はじめに
こんにちは。アジアクエスト株式会社の足立です!
この記事は「アジアクエスト Advent Calendar 2025」の14日目の記事です。
この記事では、AWS re:Invent 2025の5日目に行われたキーノート
「Infrastructure Innovations with Peter DeSantis and Dave Brown (KEY004)」
を中心に「AWSを支えるインフラ(半導体)」について調べた内容をまとめます。
アーカイブURL:
関連する他のKeynoteについてもまとめていますので、良ければどうぞ!
この記事を書いた理由
私はこのKeynoteのライブ配信を日本から視聴していました。
ただ、ハードウェアや半導体に関する知見が少なかったため、発表を聞いた当初は 「へー、またコンピューティングやメモリの性能が上がったのか」 程度の感想しか持てませんでした。
しかし、後日調べてみると、AWSのコアとなるインフラ部分を支える技術の進化、AI時代における影響、AWSの長期戦略 など、興味深い内容が多く含まれていることがわかりました。
そこで、ハードウェアや半導体に詳しくない読者を対象に、「AWSの長期的なインフラ戦略」 の面白さを伝える 記事としてまとめることにしました。
この記事で書くこと・書かないこと
この記事では、Keynoteで語られた文脈に沿って、「Nitro / Graviton / Trainium 3 / Neuron」 などのAWSのコアインフラと、私が理解した「変化のポイント」と「影響」を書いていきます。
それぞれの技術について、「背景にある課題」「今回の世代で変わったこと」「その結果、AI時代にどんな意味があるか」の3点を中心に説明します。
アップデートを網羅的に列挙するのではなく、ハードウェア・インフラに絞って詳しく解説します。対象読者として、クラウドは触っているがCPUや半導体の仕組みには詳しくないエンジニア を想定しています。
調査と理解のため、公式のドキュメントやYoutubeアーカイブをソースとして「Google NotebookLM」などのAIを活用しています。内容は確認していますが、間違いなどあればご指摘いただけると幸いです。
1. AI 時代でも変わらない「AWSの5つのコア属性」
Peter DeSantis氏は、Keynoteの冒頭で、AI時代においても変わらないAWSの5つのコア属性について語りました。
これらは、「AWSが最初から注力してきたものであり、すべてのサービス、API、技術的な意思決定の指針となってきた原則として、AI時代においてもその重要性は変わらない」と主張していました。

AWSが重視する5つのコア属性は以下の通りです。実際の発言内容を基にまとめてみます。
-
セキュリティ(Security)
"As you probably already know, it's not just the good guys that are getting more productive with AI. The bad guys are using the same tools to attack your products, your customers, and your infrastructure. So it's never been a more important time to know that your cloud provider's first priority is security."
すでにご存知の通り、AIによって生産性を上げているのは「善人」だけではありません。「悪人」も同じツールを使って、皆さんの製品、顧客、そしてインフラストラクチャを攻撃しています。ですから、クラウドプロバイダーの最優先事項がセキュリティであることを知るのが、これほど重要な時はありません。
-
可用性(Availability)
"Or right there behind security is availability. And the sheer size and scale of the applications that are being built right now demand performance from security, or from databases, analytics, networks. So there's never been a better time to build on a cloud that's been tested running the most demanding workloads of the last decade."
セキュリティのすぐ後ろには可用性があります。現在構築されているアプリケーションの圧倒的なサイズと規模は、セキュリティだけでなく、データベース、分析、ネットワークからのパフォーマンスも要求しています。ですから、過去10年間の最も要求の厳しいワークロードを実行してテストされてきたクラウド上で構築するのに、これほど適した時期はありません。
-
弾力性 / スケーラビリティ(Elasticity)
"One of the most important things about the cloud is it takes away capacity planning... Now today, capacity planning is likely something that you don't do at all, and that's a great thing. AWS is ready to scale when you need us... Our goal is to give you the same elasticity that you get from a service such as S3 with your AI workloads."
クラウドの最も重要なことの一つは、キャパシティプランニング(容量計画)を不要にすることです。今日、キャパシティプランニングはおそらく皆さんが全く行っていないことであり、それは素晴らしいことです。AWSは必要なときにスケールする準備ができています。私たちの目標は、S3のようなサービスで得られるのと同じ弾力性を、AIワークロードでも提供することです。
-
コスト効率(Cost)
"But one thing that anyone who's put an AI application into production knows is that AI ain't cheap. It's really, really expensive to build these highly capable models, and more expensive still to run the massive amount of inference that we need to transform our lives with these models... We're investing deeply in lowering the cost of building these models and running these workloads."
AIアプリケーションを本番環境に導入した人なら誰でも知っていることが一つあります。それは、AIは安くないということです。これらの高機能なモデルを構築するのは高価ですし、これらのモデルで生活を変革するために必要な大量の推論を実行するのはさらに高価です。私たちは、これらのモデルの構築とワークロードの実行コストを下げるために深く投資しています。
-
俊敏性(Agility)
"When we launched AWS almost 20 years ago, I think the attribute that most contributed to the success of the cloud was agility... They were able to innovate faster. They were able to deliver value to their customers faster... And most importantly, they were able to pivot faster. That's agility. That's the magic of the cloud. You can launch, optimize, pivot quickly. Now, doesn't that sound exactly like what you're going to need during this AI transformation?"
約20年前にAWSを立ち上げたとき、クラウドの成功に最も貢献した属性は俊敏性だったと思います。クラウドを採用した企業は、より速くイノベーションを起こし、より速く顧客に価値を提供し、そして最も重要なことに、より速くピボット(方向転換)することができました。それが俊敏性です。それがクラウドの魔法です。ローンチし、最適化し、素早くピボットできるのです。さて、これはまさにこのAI変革の間に皆さんが必要とするもののように聞こえませんか?
これらの発言からは、5つの属性(設計原則)が偶然ではなく、AWSが長期的な戦略としてコミットメントと投資を続けてきた結果 として実現されていることが分かります。
次章からは、これらの属性を支える具体的なインフラ・ハードウェアの技術に焦点を当てます。「AI変革に必要とされるもの」とは一体なんでしょうか?
2. AWS Nitro System - 仮想化を専用ハードウェアに切り出すインフラ基盤
AWS Nitro System とは?
AWS Nitro System とは 「仮想化の処理を専用ハードウェアに逃がして、性能とセキュリティを同時に上げる基盤」 です。
2017年以降、すべてのEC2インスタンスに使われているAWSを支える「土台」 と言えます。
さらに、AWSが独自のシリコン(半導体)を作るきっかけになった点でも非常に重要なものです。
なぜ AWS Nitro System が生まれたのか?
AWS Nitro System は2013年から開発が始まりました。
従来の仮想化技術(Xenなど)では、アプリケーションの処理も、ネットワークやストレージの管理も、セキュリティの監視も、すべてホストのCPUが担当していました。
Nitro System の開発の目的は、このような雑務を 「専用のハードウェア」と「非常に軽くて薄いハイパーバイザ」に切り分ける ことです。
雑務から解放されることで、ホストCPUは本来の目的である 「顧客のアプリケーションの処理」に専念できる ようになります。
AWS Summit 2025の資料が分かりやすいので引用します。
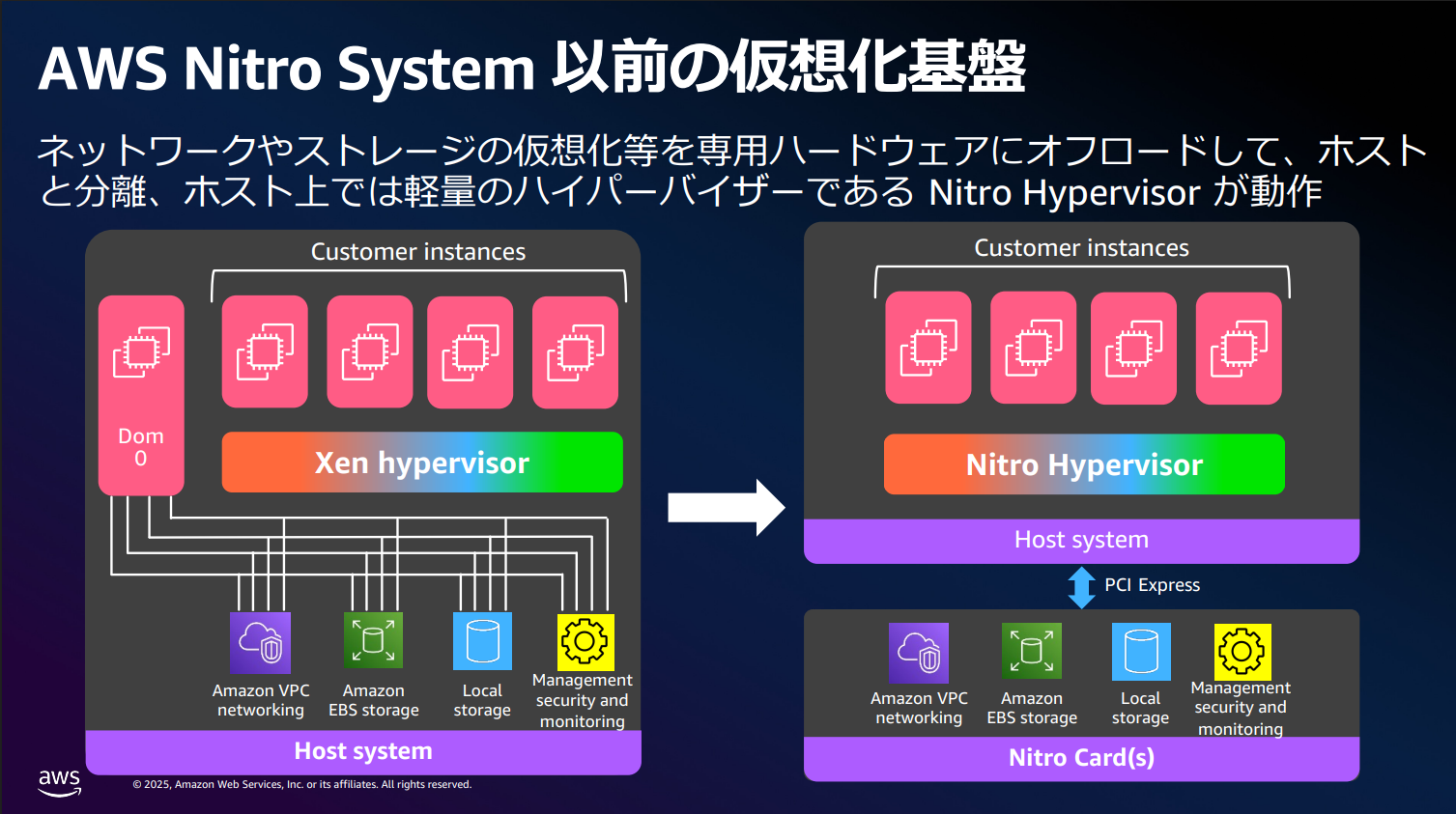
AWS Summit 2025: 進化する Amazon EC2 〜 AWS Nitro システムと独自プロセッサがもたらす価値とコスト効率(AWS-03)
このように仮想化の処理をオフロードした結果、従来の課題だったJitter(突発的な遅延)が解消され、ベアメタルホストと変わらない性能を実現 しました。
さらに、ハイパーバイザーが顧客の仮想マシンのメモリから物理的に分離されていることで、「AWSのオペレータであっても顧客データにアクセスすることが原理的に不可能」 になっておりセキュリティ面でも大きく向上しています。
ベアメタルホストとは
「仮想化されていない、素の物理サーバーをそのまま1台まるごと使えるコンピューティング環境」 です。
仮想化レイヤーを挟まないため、ハードウェア性能をダイレクトに引き出せる一方で、柔軟にリソースを割り当てたりする自由度は低くなります。
重要な技術革新・設計のポイント
AWS Nitro System の重要な構成要素は以下の3つです。
Nitro Cards
Nitro Cardsは、ネットワークやストレージをホストCPUから物理的に切り分ける専用ハードウェア(カード群)です。
VPC用のネットワークインターフェース、EBS用のストレージコントローラなどを物理的に分離することで、ホストCPUのほとんどの計算リソースを顧客アプリケーションに割り当てられます。
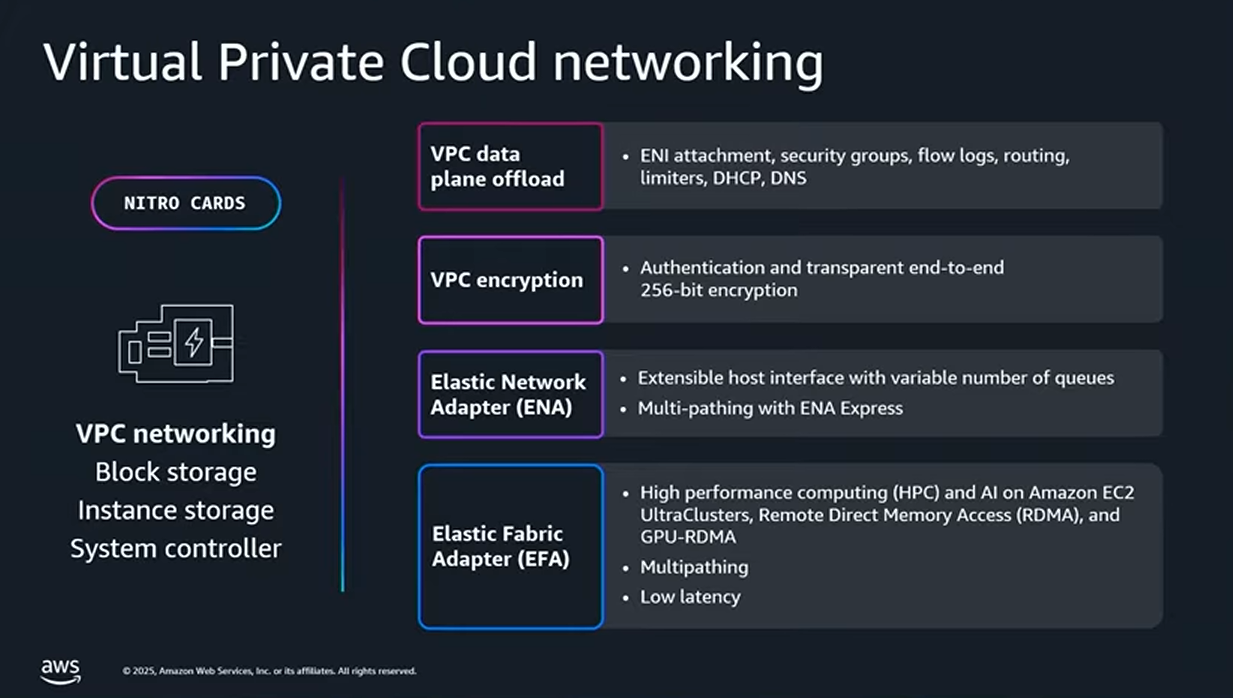
ネットワークやストレージを物理的に分離する仕組みは以下の通りです。
-
ネットワーク
VPCデータプレーン機能(ENI、セキュリティグループ、フローログ、ルーティング等)をホストCPUから分離します。さらに、SR-IOV(デバイス仮想化の方式)で専用のネットワークインターフェイスが割り当てられます。
簡単に言うと、「実際のパケットが流れて転送・暗号化・記録などが行われる経路」 がハードウェアレベルで分離されていて、顧客VMに直結しています。
-
ストレージ
EBS(ブロックストレージ)の場合は、実データがNVMe(高速SSDで使われる規格)のインターフェースを経由して専用のカード(Nitro Cards)で処理されます。また、データの暗号化処理もカード側で処理されます。
Instance Store(ローカルの一時ストレージ)の場合も同様の考え方で、データプレーンや暗号化処理がホストCPUから分離されています。
重要キーワード(ENA、EFA、SRD)
- ENA(Elastic Network Adapter)
EC2で高帯域・低遅延のネットワーク性能を提供するためのアダプタ - EFA(Elastic Fabric Adapter)
大規模分散(HPC/機械学習)向けに、ノード間通信を最適化するアダプタ - SRD(Scalable Reliable Datagram)
大量のサーバー間通信を低遅延で扱うためのデータグラム型プロトコル
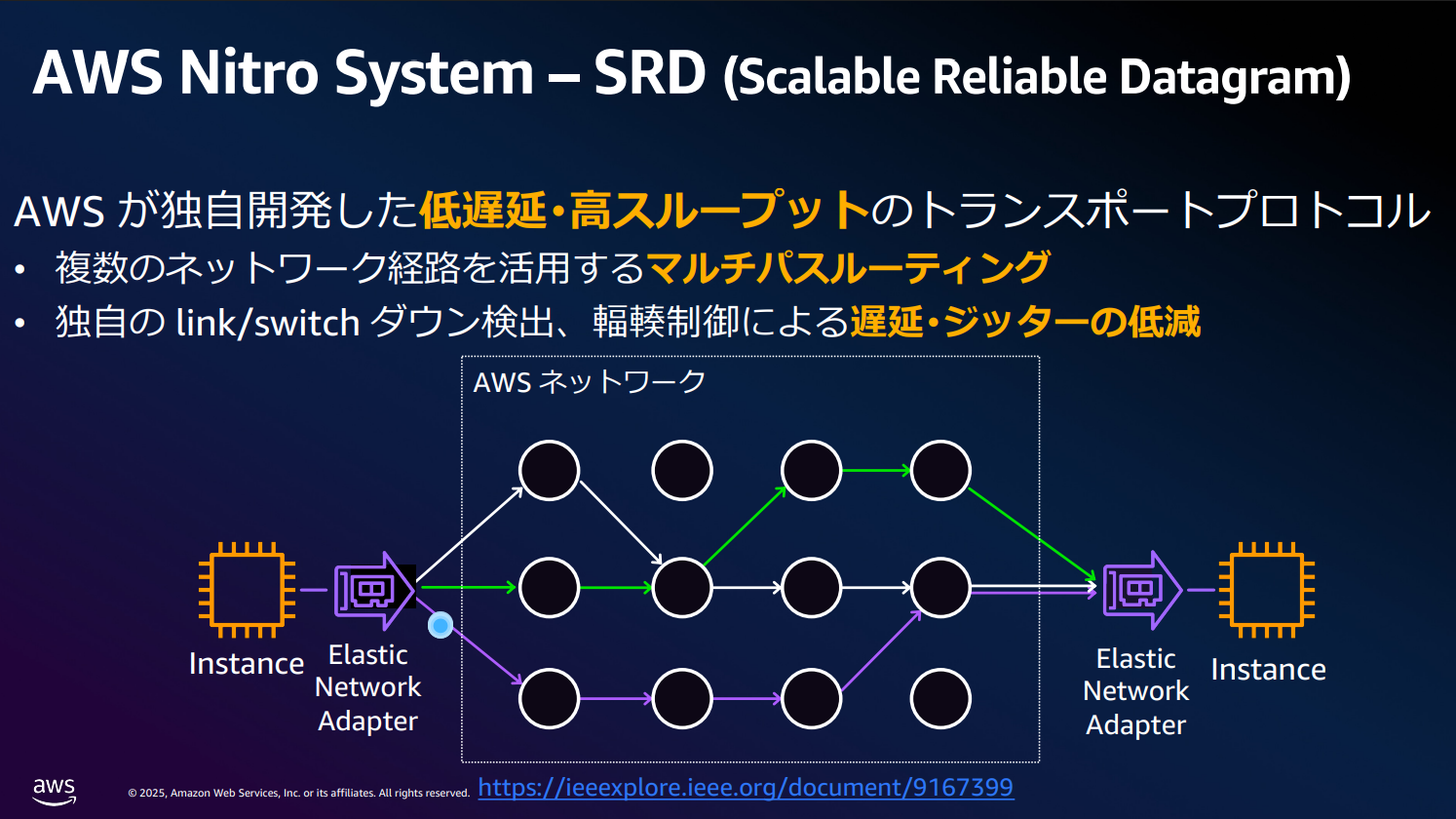
Nitro Hypervisor
Nitro Hypervisorとは、必要最低限の機能のみに焦点を絞って設計されたハイパーバイザ です。
具体的には、Nitro Cards にネットワークやストレージの入出力(I/O)処理を分離したことで、デバイスの割り当て(仮想CPUが専用ハードウェアに直接アクセスするためのパスの提供)など最小限の機能だけ を担っています。
Nitro Security Chip
Nitro Security Chipは、物理的なセキュリティチップ(HSM相当)として、鍵管理・暗号化などをハードウェアで処理します。顧客データにアクセスする機能を物理的にハードウェアレベルで取り除き、AWSの社員ですら顧客のサーバーの中身を覗き見することが不可能になっています。
AWS Nitro Systemが与えた影響
AWS Nitro System は現代ではAWSの土台を支える技術として欠かせないものとなっています。EC2やLambda、Fargateなどのコンピューティングリソースはもちろん、多くのマネージドサービスもこの基盤の上で動いています。
ストレージ性能やネットワーク性能を柔軟に変更できるようになった結果、2017年以降、800種類以上の新しいEC2インスタンスタイプを提供 しているそうです。
また、AWSが独自のシリコン(半導体)を設計するきっかけ となり、後述する Graviton や Trainium に繋がっている点でも重要な技術です。
3. AWS Graviton - マネージドサービスを支える自前CPU
AWS Graviton とは何か?
AWS Graviton は AWSが独自に設計したArmベースのCPU です。コストパフォーマンスと電力効率に優れている点が特徴です。
誕生の背景と Nitro との関係
AWS Nitro System によってネットワークや仮想化の処理をオフロードした後、AWSが次に目指したのが、プロセッサの性能向上 でした。
Graviton と Nitro Systemの関係
AWS Nitro Systemがネットワークや仮想化機能などの「雑務」をサーバーから切り離す役割とすれば、Graviton はサーバー本体の「頭脳」にあたる部分 に相当します。
雑務から解放されたことで、頭脳の性能をフルに発揮できていると言えます。
一般的に汎用CPUでは「x86系」がよく使われていますが、AWSはデータセンター環境に最適化させるために「Arm」を使ったチップを開発しました。
x86系とArm系ではISA(機械語への命令セット)が異なります。言い換えると、「同じソースコードでも、コンパイルした実行ファイルは原則として互換性がない(x86用はArmでそのまま動かない)」 ということです。
なぜわざわざ互換性のないアーキテクチャを採用するのでしょうか?
それはArmを採用することで、クラウドにおける強みを出しやすい理由が2つあるからです。
-
ライセンスモデル
ArmはISAやコア設計をライセンス提供している一方で、x86はISA・実装・供給の主導権を「Intel / AMD」が持っています。つまり、「Armは自社の目的に合わせてカスタマイズしやすい」 のに対し、x86はそうでないのです。 -
エコシステムの移植性
ArmはLinuxやコンテナ、各種言語ランタイム(Java、Go、Pythonなど)をサポートしているため、Linux上で再コンパイル可能なアプリであれば比較的簡単に移植 することができます。
こうした理由から、AWSが「自前CPU」を設計し、不要な機能をそぎ落として価格・電力あたりの性能(データセンターのラックごとの密度)を最大化する ことが可能となっています。
重要な技術革新・設計のポイント
Graviton の登場は2018年にさかのぼります。初代のGravitonでは、Armベースのアーキテクチャがクラウド上で「動く」基盤を確立しました。
翌年2019年に発表されたGraviton2では、64物理コア、7nmプロセス、Arm Neoverse N1コア採用など、大幅な性能向上を狙いました。

その結果、x86ベースのCPUと比べて 価格が20%安価になり、1つのvCPUに2倍の物理コアを利用可能 とすることで、最大で40%のコストパフォーマンスを実現することになりました。
この時点で「Armで動くCPU」というだけでなく、「x86と比較しても価格性能が高い」 という立ち位置になったと言えます。

AWS Black Belt: AWS Graviton2 Arm CPU 搭載インスタンス
さらに世代を経るごとにGravitonの価格性能が上がっていきます。第3世代ではメモリアクセス性能やネットワーク帯域が強化され、HPC(高性能計算)に特化した「Graviton3E」 も発表されました。
そして、第4世代では L2キャッシュ(アクセスが多いデータを格納)のコアサイズを2倍にし、メモリ帯域も75%増加 しました。大規模な分析やDBの読み書きにも高い性能を発揮するようになりました。
一方で、第4世代では2つのコアをコヒーレントリンク(複数のCPUを一貫性を保って接続する仕組み)で接続することで、大規模処理用の192vCPUを実現していました。しかし、これは CPUが別のCPU上のメモリにアクセスする際に遅延の原因となり、最大で3倍の時間がかかっていたそうです。
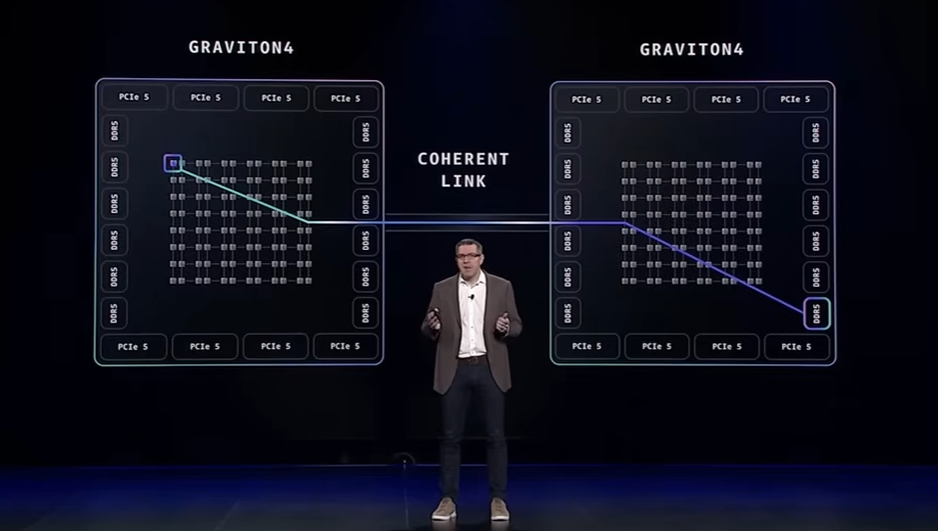
最新のGraviton5では、「単一パッケージで192コア」 を実現し、L3キャッシュ(コア間で共有される、より大きなキャッシュ)のサイズを5倍以上 にしました。

さらに、最新のEC2インスタンスタイプである 「M9g instances」 も発表され、前世代よりも25%の性能向上をアピールされていました。

Graviton 5の仕様
| 項目 | 仕様 |
|---|---|
| コア数 | 最大192コアを単一パッケージに集約(Graviton4の96コアの2倍) |
| L3キャッシュ | 192MB(Graviton4比で5倍以上、1コアあたり最大2.6倍) |
| メモリサポート | DDR5-7200(最大614.4 GB/s帯域、Graviton4比14%向上) |
| PCIeサポート | PCIe 6.0(AWS EC2では初の高速インターフェース) |
| 製造プロセス | TSMC 3nm |
| アーキテクチャ | Arm Neoverse V3 |
ハードウェアの全体最適の例(Direct to Silicon Cooling)
Keynoteでは「シリコン直接冷却(Direct to Silicon Cooling)」が紹介されていました。
従来は「シリコン(CPUチップ本体)→ 熱界面材料(TIM) → 保護用の蓋 → 熱界面材料(TIM) → ヒートシンク(放熱器)」という構造が一般的でした。
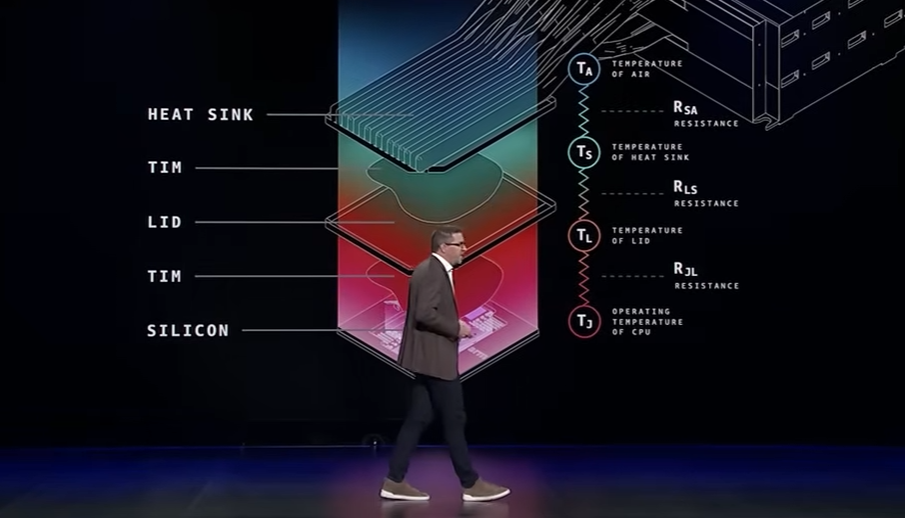
AWSでは「保護用の蓋」とその下の「熱界面材料(TIM)」を取り払い、熱効率を33%も改善したそうです。これは AWSが自社でハードウェア全体を設計・制御している好例 と言えます。

マネージドサービスを支えるインフラとしての位置づけ
GravitonはEC2だけの話ではありません。Graviton公式ページ によると、Aurora、RDS、EKSなど多くのマネージドサービスでGravitonが利用されているそうです。
その規模感としては、「3年連続で、AWSに追加される新しいCPU容量の半分以上がGravitonによって供給されている」 (About Amazon)とのことです。これは、Gravitonが「選べるCPUの1つ」というより、「AWSのサービス全体を支える基礎」 になっている、という意味合いを持ちます。
4. AWS Trainium 3 と 第2世代 UltraServer - 大規模AI学習向けの専用チップ
AWS Trainiumとは?
AWS Trainiumとは、AWSが独自に開発したAIの学習・推論に特化したチップ(半導体) です。大規模なAIの学習(Training)などに最適化されているため、大幅なコスト削減を実現しています。
なぜAI専用の半導体が求められるのか?
ChatGPTやClaudeなどの生成AIを使っている人は多いでしょう。こうした大規模言語モデルなどに関して、以下のような特徴があります。
- 大規模言語モデルでは、モデルのサイズ、データ量、計算量を増やすほど性能が上がっていく構造(スケーリング則) がある
- 最先端のAIを開発するには、高品質なデータと計算資源(GPUなど)をどれだけ確保できるか が鍵となる
- データセンターの建設には時間がかかるため、電力や設置面積あたりの性能がボトルネックになる
結果として、AI需要が伸び続けているにも関わらず供給が制約されるため、電力やコスト効率の良い半導体 が求められているわけです。
「札束で殴る」とは?
最先端の半導体を大量に確保するためには何が必要でしょうか? そうです、「お金」 です。AIモデルの開発に参入するには巨額の費用がかかり、生き残るには投資をし続けないといけません。
このような 「結局はお金がすべて」 の構造を俗に 「札束で殴る」 と表現されることがあります。
AIの学習や推論には何がもとめられるのか?
大規模言語モデルなどは大きく、学習(Training)と推論(Inference)の2段階 で開発されています。
まず学習(Training)の段階では、順伝播・逆伝播・重みの更新を長時間回し続けることが必要です。言い換えると、「高い計算性能」を維持したまま「大規模にスケール」させて「安定稼働」させる ことが求められます。
一方、推論(Inference)とは学習したモデルを実際に使う時の処理です。入力処理(prefill)として大量の入力を並列処理して注意機構(attension)のキャッシュを作ります。簡単に言うと 「どのトークンが重要で、どこに注意を向けるべきなのか」 を考える段階で行列演算が重要になります。
そして、出力処理(decode)の段階では入力時に作成したキャッシュを読み書きしながら返答を1トークンずつ生成していきます。ここではメモリ帯域が重要です。
つまり、AIの学習や推論には「ただ速い演算装置」ではなく 「メモリ / 通信 / 電力効率 / スケール運用」まで含めた設計が必要 になります。
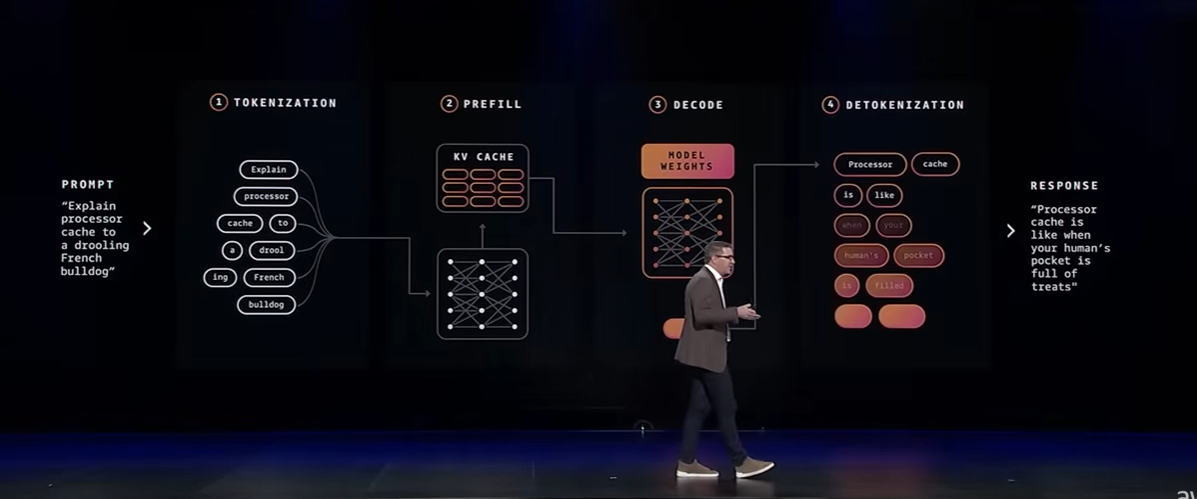
Trainium 3は何がすごいのか?
AWS Trainiumの最新世代「Trainium 3」では、AIの学習や推論に最適化してチップを作っており、高い演算性能と価格の安さを両立 しています。

これは前述の「AWS Nitro System」や 「Graviton」の合わせ技によって実現しています。具体的には、AI向けの高度な演算を担当する「Trainium 3」を常に忙しくさせる ために必要な高速なI/O(入出力)をGravitonが担っています。

そして、このTrainium 3を 「144個」 接続した箱が 「Trainium 3 UltraServers」 です。
前の世代に比べ、4.4倍のコンピューティング性能 と 3.9倍のHBMメモリ帯域 を実現しているそうです。何よりすごいのは、非常に電力効率が高いという点です。メガワットあたりのトークン生成数で最大5倍以上の性能 を出せるとのことです。

PFOPS(FP8)の意味
スライドでは、コンピューティング性能として「360 PFLOPS(FP8)」という数字が上がっています。これは 「8ビットの浮動小数点演算を1秒あたり何回実行できるか」 を表しています。16ビットよりも低精度(1回のデータが小さい)ため、同じハードウェアでもより多くの演算を並列にこなせることを意味しています。
5. AWS Neuron と Neuron Kernel Interface (NKI) - ハードウェアを活かす土台となるソフトウェア
AWS Neuron とは?
AWS Neuron(Neuron SDK)は、AWS のAI向けチップであるTrainium(またはInferentia)上で、機械学習を動かすための「コンパイラ + 実行環境 + ツール」をまとめたソフトウェア基盤 です。
背景にあった課題
Trainium のような専用のAIチップのおかげで、大規模な計算リソースが使えるようになりました。しかし、UltraServerなど複数のチップを繋げる場合には、チップ間の相互接続を管理して遅延が発生しないようにする必要 があります。
つまり、処理を早くするためには 「どの順番で計算し、どのタイミングでデータをメモリに置くか」 などを制御しなければならないということです。
重要な技術要素
こうした課題を解決するため、Neuron には以下のような要素が備わっています。
Neuron Switches
Trainium 3 に物理的に搭載されたネットワークスイッチです。チップ間の低遅延の接続のために、Neuron SDKからの命令をハードウェアに翻訳する役割を果たしています。

Neuron Kernel Interface (NKI)
ユーザーが通常のプログラミング言語を使って、「Trainiumのハードウェアに直接命令するための入口(インターフェース)」 です。スケジューリングやメモリ割り当てなどの低レベルの制御をPythonなどの言語で行うことができます。
実際に、今回のre:Inventでは 「Pytorchのネイティブサポート」 も発表され、使い慣れた機械学習フレームワークでTrainiumの制御が可能となりました。

Neuron Profiler / Neuron Explorer
Neuron Profilerが 「ハードウェア上で何が起こっているかを詳細に把握」 するためのツールで、Neuron Explorerが 「Profilerで収集されたデータをユーザーが理解しやすい形に変換」 するためのツールです。
「どこが遅いのか分からない」 という問題に対して、原因調査を行い、「どこを直せばいいか」推奨事項まで提示してくれる 機能を搭載しています。
まとめ
いかがだったでしょうか。この記事では、AWS re:Invent 2025の「Infrastructure Innovations Keynote」で発表された 主要なインフラ技術(Nitro / Graviton / Trainium / Neuron) について、背景にある課題や技術革新のポイントを整理しました。
個人的には、「なぜAWSが独自の半導体を作っているのか」 という疑問がある程度解消されたと感じています。また、「AWSの半導体への長期投資が、AI時代においてどのように実を結んでいるのか」 が理解でき、今後の可能性を感じて楽しみになりました。