この記事はdbt Advent Calendar 2022 4日目の記事になります。
はじめまして、日頃 dbt を用いてデータ分析基盤の開発をしている K と申します。
現在、株式会社ベーシック(以下、ベーシック)にて Analytics Engineer としてデータ分析基盤開発のお手伝いをしております。
データ分析基盤の開発には dbt Cloud(以下、dbt) を利用しており、今回は実際に dbt を用いてどんな風に実装しているかをご紹介できればと思います。
※1:DWH には BigQuery を利用しています。
※2:ご紹介する内容が、ベストプラクティスを保証するものではございません。
※3:現在も絶賛開発中で、紹介する内容には一部実装予定のものも含まれております。
データ層の分け方
データ分析基盤開発において、データ層の分け方はとても重要な要素になります。
今回データ層の分け方を考える上で、Ubie株式会社様の事例を非常に参考にさせていただきました。
具体的には、下記のようにデータ層をわけて開発しております。
- Data Source 層
- Data Lake 層
- Interface 層
- Compornent 層
- Data Warehouse 層
- Data Mart 層
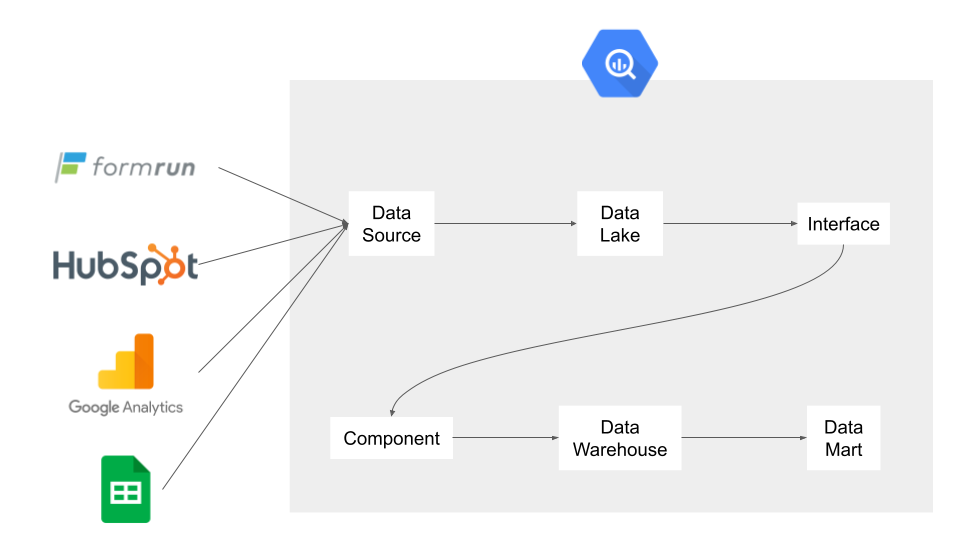
以下、各データ層について説明させていただきます。
Data Source 層
その名の通り、社内に点在するデータソースを ETL で転送し、そのデータを保存する場所です。
複数のデータソースを同一のデータセットに保存してしまうと、テーブル名が被る可能性を考慮して、データソースごとにデータセットを作成してデータを保存しています。
データセットの命名規則としては、source_formrunのように、データソース名の前にsource_のプレフィックスを入れるようにしてます。
また、テーブルの命名規則としては、基本的にデータソース側のテーブル名を踏襲するようにし、ないものに関しては必要に応じて命名しています。
Data Lake 層
データ分析基盤を作る要件の1つとして、「過去データの蓄積をしたい」という要件がありました。
こちらに関しては、dbt の Snapshots機能 と dbt_utils パッケージの surrogate_key() を使って実装しています。
当初、データ層とは切り離してスナップショットテーブルを作ることを考えていたのですが、Component 層を構築するにあたりデータモデリングとして Dimensional Modeling を採用することを途中で決め、スナップショットテーブルで生成している surrogate_key のカラムを使うために、Data Source 層の次に Data Lake 層を入れることにしました。
データセットの命名規則としては、lake_formrunのように、データソース名の前にlake_のプレフィックスを入れるようにしています。
また、dbt では基本的に同名のモデルを作れないため、dl_fmrn_teamのように、dl_{サービス名の略称}_のプレフィックスをテーブル名に入れるようにしています。(以降のデータ層も同様)
Data Lake 層のモデル例
{% snapshot dl_fmrn_team %}
{% set columns = dbt_utils.get_filtered_columns_in_relation(from=source('source_formrun', 'teams'), except=['transferred_at']) %}
{% set column_list = columns|list %}
{{
config(
target_schema=generate_schema_name_for_env('lake_formrun')
, unique_key='id'
, strategy='check'
, check_cols=['team_sk']
, partition_by={
'field': 'dbt_valid_to'
, 'data_type': 'timestamp'
, 'granularity': 'day'
}
)
}}
SELECT
{{ dbt_utils.surrogate_key(column_list) }} AS team_sk
, {{ dbt_utils.star(source('source_formrun', 'teams')) }}
FROM
{{ source('source_formrun', 'teams') }}
{% endsnapshot %}
Interface 層
この層では、
- ゴミデータの排除
- タイムゾーンの変換
- カラム名の変更
を行っています。
データセットの命名規則としては、interface_formrunのように、データソース名の前にinterface_のプレフィックスを入れるようにしています。
また、テーブル名はitf_fmrn_userのように、itf_{サービス名の略称}_のプレフィックスをテーブル名に入れるようにしています。
Interface 層のモデル例
SELECT
id AS team_id
, DATETIME(created_at, 'Asia/Tokyo') AS created_at
, DATETIME(dbt_valid_from, 'Asia/Tokyo') AS dbt_valid_from
, DATETIME(dbt_valid_to, 'Asia/Tokyo') AS dbt_valid_to
, {{ dbt_utils.star(from=ref('dl_fmrn_team'), except=['id', 'created_at', 'dbt_valid_from', 'dbt_valid_to', 'dbt_scd_id', 'dbt_valid_to']) }}
FROM
{{ ref('dl_fmrn_team') }}
WHERE
dbt_valid_to IS NULL -- 最新のデータに絞る
AND NOT is_test -- テストデータを除外する
Component 層
この層では、Dimensional Modeling のデータモデリングを採用し、Dimension テーブルと Fact テーブルを生成しています。
また、データ分析や集計に利用するカラムの追加も、基本的にこのデータ層で行っています。
データセットの命名規則としては、component_formrunのように、データソース名の前にcomponent_のプレフィックスを入れるようにしています。
Dimension テーブル
テーブル名はcom_fmrn_dim_teamのように、com_{サービス名の略称}_dim_のプレフィックスをテーブル名に入れるようにしています。
この層ではワイドテーブル化することが多いのですが、*(アスタリスク)で全カラム指定する場合、GROUP BY 句でのカラム宣言が面倒なことがあります。
そこで紹介したいのが、dbt_utils パッケージの star() です。
こちらは *(アスタリスク)と違いGROUP BY 句でも使えるため、データソースでカラムの増減が発生しても、クエリの修正をしなくても良い利点があります。
Component 層の Dimension テーブルのモデル例
WITH
-- 初めて作成されたフォームのform_idを取得する
first_created_form AS (
SELECT
team_id
, MIN(form_id) AS min_form_id
FROM
{{ ref('itf_fmrn_form') }}
GROUP BY
team_id
)
SELECT
{{ dbt_utils.star(from=ref('itf_fmrn_team'), relation_alias=('itf_fmrn_team')) }}
, first_created_form.min_form_id AS first_created_form_form_id
, MAX(IF(itf_fmrn_form.form_id IS NOT NULL, TRUE, FALSE)) AS created_form
FROM
{{ ref('itf_fmrn_team') }} AS itf_fmrn_team
LEFT JOIN
{{ ref('itf_fmrn_form') }} AS itf_fmrn_form
ON
itf_fmrn_team.team_id = itf_fmrn_form.team_id
LEFT JOIN
first_created_form
ON
itf_fmrn_team.team_id = first_created_form.team_id
GROUP BY
{{ dbt_utils.star(from=ref('itf_fmrn_team'), relation_alias=('itf_fmrn_team')) }}
, first_created_form_form_id
Fact テーブル
テーブル名はcom_fmrn_fact_team_by_created_teamのように、com_{サービス名の略称}_fact_のプレフィックスをテーブル名に入れるようにしています。
Component 層の Fact テーブルのモデル例
SELECT
itf_common_date.date_sk
, itf_fmrn_team.team_sk
, itf_fmrn_utm_parameter.utm_parameter_sk
, COALESCE(COUNT(DISTINCT itf_fmrn_team.team_id), 0) AS cnt_team_by_created_team
FROM
{{ ref('itf_cmn_date') }} AS itf_common_date
LEFT JOIN
{{ ref('itf_fmrn_team') }} AS itf_fmrn_team
ON
itf_common_date.date = DATE(itf_fmrn_team.created_at)
LEFT JOIN
{{ ref('itf_fmrn_utm_parameter') }} AS itf_fmrn_utm_parameter
ON
itf_fmrn_team.team_id = itf_fmrn_utm_parameter.team_id
GROUP BY
itf_common_date.date_sk
, itf_fmrn_team.team_sk
, itf_fmrn_utm_parameter.utm_parameter_sk
Data Warehouse 層
この層では、データ分析に使える汎用的なテーブルを生成しています。
データセットの命名規則としては、warehouse_formrunのように、データソース名の前にwarehouse_のプレフィックスを入れるようにしています。
また、テーブル名はdw_fmrn_daily_team_by_created_teamのように、dw_{サービス名の略称}_のプレフィックスをテーブル名に入れるようにしています。
Data Warehouse 層のモデル例
SELECT
com_cmn_dim_date.date AS target_date
, com_fmrn_dim_team.use_case
, com_fmrn_dim_team.is_iframe_embedded
, com_fmrn_dim_utm_parameter.utm_source
, com_fmrn_dim_utm_parameter.utm_medium
, com_fmrn_dim_utm_parameter.utm_campaign
, com_fmrn_dim_utm_parameter.utm_content
, com_fmrn_dim_utm_parameter.utm_term
, com_fmrn_dim_utm_parameter.utm_group
, SUM(com_fmrn_fact_team_by_created_team.cnt_team_by_created_team) AS cnt_team_by_created_team
FROM
{{ ref('com_fmrn_fact_team_by_created_team') }} AS com_fmrn_fact_team_by_created_team
INNER JOIN
{{ ref('com_cmn_dim_date')}} AS com_cmn_dim_date
ON
com_fmrn_fact_team_by_created_team.date_sk = com_cmn_dim_date.date_sk
LEFT JOIN
{{ ref('com_fmrn_dim_team') }} AS com_fmrn_dim_team
ON
com_fmrn_fact_team_by_created_team.team_sk = com_fmrn_dim_team.team_sk
LEFT JOIN
{{ ref('com_fmrn_dim_utm_parameter') }} AS com_fmrn_dim_utm_parameter
ON
com_fmrn_fact_team_by_created_team.utm_parameter_sk = com_fmrn_dim_utm_parameter.utm_parameter_sk
GROUP BY
target_date
, com_fmrn_dim_team.use_case
, com_fmrn_dim_team.is_iframe_embedded
, com_fmrn_dim_utm_parameter.utm_source
, com_fmrn_dim_utm_parameter.utm_medium
, com_fmrn_dim_utm_parameter.utm_campaign
, com_fmrn_dim_utm_parameter.utm_content
, com_fmrn_dim_utm_parameter.utm_term
, com_fmrn_dim_utm_parameter.utm_group
Data Mart 層
この層では、KGI・KPIの集計や特定用途に特化したテーブルを生成しています。
データセットの命名規則としては、mart_formrunのように、データソース名の前にmart_のプレフィックスを入れるようにしています。
また、テーブル名はdm_fmrn_monthly_team_metricsのように、dm_{サービス名の略称}_のプレフィックスをテーブル名に入れるようにしています。
Data Mart 層のモデル例
{{
config(
partition_by={
'field': 'target_month'
, 'data_type': 'date'
, 'granularity': 'day'
}
)
}}
SELECT
DATE_TRUNC(target_date, MONTH) AS target_month
, use_case
, is_iframe_embedded
, utm_source
, utm_medium
, utm_campaign
, utm_content
, utm_term
, utm_group
, team_category
, SUM(cnt_team_by_created_team) AS cnt_team_by_created_team
, SUM(cnt_team_by_created_first_form) AS cnt_team_by_created_first_form
, SUM(cnt_team_by_created_first_entry) AS cnt_team_by_created_first_entry
, SUM(cnt_team_by_is_paid_team) AS cnt_team_by_is_paid_team
, SUM(cnt_team_by_is_churn_team) AS cnt_team_by_is_churn_team
, SUM(cnt_team_by_is_upgrade_team) AS cnt_team_by_is_upgrade_team
, SUM(cnt_team_by_is_downgrade_team) AS cnt_team_by_is_downgrade_team
FROM
{{ ref('dm_fmrn_daily_team_metrics') }}
GROUP BY
target_date
, use_case
, is_iframe_embedded
, utm_source
, utm_medium
, utm_campaign
, utm_content
, utm_term
, utm_group
, team_category
おわりに
ここまで読んでくださりありがとうございました。
Analytics Engineer としての経験値はまだまだ少ない身ではあるのですが、それでもデータ分析基盤の開発に挑戦できているのは、ひとえに dbt というサービスのおかげだと思っています。
これからも、dbt や他社のデータ分析基盤事例をキャッチアップしながら、Analytics Engineer としてのスキルを上げていけるよう頑張ってまいりますので、もしイベントや SNS 等で絡むことがあれば仲良くしていただけると嬉しいです!