NTTテクノクロスの川部です。
この記事は、NTTテクノクロスアドベントカレンダーシリーズ1の16日目の記事になります。
概要
ローカル環境だけで完結する RAG チャットボットを作りたくて、
「Dify × gpt-oss:20b × EmbeddingGemma」の構成で実際に動かしてみました。
各モデルを選択した理由
- 20Bクラスでローカルでも動かしやすく、汎用的な用途に優れているため(gpt-oss:20b)
- 多言語対応で軽量なモデルであるため(EmbeddingGemma)
環境はこんな感じです。
- 個人PC
- OS: Windows 11
- CPU: AMD Ryzen 7 7700 (8-Core)
- GPU: GeForce RTX 5070
- メモリ: 32GB
この記事では、次のような構成を目指します。
- 推論 LLM:
gpt-oss:20b(Ollama 経由) - 埋め込みモデル:
embeddinggemma:300m(同じく Ollama) - チャットボット & RAG: Dify を Docker でセルフホスト
- すべてローカル(クラウド API 一切ナシ)
構成に沿って「0〜8」のプロセスで整理していきます。
0. 全体像と構成
最終的なアーキテクチャはこうです。
-
Windows ホスト上
-
Ollama
-
gpt-oss:20b… チャット用 LLMモデル -
embeddinggemma:300m… ナレッジ用 Embeddingモデル
-
-
-
Docker コンテナ内
-
Dify(API / Web UI)
- モデルプロバイダとして Ollama を登録
- ナレッジベースを EmbeddingGemma でベクトル化
- RAG チャットボットを GUI で構築
-
ネットワーク的には:
- Dify コンテナ →
http://host.docker.internal:11434→ ホスト上の Ollama
という形でつなぎます。
1. Ollama のセットアップ(Windows11)
① インストール
- 公式サイトから Windows 用インストーラをダウンロード
https://ollama.com/download - 普通にインストールして、Ollama アプリを起動
- PowerShell でバージョン確認
ollama --version
ollama コマンドが通れば OK です。
② 外部(Docker)からアクセスできるようにする
Dify はコンテナの中で動くので、ホスト上の Ollama が 0.0.0.0 で listen している必要があります。
-
Windows「環境変数の編集」から、ユーザーまたはシステム環境変数に:
- 変数名:
OLLAMA_HOST - 値:
0.0.0.0
- 変数名:
-
PC を再起動(少なくとも Ollama は再起動)
-
PowerShell で確認:
Invoke-RestMethod -Uri "http://localhost:11434/api/tags"
モデル一覧の JSON が返ってくれば OK です。
③ モデルのダウンロード(gpt-oss:20b & EmbeddingGemma)
PowerShell で以下を実行します。
# LLM 本体
ollama pull gpt-oss:20b
# 埋め込みモデル
ollama pull embeddinggemma:300m
④ Embedding API の動作確認
PowerShell で以下を実行します。
Invoke-RestMethod `
-Uri "http://localhost:11434/api/embed" `
-Method POST `
-ContentType "application/json" `
-Body '{"model":"embeddinggemma:300m","input":["東京の天気","寿司が食べたい"]}'
埋め込みベクトルの配列が返ってくれば EmbeddingGemma は正常に動作しています。
2. Dify を Docker でセルフホスト
① Docker Desktop のインストール
Windows 11 では Docker Desktop を普通にインストールして、初期設定を完了させます。
(本記事の環境スペックではこのままでも問題なく動作しますが、スペック不足などでリソースを絞りたい場合は、.wslconfigでWSL側に割り当てるメモリ量などを制限しましょう)
※業務で利用する際は必要に応じてライセンス購入を検討する必要があります。
② Dify の取得と起動
作業用ディレクトリ(例: C:\work)で:
cd C:\work
# Dify のソース取得
git clone https://github.com/langgenius/dify.git
cd dify\docker
# 環境ファイルをコピー
copy .env.example .env
# Dify を起動
docker compose up -d
コンテナ起動後、ブラウザで:
http://localhost/
にアクセスすると、Dify の初期セットアップ画面が表示されます。
管理者アカウントのメールアドレスとパスワードを登録してログインします。
3. Dify と Ollama をつなぐ
① Base URL(host.docker.internal)の設定
Dify はコンテナ内で動いているため、ホストの localhost にはそのまま届きません。
そこで Docker のお約束である host.docker.internal を使います。
- Base URL:
http://host.docker.internal:11434
docker-compose.yml の api サービスに、念のため以下を追加しておくと確実です。
services:
api:
# 既存設定…
extra_hosts:
- host.docker.internal:host-gateway
② Dify 側でモデルプロバイダとして Ollama を登録
- Dify 管理画面で右上のアイコン → 「設定」
- 「モデルプロバイダー」タブ
- 一覧から「Ollama」を選択 → 「インストール」

ここで、Ollama 用のモデルを 2 種類登録します。
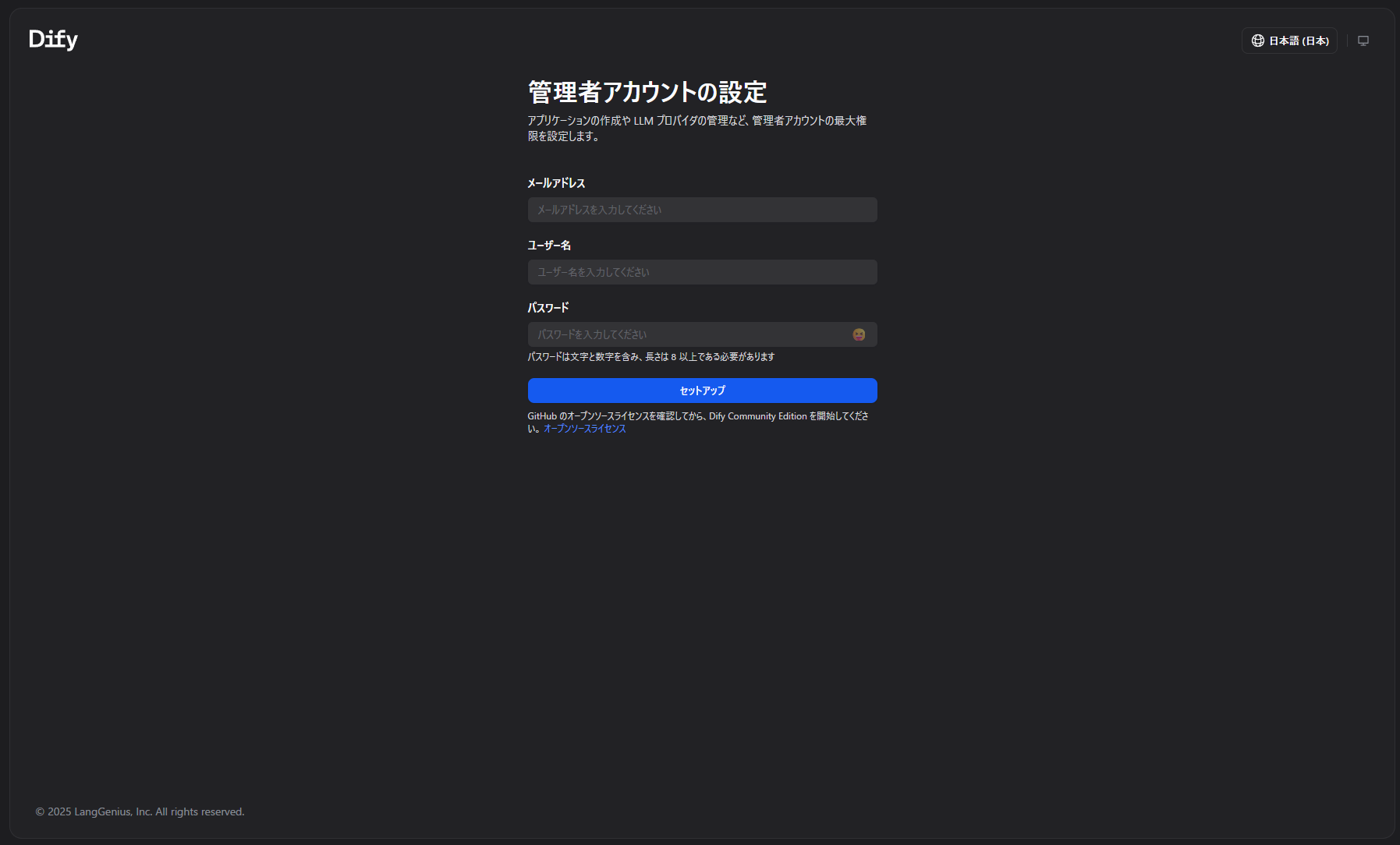
③ gpt-oss:20b を LLM として登録
「モデルを追加」から:
- モデルタイプ:
LLM - モデル名:
gpt-oss:20b - Base URL:
http://host.docker.internal:11434 - 補完タイプ:
Chat(会話モデル) - コンテキスト長: 4096 など
保存後、「システムモデル設定」で:
- システム推論モデル:
gpt-oss:20b
を選択して保存します。
これで Dify 全体のデフォルト LLM が gpt-oss になります。
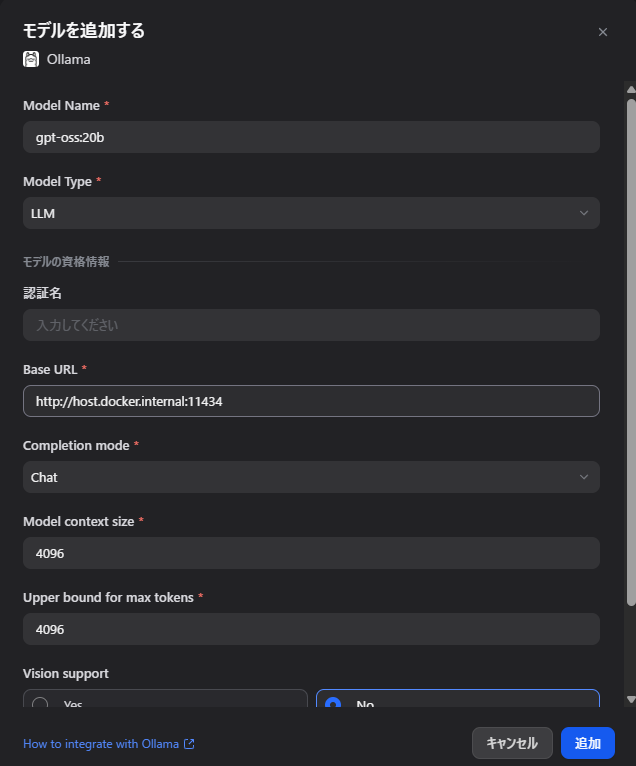
④ embeddinggemma:300m を埋め込みモデルとして登録
同様に「モデルを追加」から:
- モデルタイプ:
Text Embedding - モデル名:
embeddinggemma:300m - Base URL:
http://host.docker.internal:11434
保存後、「システムモデル設定」で:
- 埋め込みモデル:
embeddinggemma:300m
を選択して保存します。
これで Dify のナレッジベース機能が EmbeddingGemma を使うようになります。
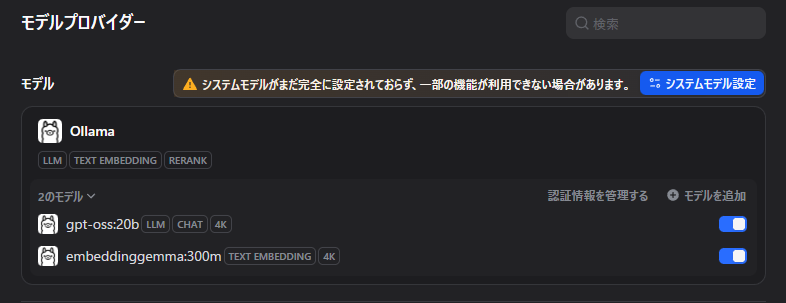
以下のように2つのモデルが表示されていればOK
4. ナレッジベースの作成(RAG 用コーパス)
① ナレッジベースを新規作成
- メニュー → 「ナレッジベース」
- 「ナレッジを作成」
- 名前・説明を入力
- 埋め込みモデルに
embeddinggemma:300mを指定して作成
EmbeddingGemma は多言語対応の軽量埋め込みモデルなので、
日本語を含む社内ドキュメントなどの RAG にもそのまま使えます。
以下が他のモデルとの比較になります。
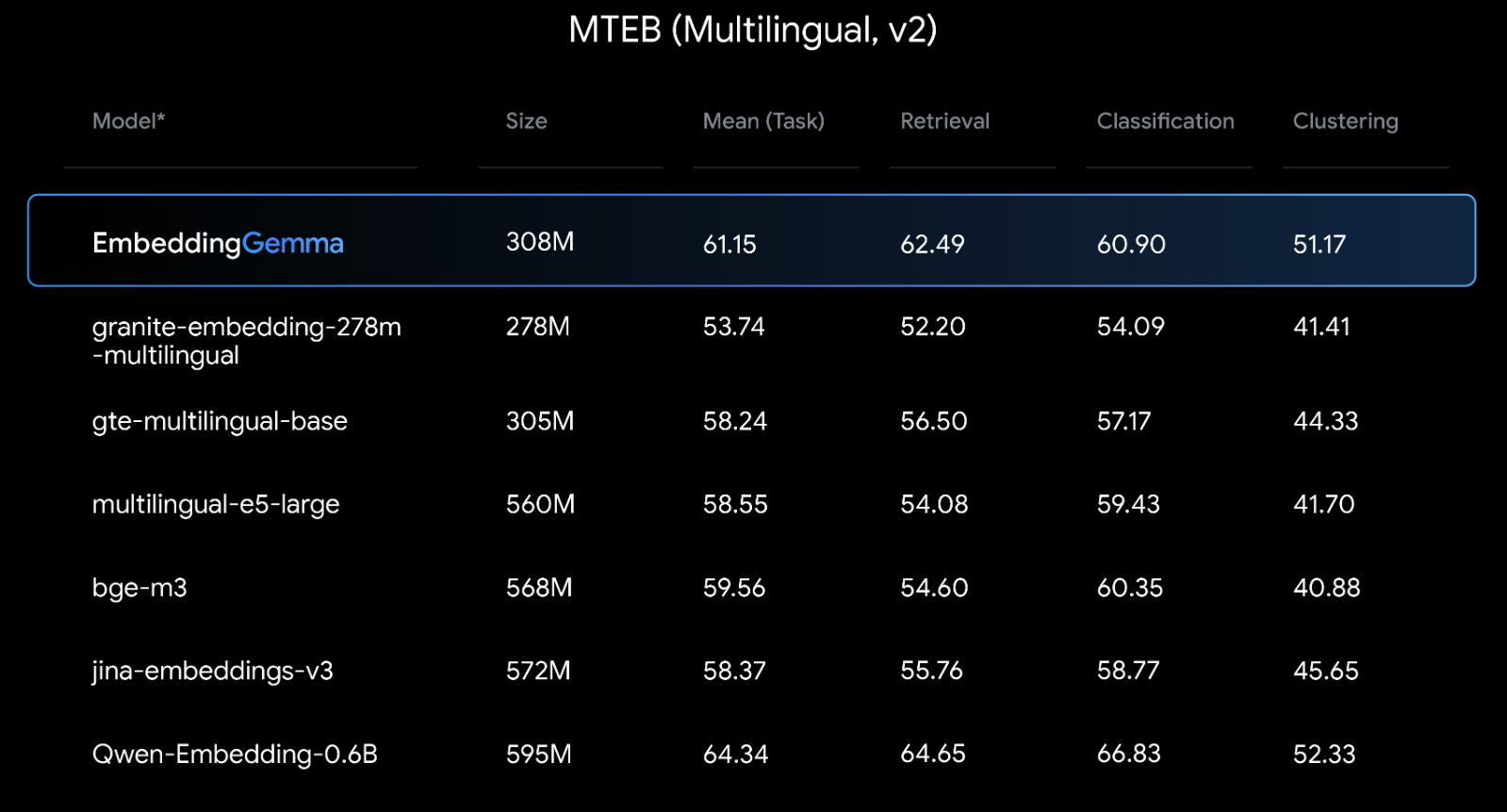
引用:https://developers.googleblog.com/en/introducing-embeddinggemma/
② ドキュメント投入とチャンク設定
作成したナレッジベースの画面から、ドキュメントを追加します。
今回は架空の会社のドキュメントデータを生成AIに作ってもらいました。
-
対応形式: PDF / Markdown / テキスト / Web ページ など
-
チャンク設定の例(日本語向けの目安):
- チャンクサイズ: 800〜1,000 文字
- オーバーラップ: 150〜200 文字
ドキュメントをアップロードすると、バックグラウンドで EmbeddingGemma によるベクトル化が走ります。
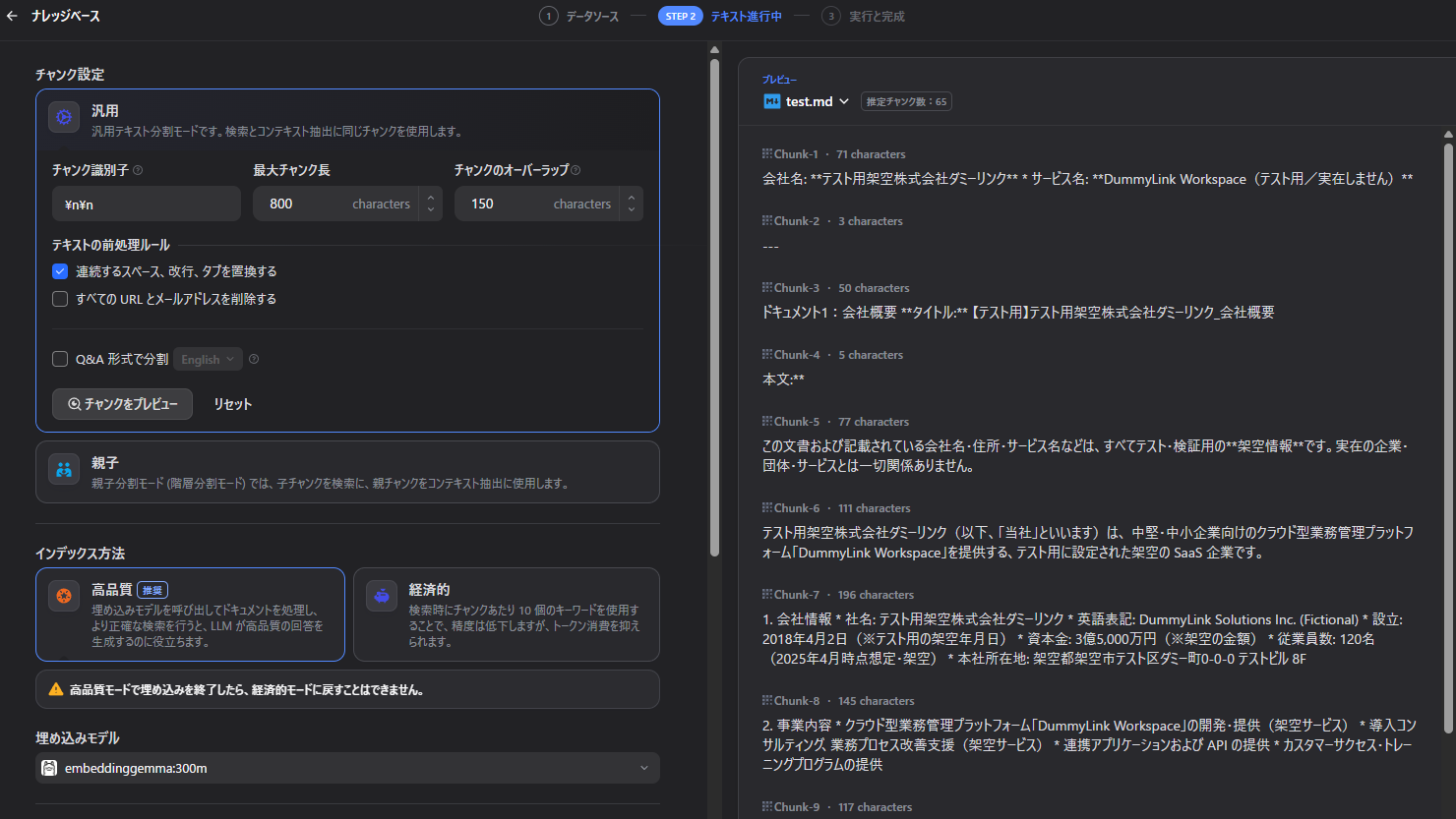
インデックスが完了すると「インデックス」タブにステータスが表示されます。
5. RAG チャットボットの作成(Dify アプリ)
① アプリ(チャットボット)を作る
- メニュー → 「スタジオ」
- 「最初から作成」
- 種類で「チャットボット」を選択
- 名前やアイコンを入れて作成

② ナレッジベースを接続して RAG にする
アプリの設定画面で:
-
「ナレッジ」または「コンテキスト」タブを開く
-
先ほど作成したナレッジベースを選択
-
検索設定を調整:
- 検索モード: デフォルトではマルチパス検索 1
- TopK: とりあえず 3〜5
- スコア閾値: 0.3〜0.4 くらいから調整

System プロンプトに:
あなたは会社やサービスについてドキュメントに基づいて回答するアシスタントです。
以下の「検索結果コンテキスト」だけを根拠として回答してください。
コンテキストにないことは「分かりません」と答えてください。
などと明示しておくと、幻覚を抑えやすくなります。
③ 推論モデルとして gpt-oss:20b を指定
アプリの「モデル」タブで:
- モデル:
gpt-oss:20b - Temperature: 0.2〜0.5(まずは 0.3)
- 最大トークン: 1024〜2048
あたりから始めて、応答の長さや安定性を見ながら調整します。

6. 動作確認と公開方法
① 動作確認
アプリ編集画面の「デバッグ」タブで、そのままチャットできます。
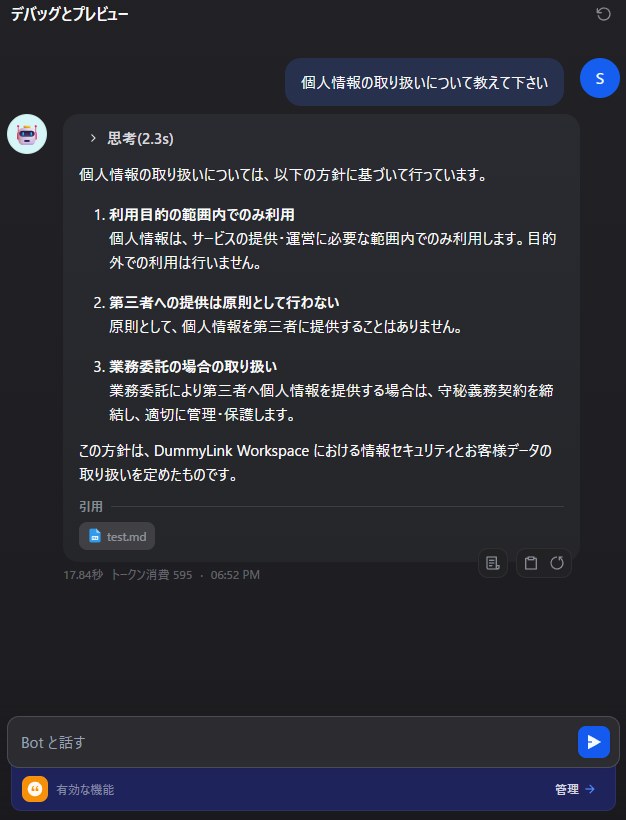
- ナレッジに入れた内容に関する質問を投げる
- 応答の下に表示される「引用」を確認し、
関連するチャンクがちゃんと引かれているか確認
ここで参照データからの適切な引用や、意図した回答ができていない場合は、
- チャンクサイズやオーバーラップ
- TopK
- スコア閾値
- プロンプト(コンテキストをどう LLM に渡しているか)
あたりを見直します。
6-2. 外部公開 / API 連携
「公開」タブから:
- アプリの URL を発行
- API Key を取得して、自作サイトから叩く
といった運用も可能です。
API パターンであっても、LLM と埋め込みはすべてローカルで完結します。
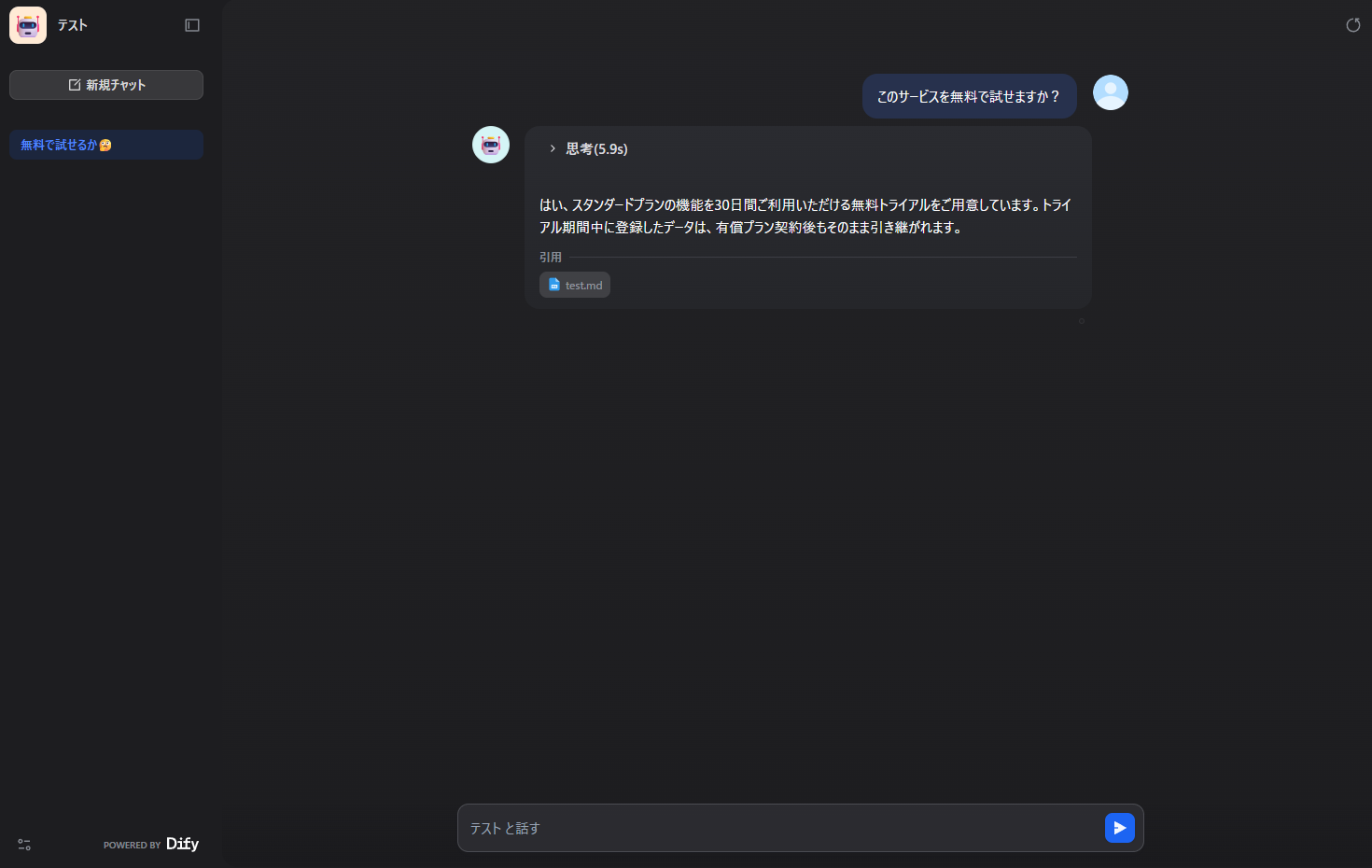
下の画像はシンプルに「公開」タブ→「アプリを実行」を選択した画面です
7. チューニングのポイント(RAG × EmbeddingGemma)
実際に動かしてみて、効き方に影響が大きかったのはこのあたりです。
① チャンクサイズとオーバーラップ
- 長すぎるチャンク: 関連度はそこそこでも、ノイズが増えがち
- 短すぎるチャンク: 文脈が切れてしまい、回答が部分的になる
目安としては:
- チャンク: 800〜1,000 文字
- オーバーラップ: 150〜200 文字
をスタート地点にして、ドキュメントの構造(仕様書か FAQ か、など)に合わせて調整するイメージです。
② Embedding モデルの適合性
EmbeddingGemma は:
- 軽量・高速
- 多言語対応
- ローカルで動かしやすい
というメリットがある一方で、
日本語検索タスク専用モデルと比べると、
ケースによっては検索精度が劣ることもあると思います。
「日本語の検索精度が物足りない」と感じたら、
- 同じナレッジベースを別の埋め込みモデルでも作って比較
- Dify 側で複数ナレッジを切り替えて A/B 的に検証
などをやってみると良いです。
③ TopK とスコアしきい値
- TopK を増やすと取りこぼしは減るが、LLM に渡るコンテキストが無駄に増える
- 閾値を上げるとノイズは減るが、ヒットしないケースも
個人的には:
- TopK: 3〜5
- スコアしきい値: 0.3〜0.4
あたりから始めて、
「関係ないコンテキストが混じるようなら TopK を減らす or しきい値を上げる」
という調整がしっくりきました。
④ LLM 側プロンプトの役割
RAG においては、埋め込みや検索だけでなく「LLM の制約」も重要です。
- コンテキスト以外からの知識で推測しない
- 必要に応じて、どのチャンクを根拠にしたか要約させる
- 「わからない」と答えてよいことを明示する
などを System プロンプトできちんと書いておくと、
ローカル LLM でもかなり安定して使えるようになります。
8. まとめ・所感
- Windows 11 + Docker Desktop + Ollama という、比較的身近な環境で
完全ローカル RAG チャットボット を構築できた - gpt-oss:20b はローカル LLM としてはかなりリッチで、
RAG 前提の QA ボット用途なら十分実用レベル - EmbeddingGemma は「完全ローカル・軽量・多言語」という観点でバランスが良く、個人用途にはかなり向いている
私の記事は以上となります。明日のNTTテクノクロス Advent Calendar 2025はこちらです!お楽しみに!
-
選択されたすべての知識ベースを同時にクエリし、結果を組み合わせる 引用:https://docs.dify.ai/ja/use-dify/nodes/knowledge-retrieval ↩