この記事はAkatsuki Advent Calendar 2018の21日目の記事です。
はじめに
この記事では機械学習で用いられるDQNについて、学習速度の改善手法を取り上げたいと思います。
題材としてこちらのブログで取り上げられているカード編成問題をDQNで解く課題を高速化してみます。Originalでは大体全勝するのに20000回くらいの試行が必要でした。
Originalとの違い
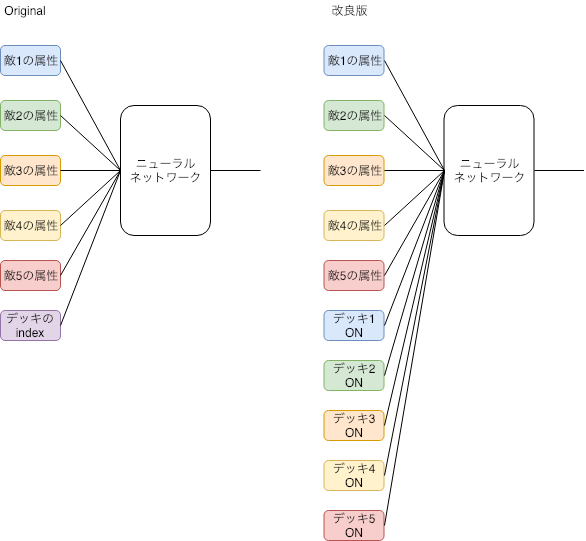
Originalからどのように改良したかというと、Originalではニューラルネットワークに現在どのデッキを選んでいるかをindexで入力していましたが、これを選ぶべきデッキ番号のみ1が立つone hot表現に展開しています。一見、変数が増えて学習が遅くなりそうですが、Originalではデッキのindexという入力は他の全ての入力に関わっています。このため、学習時は敵の属性の全ての組合せを網羅する必要があります。一方、改良版ではデッキ1と敵1、デッキ2と敵2といったようにそれぞれのカード同士でしか結合しないため、デッキNoごとに学習すればよくなります。
結果
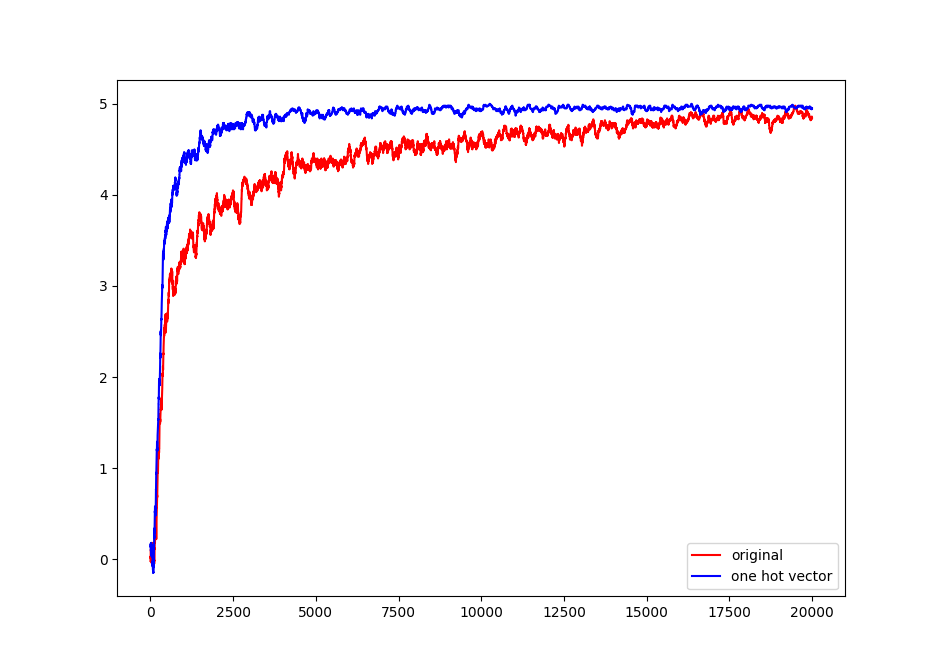
学習させて得られた報酬をプロットすると(100回の移動平均を使っています)上のようになりました。他のパラメータは全て同じにしています。Originalが20000回の試行でようやく5点付近に来るのに対して、改良版は2500〜3000回くらいの試行で5点付近に到達しています。7〜8倍くらいの改善が見られました。
まとめ
DQNの学習速度を改善するためにはニューラルネットワークの層を変える、ハイパーパラメータを変えるなどの対策がありますが、ニューラルネットワークに入れる入力を見直すことで大きく改善ができる可能性があります。今回のように入力の1つがデータ列のindexとして使われている場合、one hot表現に展開することでニューロン間の結合が少なくなり学習速度を改善することができます。