科研費申請書を書いている研究者のみなさま、お疲れ様です。
ご存知の通り、過去に採択された研究は科研費データベースに載っています。が、全部見るのはなかなか大変です。
過去の傾向をざっくり把握してみよう! ということで、今回は科研費データベースの研究の概要から自然言語処理でキーワードを抽出してみました。形態素解析パッケージMeCabと専門用語抽出ツールのtermextractを使っています。
環境構築
PythonとJupyter Notebookを使います。
OSなど
- MacOS Mojave 10.14.5
- Anaconda 2020.02
- Python 3.7.6
- Jupyter Notebook 6.0.3
MeCab
こちらを参考に、形態素解析のためにMeCabとmecab-python3をインストールし、neologdを標準辞書に設定します。
インストールできたらbashで試してみましょう。
標準辞書ipadic(MeCabのデフォルト)
echo "真核生物" | mecab
真 接頭詞,名詞接続,*,*,*,*,真,マ,マ
核 名詞,一般,*,*,*,*,核,カク,カク
生物 名詞,一般,*,*,*,*,生物,セイブツ,セイブツ
EOS
デフォルトのipadicでは「真核生物」が認識されません。
echo "科学研究費補助金" | mecab
科学 名詞,一般,*,*,*,*,科学,カガク,カガク
研究 名詞,サ変接続,*,*,*,*,研究,ケンキュウ,ケンキュー
費 名詞,接尾,一般,*,*,*,費,ヒ,ヒ
補助 名詞,サ変接続,*,*,*,*,補助,ホジョ,ホジョ
金 名詞,接尾,一般,*,*,*,金,キン,キン
EOS
「科学研究費補助金」も認識してくれませんでした。
標準辞書neologd
echo "真核生物" | mecab
真核生物 名詞,固有名詞,一般,*,*,*,真核生物,シンカクセイブツ,シンカクセイブツ
EOS
neologdは「真核生物」を認識してくれました! これならキーワード抽出に少し期待が持てるかな。
echo "科学研究費補助金" | mecab
科学 名詞,一般,*,*,*,*,科学,カガク,カガク
研究 名詞,サ変接続,*,*,*,*,研究,ケンキュウ,ケンキュー
費 名詞,接尾,一般,*,*,*,費,ヒ,ヒ
補助金 名詞,固有名詞,一般,*,*,*,補助金,ホジョキン,ホジョキン
EOS
「科学研究費補助金」は1語として認識してくれないようです。
mecab-python
PythonでMeCabを試してみましょう。テスト用に後述のデータの1文目をお借りしました。
import sys
import MeCab
tagger = MeCab.Tagger ("mecabrc")
print(tagger.parse ("真核生物はユニコンタとバイコンタに大別できる。"))
真核生物 名詞,固有名詞,一般,*,*,*,真核生物,シンカクセイブツ,シンカクセイブツ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
ユニコンタ 名詞,固有名詞,一般,*,*,*,ユニコンタ,ユニコンタ,ユニコンタ
と 助詞,並立助詞,*,*,*,*,と,ト,ト
バイコンタ 名詞,固有名詞,一般,*,*,*,バイコンタ,バイコンタ,バイコンタ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
大別 名詞,サ変接続,*,*,*,*,大別,タイベツ,タイベツ
できる 動詞,自立,*,*,一段,基本形,できる,デキル,デキル
。 記号,句点,*,*,*,*,。,。,。
EOS
Pythonから形態素解析できました。
termextract
termextractは専門語抽出をしてくれるパッケージです。MeCabの解析結果の形式でデータを渡す必要があります。
こちらを参考にインストールしました。
科研費データベースからcsvデータをダウンロード
いよいよ科研費データを扱っていきます。
当初Pythonでスクレイピングしようかと思ってスクレイピング禁止だーとかいろいろ調べていたのですが、csvでダウンロードできることに気づき、ことなきを得ました。
検索ワード「クラミドモナス」で全件ダウンロードしてみます。
クラミドモナスに馴染みのない人はこちらを見てみてください。
pandasでデータ読み込み・整形
pandasでデータを読み込んで確認します。encodingを指定するのを忘れましたが、エラーが出ずに読み込めました。
import pandas as pd
kaken = pd.read_csv('kaken.nii.ac.jp_2020-10-23_22-31-59.csv')
kaken.head() でデータの最初の部分を確認します。NaNが多そうです。
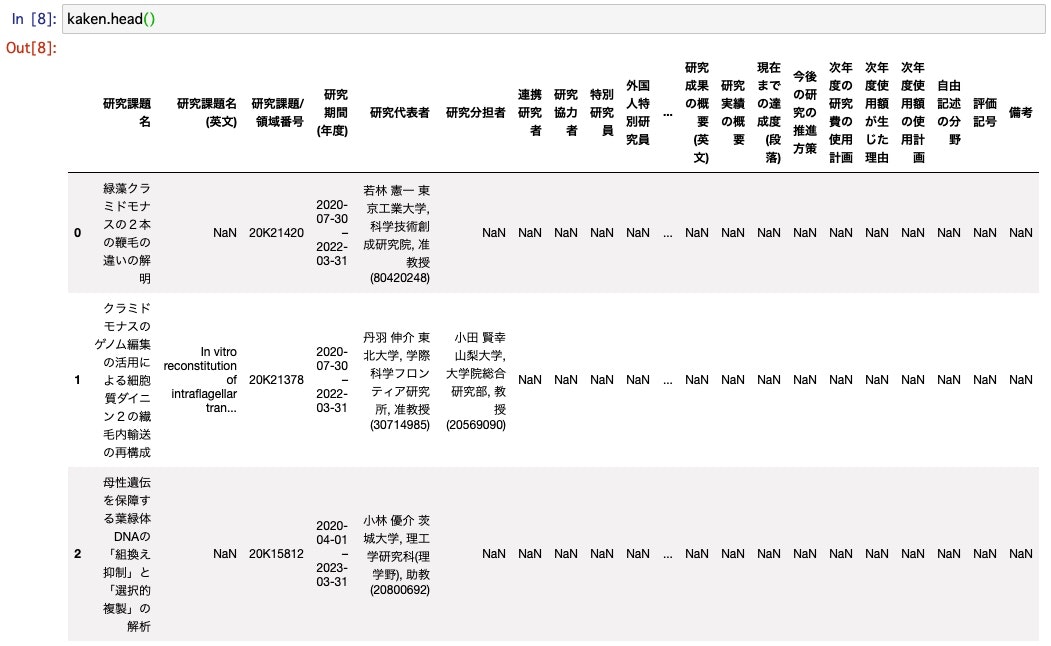
kaken.info()でデータ全体を確認します。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 528 entries, 0 to 527
Data columns (total 40 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 研究課題名 528 non-null object
1 研究課題名 (英文) 269 non-null object
2 研究課題/領域番号 528 non-null object
3 研究期間 (年度) 528 non-null object
4 研究代表者 471 non-null object
5 研究分担者 160 non-null object
6 連携研究者 31 non-null object
7 研究協力者 20 non-null object
8 特別研究員 53 non-null object
9 外国人特別研究員 4 non-null object
10 受入研究者 4 non-null object
11 キーワード 505 non-null object
12 研究分野 380 non-null object
13 審査区分 102 non-null object
14 研究種目 528 non-null object
15 研究機関 528 non-null object
16 応募区分 212 non-null object
17 総配分額 526 non-null float64
18 総配分額 (直接経費) 526 non-null float64
19 総配分額 (間接経費) 249 non-null float64
20 各年度配分額 526 non-null object
21 各年度配分額 (直接経費) 526 non-null object
22 各年度配分額 (間接経費) 526 non-null object
23 現在までの達成度 (区分コード) 46 non-null float64
24 現在までの達成度 (区分) 46 non-null object
25 理由 46 non-null object
26 研究開始時の研究の概要 14 non-null object
27 研究概要 323 non-null object
28 研究概要 (英文) 156 non-null object
29 研究成果の概要 85 non-null object
30 研究成果の概要 (英文) 85 non-null object
31 研究実績の概要 84 non-null object
32 現在までの達成度 (段落) 90 non-null object
33 今後の研究の推進方策 94 non-null object
34 次年度の研究費の使用計画 0 non-null float64
35 次年度使用額が生じた理由 0 non-null float64
36 次年度使用額の使用計画 0 non-null float64
37 自由記述の分野 0 non-null float64
38 評価記号 3 non-null object
39 備考 0 non-null float64
dtypes: float64(9), object(31)
memory usage: 165.1+ KB
「研究開始時の研究の概要」「研究概要」「研究成果の概要」「研究実績の概要」に文章が入っていそうです。「キーワード」もありますが、今回はあくまで文章からキーワード抽出したいので、無視します。
おそらく年度ごとに執筆すべき項目が変わった影響で、NaNが多くて文章の入っている行が揃っていません。文章だけデータフレームから出してリストを作ってしまうことにします。
column_list = ['研究開始時の研究の概要', '研究概要', '研究成果の概要', '研究実績の概要']
abstracts = []
for column in column_list:
abstracts.extend(kaken[column].dropna().tolist())

形態素解析の準備ができました。このリストの各要素に対して形態素解析をかけていきましょう。
MeCabで形態素解析
こちらを参考に、MeCabで形態素解析した結果の語のリストを返す関数を定義しました。
デフォルトでは名詞・動詞・形容詞のみ抽出し、動詞と形容詞は原型に戻します。
tagger = MeCab.Tagger('')
tagger.parse('')
def wakati_text(text, word_class = ['動詞', '形容詞', '名詞']):
# 分けてノードごとにする
node = tagger.parseToNode(text)
terms = []
while node:
# 単語
term = node.surface
# 品詞
pos = node.feature.split(',')[0]
# もし品詞が条件と一致していたら
if pos in word_class:
if pos == '名詞':
terms.append(term) #文中の形
else:
terms.append(node.feature.split(",")[6]) # 原型で入れる
node = node.next
return terms
さきほど抽出したデータの一部を使ってテストしてみます。

名詞・動詞・形容詞のみ抽出できています。(「9+2構造」は抽出できませんね……)
リストabstracts全体に関数wakati_textを適用して名詞・動詞・形容詞のリストを得ます。
wakati_abstracts = []
for abstract in abstracts:
wakati_abstracts.extend(wakati_text(abstract))
名詞・動詞・形容詞のリストができました。

可視化
リストwakati_abstractsの要素を数え、数が多い方から50位まで棒グラフにしてみます。
import collections
import matplotlib.pyplot as plt
import matplotlib as mpl
words, counts = zip(*collections.Counter(wakati_abstracts).most_common())
mpl.rcParams['font.family'] = 'Noto Sans JP Regular'
plt.figure(figsize=[12, 6])
plt.bar(words[0:50], counts[0:50])
plt.xticks(rotation =90)
plt.ylabel('freq')
plt.savefig('kaken_bar.png', dpi=200, bbox_inches="tight")
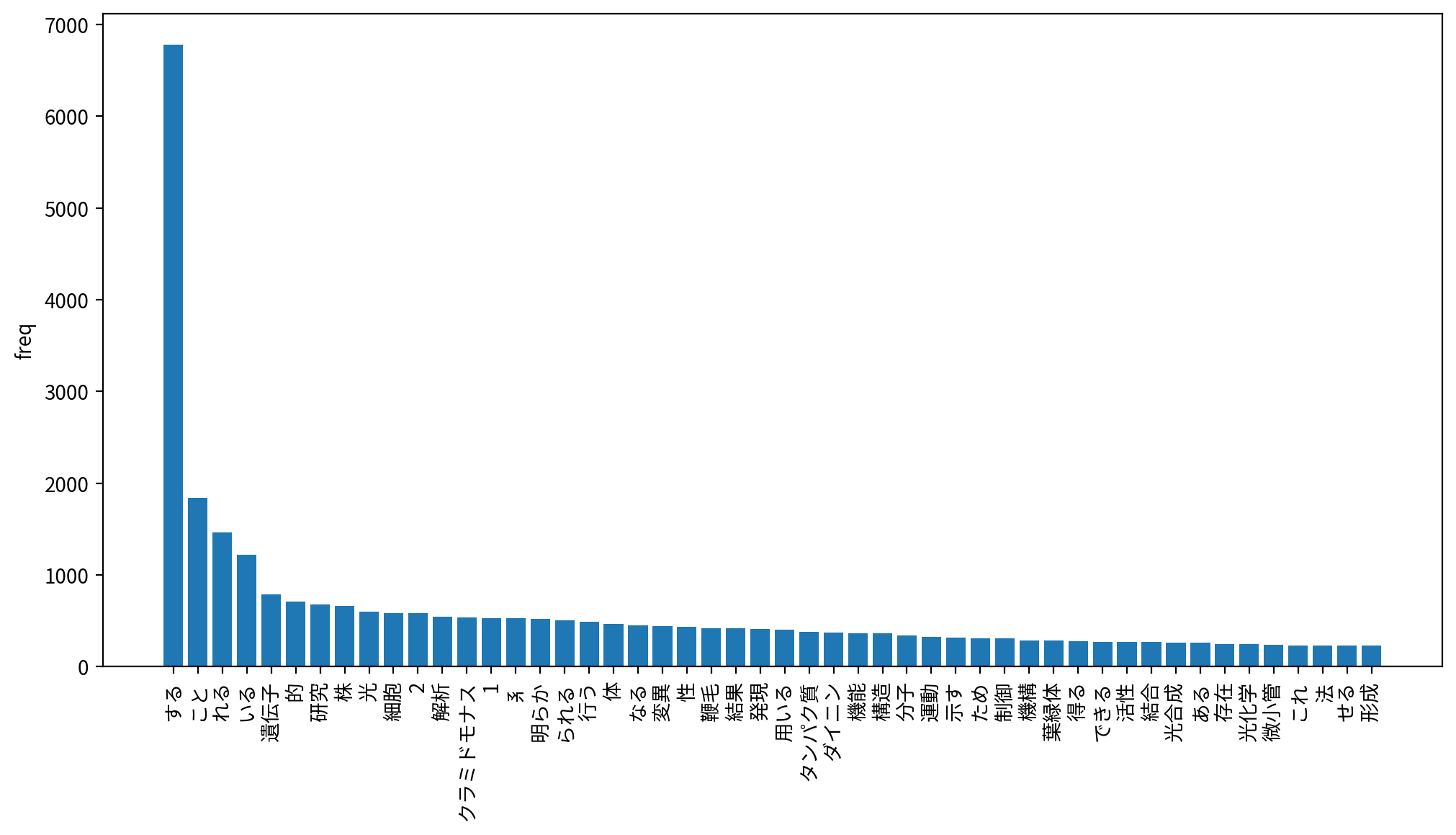
ストップワード除去をしなかったため、「する」「こと」「れる」「いる」「的」などが上位に来ています。
検索ワードである「クラミドモナス」のほか、「遺伝子」「光」「細胞」「鞭毛」「タンパク質」「ダイニン」など、クラミドモナス関係者なら見覚えのある単語が並んでいます。
動詞と形容詞はいらなかったのでは? と思われる結果になっています。
名詞のみの抽出
上記と同様の手順で名詞のみを抽出してみました。
関数wakati_abstractの第2引数を['名詞']とするだけです。
noun_abstracts = []
for abstract in abstracts:
noun_abstracts.extend(wakati_text(abstract, ['名詞']))
途中のコードは上と同じなので省略して、可視化の結果を示します。
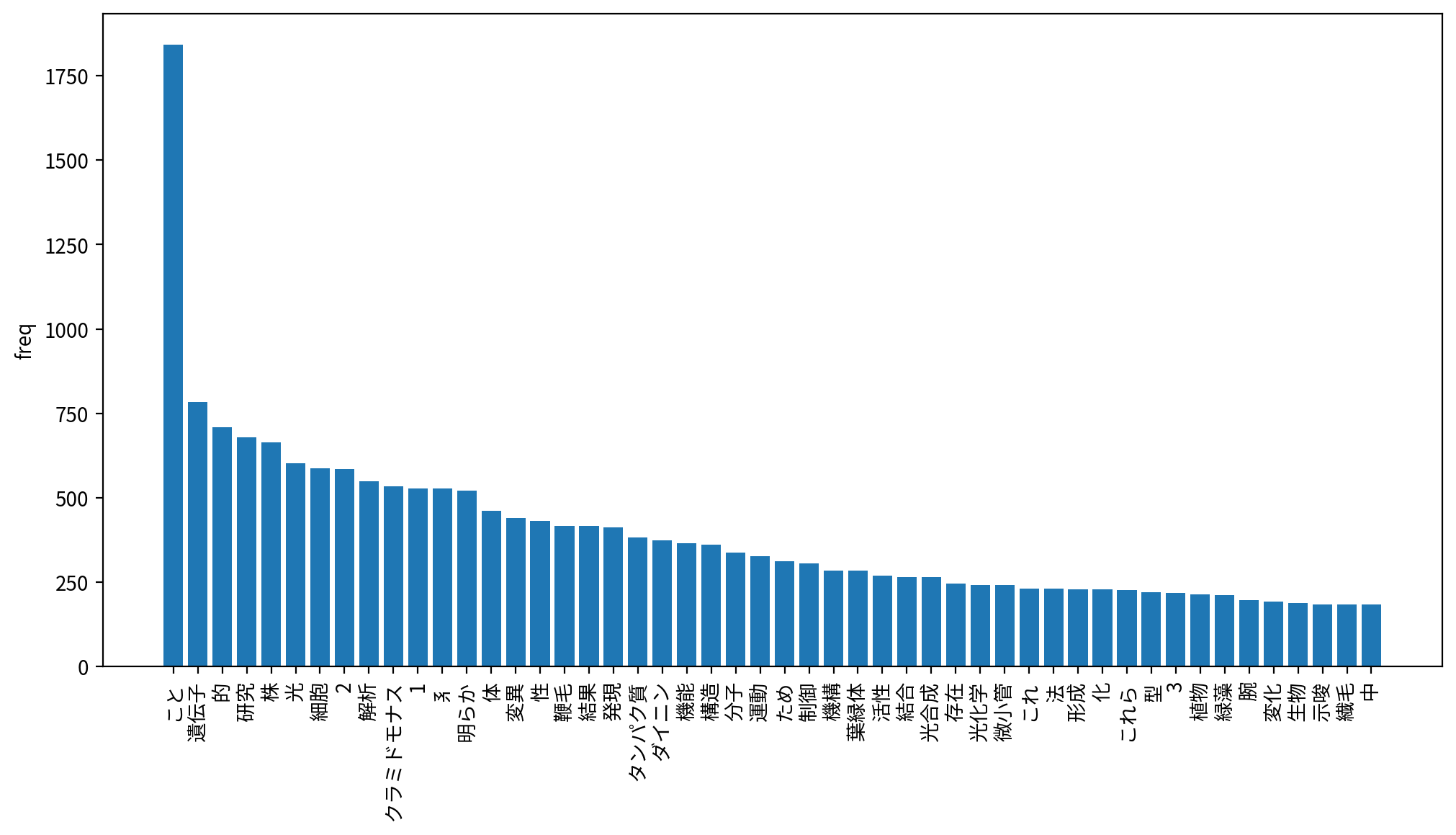
「こと」が1位に来ていたり、数字の「1」「2」「3」が入っているのが気になりますが、先ほどよりも若干キーワードっぽい結果になっています。
termextractを使った専門用語抽出
次に、termextractを使って専門用語を抽出してみます。
こちらを参考に、形態素解析方式をやってみました。
データ整形
termextractの入力形式はMeCabの形態素解析の出力結果です。
リストabstractsをMeCabで解析し、各要素の解析結果を連結して改行で区切った形式にします。
# mecabの形式で渡す
mecab_abstracts = []
for abstract in abstracts:
mecab_abstracts.append(tagger.parse(abstract))
input_text = '/n'.join(mecab_abstracts)

termextractで解析
コードはほぼ全面的にこちらのものです。
import termextract.mecab
import termextract.core
word_list = []
value_list = []
frequency = termextract.mecab.cmp_noun_dict(input_text)
LR = termextract.core.score_lr(frequency,
ignore_words=termextract.mecab.IGNORE_WORDS,
lr_mode=1, average_rate=1
)
term_imp = termextract.core.term_importance(frequency, LR)
# 重要度が高い順に並べ替えて出力
data_collection = collections.Counter(term_imp)
for cmp_noun, value in data_collection.most_common():
word = termextract.core.modify_agglutinative_lang(cmp_noun)
word_list.append(word)
value_list.append(value)
print(word, value, sep="\t")

スコアが何を意味しているのかはよく理解していませんが、それらしき語が表示されています。
これも可視化してみます。
可視化
コードは上と同じなので省略します。
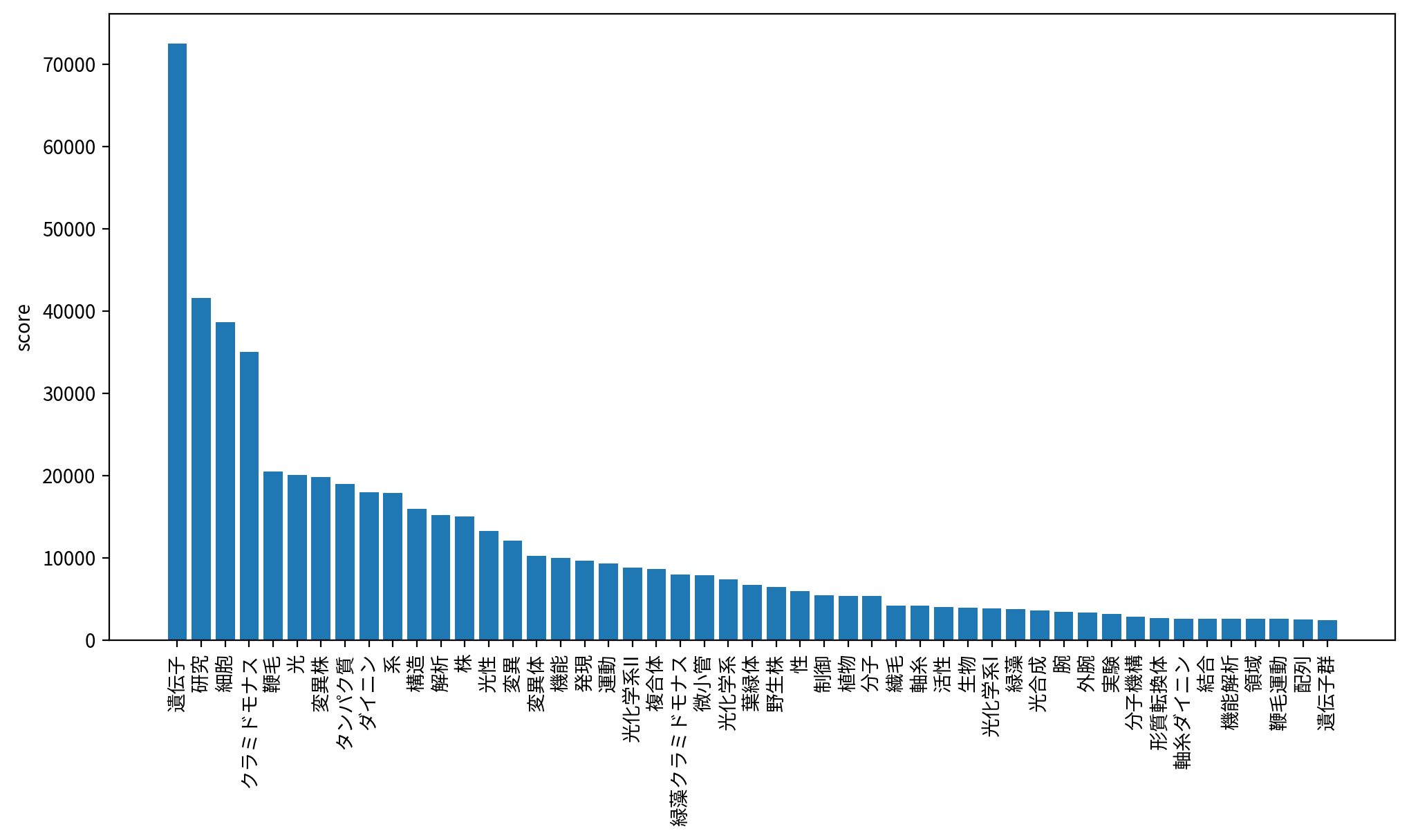
「光化学系II」「形質転換体」「鞭毛運動」「遺伝子群」など、よりそれらしい単語がとれています。
「クラミドモナス」と「緑藻クラミドモナス」、「ダイニン」と「軸糸ダイニン」が異なる項目になっているのは、まあしかたないですかね。
まとめ
科研費データベースの検索結果からキーワード抽出しました。MeCabで形態素解析のみした結果より、termextractの方がよりキーワードらしい単語抽出ができました。
おまけ:GiNZA
ついでにGiNZAの固有表現抽出も試してみました。
import spacy
from spacy import displacy
nlp = spacy.load('ja_ginza')
doc = nlp(abstracts[0])
# 固有表現抽出の結果の描画
displacy.render(doc, style="ent", jupyter=True)

固有表現じゃないのでしかたないですが、「ユニコンタ」「バイコンタ」「繊毛」「クラミドモナス」など、とってほしい表現がとれてないですね。そしてやっぱり「9+2構造」はとれない。