記事一覧ページなどで、タイトルやリンク先情報の一覧を一括で取得したい時、
Chromeの拡張ツール「Scraper」を利用してスクレイピング(scraping)して取得する方法の忘備録。
ScraperをChromeの拡張機能に追加する
Chrome ウェブストアにて、「拡張機能を追加」ボタンをクリックして拡張機能に追加する。
Scraper(Chrome ウェブストア)
https://chrome.google.com/webstore/detail/scraper/mbigbapnjcgaffohmbkdlecaccepngjd?hl=ja
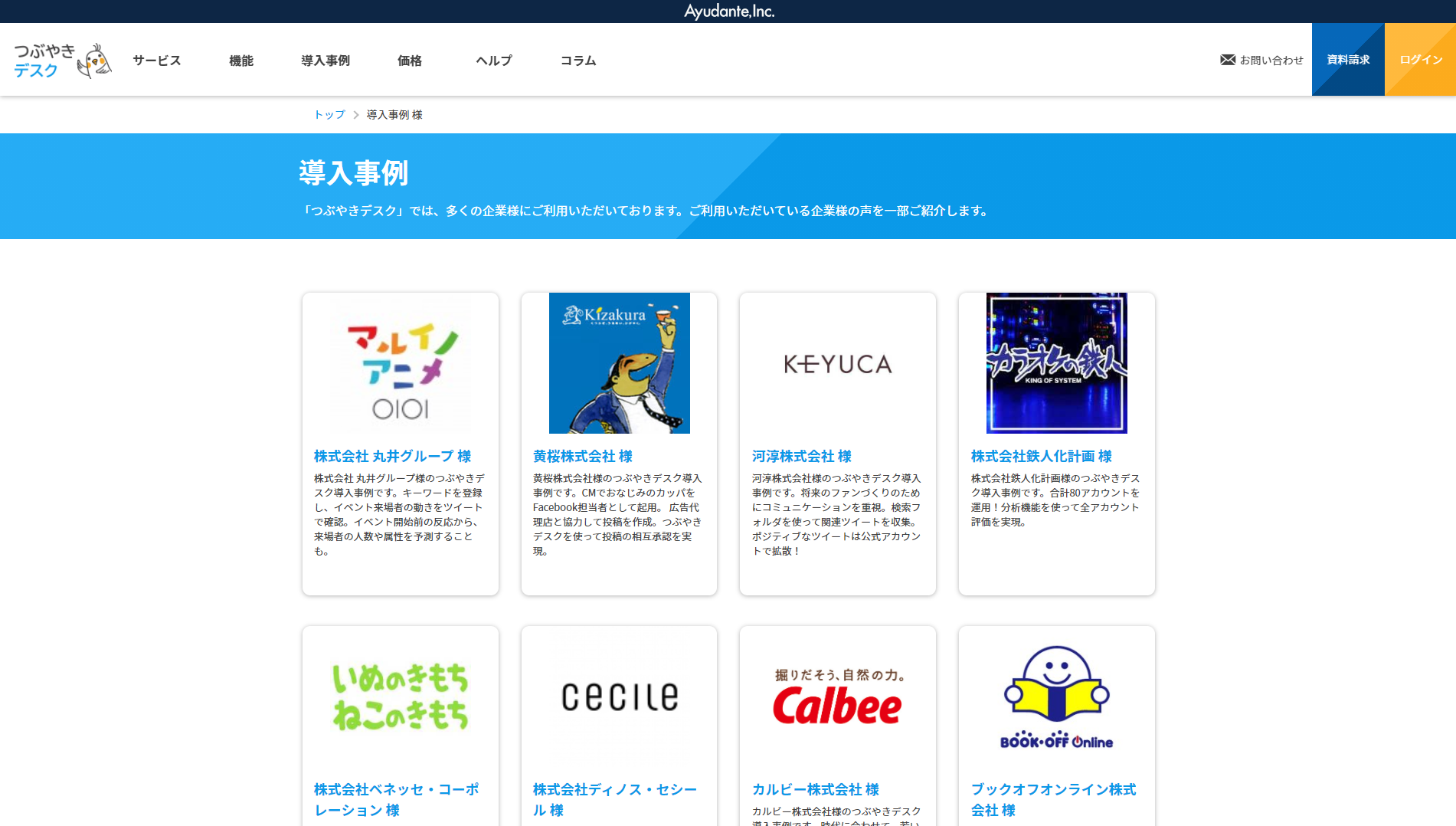
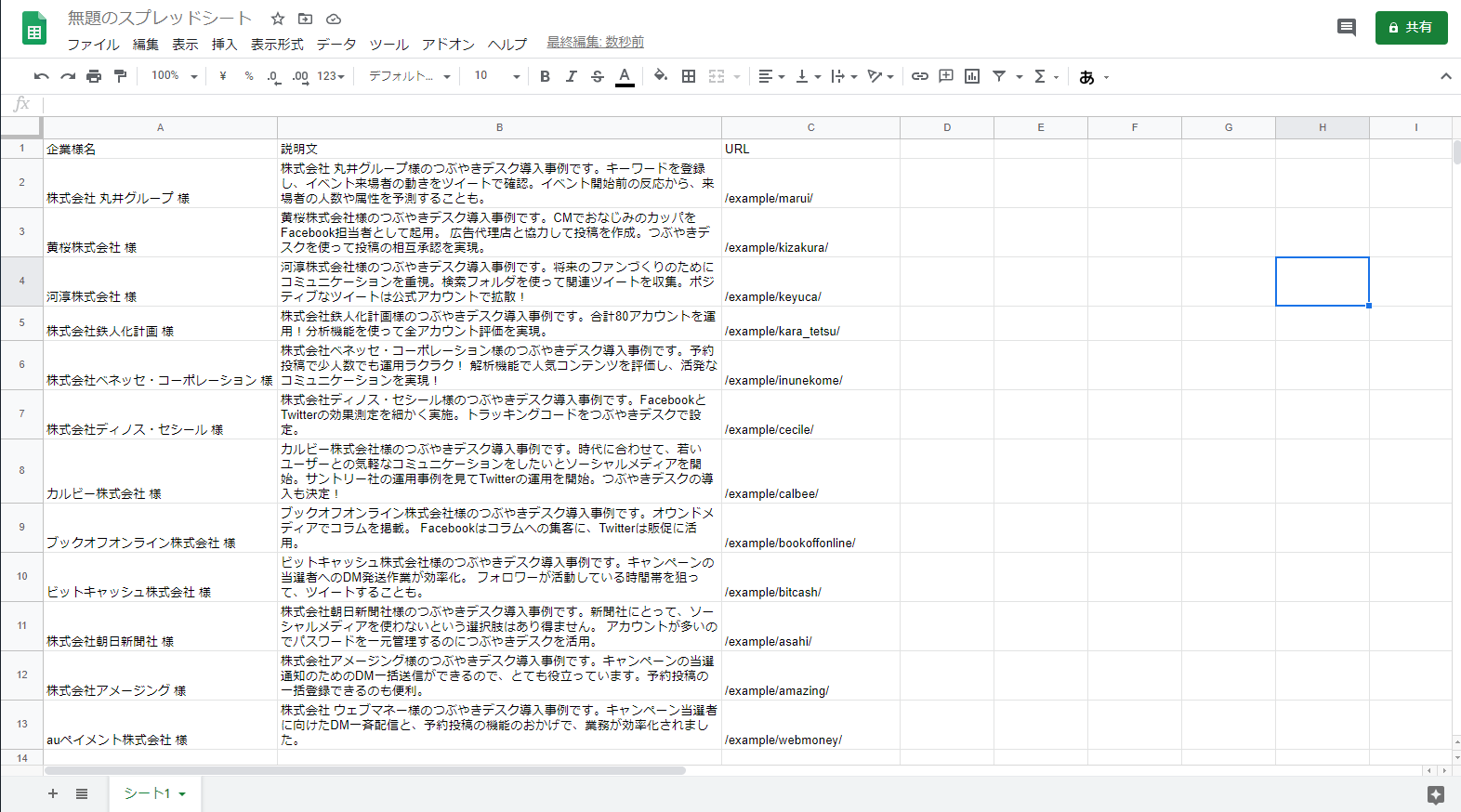
取得例:「つぶやきデスク」導入事例の個別の事例情報を取得したい時
導入事例の企業様名、説明文(description)、ページリンク先を
一括取得して一覧表にする場合の参考ページおよび参考画面を下記に記載。
■「つぶやきデスク」導入事例
https://twdesk.com/example/
■取得したい部分のコードサンプル
<!-- ※起点とするdiv要素 -->
<div class="archive-list">
<!-- ※起点とするdiv要素の子要素 -->
<div class="post-box">
<!-- ※起点とするdiv要素の1番目の孫要素 -->
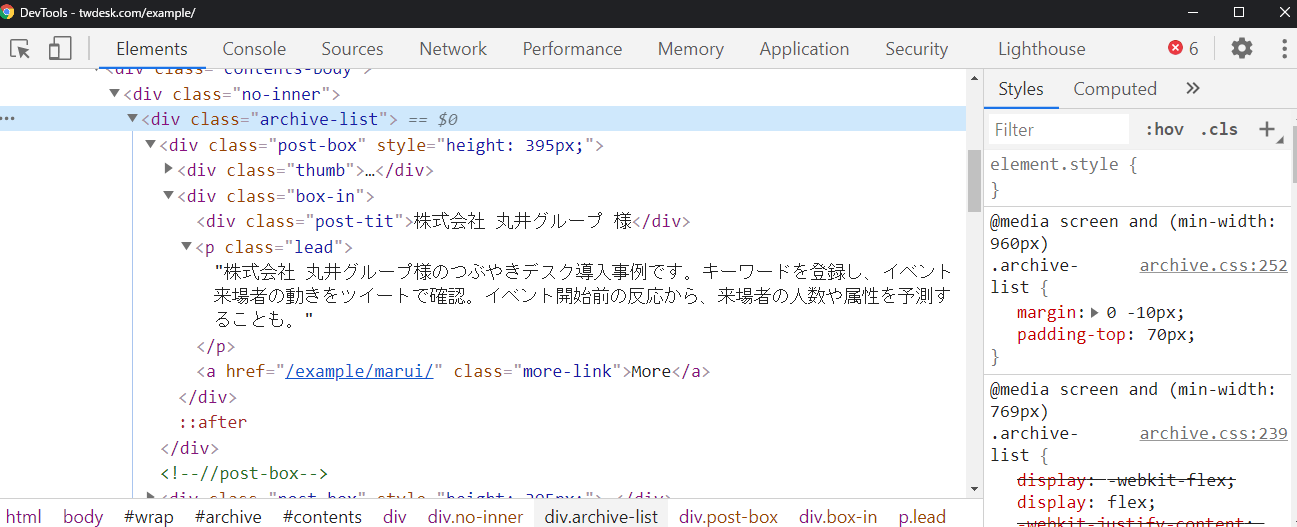
<div class="thumb"> <img width="110" height="110" src="/wp-content/uploads/2020/04/14_marui_anime_emblem.jpg" class="attachment-post-thumbnail size-post-thumbnail wp-post-image" alt="" /> </div>
<!-- ※起点とするdiv要素の2番目の孫要素 -->
<div class="box-in">
<!-- ※取得したい企業様名 -->
<div class="post-tit">株式会社 丸井グループ 様 </div>
<!-- ※取得したい説明文(description) -->
<p class="lead">株式会社 丸井グループ様のつぶやきデスク導入事例です。キーワードを登録し、イベント来場者の動きをツイートで確認。イベント開始前の反応から、来場者の人数や属性を予測することも。</p>
<!-- ※取得したいリンク先を持つaタグ -->
<a href="/example/marui/" class="more-link"> More</a> </div>
</div>
<!--//post-box-->
{ 中略 }
</div>
<!--//archive-list-->
《参考》Chromeのデベロッパーツールで見た時の該当箇所のコード
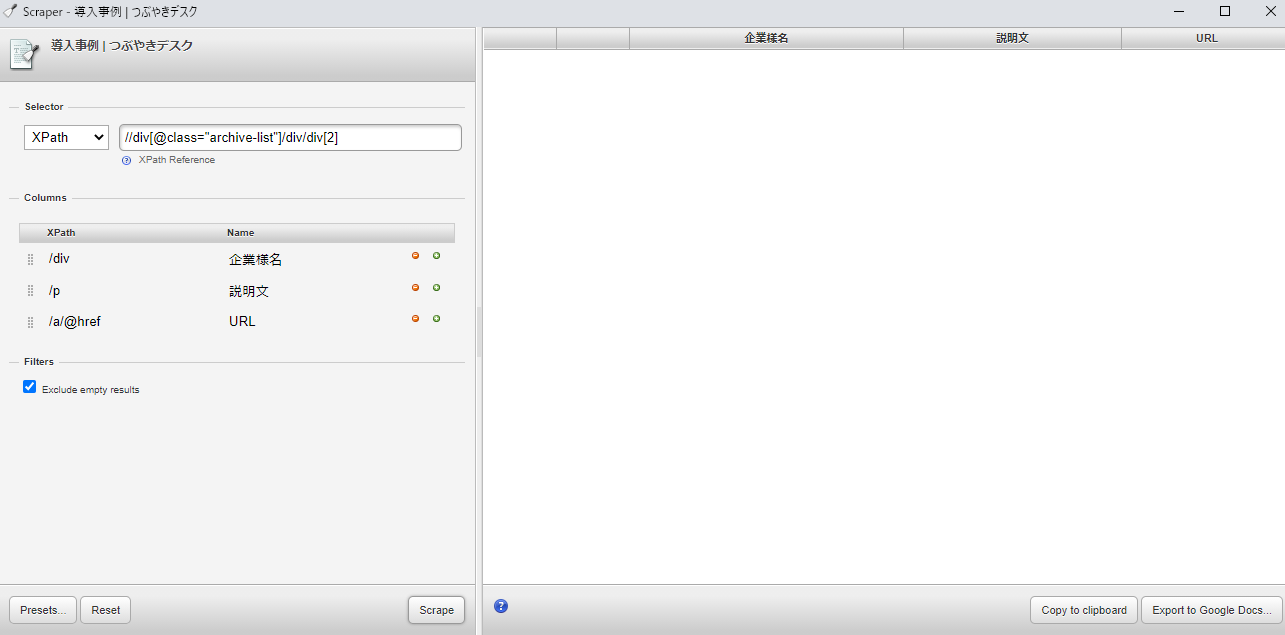
■「Scraper」で導入事例の企業様名、説明文(description)、ページリンク先を取得したときの画面
取得したい項目のパスを記載して、「Scrape」ボタンをクリックすると情報取得可能。
※selectorはXPathを利用
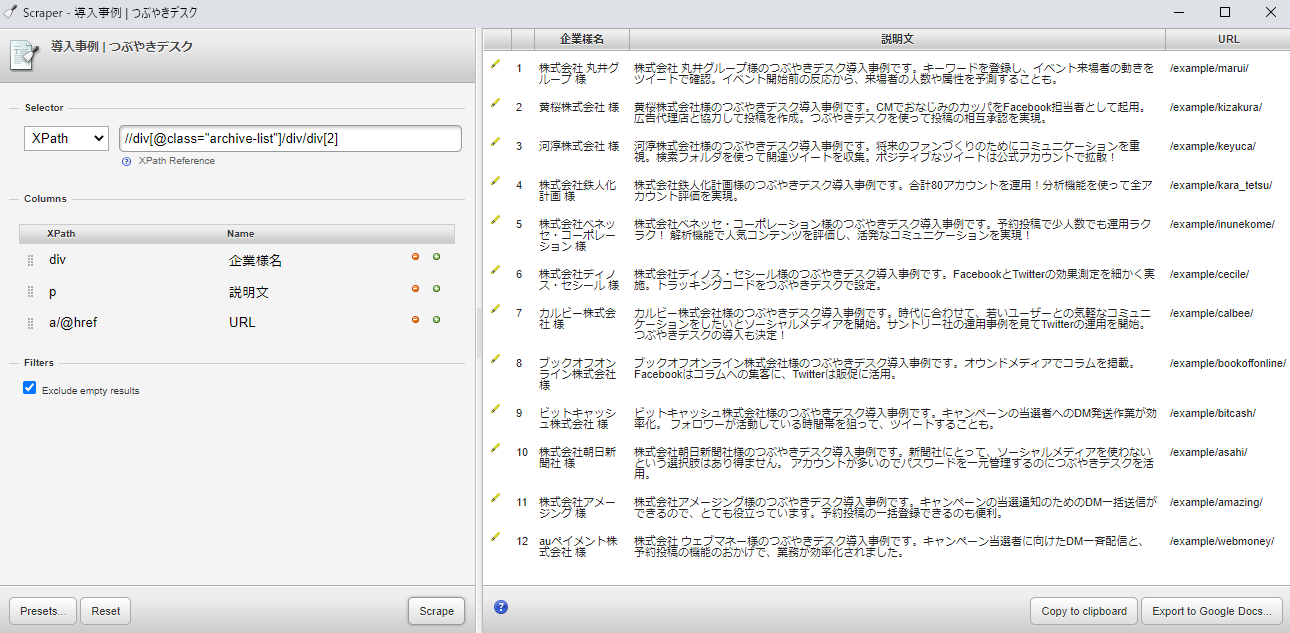
画面内の設定内容
■Selector
XPath : //div[@class="archive-list"]/div/div[2]
■Columns
{XPath} : {Name}
div : 企業様名
p : 説明文
a/@href : URL
情報取得後、「Copy to clipboard」をクリックすると、取得した情報をまるっとコピー可能。
Excelやスプレッドシートなどに貼り付けも可能でした。
書き方メモ
自分で書くとき用の書き方メモ
| やりたいこと | 記述 | 記述例 |
|---|---|---|
| 起点までのパスの記載を省略 (起点となるノードの子孫すべての集合) |
// | //article ※article要素を起点としたい場合 |
| n番目の要素を指定 | [n] | div[2] ※2番目のdiv要素を指定 |
| 特定のclassを持った要素の指定 | [@class="{クラス名}"] | div[@class="archive-list"] ※"archive-list"というクラスを持ったdiv要素を指定 |
| aタグのリンク先URLを指定 | a/@href | -- |
取得したい要素のXPathがよくわからない時
Chromeのディベロッパーツールにて
- 該当要素を右クリック
- 「Copy」にマウスをのせる
- 「Copy XPath」をクリックしてCopyする。(「Copy full XPath」でhtmlからのパスを取得も可能)
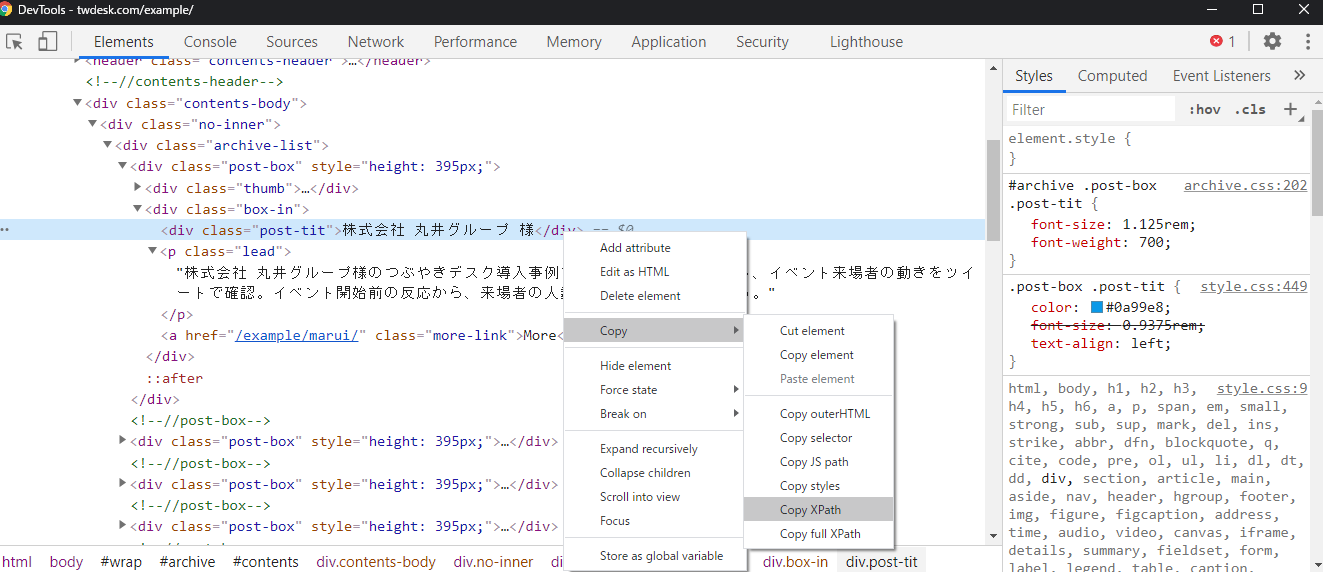
例:企業様名の要素をChromeのディベロッパーツールで取得した場合
「Copy XPath」 で取得:
//*[@id="contents"]/div[1]/div/div/div[1]/div[2]/div
「Copy full XPath」 で取得:
/html/body/div[1]/main/article/div[1]/div/div/div[1]/div[2]/div
ユニークなところまで遡るので、パスが長くなるのが難点(´・ω・`)
設定時の注意点
初回利用時、自分が設定でコケたポイント。
1.パスの最後にスラッシュ"/"はつけない。
SelectorにXPathを指定した際、最後の要素の後ろにスラッシュ"/"を付けるとエラー画面が出ます。
OKだった時の記載例:
//div[@class="archive-list"]/div/div[2]
エラーが出た時の記載例(後ろにスラッシュ"/"が入っていた):
//div[@class="archive-list"]/div/div[2]/
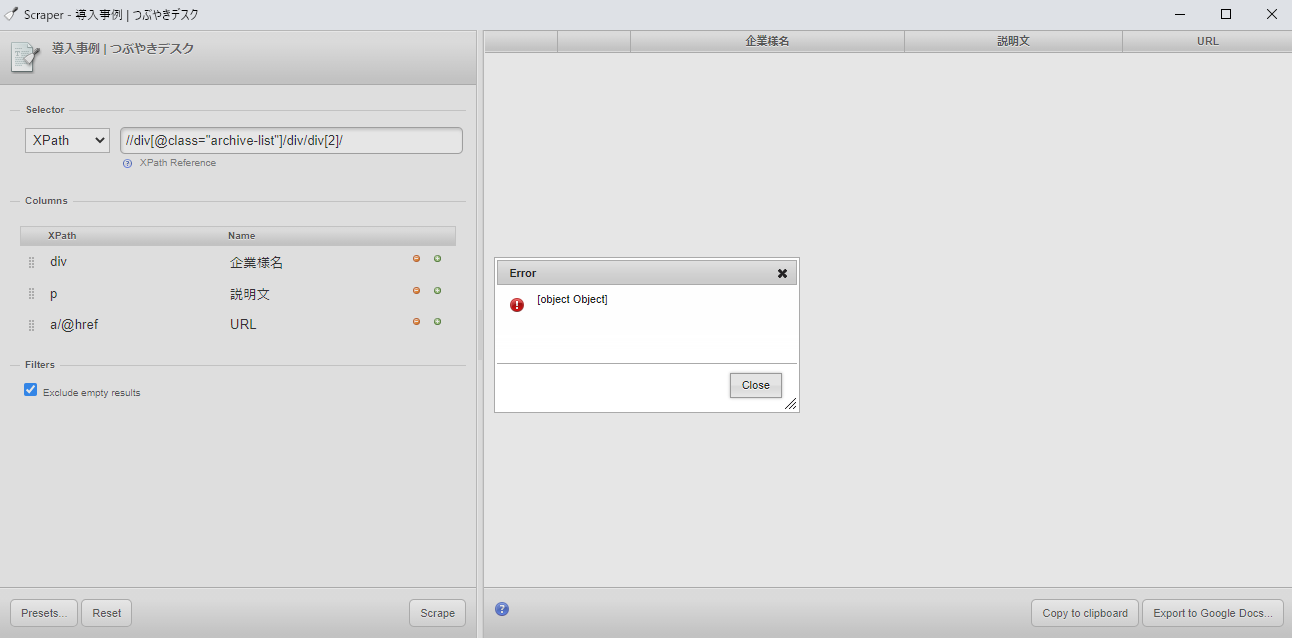
ColumnsのXPathでも同様の現象が生じます。
一箇所でも最後にスラッシュが入っていると、エラー画面が出ます。
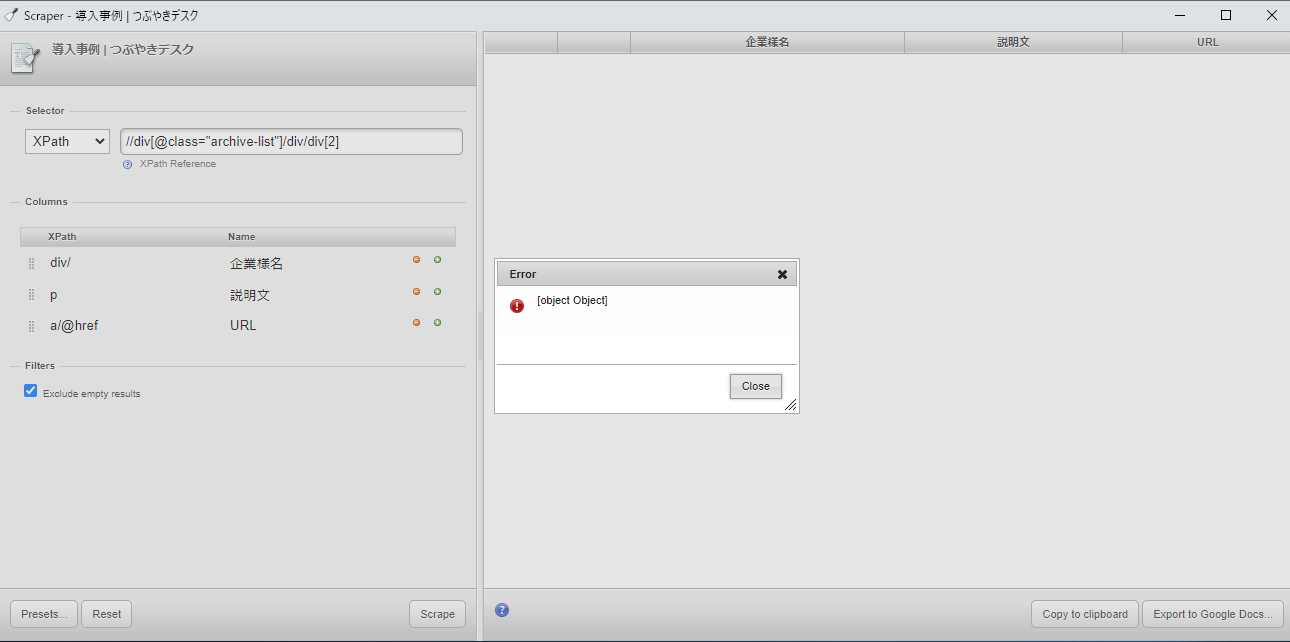
パスをコピペで貼り付けた時など生じやすいのでご注意を。
2.ColumnsのXPathに記載するパスの先頭にスラッシュ"/"はつけない。
ColumnsのXPathを記載する時、パスの頭にスラッシュ"/"をつけると、データが取得されず該当欄には何も記載されません。エラー画面は出ません。
これも、パスをコピペで貼り付けた時など生じやすいのでご注意を。