達人に学ぶDB設計 | 正規化と非正規化、インデックスについて
前回こちらの記事で、DB設計の正規化とパフォーマンスのトレードオフについて、学習しました。その中で、結合処理のコストの高さや、インデックスによる性能改善が触れられていて、実際にどのくらいの違いがあるのか、知りたくなりました。
そこで、記事で扱った処理について、3つの場合に分けて、処理時間を比較してみました。
- そのまま結合を使った場合
- テーブルに集計データを持たせて、結合せずに済むようにした場合
- インデックスを利用しつつ、結合を使った場合
素人の実験ですので、おかしな部分がありましたら、コメントでご教授ください。
結果
結果を先に述べてしまうと、そのまま結合した時に比べて、結合を使わない場合は、 約19倍 、インデックスを利用した場合は、 約10倍 早くなりました。
検証方法
環境
MySQL 5.7
MySQL Workbench 8.0
MySQL Workbenchは、SQLクエリを実行して処理時間を計測したり、インデックスが使われているかをGUIで確認できる開発ツールです。
検証データ
1対多の関連を持つ「受注(orders)」テーブルと「受注明細(line_items)」テーブルを用意しました。
受注(orders)テーブル
| id 受注ID |
order_date 受注日 |
customer_name 注文者名義 |
|---|---|---|
| 1 | 2020-06-26 | 岡野 徹 |
| 2 | 2020-06-26 | 浜田 健一 |
| 3 | 2020-06-26 | 石井 恵子 |
| 4 | 2020-06-26 | 若山 みどり |
| 100000 | 2023-03-22 | 庄野 弘一 |
受注明細(line_items)テーブル
| id 受注明細ID |
order_id 受注ID |
serial_number 受注明細連番 |
item_name 商品名 |
|---|---|---|---|
| 1 | 1 | 1 | マカロン |
| 2 | 1 | 2 | 紅茶 |
| 3 | 1 | 3 | オリーブオイル |
| 4 | 2 | 1 | チョコ詰め合わせ |
| 5 | 2 | 2 | 紅茶 |
| 6 | 2 | 3 | 日本茶 |
| 299998 | 100000 | 1 | 牛肉 |
| 299999 | 100000 | 2 | 鍋セット |
| 300000 | 100000 | 3 | 米 |
※赤字が主キー
簡単にするため、次のようにして大規模データを持たせました。
-
ordersテーブル:毎日100人の顧客が注文(1000日分、計10万レコード)
-
line_itemsテーブル:1回の注文で3つの商品が注文される(計30万レコード)
これらのテーブルを使って、「受注日ごとに何個の商品が注文されているかを調べる」という処理を考えます。
1. そのまま結合した場合
最初に、インデックスを作成せずに、結合を使って処理する場合のSQLクエリが以下のようになります。
SELECT orders.order_date,
COUNT(*) AS item_count
FROM orders INNER JOIN line_items
ON orders.id = line_items.order_id
GROUP BY orders.order_date
LIMIT 100;
2つのテーブルを内部結合して、受注日(order_date)ごとに集計した結果を100件取得します。
結果
| order_date 受注日 |
item_count 商品数 |
|---|---|
| 2020-06-26 | 300 |
| 2020-06-27 | 300 |
| 2020-06-28 | 300 |
| 2020-06-29 | 300 |
| 2020-10-03 | 300 |
上のように、「毎日300個の商品が注文されている」という結果が得られます。
処理時間
この時、10回同じ処理をして、かかった時間の平均を求めると、 404ms でした。
この処理が頻繁に行われることを想定した場合、やや遅いのかなと思いました。
2. 集計データを持たせた場合
結合を使わずに処理するために、予め集計した「商品数(item_count)」カラムを、ordersテーブルに追加します。
受注(orders)テーブル
| id 受注ID |
order_date 受注日 |
customer_name 注文者名義 |
item_count 商品数 |
|---|---|---|---|
| 1 | 2020-06-26 | 岡野 徹 | 300 |
| 2 | 2020-06-26 | 浜田 健一 | 300 |
| 3 | 2020-06-26 | 石井 恵子 | 300 |
| 4 | 2020-06-26 | 若山 みどり | 300 |
| 100000 | 2023-03-22 | 庄野 弘一 | 300 |
上のテーブル構成は、前回の書籍からの引用ですが、非正規化の例としてそのまま集計データを追加しています。
改めて見ると、一人一人が300個注文しているように見えるので、本来は商品数テーブルとして分けた方が良さそうです。
このテーブルから、受注日ごとの商品数を得るSQLクエリは以下のようになります。
SELECT DISTINCT order_date,
item_count
FROM orders
LIMIT 100;
DISTINCTで、重複する受注日を1つにまとめています。これで、1の時と同じように毎日300個の注文があるという結果が得られます。
処理時間
この処理の10回の平均時間は、 20.8ms でした。そのまま結合した場合(404ms)に比べて、 約19倍 も速くなっています。
実際に比較してみることで、結合処理のコストの高さが実感できました。ただ、集計データを持たせると、更新の処理が複雑になるということも、意識しておく必要があります。
3. インデックスを利用した場合
1の結合を使った処理において、必要なカラムにインデックスを作成することで、処理を高速化させます。
SELECT orders.order_date,
COUNT(*) AS item_count
FROM orders INNER JOIN line_items
ON orders.id = line_items.order_id
GROUP BY orders.order_date
LIMIT 100;
インデックスを作成するにあたって、次のことを考慮しました。
- インデックスは、基本的に1つのテーブルに対して1つが使われる
- WHERE句やORDER_BY句、GROUP_BY句、または結合条件に使用されているカラムに作成する
そこで、2つのテーブルの次のカラムにインデックスを追加しました。
- ordersテーブル:GROUP_BYで使用されている、「order_date」カラム
- line_itemsテーブル:結合条件で使用されている「order_id」カラム
処理時間
最初に結合条件の「order_id」カラムにだけインデックスを追加しましたが、処理平均時間は、418msで、効果がありませんでした。
次に「order_date」カラムにもインデックスを追加すると、10回の処理平均時間は 40.7ms になりました。
1と全く同じSQLですが、インデックスを作成するだけで 約10倍 も高速になるということが分かりました。条件次第だとは思いますが、適切に改善できれば、結合処理も十分実用に耐えるのではないかと思います。
MySQL Workbench の使用感
脇道に逸れますが、MySQL Workbenchを利用すると、SQLクエリ実行時にインデックスが使われているか、重い処理はどこかが視覚的に分かり、便利でした。
下の画像は、左がインデックス作成前、右がインデックス作成後の、結合を含むSQLクエリを表した図です。
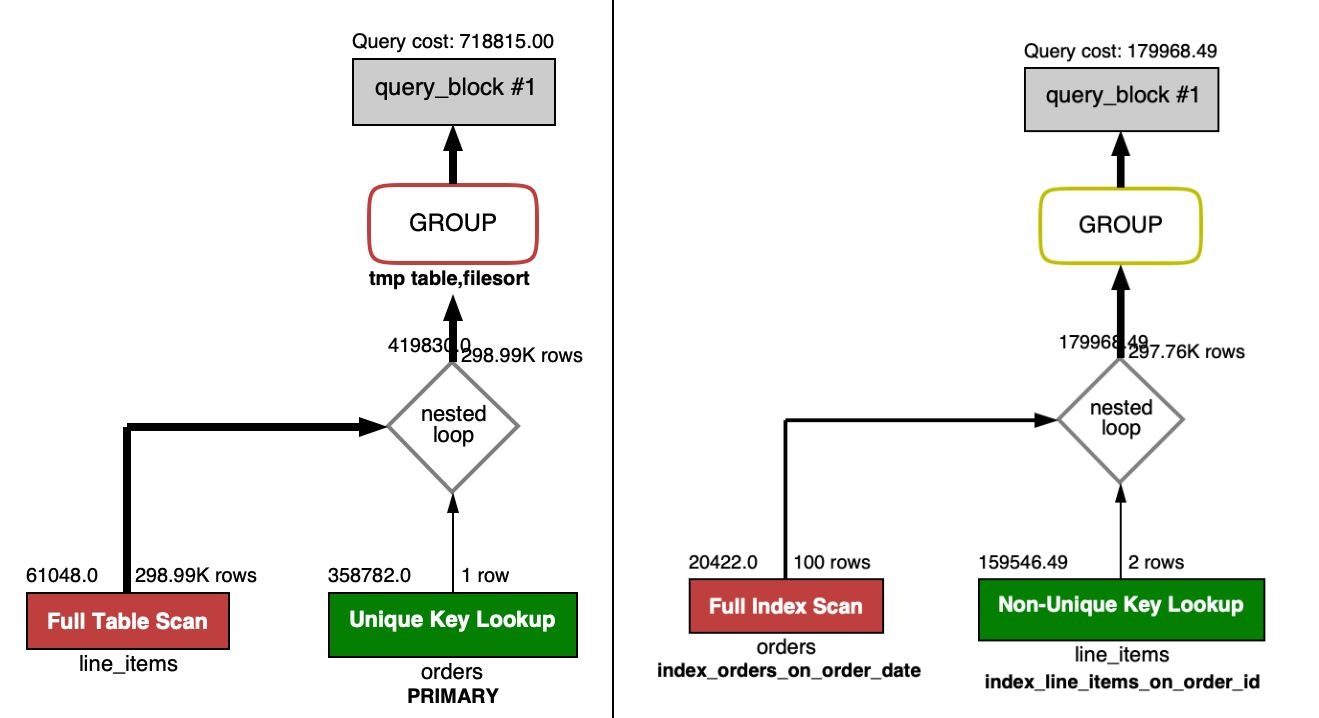
色がついている部分は、赤いほど高コストで、青い(緑)ほど低コストということを表しています。
右を見ると、2つのインデックスが使われていて、わずかですが、GROPU_BYの処理の色が変わっていることが確認できます。
結合条件を絞り込むことで、もっと改善することができるのではないかと思います。
参考:[MySQL Workbench] VISUAL EXPLAIN でインデックスの挙動を確認する
DBMSによる結合処理の違い
こちらの記事から、結合処理には次の3種類があることを知りました。
- Nested Loop Join
- Hash Join
- Merge Join
このうち、OracleとPostgreSQLには3つとも実装されていて、MySQLでは「Nested Loop Join」だけが実装されているということです。
RDBMSの、そのような細かな違いも把握しておきたいと思いました。
おわりに
実際に大規模データを作って実験してみることで、処理の仕方やインデックスの有無によるパフォーマンスの違いを実感することができました。
実験は1→3→2の順番で行ったのですが、3で2つ目のインデックスを追加した時に、あまりの処理時間の速さに、目を疑ってしまいました 笑。
適切なカラムに貼れば、たったそれだけでこんなにも違いが出るのだと分かり、インデックスはDB設計で必須のものだと改めて感じました。