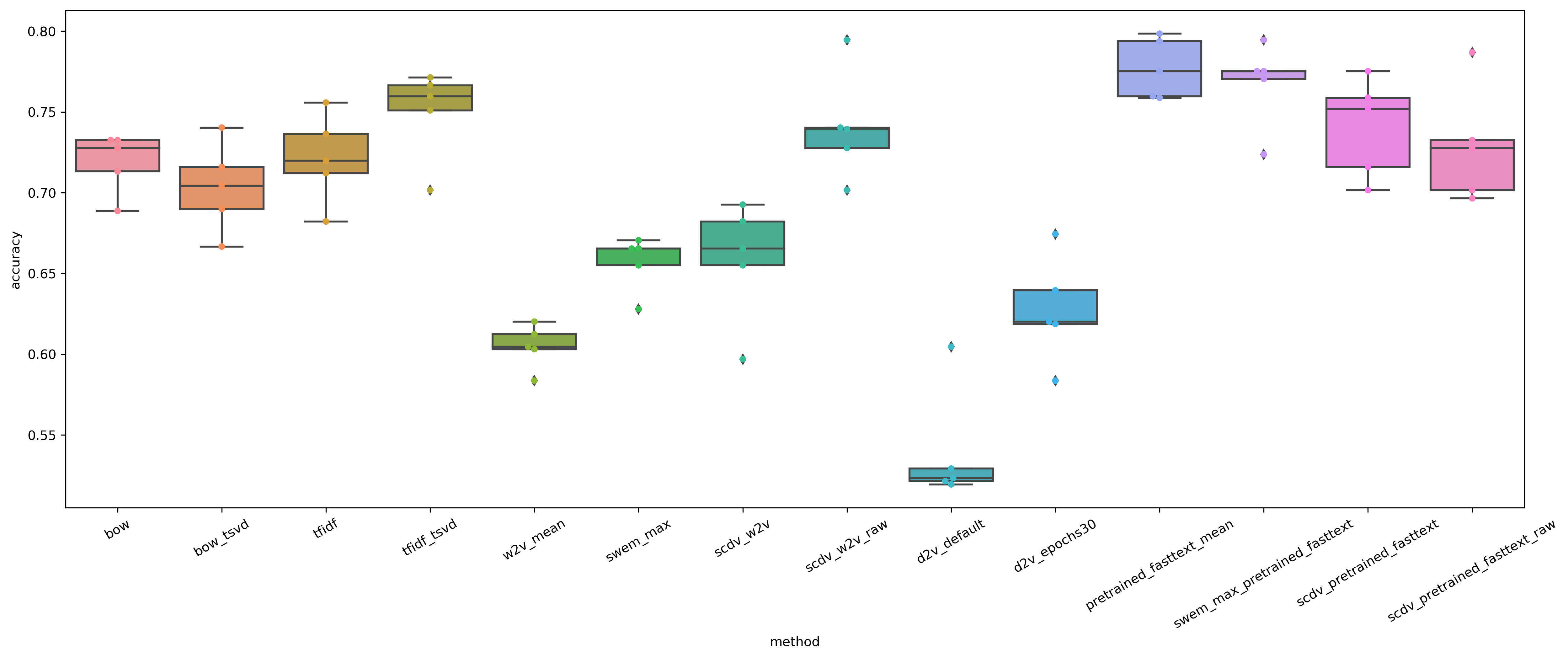
データがちょっと少ないのもあってやや分散が大きいですね。
この問題ではw2v(学習済fastText)のmeanが一番よさそうです。
ニュース記事と違い、ツイートなので1文書あたりの単語数が少ないのでBoW等よりもベクトル表現の方がより文書を表現できてるってことでしょうか。
先程と比較して、SCDVはあまり良い結果が得られていません。GMMでのクラスタリングによる効果があまりワークしないお気持ちはなんとなく分かる気がします。
また、こちらでもSWEMは安定して良い精度が得られています。
Doc2Vecに関しては、エポック数を増やすことで大幅に精度が改善していますが、他の手法よりは劣っています。
Wikipediaとかの巨大データで学習済のDoc2Vecでやってみるとまた違った結果が得られるかもしれませんね。
Accuracy(mean)とモデル学習時間のscatterplot

あいかわらずSCDVが突出していますね。
こちらではcompress処理を入れるか否かで処理時間が大きく異なっています。やっぱり処理時間短縮のための処理だったんでしょうか。
おわりに
いろいろな手法を試してみましたが、個人的にはSWEMが良いなあと思いました。
シンプルな実装、低次元、低計算時間で十分な精度がいずれの問題でも得られています。
勿論、解く問題によって何が最適なのかは変わるので、都度検討する必要はあります。
あと、日本語の文書分類に使えるデータが全然なくてそこが一番詰まりました。
参考文献
Livedoorニュースコーパス: https://www.rondhuit.com/download.html
Twitter日本語評判分析データセット: http://bigdata.naist.jp/~ysuzuki/data/twitter/
SWEM論文: https://arxiv.org/abs/1805.09843
SWEM, SCDV実装: https://nykergoto.hatenablog.jp/entry/2019/02/24/%E6%96%87%E7%AB%A0%E3%81%AE%E5%9F%8B%E3%82%81%E8%BE%BC%E3%81%BF%E3%83%A2%E3%83%87%E3%83%AB%3A_Sparse_Composite_Document_Vectors_%E3%81%AE%E5%AE%9F%E8%A3%85
Doc2Vecについて: https://buildersbox.corp-sansan.com/entry/2019/04/10/110000
fastText学習済ベクトル: https://qiita.com/Hironsan/items/513b9f93752ecee9e670