はじめに
はじめまして!今回は25卒SREの内定者アルバイトとして取り組ませていただいている内容の1つを紹介させていただきます!
EKSのログ基盤としてFluentdからFluent Bitへの移行を計画している方のご参考になれば幸いです!
この記事の内容
- EKS上でのFluent BitのインストールとConfigmapなどの設定方法について
- Fluent Bit自体の監視をDatadogで利用可能にする方法について
背景
まず、Fluentd(Fluent Bit)とはなんぞや?ということですが、ざっくり言うと「アプリケーションログやsyslogなど様々なlogを集約し、任意のサービス(SQS・CloudWatch・Splunkなど)に送信するOSS」です!

引用元: https://fluentbit.io/
FluentdとFluent Bitの違いとは?
公式ドキュメントによると、実はFluent Bitは完全上位互換ではなく双方にメリットがあるらしく、どちらを使うかはユーザのニーズによって選択するみたいです。
Fluentdは大部分がRubyで実装されており、対応プラグインが豊富なことに対して、Fluent Bitは全てC言語で実装されており、軽量でパフォーマンスが優れているという特徴があります。
Fluentdの何が問題でなぜFluent Bitに移行するのか?
これまで稼働していたFluentdはログが欠損したり、OOMKilled、CrashLoopBackOffといった問題を抱えていました。
また、Fluentdのサポートは現在メンテナンスモードで、AWSはこれ以上Fluentdの更新を提供せず、近い将来に廃止する予定であることも明記されています。
以下AWS公式の抜粋です。
Container Insights support for Fluentd is now in maintenance mode, which means that AWS will not provide any further updates for Fluentd and that we are planning to deprecate it in near future. Additionally, the current Fluentd configuration for Container Insights is using an old version of the Fluentd Image fluent/fluentd-kubernetes-daemonset:v1.10.3-debian-cloudwatch-1.0 which does not have the latest improvement and security patches. For the latest Fluentd image supported by the open source community, see fluentd-kubernetes-daemonset.
We strongly recommend that you migrate to use FluentBit with Container Insights whenever possible. Using FluentBit as the log forwarder for Container Insights provides significant performance gains.
他には、Fluent Bitの方がFluentdよりもメモリ使用量が小さいなど様々な理由から、Fluentdの問題を解決するよりも、深く考えずにFluent Bitへ移行してしまった方が早いのではないか?という流れです!
Amazon CloudWatch Observability EKS add-onについて
当初はFluentdからFluent Bitへの移行でEKS add-on化も同時に行うことを計画していました。
Amazon CloudWatch Observability EKS add-onをインストールすると、EKS上でCloudWatchエージェントとFluent Bitエージェントが自動で起動してくれるみたいです。
ただ、以下チーム事情的な理由から導入は断念し、k8sのmanifestでインストールしてDaemonsetを起動することにしました。
- 起動するDaemonsetにnodeAffinityを設定する必要があったが、このadd-onだけそれを設定するオプションがなかった(サポートにも問い合わせましたが、このadd-onだけ存在しないという回答をいただきました)
- CloudWatchの監視コストが非常に高額になっていて、コスト削減のためにほぼ使われていないロググループを調査したところ、CloudWatchエージェントは不要だった
今回は触れないので、詳しくはインストール方法を参考にしてください。
Fluent Bitのインストール方法
Fluent Bitのインストール自体はとても単純です。
HelmChartでもインストールはできると思いますが、今回はQuickStartで公開されているmanifestがあるので、そこからダウンロードしました!
ダウンロードしたmanifestの調整
必要に応じて、不要な部分を削除します。ただし、最低限下記のリソースは残しておかないと動かないと思います。
また、DaemonSetでのenvに設定されているplaceholderも自身の設定に書き換えます
- ServiceAccount
- ClusterRole
- ClusterRoleBinding
- ConfigMap
- DaemonSet(fluent-bitのみ)
IAM Roleを作成してService Accountに関連付け
logを集約してCloudWatchへ送信するためにはCloudWatchAgentServerPolicyというIAMポリシーが必要です。クラスター用のOIDCプロバイダーを作成してAssumeRoleを実行する方法(IRSA)か、「AWS re:Invent 2023」で発表されたEKS Pod Identityを利用して、Service AccountへIAMロールを割り当てるようにします。
以下IRSAでの例です。
IAM Roleの作成(CloudFormation)
IAMRoleFluentBit:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument: !Sub
- '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::${AWS::AccountId}:oidc-provider/${EKSClusterOIDCEndpoint}"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"${EKSClusterOIDCEndpoint}:aud": "sts.amazonaws.com",
"${EKSClusterOIDCEndpoint}:sub": "system:serviceaccount:<NAMESPACE>:fluent-bit-service-account"
}
}
}
]
}'
- EKSClusterOIDCEndpoint: !ImportValue eks-cluster::EKSClusterOidConnectIssure
ManagedPolicyArns:
- arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy
RoleName: !Sub fluent-bit
Service Accountの作成
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluent-bit-service-account
namespace: <NAMESPACE>
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::<AWS_ACCOUNT_ID>:role/fluent-bit
ConfigMapの移行
次にFluentdで用いていたConfigMapをFluent Bitに移行していきます。若干書き方が変わっていますが、本質的にやっていることは変わりません。以下ConfigMapの移行例です。
FluentdのConfigMap
fluent.conf: |
@include containers.conf
@include systemd.conf
@include host.conf
<match fluent.**>
@type null
</match>
containers.conf: |
<source>
@type tail
@id in_tail_container_logs
@label @containers
path /var/log/containers/*.log
exclude_path ["/var/log/containers/cloudwatch-agent*", "/var/log/containers/fluentd*"]
pos_file /var/log/fluentd-containers.log.pos
tag *
read_from_head true
<parse>
@type cri
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
<label @NORMAL>
<match **>
@type cloudwatch_logs
@id out_cloudwatch_logs_containers
region "#{ENV.fetch('REGION')}"
log_group_name "/aws/containerinsights/#{ENV.fetch('CLUSTER_NAME')}/application"
log_stream_name_key stream_name
remove_log_stream_name_key true
auto_create_stream true
<buffer>
flush_interval 5
chunk_limit_size 2m
queued_chunks_limit_size 32
retry_forever true
flush_thread_count 8
</buffer>
</match>
</label>
Fluent BitのConfigMap
fluent-bit.conf: |
[SERVICE]
Flush 5
Grace 30
Log_Level info
Daemon off
Parsers_File parsers.conf
storage.path /var/fluent-bit/state/flb-storage/
storage.sync normal
storage.checksum off
storage.backlog.mem_limit 5M
@INCLUDE application-log.conf
@INCLUDE dataplane-log.conf
@INCLUDE host-log.conf
application-log.conf: |
[INPUT]
Name tail
Tag application.*
Path /var/log/containers/*.log
Exclude_Path /var/log/containers/cloudwatch-agent*, /var/log/containers/fluent-bit*
multiline.parser docker, cri
DB /var/fluent-bit/state/flb_container.db
Mem_Buf_Limit 50MB
Skip_Long_Lines On
Refresh_Interval 10
Rotate_Wait 30
storage.type filesystem
Read_from_Head ${READ_FROM_HEAD}
[FILTER]
Name kubernetes
Match application.*
Kube_URL https://kubernetes.default.svc:443
Kube_Tag_Prefix application.var.log.containers.
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude Off
Labels Off
Annotations Off
Use_Kubelet On
Kubelet_Port 10250
Buffer_Size 0
[OUTPUT]
Name cloudwatch_logs
Match application.*
region ${AWS_REGION}
log_group_name /aws/containerinsights/${CLUSTER_NAME}/application
log_stream_prefix ${HOST_NAME}-
auto_create_group true
extra_user_agent container-insights
また、このままではアプリケーション部分のlogがただの文字列として出力されてしまうので、parsers.confに以下の設定を追記して、[INPUT]のparserを追記したcriに書き換えます。(QuickStartのmanifestはdockerという名前も指定されmultiline.parserになっていますが、そのdockerを削除します)
[PARSER]
Name cri
Format regex
Regex ^(?<time>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) (?<log>.*)$
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L%z
さらに、CloudWatch Logsでメトリクスフィルターを利用しているなどの関係でFluentdとフォーマットを統一したいときは、以下のフィルタを設定します。
[FILTER]
Name modify
Match application.*
Rename _p logtag
Rename log message
kustomizeのConfigMapGeneratorを利用
現状はk8sのmanifestをapplyすることで、ConfigMapも同時に変更が加えられDaemonSetを再起動する必要がありましたが、ConfigMapだけ変更する場合本番環境でこれが起きてしまうのは好ましくありません。
そこで、kustomizeのConfigMapGeneratorを使ってConfigMapを動的に生成することができます。
以下のようにディレクトリを構成します!
ディレクトリ構成例
fluent-bit/
├── config/
│ ├── application-log.conf
│ └── dataplane-log.conf
│ └── fluent-bit.conf
│ └── host-log.conf
│ └── parsers.conf
└── fluent-bit.yaml
└── kustomization.yaml
また、kustomization.yamlに以下の内容を追記します。
kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: <NAMESPACE>
resources:
- fluent-bit.yaml
configMapGenerator:
- name: fluent-bit-config
files:
- config/fluent-bit.conf
- config/application-log.conf
- config/parsers.conf
- config/dataplane-log.conf
- config/host-log.conf
これでKubernetesのマニフェストを柔軟に管理できるかつ、ConfigMapの変更をすぐ反映できるようになりました!
結果
欠損しまくっていたlogが正しく送信できるようになり、リソースの消費量も激減しました 🎉
- Fluentd

- Fluent Bit
※FluentdとFluent Bitが別Nodeに両立しているときのデータであり、載っているPodなど条件が全く異なる比較なので参考程度でお願いします。一応公式だと1/60のメモリ消費量だと言われています。
Fluent Bit自体の監視を導入
Fluent Bitを導入し終えたところですが、そもそもこのFluent Bitが正しくlogを送れているかも監視する必要がありそうです。(監視の監視)
そのため、Fluent BitのメトリクスをDatadogに送信する方法について今から紹介させていただきます!
基本的に公式ドキュメントの手順に従いますが、Datadogとのインテグレーション面で情報が足りていなかったので、そこを補足しながら説明します!
Fluent Bitのメトリクスを公開
まず、Fluent BitのHTTP Serverを有効にして、メトリクスを公開します。
以下の3行をapplication.confの[SEVICE]に追記します。
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
fluent-bitのannotationにopenmetricsとして設定
https://docs.datadoghq.com/containers/kubernetes/prometheus/?tab=kubernetesadv2
↑を参考にfluent-bitのDaemonsetにannotationsを適用します
ad.datadoghq.com/fluent-bit.checks: |
{
"openmetrics": {
"init_config": {},
"instances": [
{
"openmetrics_endpoint": "http://%%host%%:2020/api/v1/metrics/prometheus",
"namespace": "fluentbit",
"metrics": [
".*"
]
}
]
}
}
metricsは全て取るように設定していますが、必要なメトリクスに絞ることもできます。また、ここで指定するnamespaceはDatadogのmetricsではprefixの役割をします。
(例えば、fluentbit_input_bytes_totalというメトリクスはDatadog上で、fluentbit.fluentbit_input_bytes.countと表示されます)
また、Datadog Agentがメトリクスにアクセスできるように、Daemonsetの設定で2020番ポートを解放する必要があります。
ports:
- containerPort: 2020
protocol: TCP
name: metrics
これで、Fluent BitのメトリクスがDatadogへ送信できるようになりました!

AlertやDashBoardの実装
メトリクスがDatadogへ送れるようになったところで、実際の運用についても少しだけ紹介させていただきます!
- そもそも正常に動いていてエラーが最小限に抑えられているか?
- 入力から出力へのlogが正しく送信できているか?
を監視する必要がありそうで、特に2つ目に関してはlogの収集(input)や転送(output)などpipelineで監視しておいた方が良いでしょう。
まず、異常系監視で使えそうなメトリクスは以下です。
| メトリクス名 | 説明 |
|---|---|
| fluentbit_output_errors_total | エラーが発生したチャンクの数 |
| fluentbit_output_dropped_records_total | 出力によってドロップされたlog数 |
これは、多発すると対応が必要になってくると思うので、Alertを作成する必要がありそうです。以下のクエリでAlertを作成してみました。
sum(last_5m):sum:fluentbit.fluentbit_output_errors.count{kube_cluster_name:<CLUSTER_NAME>} by {kube_node}.as_count() > 10
閾値は試験的なので今後の様子次第です。エラーはチャンク数なのに対して、ドロップはlog数なので注意する必要があります。
次に正常系監視で使えそうなメトリクスは以下です。
| メトリクス名 | 説明 |
|---|---|
| fluentbit_input_records_total | 入力層取り込んだlogの数 |
| fluentbit_filter_records_total | フィルタ層が取り込んだlogの数 |
| fluentbit_filter_drop_records_total | フィルタ層で設定した条件でドロップしたlogの数 |
| fluentbit_output_proc_records_total | 出力層が正常に送信したlogの数 |
pipelineのlog量を監視することによって、明らかにlogが少ないDaemonsetや、logが何らかの原因で送信できていない場合、どこの層が原因かを分析することができます。
あとは単純に負荷分析とかにも使えると思います。
しかし、Daemonsetごとの監視にしてしまうとlog量にかなり差があり、Alertの閾値を決め打ちすることが難しかったのでAlertは諦めてDashBoardを作成することにしました。
他にはメモリやバッファのリソース量が最適化どうかを監視するためにBuffering関係のメトリクスを利用する必要もありそうです。
また、kubernetesのメトリクスを用いてCPU使用率やメモリ使用率なども監視しリソース最適化に活用することもできます。
(余談です)
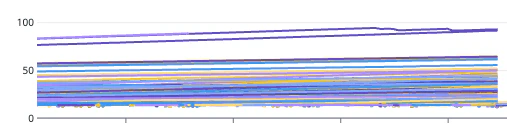
監視してみたところFluent Bitでメモリリークが発生していることが発覚したのですが、なぜか95%付近まで上がると、一旦下がってクラッシュはしない仕様になっていました。余力があったらこれも調査してみたいです。KarpenterによってNodeが入れ替わったり、Daemonsetに更新が入ることでこれは解決されますが...
まとめ
今回はFluentd CloudWatchからFluent Bitへの移行および、Fluent Bitの監視について紹介させていただきました!
Alertの閾値最適化やDaemonsetのリソースチューニングなどが今後の課題になってきそうです。
また、今回Fluent Bitのversionは1.9でインストールしましたが、PublicなECRリポジトリの最新がこれしかなかったです。(最新は3.1)
また、1.9と3.1ではメトリクスのエンドポイントと、取れるメトリクスが大きく変わるので今後対応が必要そうです。