13章「boto3道場」「S3道場」(後編)
こんにちは、k_ukiです。現在「AWSではじめるクラウド開発入門」という書籍の13章を進めています。
この章では、PythonからAWS APIを操作するためのライブラリ「boto3」の理解を「S3,DynamoDB」のハンズオンで深めていくということを行いました。その中でも今回は「S3」のハンズオンで学んだことをまとめていきます。
なお、こちらの記事は後編となるのでまだ前半をご覧になられていない場合はこちらを先に見てください。
概要
- 空のバケットをデプロイ
- 【LEVEL1】Jupyter notebookを使用し、ローカルのディスクに保存されているデータを操作する。
前編はここまで
- 【LEVEL2】ディスク上ではなくメモリ上に保存されているデータを操作する。
- 【LEVEL3】署名付きURLを触ってみる。
LEVEL2 メモリ上のデータを操作する。
LEVEL1では、ローカルのディスク上にあるファイルをアップロードしたり、S3のオブジェクトをローカルのディスクにダウンロードしたりしてきました。しかし、データの送受信に毎回ディスクを介していると処理速度などに無駄が生じてしまいます。
LEVEL2では、メモリー上にあるデータのアップロード方法及び、S3のオブジェクトをローカルメモリにロードする方法について学んでいきます。
初めに、pandasを使ったCSVデータを読み書きする方法を見ていきます。
pandasとは、データ分析などで用いられるライブラリで、テーブルデータを操作するために用いられます。CSV,Excel,JSONなどといった拡張子のデータを扱うことができます。
使用するライブラリをインポートし、適当なテーブルを作成します。ここでは車のスペックをまとめた表を作成しています。
また、テーブルのことをDataFrameオブジェクトといいます。
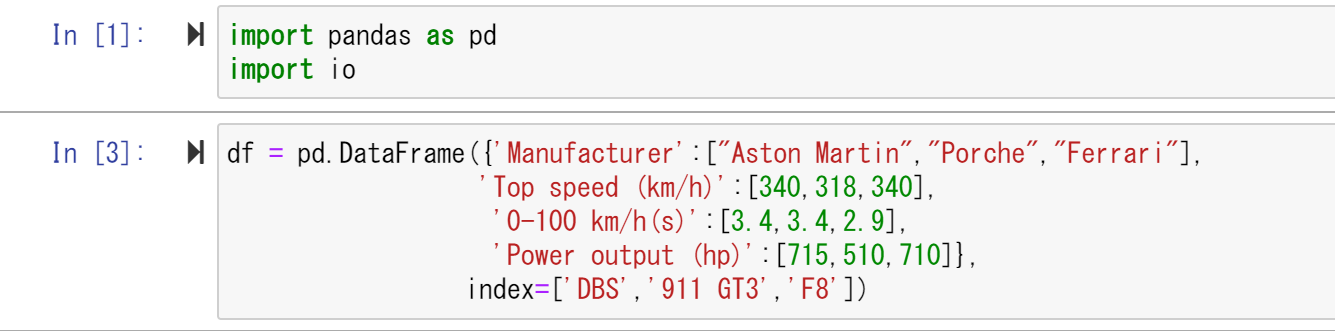
定義したテーブル(df)を出力してみます。
df
先ほど作成した表が正しく表示されました。
次に、このテーブルをCSV形式でS3にアップロードします。
以下のコードを記述します。
with io.BytesIO() as stream:
df.to_csv(stream, index_label="Car")
resp = bucket.put_object(
Key="data.csv",
Body=stream.getvalue()
)
コードの説明をします。
まずはwith構文についてです。with構文について簡単に話すと開始と終了がセットになっている処理を行う際に使用する構文です。例えば、以下の処理が該当します。
- ファイルの読み書き
- DBの更新、書き込み処理
with構文を使用することで処理の完了後自動的に終了してくれます。ファイルの閉じ忘れなどがなくなるということですね。
【参考】https://prograshi.com/language/python/what-is-a-with-statement/
次に、io.BytesIO()メソッドはメモリ上でバイナリデータを扱うためのメソッドです。このメソッドを呼び出すことで、CSVデータを書き込むためのメモリ上のストリームを用意しています。ちなみに、ストリームはデータの入出力におけるデータの流れのことです。
df.to_csv()メソッドを呼び出すことで、テーブルの情報をCSVに書き出してメモリのストリームに一時的に格納します。
最後に、bucket.put_object()でS3にアップロードする内容を記述しています。引数としてKeyを、Bodyとしてストリームに保存していた内容を渡しています。
次にS3に保存しているCSVデータをローカルのメモリに読み込んでいきます。こちらも以下のコードを入力します。
obj = bucket.object("data.csv").get()
stream = io.BytesIO(obj.get("Body").read())
df2 = pd.read_csv(stream, index_col="Car")
bucket.Object("data.csv")と記述することで、data.csvというKeyのS3オブジェクトを作成し、それに対しget()メソッドを呼び出すことでS3からdata.csvというオブジェクトを取得します。
次に、get("Body")を呼ぶことによって、指定したKeyに対応するBodyの情報が入ったオブジェクトが生成されます。これに対し、read()メソッドを呼び出すことでデータの内容がダウンロードされます。最後に、read_csv()の引数に取得されたデータを渡している。
以上が、S3に保存しているデータをローカルのメモリに読み込む方法です。
ここまでは、扱うデータとしてテーブルのデータを扱ってきました。ここからは画像データを読み書きする方法について実践していきます。
ここでは、PILを使って読み書きを行っていきます。まず、ライブラリのインストールを行っていきます。
from PIL import Image
import numpy as np
from matplotlib import pyplot as plt
次に、用意されているテスト用の画像をロードします。
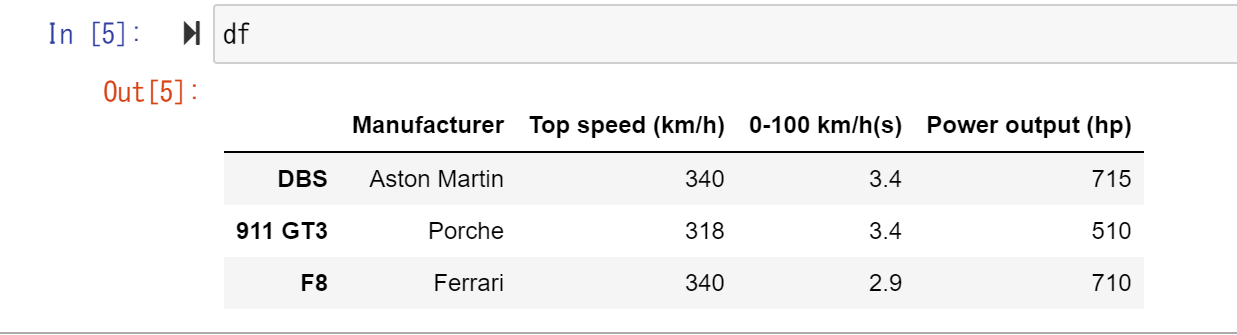
img = Image.open("clownfish.jpg")
最後に現在ロードした画像を表示させてみます。
以下のように画像が表示されたら成功です。
plt.imshow(np.asarray(img))
画像が表示されたら、メモリにロードされた画像をS3にアップロードしていきます。今回は以下のコードを使用します。
with io.BytesIO() as buffer:
img.save(buffer, "PNG")
resp = bucket.put_object(
Key="clownfish.png",
Body=buffer,getvalue()
)
ここではsave()メソッドを使用することでメモリバッファ上に書き込みを行います。ここでは第二引数でPNG形式での保存を指定しています。
resp変数の箇所はテーブルのデータをアップロードした場合と同様なので省略します。
アップロードが終わったらImageオブジェクトを閉じておきます。
img.close()
また、AWSコンソールを確認すると正しく"clownfish.png"がアップロードされました。
最後に、バケットの画像情報をメモリに直接ロードする方法について見ていきます。次のコードを入力します。
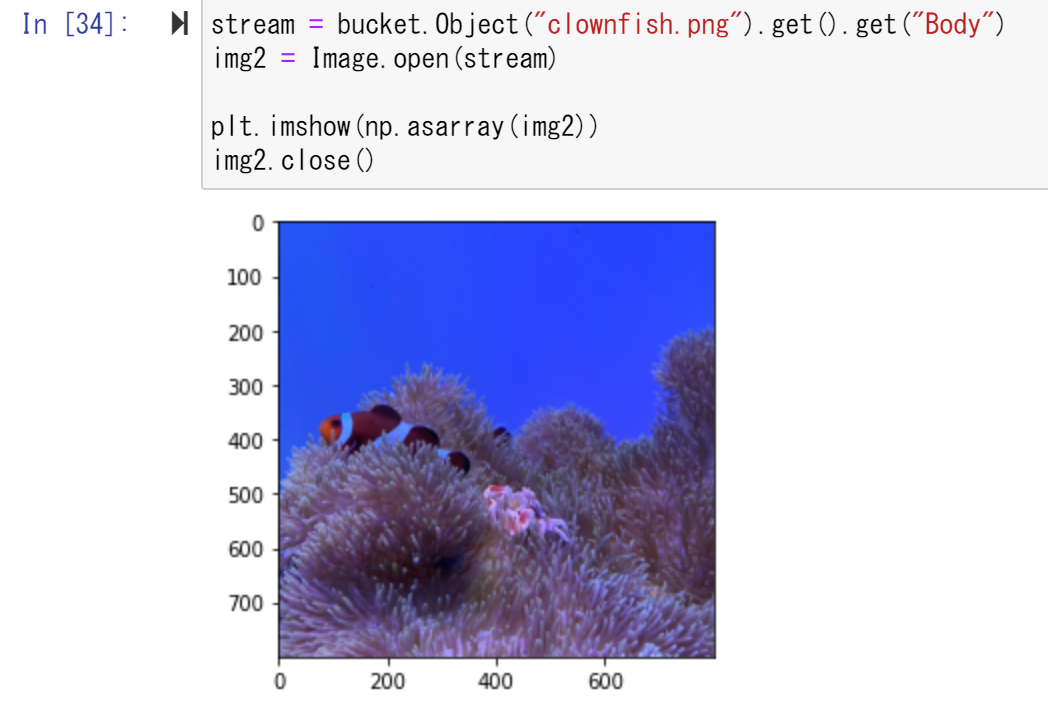
stream = bucket.Object("clownfish.png").get().get("Body")
img2 = Image.open(stream)
plt.imshow(np.asarray(img2))
img2.close()
やっていることは、テーブルのデータをロードした時や画像を出力する際と、ほとんど同様なので割愛します。
正しくクマノミの画像が表示されたら成功です。
LEVEL3 Presigned URL
S3道場の最後はPresigned URL(署名付きURL)の使用方法について見ていきます。
Presigned URLを発行することで、管理ユーザ以外のユーザがオブジェクトに対し書き込み、読み込み等の操作を行えるようになります。WEBサービスなどでは、ユーザにアップロード、ダウンロードを行えるようにする機構で利用されることがあり、S3を使用していく中では重要な項目となっています。
Presigned URL以外の、オブジェクトのアップロード及び、ダウンロードを実行する手段として、Lambdaにリクエストを送信する方法が挙げられると思います。しかし、この方法だと以下のような欠点があります。
- Lambdaを経由することによる通信速度の低下
- Lambdaを使用する分の料金の発生(データ容量が大きい場合など)
Presigned URLを使用することでクライアントとの通信の効率化も果たすことができます。
さっそく使い方を見ていきます。まずはhttp通信を行うためのライブラリをインポートします。
import requests
requestsはpythonのHTTP通信を行うためのライブラリでこれを使用することでHTMLの取得などを簡単に行うことができます。
requestsのインポートが完了したら、S3のclientオブジェクトを作成します。Presigned URLを作成するAPIはclientオブジェクトのみサポートされています。
client = session.client("s3")
clientオブジェクトが作成出来たらS3へアップロードを行うPresigned URLを作成します。
resp = client.generate_presigned_post(
Bucket=bucket.name,
Key="upload.txt",
ExpiresIn=600
)
print(resp)
コードの説明に移ります。
generate_presigned_post()メソッドはアップロード専用のPresigned URLを発行します。アップロード専用のためS3からローカルなどへダウンロードすることはできません。
Bucket=bucket.name ではURLを発行するために使用するバケットを指定を行っており、Key="upload.txt"はアップロードするオブジェクトのKeyをupload.txtにするための記述です。
ExpiresIn=600 はURLが失効する時間の指定を行っている記述となっており、ここでは発行から600秒(10分)でURLが失効するように設定しています。
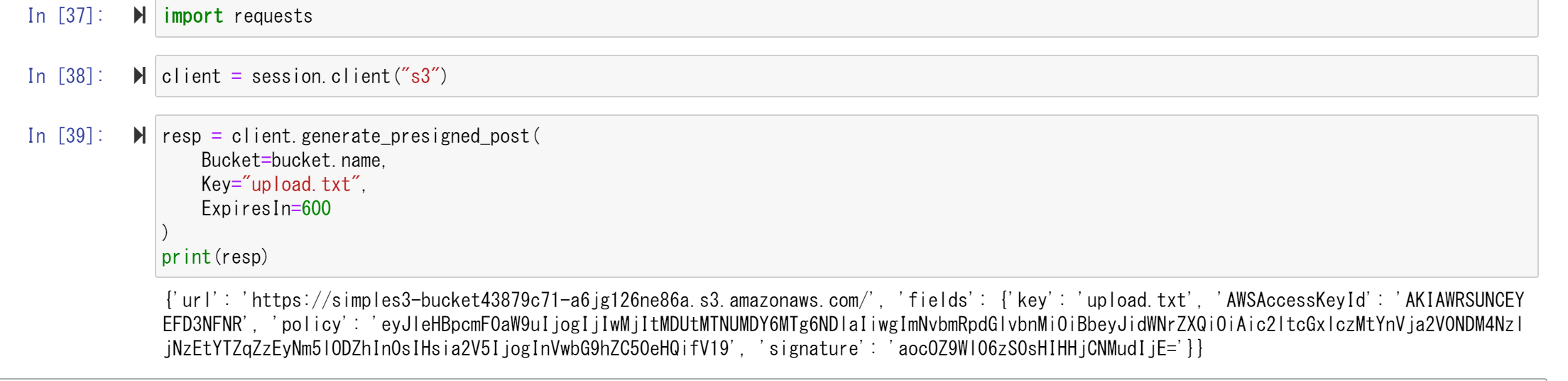
generate_presigned_post()が実行されると以下のような実行結果が得られるはずです。
JSON形式でアップロード先のURLや認証情報である"fields"が出力されています。
次に返されたPresigned URLを用いてアップロードを行ってみます。
resp2 = requests.post(
resp["url"],
data=resp["fields"],
files={'file':("dummy.text","Hello world!")}
)
print("Upload success?",resp2.status_code == 204)
requests.postの引数として先ほど返されたURLと認証情報を格納しています。
記述を実行してみます。
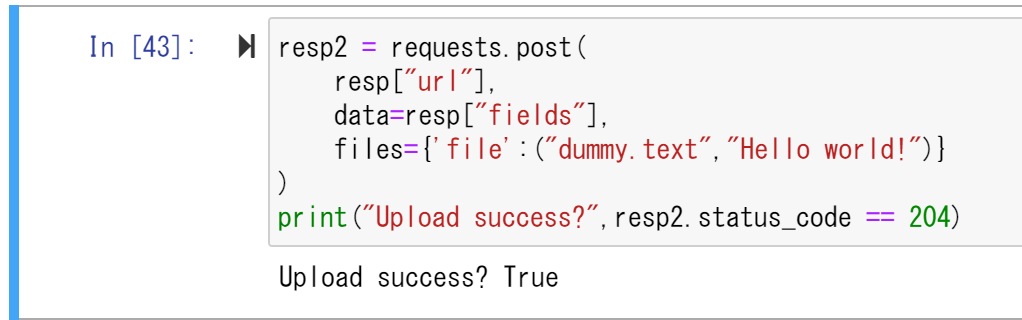
"Upload success? True"と返されたため、アップロードが正しく実行されたことが分かります。
先ほどはアップロード用のpresigned URLを発行しました。次に、オブジェクトのダウンロードを行うためのPresigned URLを発行してみます。
以下のコードを入力します。
resp3 = client.generate_presigned_url(
ClientMethod="get_object",
Params={
'Bucket':bucket.name,
'Key':"upload.txt",
},
ExpiresIn=600
}
print(resp3)
generate_presigned_url()は汎用的なPresigned URLを生成します。ClientMethodに"get_object"を記述することでHTTPメソッドでいうと [GET] すなわち、ダウンロードを許可しています。
Paramsでは、バケット名とKeyの設定を行っています。正しく実行されると以下のようなURLが返されます。
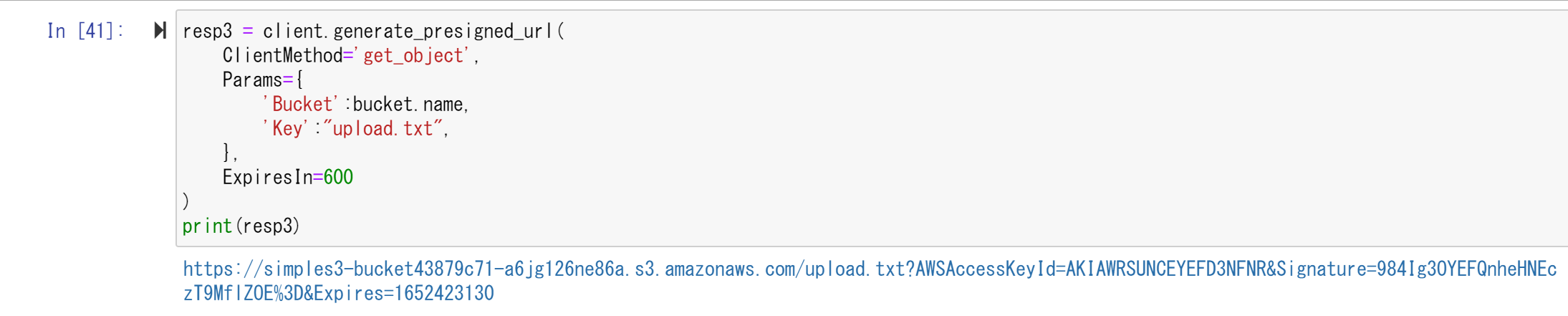
このURLがオブジェクトのダウンロードを行うためのURLとなっており、ブラウザ上でこのURLにアクセスするとダウンロードすることができます。
これでPresigned URLの基本的な使い方を覚えることができました。
今回の演習は以上になるので、スタックを削除しておきます。
$ cdk destroy
最後に
以上が13章「boto道場」の「S3道場」で学んだことになります。
LEVEL1ではディスクに保存されているデータを操作する方法、LEVEL2ではメモリ上に保存されているデータを操作する方法、LEVEL3ではS3オブジェクトを効率的に送受信するために必要はPresign URLについて学ぶことができました。