はじめに
Windows環境(WSL2)で、LiteLLM Python SDK、LiteLLM Proxyを利用してローカルLLM(Ollama)を呼び出す手順をまとめました。
LiteLLMを使用することで、OpenAI互換のインターフェースでコードを書き換えることなく様々なモデルを簡単に切り替えて利用できるようになります。
前提
- WSL2を有効化。Ubuntuがインストール済みであること。
- pythonがインストール済みであること。
参考資料
- LiteLLM Python SDK Getting Started | liteLLM
- LiteLLM AIゲートウェイ(プロキシ) CLI - クイックスタート |liteLLM
- LiteLLM入門:OpenAI互換フォーマットでLLM APIを簡単に呼び出す方法
- WSLでローカルLLMを動かす #ollama - Qiita
プロジェクトの作成とLiteLLM Python SDK、LiteLLM Proxyのインストール
プロジェクト用のフォルダを作成し、必要なライブラリをインストールする。
プロジェクトの作成
WSL2の任意の場所にプロジェクトフォルダを作成する。
VSCodeのターミナルなどから作成したプロジェクトフォルダを開く。
cd {作成したプロジェクトフォルダ}
pipfileの新規作成、python-dotenvをインストール
以下を実行する。
このプロジェクト内にpipfileを新規作成し、python-dotenvをインストールする。
pipenv install python-dotenv
LiteLLM Python SDKのインストール
以下を実行し、LiteLLMをインストールする。
pipenv install litellm
LiteLLM Proxyのインストール
以下を実行し、LiteLLM Proxyをインストールする。
pipenv install "litellm[proxy]"
以下を実行し、LiteLLM Proxyがインストールされていることを確認する。
pipenv run pip list | grep -i litellm
【実行結果(例)】
実行結果にlitellm、litellm-proxy-extrasが出力される。
$ pipenv run pip list | grep -i litellm
litellm 1.81.10
litellm-enterprise 0.1.31
litellm-proxy-extras 0.4.34
Ollamaのセットアップとモデルの準備
ローカルでLLMを動かすための「Ollama」をインストールし、モデルを準備する。
Ollamaのインストール
以下を実行し、Ollamaをインストールする。
curl -fsSL https://ollama.com/install.sh | sh
Ollamaサーバーを起動する・モデルのダウンロード
Ollamaサーバーの起動とモデルのダウンロードを行う。
Ollamaサーバーを起動する
ターミナルを開いて以下を実行し、待ち受け状態にする。
ollama serve
別のターミナルを開いて以下を実行し、Ollamaが起動していることを確認する。
curl http://localhost:11434
【実行結果】
以下が出力される。
Ollama is running
モデルのダウンロード
以下を実行し、モデルをダウンロードする。
ollama pull llama3.2:1b
以下を実行し、ダウンロードしたモデルと直接対話できるか確認する。
ollama run llama3.2:1b
【実行結果(例)】
以下が出力される。
$ ollama run llama3.2:1b
>>> こんにちは、調子はどうですか?
こんにちは!私は、調子は良好です。
>>> Send a message (/? for help)
PythonスクリプトでLiteLLM(SDK)から直接ローカルLLM(ollama)を呼び出す
.envの設定
プロジェクトフォルダの直下に.envファイルを作成し、以下を定義する。
OLLAMA_API_BASE=http://localhost:11434
OLLAMA_API_KEY=ollama # ダミーで良い
Pythonスクリプトを作成
LiteLLM(SDK)からOllamaのローカルLLMを呼び出すスクリプトを作成する。
以下のコードを作成し、任意のファイル名(test_ollama.pyなど)で保存する。
from dotenv import load_dotenv
from litellm import completion
import os
load_dotenv() # .env ファイルから環境変数を読み込む
# LiteLLMを使用したチャット補完
get_response = completion(
model="ollama/llama3.2:1b",
messages=[
{"role": "system", "content": "あなたは親切で簡潔なアシスタントです。"},
{"role": "user", "content": "こんにちは。今日の天気は?"}
],
api_base=os.getenv("OLLAMA_API_BASE", "http://localhost:11434"),
api_key=os.getenv("OLLAMA_API_KEY", "ollama"),
temperature=0.3,
max_tokens=50 # 応答の上限
)
# 応答の表示
print(get_response.choices[0].message["content"])
completion関数
OpenAI APIと互換性のあるインターフェースを提供する関数。
【引数】
| 項目 | 説明 |
|---|---|
| model | プロバイダ名/モデル名 の形式で指定。 |
| messages | 会話内容。リスト形式。role(system/user/assistant)とcontentを含む。 ※system:AIの性格・方針を決める。 user:ユーザー入力(実際の質問内容) |
| api_base | 接続先URL。 |
| api_key | 認証キー。ローカルのOllamaでは不要だが、インターフェース維持のため任意の文字列を入れる。 |
| temperature | 回答の多様性。0 に近いほど決定的、1 に近いほど創造的な回答になる。 |
| max_tokens | 応答メッセージの最大トークン数(長さ)の上限。 |
【戻り値】
ModelResponseオブジェクト。OpenAI APIのレスポンス形式に準拠。response.choices[0].message.content で回答テキストを取得できる。
実行と結果の確認
ターミナルを開いて、以下を実行する。
pipenv run python test_ollama.py
【実行結果(例)】
戻り値のオブジェクトmessage["content"]にモデルからの応答メッセージが出力される。
$ pipenv run python test_ollama.py
Loading .env environment variables...
今日の天気は Sunny で、風が強いです。
LiteLLM ProxyからローカルLLMを呼び出す準備
設定ファイルの準備
プロジェクトフォルダ内に2つの設定ファイルを作成する。
.envの設定
.envファイルを作成し、以下を定義する。
LITELLM_PROXY_API_BASE=http://localhost:4000 # LiteLLM ProxyのAPIエンドポイントURLを指定
LITELLM_PROXY_API_KEY=sk-user-abcdef1234 # config.yamlのvirtual_keyと一致させる
config.yamlの設定
config.yamlファイルを作成し、以下を定義する。
# LiteLLM Proxyの設定
# master_keyなどProxyの基盤設定
litellm_settings:
master_key: sk-admin-1234 # 管理者用のキー(何でも良い)
# クライアント用のAPI Key(バーチャルキー)とユーザーID
virtual_keys:
- key: sk-user-abcdef1234 # クライアント用バーチャルキー
user_id: "user1"
# 論理モデル名 → 実モデル(Ollamaなど)へのルーティング設定
model_list:
- model_name: my-ollama-model # クライアントが呼ぶモデル名(これをプロンプトで指定)
litellm_params:
model: "ollama/llama3.2:1b" # 実際に呼びたいモデル
api_base: "http://localhost:11434"
api_key: "ollama" # Ollama用ダミーキー(任意)
LiteLLM Proxyの起動
別のターミナルを開いて以下を実行し、config.yaml を読み込んでLiteLLM Proxyを起動する。
pipenv run litellm --config ./config.yaml
LiteLLM Proxyが起動後、APIの待ち受けが開始される。
http://localhost:4000 がOpenAI互換のAPIエンドポイントとして動作し、外部からのリクエストを待ち受ける状態になる。
LiteLLM ProxyのUIからローカルLLM(ollama)を呼び出す
LiteLLM Proxyが提供するWeb UI(Swagger UI)からGUIベースで実行する方法。
ブラウザでアクセス
ブラウザで http://localhost:4000 を開くとSwagger UIが表示される。
認証設定(Authorize)
画面右上の「Authorize」ボタンをクリックし、config.yamlで設定したバーチャルキー(例: sk-user-abcdef1234)を入力して認証を完了させる。
リクエストの実行
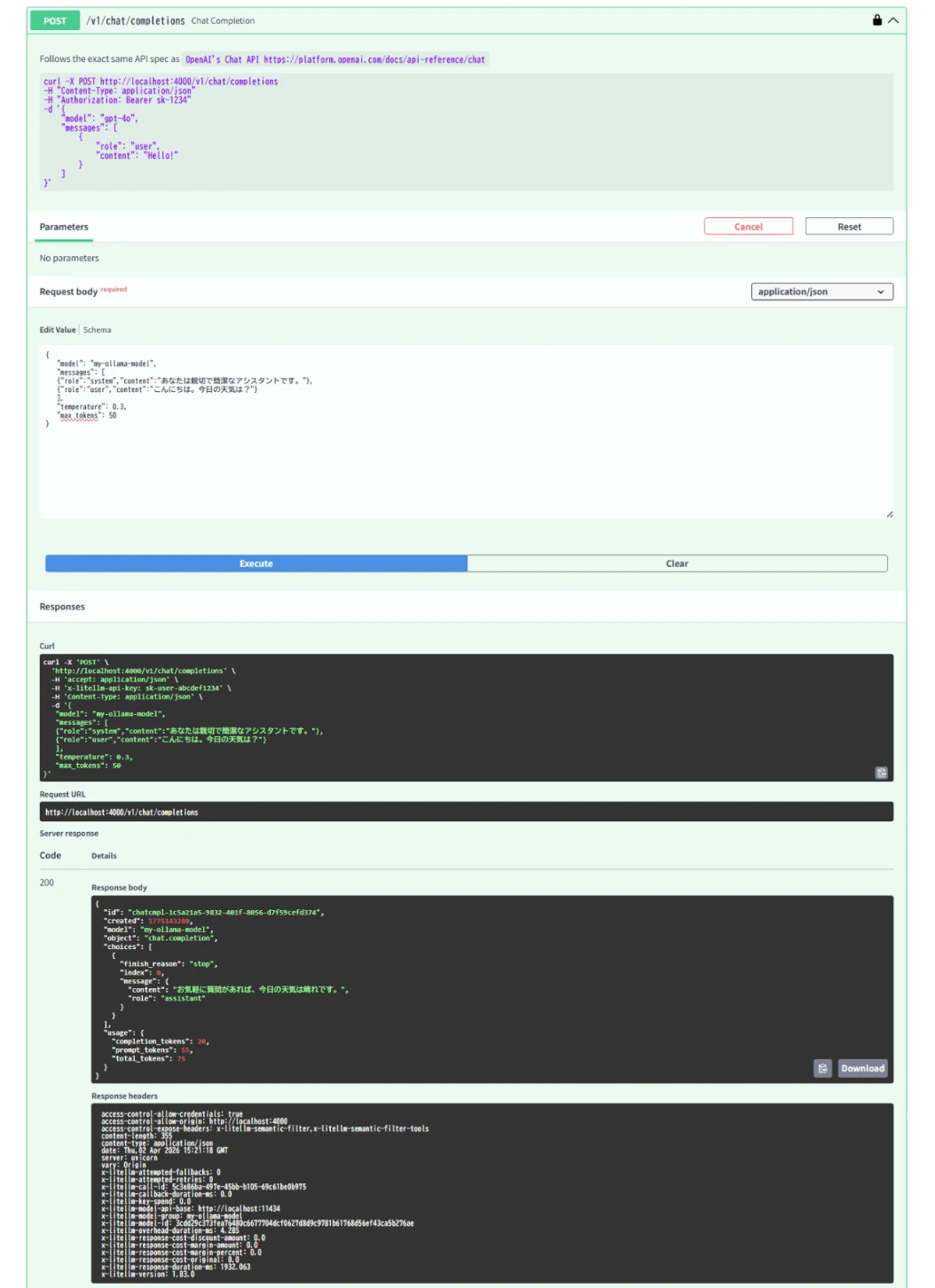
「model management」の中にあるPOST v1/chat/completionsを開く。
Parametersの左にある 「Try it out」をクリックする。
Request bodyの入力箇所に以下を入力し、「Execute」を押下する。
{
"model": "my-ollama-model",
"messages": [
{"role":"system","content":"あなたは親切で簡潔なアシスタントです。"},
{"role":"user","content":"こんにちは。今日の天気は?"}
],
"temperature": 0.3,
"max_tokens": 50
}
結果の確認
「Server response」欄にコード200とモデルからの応答メッセージ(JSON形式)が表示されれば成功。
CURLコマンドを使ってLiteLLM ProxyからローカルLLM(ollama)を呼び出す
実行と結果の確認
別のターミナルを開いて、以下を実行する。
$ curl -s -X POST http://localhost:4000/v1/chat/completions \
-H "Authorization: Bearer sk-user-abcdef1234" \
-H "Content-Type: application/json" \
-d '{
"model": "my-ollama-model",
"messages": [
{"role":"system","content":"あなたは親切で簡潔なアシスタントです。"},
{"role":"user","content":"こんにちは。こんにちは。今日の天気は?"}
],
"temperature": 0.3,
"max_tokens": 50
}'
【実行結果(例)】
戻り値のオブジェクトmessage["content"]にモデルからの応答メッセージが出力される。
{"id":"chatcmpl-148cf075-a39c-4056-97e5-6ace195ca7fb","created":1775143181,"model":"my-ollama-model","object":"chat.completion","choices":[{"finish_reason":"stop","index":0,"message":{"content":"今日の天気は Sunny で、暑いですが、風が強く流れることがわかります。","role":"assistant"}}],"usage":{"completion_tokens":25,"prompt_tokens":55,"total_tokens":80}}
LiteLLM(SDK)からLiteLLM Proxy経由でローカルLLM(ollama)を呼び出す
Pythonスクリプトを作成
LiteLLM(SDK)からLiteLLM Proxy経由でOllamaのローカルLLMを呼び出すスクリプトを作成する。
以下のコードを作成し、任意のファイル名(test_proxy_ollama.pyなど)で保存する。
from dotenv import load_dotenv
from litellm import completion
import os
load_dotenv() # .envファイルから環境変数を読み込む
response = completion(
model="litellm_proxy/my-ollama-model", # litellm_proxy/[config.yamlで指定したmodel_name]
messages=[
{"role": "system", "content": "あなたは親切で簡潔なアシスタントです。"},
{"role": "user", "content": "こんにちは。今日の天気は?"}
],
api_base=os.getenv("LITELLM_PROXY_API_BASE", "http://localhost:4000"), # LiteLLM ProxyのURL
api_key=os.getenv("LITELLM_PROXY_API_KEY", "sk-user-abcdef1234"), # LiteLLM Proxyのバーチャルキー
temperature=0.3,
max_tokens=50
)
print(response.choices[0].message)
実行と結果の確認
別のターミナルを開いて、以下を実行する。
$ pipenv run python test_proxy_ollama.py
【実行結果(例)】
戻り値のオブジェクトmessage["content"]にモデルからの応答メッセージが出力される。
$ pipenv run python test_proxy_ollama.py
Loading .env environment variables...
Message(content='今日の天気は晴れです。', role='assistant', tool_calls=None, function_call=None, provider_specific_fields={'refusal': None})