はじめに
今年もそろそろ科研費の季節がやってまいりました。
申請にあたって小区分のキーワード表があるので、各キーワードの位置関係を知るために、BERTでベクトル化して次元削減し、2次元で可視化してみました。pdfからデータを読み込むところはtabulaでやります。
科研費小区分とキーワード
科研費を申請する時に、自分の研究をどの分野で審査してほしいか指定します。審査区分表 に「内容の例」があるので、これをキーワードとしてBERTでベクトル化します。申請する種目によって小区分、中区分、大区分がありますが、今回は小区分があるということを理解していれば大丈夫です。各小区分には5桁の番号が割り振られており、近い分野はおおむね近い番号になっているようです。

審査区分表 2ページより
環境
前半: ローカル
tabulaでpdfからデータを取得して整形する部分はローカルで作業しました。
- MacOS Mojave 10.14.6
- メモリ 16 GB
- Anaconda
- Python 3.7.10
- Jupyter notebook
後半: Google Colaboratory
transformersを使おうとしたらDead Kernelを何度も出したので(おそらくメモリ不足)、データを書き出してColabにお引越ししました。
tabulaでpdfの表からデータを読み込んで整形する
準備
pip install tabula-py
import pandas as pd
import tabula
審査区分表のpdfをダウンロードし、読み込んでいきます。
tables = tabula.read_pdf("syokubun.pdf", lattice=True, pages='2-20')
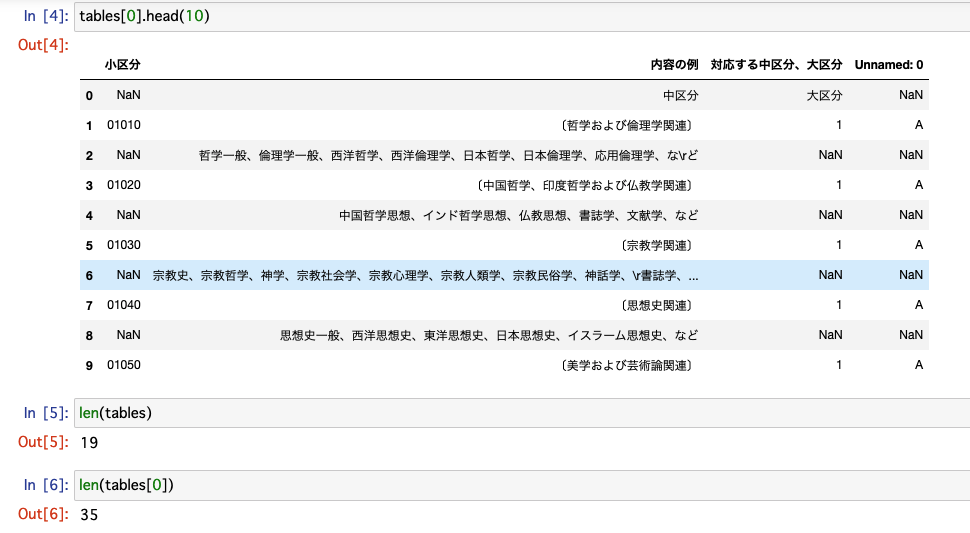
19個のテーブルがpd.DataFrameとして読み込まれました。
0行目は見出しの一部で、奇数行0列目に小区分番号があり、2以降の偶数行1列目に「内容の例」が入っているようです。
データの整形
tabulaで読み込んだ表から小区分番号と「内容の例」だけ取り出して整形します。
df = pd.DataFrame([], columns=["syokubun", "example"]) #データ格納用
for i in np.arange(1, len(tables[0]), 2):
data = pd.DataFrame([tables[0]["小区分"][i], tables[0]["内容の例"][i+1]]).T
data.columns = ["syokubun", "example"]
df = pd.concat([df, data])
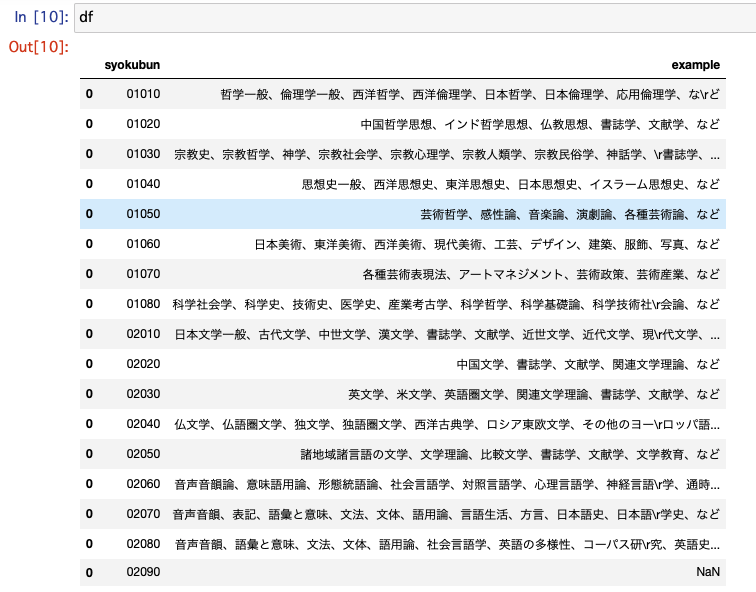
pdfの各ページの最終行だけなぜか「内容の例」を拾えていないようです。pdfからコピペして手動でフィルします。
df.iloc[16, 1] = "学習者研究、言語習得、教材開発、カリキュラム評価、目的別日本語教育、バイリンガル教育、教師研究、日本語教育のための日本語研究、日本語教育史、異文化理解、など"
df.iloc[32, 1] = "憲法、行政法、租税法、など"
df.iloc[49, 1] = "財務会計論、管理会計論、監査論、会計学一般、など"
df.iloc[65, 1] = "群論、環論、表現論、代数的組み合わせ論、数論、数論幾何学、代数幾何、代数解析、代数学一般、など"
df.iloc[81, 1] = "理論天文学、電波天文学、光学赤外線天文学、X線γ線天文学、位置天文学、太陽物理学、系外惑星天文学、など"
df.iloc[98, 1] = "制御理論、システム理論、制御システム、知能システム、システム情報処理、システム制御応用、バイオシステム工学、など"
df.iloc[115, 1] = "災害予測、ハザードマップ、建造物防災、ライフライン防災、地域防災計画、災害リスク評価、防災政策、災害レジリエンス、など"
df.iloc[131, 1] = "磁性体、超伝導体、誘電体、微粒子、液晶、新機能材料、分子エレクトロニクス、バイオエレクトロニクス、スピントロニクス、など"
df.iloc[147, 1] = "有機半導体材料、液晶、光学材料、デバイス関連材料、導電機能材料、ハイブリッド材料、分子機能材料、有機複合材料、エネルギー変換材料、など"
df.iloc[163, 1] = "蚕糸昆虫利用学、昆虫遺伝、昆虫病理、昆虫生理生化学、昆虫生態、化学生態学、系統分類、寄生・共生、社会性昆虫、衛生昆虫、など"
df.iloc[180, 1] = "タンパク質、核酸、脂質、糖、生体膜、分子認識、変性、立体構造解析、立体構造予測、分子動力学、など"
df.iloc[197, 1] = "形態形成、脳構造、回路構造、神経病理、など"
df.iloc[214, 1] = "ウイルス、プリオン、ウイルス病原性、ウイルス疫学、ウイルス感染制御、など"
df.iloc[231, 1] = "血液腫瘍学、腫瘍内科、血液免疫学、貧血、血栓止血、化学療法、など"
df.iloc[248, 1] = "口腔解剖学、口腔組織発生学、口腔生理学、口腔生化学、硬組織薬理学、など"
df.iloc[264, 1] = "リハビリテーション医学、リハビリテーション看護学、リハビリテーション医療、理学療法学、作業療法学、福祉工学、言語聴覚療法学、など"
df.iloc[278, 1] = "パターン認識、画像処理、コンピュータビジョン、視覚メディア処理、音メディア処理、メディア編集、メディアデータベース、センシング、センサ融合、など"
df.iloc[293, 1] = "汚染物質除去技術、廃棄物処理技術、排出発生抑制、適正処理処分、環境負荷低減、汚染修復技術、騒音振動対策、地盤沈下等対策、生物機能利用、放射能除染、など"
df.iloc[305, 1] = "健康福祉工学、生活支援技術、介護支援技術、バリアフリー、ユニバーサルデザイン、福祉介護用ロボット、生体機能代行、福祉用具、看護理工学、など"

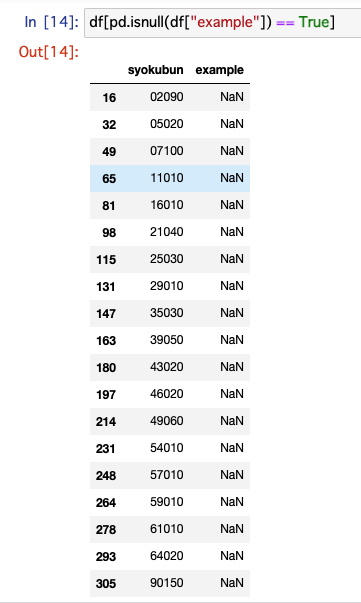
これで欠損値がなくなりました。
\rの削除
tabulaで読み込んだデータは改行の\rが入っているようなので、削除します。
# \rを削除
for i in range(len(df)):
df.iloc[i, 1] = df.iloc[i, 1].replace("\r", "")

キーワードを1個ずつに分ける
キーワードを1個ずつに分けて新しいデータフレームを作ります。
キーワードは「、」で区切られているので、split()を使って分けます。最後は必ず「など」になっているようなので捨てます。

# exampleを1個ずつにバラす
df_new = pd.DataFrame([], columns = ["syokubun", "example"])
for i in range(len(df)):
example = df.iloc[i, 1].split("、")
for j in range(len(example) - 1): #最後の「など」は削除
data = pd.DataFrame([df.iloc[i, 0], example[j]]).T #小区分とキーワードをセットにする
data.columns = ["syokubun", "example"]
df_new = pd.concat([df_new, data])
df_new = df_new.reset_index(drop=True)

キーワードを1個ずつに分けられました。
最後に整形したデータを出力します。
df_new.to_csv("df_new.csv", index=False)
BERTでベクトル化、次元削減、可視化
transformersを使うのにローカルマシンのメモリが足りないようなので、以下の作業はGoogle Colaboratoryに移って行いました。
準備
transformersでBERT東北大モデルを使おうとすると、fugashiとipadicがないと怒られるので、インストールしておきます。matplotlibで日本語を使うためのjapanize_matplotlibと次元削減用のumap-learnも入れておきます。
!pip install torch transformers fugashi ipadic japanize_matplotlib umap-learn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import torch
from transformers import AutoModel, AutoTokenizer
from sklearn.manifold import TSNE
from umap import UMAP
データを読み込みます。
# Google Driveをマウント
from google.colab import drive
drive.mount('/content/drive')
cd '/content/drive/My Drive/syokubun/'
# ローカルで出力したキーワードを読み込む
df_new = pd.read_csv("df_new.csv")
BERTでベクトル化
こちらを参考に、静的単語ベクトルでやってみました。
tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
model = AutoModel.from_pretrained('cl-tohoku/bert-base-japanese')
token_embeds = model.get_input_embeddings().weight.clone()
vocab = tokenizer.get_vocab()
vectors = {}
for idx in vocab.values():
vectors[idx] = token_embeds[idx].detach().numpy().copy()
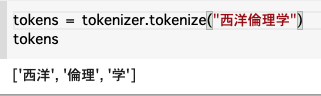
キーワードをトーカナイズし、複数トークン(≒単語)に分割されたものについては各トークンのベクトルを単純に足し合わせた結果をそのキーワードを表すベクトルとします。例えば、「西洋倫理学」は ['西洋', '倫理', '学'] に分割されるので、「西洋」+「倫理」+「学」とします。
vec_list = [] #結果格納用のリスト
for i in range(len(df_new)):
words = df_new.iloc[i, 1]
tokens = tokenizer.tokenize(words)
vec = [vectors[tokenizer.vocab[token]] for token in tokens]
vec_list.append(sum(vec))
次元削減
BERTが出力した単語ベクトルは768次元なので、2次元で位置関係を可視化するためにtSNEとUMAPをそれぞれ使ってみます。
#tSNE
tsne = TSNE(n_components=2, random_state=0)
tsne_result = tsne.fit_transform(vec_list)
#UMAP
umap_result = UMAP(random_state=0).fit_transform(vec_list)
tSNE
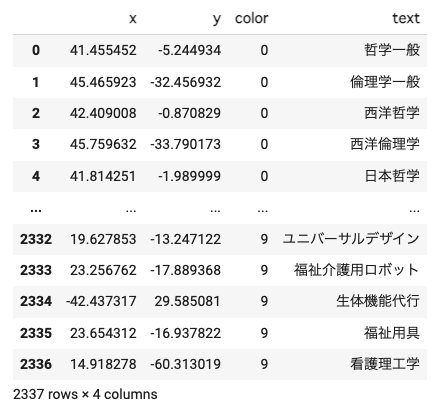
可視化用に整形した結果を示します(x, yがtsne_resultに相当します)。「哲学一般」「西洋哲学」「日本哲学」は相対的に近い値をとっており、「倫理学一般」と「西洋倫理学」、「福祉介護用ロボット」と「福祉用具」も近い、といった様子がわかります。
UMAP
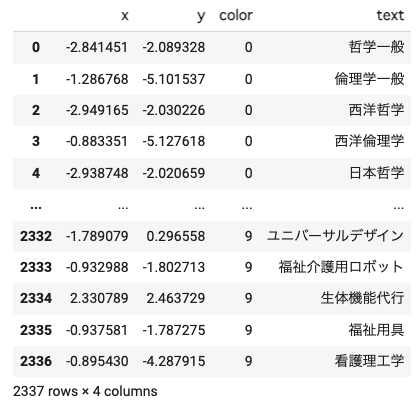
こちらも上で述べたような傾向は維持されているようです。
可視化結果
いよいよ可視化していきます。
t-SNE
散布図
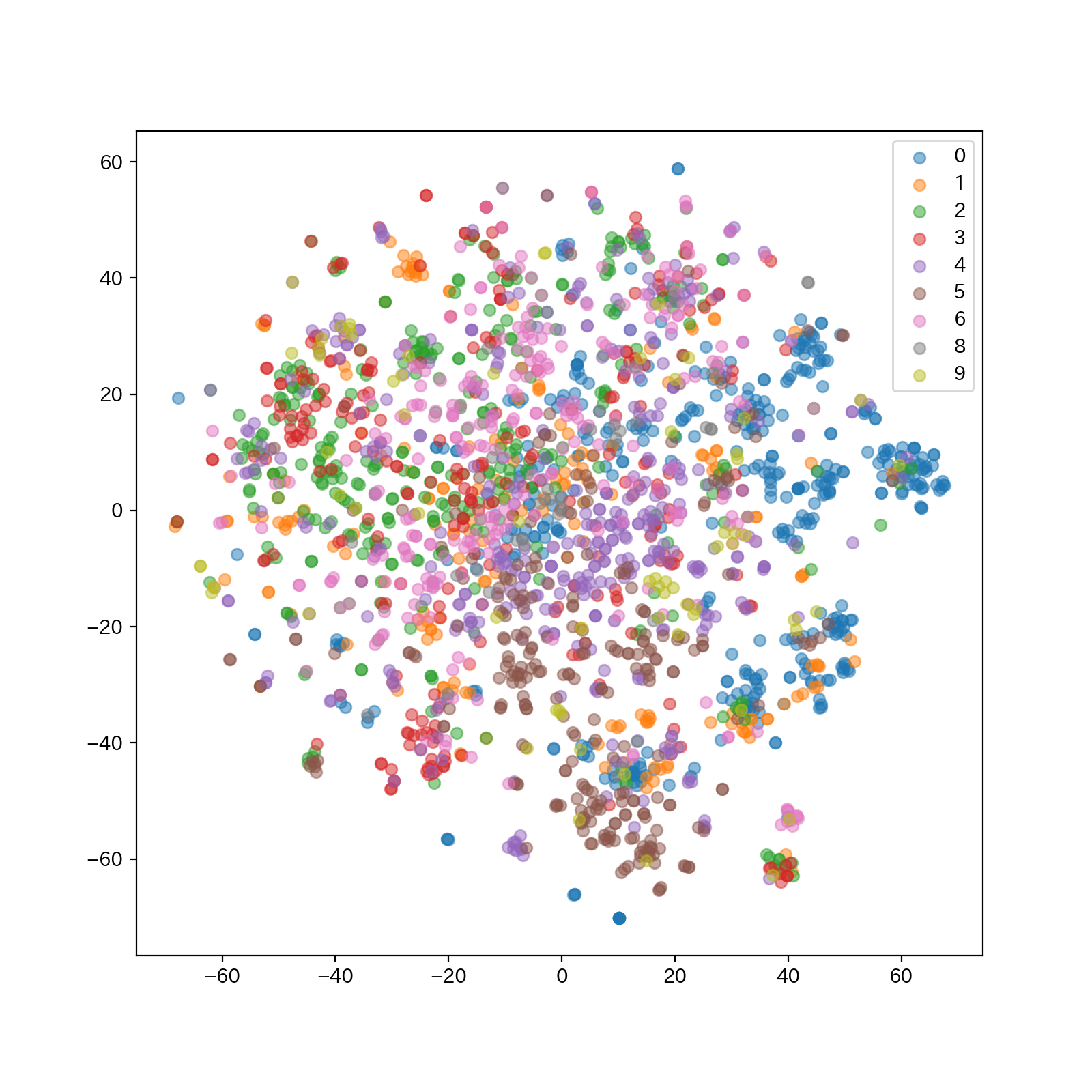
色は小区分の番号を5桁表示した時の1桁目で分けています(大区分よりもざっくりした括りです)。一目で明らかなクラスターには分かれていないものの、なんとなく偏りはあるかな、という印象です。
キーワードをプロット
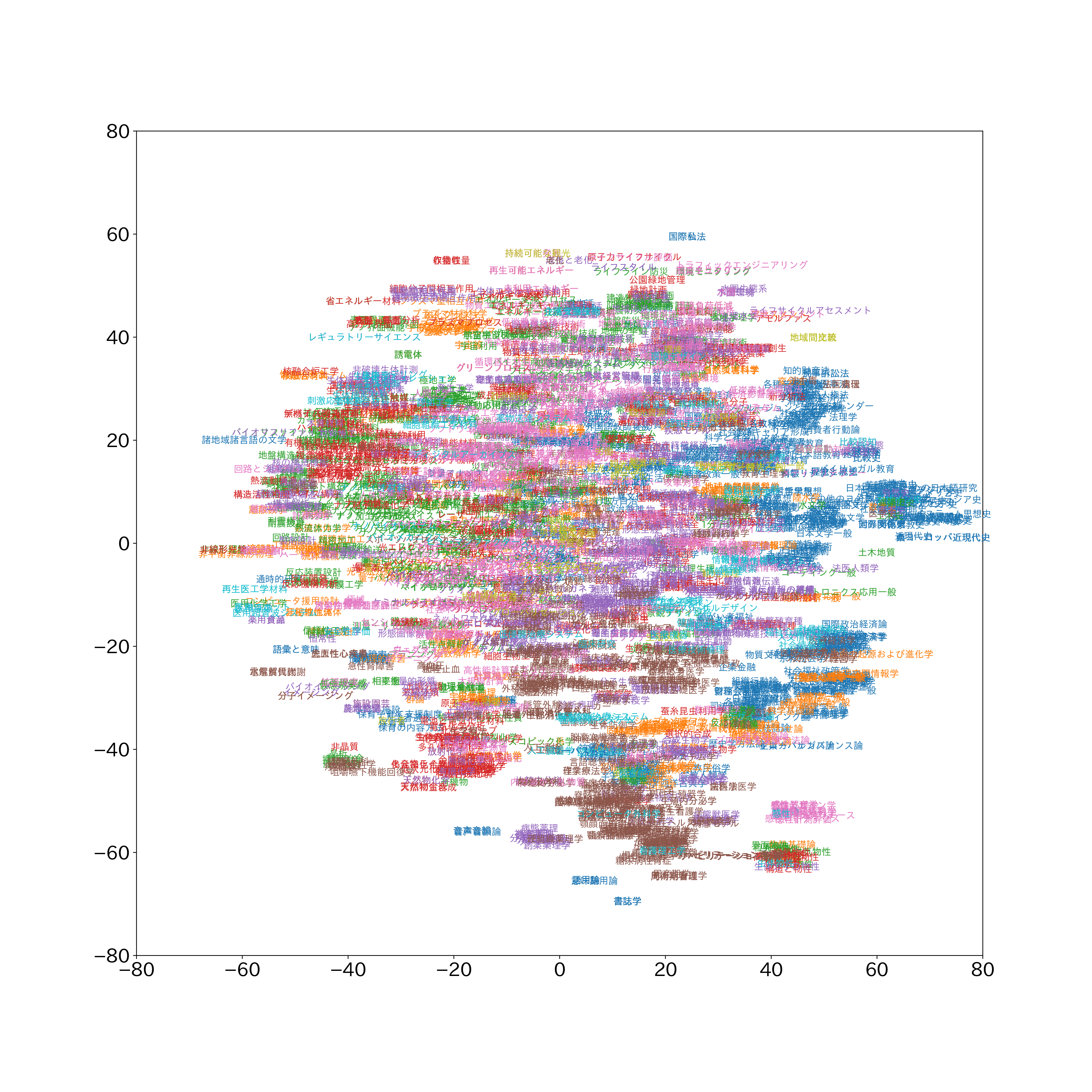
各キーワードを直接プロットしてみました。重なりすぎて可読性が低いものの、例えば一番右にちょっとはみ出ている青い小さいクラスターは歴史関係であることがわかります。上端のあたりは「持続可能な観光」「発展」「成長と老化」「原子力ライフサイクル」「再生可能エネルギー」などが見て取れます。「非晶質(赤)」は左下、「アモルファス(赤)」は右上にあり、これに関しては意味を理解していない感じがあります。
UMAP
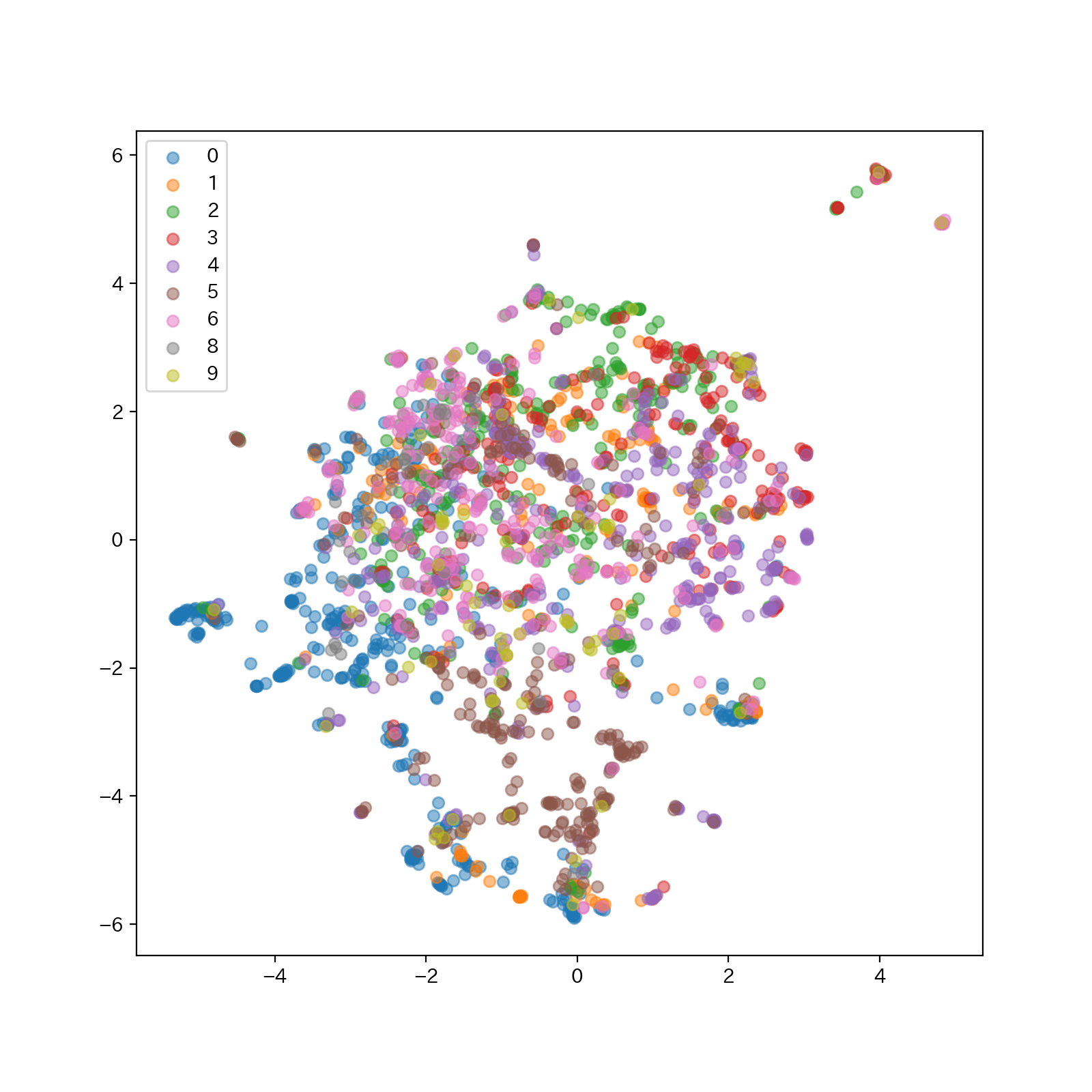
散布図
こちらも全体的になんとなく偏りはあるかなという印象です。
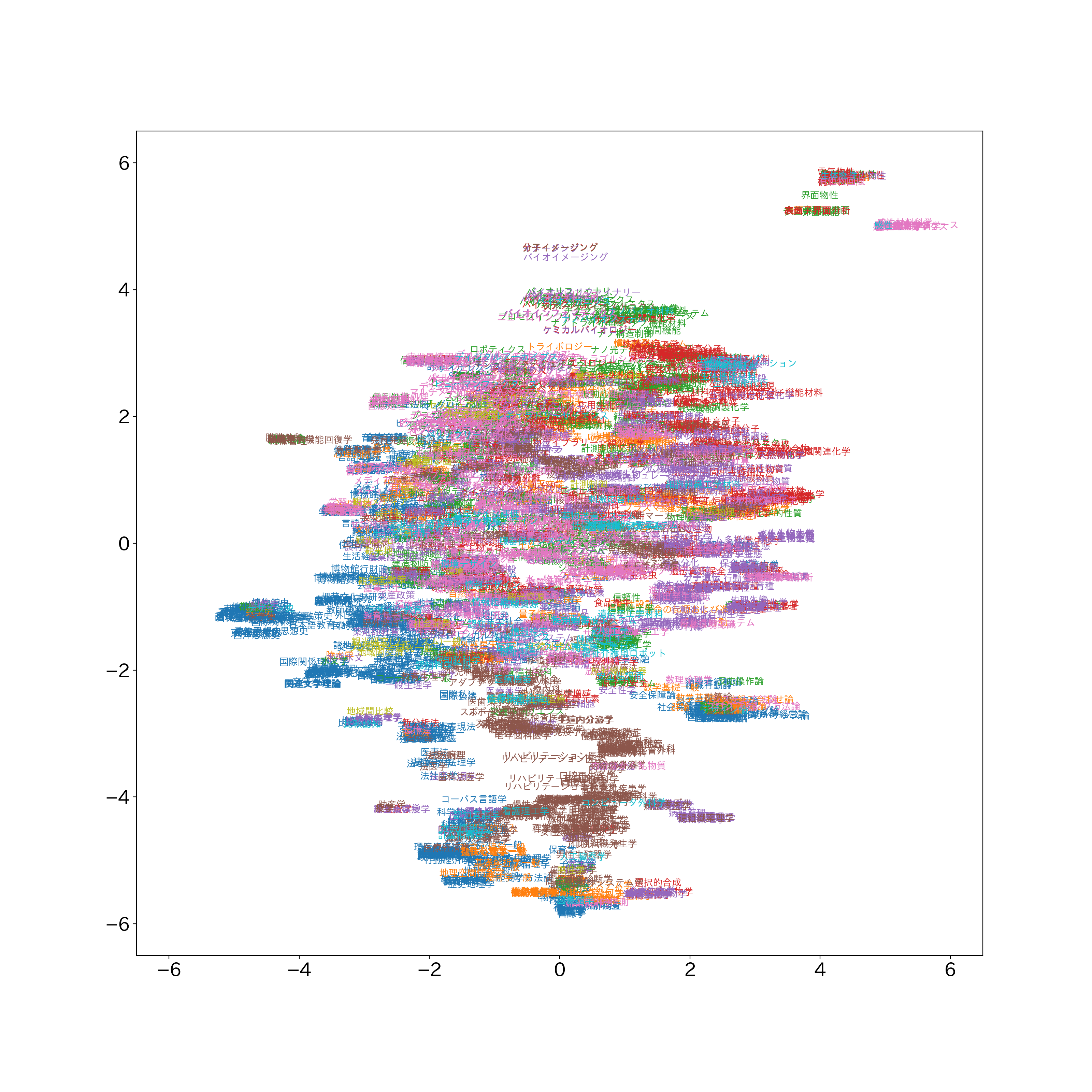
キーワードをプロット
こちらも重なりすぎて可読性は低いものの、真ん中上付近に「イメージング」関係のキーワード、右上に「物性」と「感性」関係のキーワードがあります。
まとめと所感
科研費小区分のキーワードをtabulaでpdfから取得し、BERTでベクトル化して2次元で可視化することができました。眺めた所感として、細かい関連性は拾えている気がしますが、なんか違うものが近い位置にあったりもするので、もっといいやりかたがあるのかもしれない(次元削減のチューニングの問題もある?)という印象です。
テキストをプロットした時の可読性が低い問題は、図を大きく、文字を小さくして拡大するしかないのかもしれませんが、重なりが激しいので限界がありそうです。このプロットを元にTableauダッシュボードなどを作ると自分の研究分野に近しいキーワードがプロットのどのへんにあるか探すなどができるような気がします。
参考
- 科研費審査区分表
- 【自動化】PDF内の表をPythonで抜き出す
- 【自然言語処理】BERTの単語ベクトルで「王+女-男」を計算してみる
- 特徴量次元削減手法のt-SNE・UMAPで記事文章ベクトルの可視化をしてみた
- UMAPについて私的まとめ
- 【matplotlib】日本語を表示しよう(Google Colaboratory編)
- Why am I getting the error "ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all()" on my plot? [duplicate]