BigQueryへデータロードはデータサイズによっては処理時間が長くかかることがあります。
Cloud DataflowでBigQueryへのデータロードを行うと短時間で高速に処理することができます。
今回はGoogleから提供されている Cloud Storage Text to BigQuery を利用してBigQueryへのロードを行います。
前提
- Google Cloud SDKがインストールされていること
ロードするデータ
CSV形式。文字列内のカンマに対応するためにダブルクォーテーションで括ります。
ロードするファイルはGoogle StrageにGZIP形式でアップロードします。
"A000001","***************","2019-01-01 00:00:00"
"A000002","***************","2019-01-01 00:00:00"
"A000003","***************","2019-01-01 00:00:00"
JSONファイル
スキーマの情報を記述したJSONファイルを以下のように作成します。
作成したファイルはGoogle Strageにアップロードします。
{
"BigQuery Schema": [
{
"mode": "NULLABLE",
"name": "id",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "title",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "stamp",
"type": "TIMESTAMP"
}
]
}
UDFファイル
文字列内のカンマやダブルクォーテーションに対応させています。
作成したファイルはGoogle Strageにアップロードします。
function transform(line) {
var values = line.match(/"(\\["ntr\\]|[^"])*"|[^,]+/g);
var obj = new Object();
obj.id = unescape(String(values[0]).slice(1,-1))
obj.name = unescape(String(values[1]).slice(1,-1))
obj.stamp = unescape(String(values[2]).slice(1,-1))
var jsonString = JSON.stringify(obj);
return jsonString;
}
CREATE TABLE
データロード先のテーブルを事前に作成します。
CREATE TABLEで利用するスキーマファイルを作成します。
[
{
"mode": "NULLABLE",
"name": "id",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "title",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "stamp",
"type": "TIMESTAMP"
}
]
テーブル作成
bq mk --table --schema book.schema %{project}:%{dataset}.book
Cloud Dataflow実行
gcloud dataflowコマンドを以下のように実行します。
gcloud dataflow jobs run bqload-book \
--gcs-location gs://dataflow-templates/latest/GCS_Text_to_BigQuery \
--max-workers=10 \
--parameters \
javascriptTextTransformFunctionName=transform,\
JSONPath=gs://bqload-bucket/schema/book.schema,\
javascriptTextTransformGcsPath=gs://bqload-bucket/udf/book.js,\
inputFilePattern=gs://bqload-bucket/load/book/*.gz,\
outputTable=%{project}:%{dataset}.book,\
bigQueryLoadingTemporaryDirectory=gs://bqload-bucket/tmp/
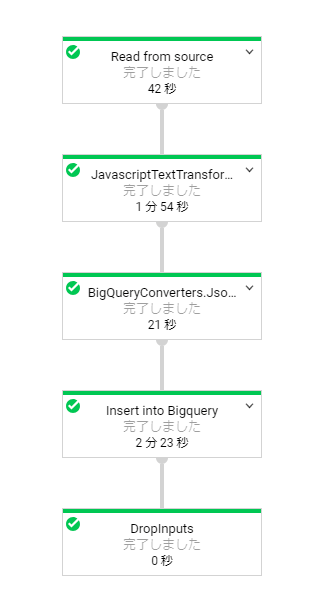
結果
Dataflowがこのように実行されbookテーブルデータをロードできました。
最後に
- 文字列内にカンマやダブルクォーテーションがあった時のエラー対応は手間取りました。
- データサイズが大きければ大きいほどDataflow実行時のワーカー数を増やし効率アップが期待できます。